BigQuery と Document AI の統合により、ドキュメント分析や生成 AI のユースケース構築を促進します。デジタル トランスフォーメーションの加速に伴い、組織は膨大な量のテキストデータやその他のドキュメント データを生成しています。これらのすべてのデータには、インサイトの取得や生成 AI の新たなユースケースを実現する計り知れない可能性が秘められています。こうしたデータの活用を支援するため、このたび BigQuery と Document AI を統合したことを発表いたします。この統合により、ドキュメント データからインサイトを引き出して、新しい大規模言語モデル(LLM)アプリケーションを構築できるようになりました。
概要
BigQuery をご利用のお客様は、Google の最先端の基盤モデルを利用した Document AI カスタム エクストラクタを作成して、それを独自のドキュメントやメタデータに基づいてカスタマイズすることができるようになりました。こうしてカスタマイズしたモデルを BigQuery から呼び出せば、シンプルで強力な SQL を活用して安全かつ管理された方法でドキュメントから構造化データを抽出できます。この統合が行われる前、一部のお客様は、抽出ロジックや抽出スキーマを手作業でキュレートしながら、独立した Document AI パイプラインを構築することを試みていました。また、ネイティブな統合機能がないなか、データを同期して、その整合性を維持するには特注のインフラストラクチャを開発する必要がありました。そのため、ドキュメント分析プロジェクトはいずれも多額の投資を必要とする大規模な事業になっていました。今回の統合により、Document AI のカスタム エクストラクタ用のリモートモデルを BigQuery で簡単に作成できるようになりました。そのリモートモデルを利用してドキュメント分析や生成 AI を大規模に実行すれば、データ主導のインサイトやイノベーションの新時代を切り開くことができます。
Cloud Storage に保存されているドキュメントについて、SQL を使用してオブジェクト テーブルを作成します。行レベルのアクセス ポリシーを設定してテーブル内の非構造化データを管理すると、ユーザーによる特定のドキュメントへのアクセスを制限して、プライバシーとセキュリティのために AI の能力を抑えることができます。
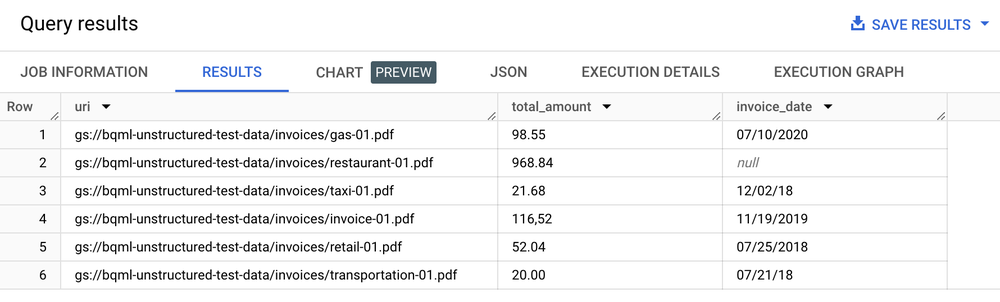
オブジェクト テーブルで ML.PROCESS_DOCUMENT 関数を使用して API エンドポイントへの推論呼び出しを行い、関連するフィールドを抽出します。関数の外部で WHERE 句を使用して、抽出対象のドキュメントをフィルタすることもできます。この関数は、抽出されたフィールドを各列とする構造化テーブルを返します。
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.CREATEORREPLACEEXTERNALTABLE`my_dataset.document`WITHCONNECTION`my_project.us.example_connection`OPTIONS(object_metadata='SIMPLE',uris=['gs://my_bucket/path/*'],metadata_cache_mode='AUTOMATIC',max_staleness=INTERVAL1HOUR);# Create a remote model to register your Doc AI processor in BigQuery.CREATEORREPLACEMODEL`my_dataset.layout_parser`REMOTEWITHCONNECTION`my_project.us.example_connection`OPTIONS(remote_service_type='CLOUD_AI_DOCUMENT_V1',document_processor='PROCESSOR_ID');# Invoke the registered model over the object table to parse PDF documentSELECTuri,total_amount,invoice_dateFROMML.PROCESS_DOCUMENT(MODEL`my_dataset.layout_parser`,TABLE`my_dataset.document`,PROCESS_OPTIONS=> (JSON'{"layout_config": {"chunking_config": {"chunk_size": 250}}}'))WHEREcontent_type='application/pdf';
結果のテーブル
テキスト分析、要約、その他のドキュメント分析のユースケース
ドキュメントからテキストを抽出したら、以下のような方法でドキュメント分析を実施できます。
BigQuery ML を使用してテキスト分析を実行する: BigQuery ML は、さまざまな方法でエンベディング モデルのトレーニングとデプロイをサポートしています。たとえば、BigQuery ML を使用してサポートへの問い合わせ時の顧客の感情を識別したり、製品に関するフィードバックをさまざまなカテゴリに分類したりできます。Python をご利用の場合は、Pandas 用の BigQuery DataFrames や scikit-learn などの API を使用して、データのテキスト分析を行うこともできます。
# Example 1: Parse the chunked dataCREATEORREPLACETABLEdocai_demo.demo_result_parsedAS(SELECTuri,JSON_EXTRACT_SCALAR(json,'$.chunkId')ASid,JSON_EXTRACT_SCALAR(json,'$.content')AScontent,JSON_EXTRACT_SCALAR(json,'$.pageFooters[0].text')ASpage_footers_text,JSON_EXTRACT_SCALAR(json,'$.pageSpan.pageStart')ASpage_span_start,JSON_EXTRACT_SCALAR(json,'$.pageSpan.pageEnd')ASpage_span_endFROMdocai_demo.demo_result,UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks,'$'))json)# Example 2: Generate embeddingCREATEORREPLACETABLE`docai_demo.embeddings`ASSELECT*FROMML.GENERATE_EMBEDDING(MODEL`docai_demo.embedding_model`,TABLE`docai_demo.demo_result_parsed`);
検索と生成 AI のユースケースを実装する
ドキュメントから構造化テキストを抽出したら、BigQuery の検索機能とインデックス作成機能を生かして「干し草の中から針を見つける」ようなクエリのために最適化されたインデックスを構築できます。これにより、強力な検索機能を利用できるようになります。この統合により、SQL とカスタム Document AI モデルを使用してプライバシー フィルタリング、コンテンツの安全性チェック、トークン チャンク処理を行うなど、新しい生成 LLM アプリケーションも実現できるようになります。抽出されたテキストを他のメタデータと組み合わせれば、大規模な言語モデルをファインチューニングするために必要なトレーニング コーパスのキュレーションを簡素化できます。また、BigQuery のエンベディング生成機能とベクトル インデックス管理機能を使用してグラウンディングされた、ガバナンスが適用されたエンタープライズ データに基づいて LLM ユースケースを構築します。このインデックスを Vertex AI と同期することで、検索拡張生成のユースケースを実装し、よりガバナンスが強化され、合理化された AI エクスペリエンスを実現できます。
[[["わかりやすい","easyToUnderstand","thumb-up"],["問題の解決に役立った","solvedMyProblem","thumb-up"],["その他","otherUp","thumb-up"]],[["わかりにくい","hardToUnderstand","thumb-down"],["情報またはサンプルコードが不正確","incorrectInformationOrSampleCode","thumb-down"],["必要な情報 / サンプルがない","missingTheInformationSamplesINeed","thumb-down"],["翻訳に関する問題","translationIssue","thumb-down"],["その他","otherDown","thumb-down"]],["最終更新日 2025-09-04 UTC。"],[[["\u003cp\u003eBigQuery now integrates with Document AI, enabling users to extract insights from document data and create new large language model (LLM) applications.\u003c/p\u003e\n"],["\u003cp\u003eCustomers can create custom extractors in Document AI, powered by Google's foundation models, and then invoke these models from BigQuery to extract structured data using SQL.\u003c/p\u003e\n"],["\u003cp\u003eThis integration simplifies document analytics projects by eliminating the need for manually building extraction logic and schemas, thus reducing the investment needed.\u003c/p\u003e\n"],["\u003cp\u003eBigQuery's \u003ccode\u003eML.PROCESS_DOCUMENT\u003c/code\u003e function, along with remote models, object tables, and SQL, facilitates the extraction of relevant fields from documents and the combination of this data with other structured data.\u003c/p\u003e\n"],["\u003cp\u003ePost-extraction, BigQuery ML and the \u003ccode\u003etext-embedding-004\u003c/code\u003e model can be leveraged for text analytics, generating embeddings, and building indexes for advanced search and generative AI applications.\u003c/p\u003e\n"]]],[],null,["# BigQuery integration\n====================\n\nBigQuery integrates with Document AI to help build document analytics and generative AI\nuse cases. As digital transformation accelerates, organizations are generating vast\namounts of text and other document data, all of which holds immense potential for\ninsights and powering novel generative AI use cases. To help harness this data,\nwe're excited to announce an integration between [BigQuery](/bigquery)\nand [Document AI](/document-ai), letting you extract insights from document data and build\nnew large language model (LLM) applications.\n\nOverview\n--------\n\nBigQuery customers can now create Document AI [custom extractors](/blog/products/ai-machine-learning/document-ai-workbench-custom-extractor-and-summarizer), powered by Google's\ncutting-edge foundation models, which they can customize based on their own documents\nand metadata. These customized models can then be invoked from BigQuery to\nextract structured data from documents in a secure, governed manner, using the\nsimplicity and power of SQL.\nPrior to this integration, some customers tried to construct independent Document AI\npipelines, which involved manually curating extraction logic and schema. The\nlack of built-in integration capabilities left them to develop bespoke infrastructure\nto synchronize and maintain data consistency. This turned each document analytics\nproject into a substantial undertaking that required significant investment.\nNow, with this integration, customers can create remote models in BigQuery\nfor their custom extractors in Document AI, and use them to perform document analytics\nand generative AI at scale, unlocking a new era of data-driven insights and innovation.\n\nA unified, governed data to AI experience\n-----------------------------------------\n\nYou can build a custom extractor in the Document AI with three steps:\n\n1. Define the data you need to extract from your documents. This is called `document schema`, stored with each version of the custom extractor, accessible from BigQuery.\n2. Optionally, provide extra documents with annotations as samples of the extraction.\n3. Train the model for the custom extractor, based on the foundation models provided in Document AI.\n\nIn addition to custom extractors that require manual training, Document AI also\nprovides ready to use extractors for expenses, receipts, invoices, tax forms,\ngovernment ids, and a multitude of other scenarios, in the processor gallery.\n\nThen, once you have the custom extractor ready, you can move to BigQuery Studio\nto analyze the documents using SQL in the following four steps:\n\n1. Register a BigQuery remote model for the extractor using SQL. The model can understand the document schema (created above), invoke the custom extractor, and parse the results.\n2. Create object tables using SQL for the documents stored in Cloud Storage. You can govern the unstructured data in the tables by setting row-level access policies, which limits users' access to certain documents and thus restricts the AI power for privacy and security.\n3. Use the function `ML.PROCESS_DOCUMENT` on the object table to extract relevant fields by making inference calls to the API endpoint. You can also filter out the documents for the extractions with a `WHERE` clause outside of the function. The function returns a structured table, with each column being an extracted field.\n4. Join the extracted data with other BigQuery tables to combine structured and unstructured data, producing business values.\n\nThe following example illustrates the user experience:\n\n # Create an object table in BigQuery that maps to the document files stored in Cloud Storage.\n CREATE OR REPLACE EXTERNAL TABLE `my_dataset.document`\n WITH CONNECTION `my_project.us.example_connection`\n OPTIONS (\n object_metadata = 'SIMPLE',\n uris = ['gs://my_bucket/path/*'],\n metadata_cache_mode= 'AUTOMATIC',\n max_staleness= INTERVAL 1 HOUR\n );\n\n # Create a remote model to register your Doc AI processor in BigQuery.\n CREATE OR REPLACE MODEL `my_dataset.layout_parser`\n REMOTE WITH CONNECTION `my_project.us.example_connection`\n OPTIONS (\n remote_service_type = 'CLOUD_AI_DOCUMENT_V1', \n document_processor='\u003cvar translate=\"no\"\u003ePROCESSOR_ID\u003c/var\u003e'\n );\n\n # Invoke the registered model over the object table to parse PDF document\n SELECT uri, total_amount, invoice_date\n FROM ML.PROCESS_DOCUMENT(\n MODEL `my_dataset.layout_parser`,\n TABLE `my_dataset.document`,\n PROCESS_OPTIONS =\u003e (\n JSON '{\"layout_config\": {\"chunking_config\": {\"chunk_size\": 250}}}')\n )\n WHERE content_type = 'application/pdf';\n\nTable of results\n\nText analytics, summarization and other document analysis use cases\n-------------------------------------------------------------------\n\nOnce you have extracted text from your documents, you can then perform document\nanalytics in a few ways:\n\n- Use BigQuery ML to perform text-analytics: BigQuery ML supports training and deploying embedding models in a variety of ways. For example, you can use BigQuery ML to identify customer sentiment in support calls, or to classify product feedback into different categories. If you are a Python user, you can also use BigQuery DataFrames for pandas, and scikit-learn-like APIs for text analysis on your data.\n- Use `text-embedding-004` LLM to generate embeddings from the chunked documents: BigQuery has a `ML.GENERATE_EMBEDDING` function that calls the `text-embedding-004` model to generate embeddings. For example, you can use a Document AI to extract customer feedback and summarize the feedback using PaLM 2, all with BigQuery SQL.\n- Join document metadata with other structured data stored in BigQuery tables:\n\nFor example, you can generate embeddings using the chunked documents and use it for vector search. \n\n # Example 1: Parse the chunked data\n\n CREATE OR REPLACE TABLE docai_demo.demo_result_parsed AS (SELECT\n uri,\n JSON_EXTRACT_SCALAR(json , '$.chunkId') AS id,\n JSON_EXTRACT_SCALAR(json , '$.content') AS content,\n JSON_EXTRACT_SCALAR(json , '$.pageFooters[0].text') AS page_footers_text,\n JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageStart') AS page_span_start,\n JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end\n FROM docai_demo.demo_result, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json)\n\n # Example 2: Generate embedding\n\n CREATE OR REPLACE TABLE `docai_demo.embeddings` AS\n SELECT * FROM ML.GENERATE_EMBEDDING(\n MODEL `docai_demo.embedding_model`,\n TABLE `docai_demo.demo_result_parsed`\n );\n\nImplement search and generative AI use cases\n--------------------------------------------\n\nOnce you've extracted structured text from your documents, you can build indexes\noptimized for needle in the haystack queries, made possible by BigQuery's search\nand indexing capabilities, unlocking powerful search capability.\nThis integration also helps unlock new generative LLM applications like executing\ntext-file processing for privacy filtering, content safety checks, and token chunking\nusing SQL and custom Document AI models. The extracted text, combined with other metadata,\nsimplifies the curation of the training corpus required to fine-tune large language\nmodels. Moreover, you're building LLM use cases on governed, enterprise data\nthat's been grounded through BigQuery's embedding generation and vector index\nmanagement capabilities. By synchronizing this index with Vertex AI, you can\nimplement retrieval-augmented generation use cases, for a more governed and\nstreamlined AI experience.\n\nSample application\n------------------\n\nFor an example of an end-to-end application using the Document AI Connector:\n\n- Refer to this expense report demo on [GitHub](https://github.com/GoogleCloudPlatform/smart-expenses).\n- Read the companion [blog post](/blog/topics/developers-practitioners/smarter-applications-document-ai-workflows-and-cloud-functions).\n- Watch a deep dive [video](https://www.youtube.com/watch?v=Bnac6JnBGQg&t=1s) from Google Cloud Next 2021."]]