BigQuery と Document AI の統合により、ドキュメント分析や生成 AI のユースケース構築を促進します。デジタル トランスフォーメーションの加速に伴い、組織は膨大な量のテキストデータやその他のドキュメント データを生成しています。これらのすべてのデータには、インサイトの取得や生成 AI の新たなユースケースを実現する計り知れない可能性が秘められています。こうしたデータの活用を支援するため、このたび BigQuery と Document AI を統合したことを発表いたします。この統合により、ドキュメント データからインサイトを引き出して、新しい大規模言語モデル(LLM)アプリケーションを構築できるようになりました。
概要
BigQuery をご利用のお客様は、Google の最先端の基盤モデルを利用した Document AI カスタム エクストラクタを作成して、それを独自のドキュメントやメタデータに基づいてカスタマイズすることができるようになりました。こうしてカスタマイズしたモデルを BigQuery から呼び出せば、シンプルで強力な SQL を活用して安全かつ管理された方法でドキュメントから構造化データを抽出できます。この統合が行われる前、一部のお客様は、抽出ロジックや抽出スキーマを手作業でキュレートしながら、独立した Document AI パイプラインを構築することを試みていました。また、ネイティブな統合機能がないなか、データを同期して、その整合性を維持するには特注のインフラストラクチャを開発する必要がありました。そのため、ドキュメント分析プロジェクトはいずれも多額の投資を必要とする大規模な事業になっていました。今回の統合により、Document AI のカスタム エクストラクタ用のリモートモデルを BigQuery で簡単に作成できるようになりました。そのリモートモデルを利用してドキュメント分析や生成 AI を大規模に実行すれば、データ主導のインサイトやイノベーションの新時代を切り開くことができます。
データを統合、管理して AI エクスペリエンスにつなげる
カスタム エクストラクタは、Document AI を使用して以下の 3 つの手順で構築できます。
- ドキュメントから抽出する必要のあるデータを定義します。これは
document schemaと呼ばれ、カスタム エクストラクタの各バージョンとともに保存され、BigQuery からアクセスできます。 - 必要に応じて、アノテーション付きの追加ドキュメントを抽出のサンプルとして使用します。
- Document AI で提供される基盤モデルに基づいて、カスタム エクストラクタのモデルをトレーニングします。
Document AI では、手動トレーニングが必要なカスタム エクストラクタに加えて、経費精算、領収書、請求書、税務フォーム、政府発行の ID など、多数のシナリオですぐに使用できるエクストラクタがプロセッサ ギャラリーに用意されています。
カスタム エクストラクタの準備ができたら、BigQuery Studio に移動し、次の 4 つの手順で SQL を使用してドキュメントを分析します。
- SQL を使用してエクストラクタの BigQuery リモートモデルを登録します。このモデルは、上記で作成したドキュメント スキーマを理解し、カスタム エクストラクタを呼び出して結果を解析できます。
- Cloud Storage に保存されているドキュメントについて、SQL を使用してオブジェクト テーブルを作成します。行レベルのアクセス ポリシーを設定してテーブル内の非構造化データを管理すると、ユーザーによる特定のドキュメントへのアクセスを制限して、プライバシーとセキュリティのために AI の能力を抑えることができます。
- オブジェクト テーブルで
ML.PROCESS_DOCUMENT関数を使用して API エンドポイントへの推論呼び出しを行い、関連するフィールドを抽出します。関数の外部でWHERE句を使用して、抽出対象のドキュメントをフィルタすることもできます。この関数は、抽出されたフィールドを各列とする構造化テーブルを返します。 - 抽出されたデータを他の BigQuery テーブルと結合して構造化データと非構造化データを組み合わせ、ビジネス価値を生み出します。
次の例は、ユーザー エクスペリエンスを示しています。
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.
CREATE OR REPLACE EXTERNAL TABLE `my_dataset.document`
WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://my_bucket/path/*'],
metadata_cache_mode= 'AUTOMATIC',
max_staleness= INTERVAL 1 HOUR
);
# Create a remote model to register your Doc AI processor in BigQuery.
CREATE OR REPLACE MODEL `my_dataset.layout_parser`
REMOTE WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
remote_service_type = 'CLOUD_AI_DOCUMENT_V1',
document_processor='PROCESSOR_ID'
);
# Invoke the registered model over the object table to parse PDF document
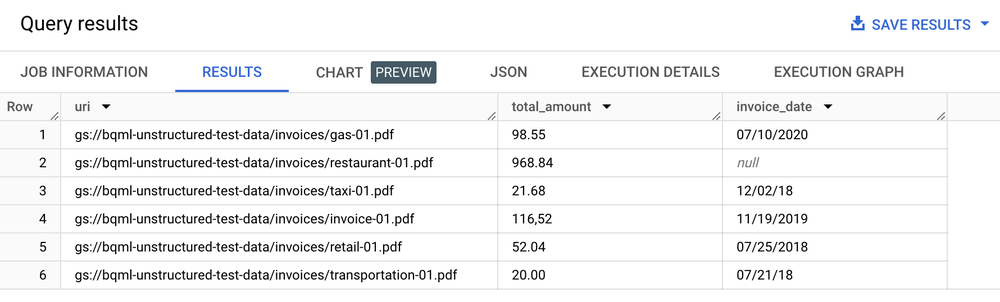
SELECT uri, total_amount, invoice_date
FROM ML.PROCESS_DOCUMENT(
MODEL `my_dataset.layout_parser`,
TABLE `my_dataset.document`,
PROCESS_OPTIONS => (
JSON '{"layout_config": {"chunking_config": {"chunk_size": 250}}}')
)
WHERE content_type = 'application/pdf';
結果のテーブル
テキスト分析、要約、その他のドキュメント分析のユースケース
ドキュメントからテキストを抽出したら、以下のような方法でドキュメント分析を実施できます。
- BigQuery ML を使用してテキスト分析を実行する: BigQuery ML は、さまざまな方法でエンベディング モデルのトレーニングとデプロイをサポートしています。たとえば、BigQuery ML を使用してサポートへの問い合わせ時の顧客の感情を識別したり、製品に関するフィードバックをさまざまなカテゴリに分類したりできます。Python をご利用の場合は、Pandas 用の BigQuery DataFrames や scikit-learn などの API を使用して、データのテキスト分析を行うこともできます。
text-embedding-004LLM を使用してチャンク化されたドキュメントからエンベディングを生成する: BigQuery には、text-embedding-004モデルを呼び出してエンベディングを生成するML.GENERATE_EMBEDDING関数があります。たとえば、Document AI を使用して顧客のフィードバックを抽出し、PaLM 2 を使用してそのフィードバックを要約することができます。なお、いずれの作業でも BigQuery SQL を使用します。- ドキュメントのメタデータを BigQuery テーブルに保存されている他の構造化データと結合する:
たとえば、チャンク化されたドキュメントを使用してエンベディングを生成し、ベクトル検索に使用できます。
# Example 1: Parse the chunked data
CREATE OR REPLACE TABLE docai_demo.demo_result_parsed AS (SELECT
uri,
JSON_EXTRACT_SCALAR(json , '$.chunkId') AS id,
JSON_EXTRACT_SCALAR(json , '$.content') AS content,
JSON_EXTRACT_SCALAR(json , '$.pageFooters[0].text') AS page_footers_text,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageStart') AS page_span_start,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end
FROM docai_demo.demo_result, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json)
# Example 2: Generate embedding
CREATE OR REPLACE TABLE `docai_demo.embeddings` AS
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL `docai_demo.embedding_model`,
TABLE `docai_demo.demo_result_parsed`
);
検索と生成 AI のユースケースを実装する
ドキュメントから構造化テキストを抽出したら、BigQuery の検索機能とインデックス作成機能を生かして「干し草の中から針を見つける」ようなクエリのために最適化されたインデックスを構築できます。これにより、強力な検索機能を利用できるようになります。この統合により、SQL とカスタム Document AI モデルを使用してプライバシー フィルタリング、コンテンツの安全性チェック、トークン チャンク処理を行うなど、新しい生成 LLM アプリケーションも実現できるようになります。抽出されたテキストを他のメタデータと組み合わせれば、大規模な言語モデルをファインチューニングするために必要なトレーニング コーパスのキュレーションを簡素化できます。また、BigQuery のエンベディング生成機能とベクトル インデックス管理機能を使用してグラウンディングされた、ガバナンスが適用されたエンタープライズ データに基づいて LLM ユースケースを構築します。このインデックスを Vertex AI と同期することで、検索拡張生成のユースケースを実装し、よりガバナンスが強化され、合理化された AI エクスペリエンスを実現できます。
サンプル アプリケーション
Document AI コネクタを使用するエンドツーエンド アプリケーションの例: