많은 조직들이 다양한 비즈니스 목적에 따라 데이터를 분석할 수 있도록 민감한 정보를 저장하는 클라우드 데이터 웨어하우스를 배포합니다. 이 문서에서는 서 엔터프라이즈 데이터 관리 위원회에서 관리하는 Cloud 데이터 관리 기능(CDMC) 키 제어 프레임워크를 BigQuery 데이터 웨어하우스에 구현하는 방법을 설명합니다.
CDMC 키 제어 프레임워크는 주로 클라우드 서비스 제공업체 및 기술 공급업체를 위해 제작되었습니다. 이 프레임워크는 클라우드에서 고객이 민감한 정보를 효율적으로 관리 및 제어할 수 있도록 공급업체가 구현할 수 있는 14개의 키 제어 방법에 대해 설명합니다. 이러한 제어 방법은 100개 이상의 회사에서 300명 이상의 전문가가 참여하는 CDMC 작업 그룹에서 고안되었습니다. 프레임워크를 작성하는 동안 CDMC 작업 그룹은 존재하는 많은 법적 및 규제 요구사항을 고려했습니다.
이 BigQuery 및 Data Catalog 참조 아키텍처는 CDMC 인증 클라우드 솔루션으로 CDMC 키 제어 프레임워크에 대해 평가 및 인증되었습니다. 참조 아키텍처는 공개 라이브러리는 물론 다양한 Google Cloud 서비스와 기능을 사용하여 CDMC 키 제어 및 권장 자동화를 구성합니다. 이 문서에서는 BigQuery 데이터 웨어하우스에서 민감한 정보를 보호하기 위해 키 제어를 구현하는 방법을 설명합니다.
아키텍처
다음 Google Cloud 참조 아키텍처는 CDMC 키 제어 프레임워크 테스트 사양 v1.1.1과 일치합니다. 다이어그램의 숫자는 Google Cloud 서비스로 처리되는 키 제어를 나타냅니다.

참조 아키텍처는 보안 데이터 웨어하우스 청사진을 기반으로 하며 민감한 정보가 포함된 BigQuery 데이터 웨어하우스를 보호하는 데 도움이 되는 아키텍처를 제공합니다. 앞의 다이어그램에서 다이어그램 상단의 프로젝트(회색)는 보안 데이터 웨어하우스 청사진의 일부이며 데이터 거버넌스 프로젝트(파란색)에는 CDMC 키 제어 프레임워크 요구사항을 충족하기 위해 추가된 서비스가 포함되어 있습니다. CDMC 키 제어 프레임워크를 구현하기 위해 이 아키텍처는 데이터 거버넌스 프로젝트를 확장합니다. 데이터 거버넌스 프로젝트는 분류, 수명 주기 관리, 데이터 품질 관리와 같은 제어 방법을 제공합니다. 또한 이 프로젝트는 아키텍처를 감사하고 발견 항목을 보고하는 방법을 제공합니다.
이 참조 아키텍처를 구현하는 방법을 자세히 알아보려면 GitHub에서 Google Cloud CDMC 참조 아키텍처를 참조하세요.
CDMC 키 제어 프레임워크 개요
다음 표에서는 CDMC 키 제어 프레임워크를 요약해서 보여줍니다.
| # | CDMC 키 제어 | CDMC 제어 요구사항 |
|---|---|---|
| 1 | 데이터 제어 규정 준수 | 클라우드 데이터 관리 비즈니스 사례를 정의하고 제어합니다. 민감한 정보가 포함된 모든 데이터 애셋은 측정항목 및 자동화된 알림을 사용하여 CDMC 키 제어 규정 준수 여부를 모니터링해야 합니다. |
| 2 | 마이그레이션된 데이터와 클라우드 생성 데이터 모두에 대해 데이터 소유권이 설정됨 | Data Catalog에서 소유권 필드는 모든 민감한 정보에 대해 입력해야 하며, 그렇지 않으면 정의된 워크플로에 보고됩니다. |
| 3 | 데이터 소싱 및 소비가 자동화에 의해 관리되고 지원됨 | 민감한 정보가 포함된 모든 데이터 애셋에 대해 권한이 있는 데이터 소스 및 프로비저닝 지점의 레지스터가 채워지거나 정의된 워크플로에 보고해야 합니다. |
| 4 | 데이터 주권 및 해외 간 데이터 이동 관리 | 민감한 정보의 데이터 주권 및 해외 간 이동은 정의된 정책에 따라 기록, 감사, 제어해야 합니다. |
| 5 | Data Catalog가 구현 및 사용되며 상호 운용이 가능 | 분류는 모든 데이터에 대해 생성 또는 수집 시 모든 환경에서 일관성 있게 자동화되어야 합니다. |
| 6 | 데이터 분류 정의 및 사용 | 분류는 생성 또는 수집 시점에 모든 데이터에 대해 자동화하고 상시 사용하도록 설정해야 합니다. 분류는 다음 항목에 대해 자동화됩니다.
|
| 7 | 데이터 사용 권한을 관리, 적용, 추적 | 이 제어를 사용하려면 다음이 필요합니다.
|
| 8 | 윤리적인 액세스, 사용, 데이터 결과 관리 | 민감한 정보가 포함된 모든 데이터 공유 계약에 대해 데이터 소비 목적을 제공해야 합니다. 목적은 필요한 데이터 유형을 지정하고 글로벌 조직의 경우 국가 또는 법인 범위를 지정해야 합니다. |
| 9 | 데이터가 보호되고 제어가 입증됨 | 이 제어를 사용하려면 다음이 필요합니다.
|
| 10 | 데이터 개인 정보 보호 프레임워크가 정의되고 운영됨 | 데이터 보호 영향 평가(DPIA)는 관할권에 따라 모든 개인 정보에 대해 자동으로 트리거되어야 합니다. |
| 11 | 데이터 수명주기 계획 및 관리 | 정의된 보관 일정에 따라 데이터 보관, 보관처리, 삭제를 관리해야 합니다. |
| 12 | 데이터 품질 관리됨 | 가능한 경우 분산된 측정항목을 사용해서 민감한 정보에 대해 데이터 품질 측정을 사용 설정해야 합니다. |
| 13 | 비용 관리 원칙 수립 및 적용됨 | 기술 설계 원칙이 설정되고 적용되었습니다. 데이터 사용, 스토리지, 이동과 직접 관련된 비용 측정항목을 카탈로그에서 사용할 수 있어야 합니다. |
| 14 | 데이터 출처 및 계보 이해 | 모든 민감한 정보에 대해 데이터 계보 정보를 제공해야 합니다. 이 정보는 최소한 데이터가 수집되었거나 클라우드 환경에서 데이터가 생성된 소스를 포함해야 합니다. |
1. 데이터 제어 규정 준수
이 제어를 사용하려면 측정항목을 사용하여 이 프레임워크의 규정 준수를 위해 모든 민감한 정보가 모니터링되는지 확인해야 합니다.
아키텍처는 각 주요 제어의 작동 범위를 보여주는 측정항목을 사용합니다. 아키텍처에는 또한 측정항목이 정의된 기준점을 충족하지 않을 때 이를 나타내는 대시보드가 포함됩니다.
아키텍처에는 데이터 애셋이 키 제어를 충족하지 않을 때 발견 항목 및 해결 권장사항을 게시하는 감지기가 포함됩니다. 이러한 발견 항목과 권장사항은 JSON 형식으로 표시되며 구독자에게 배포할 수 있도록 Pub/Sub 주제에 게시됩니다. 티켓팅 시스템에서 자동으로 이슈가 생성되도록 내부 서비스 데스크 또는 서비스 관리 도구를 Pub/Sub 주제와 통합할 수 있습니다.
아키텍처는 Dataflow를 사용하여 발견 항목 이벤트의 예시 구독자를 만듭니다. 그러면 구독자는 데이터 거버넌스 프로젝트에서 실행되는 BigQuery 인스턴스에 저장됩니다. 제공된 여러 뷰를 사용하면 Google Cloud 콘솔에서 BigQuery Studio를 사용하여 데이터를 쿼리할 수 있습니다. 또한 Looker Studio 또는 다른 BigQuery 호환 비즈니스 인텔리전스 도구를 사용하여 보고서를 만들 수 있습니다. 확인할 수 있는 보고서에는 다음이 포함됩니다.
- 마지막 실행 발견 항목 요약
- 마지막 실행 발견 항목 세부정보
- 마지막 실행 메타데이터
- 범위 내의 마지막 실행 데이터 애셋
- 마지막 실행 데이터 세트 통계
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- Pub/Sub는 발견 항목을 게시합니다.
- Dataflow에서 BigQuery 인스턴스에 발견 항목을 로드합니다.
- BigQuery는 발견 항목 데이터를 저장하고 요약 뷰를 제공합니다.
- Looker Studio는 대시보드와 보고서를 제공합니다.
다음 스크린샷은 샘플 Looker Studio 요약 대시보드를 보여줍니다.
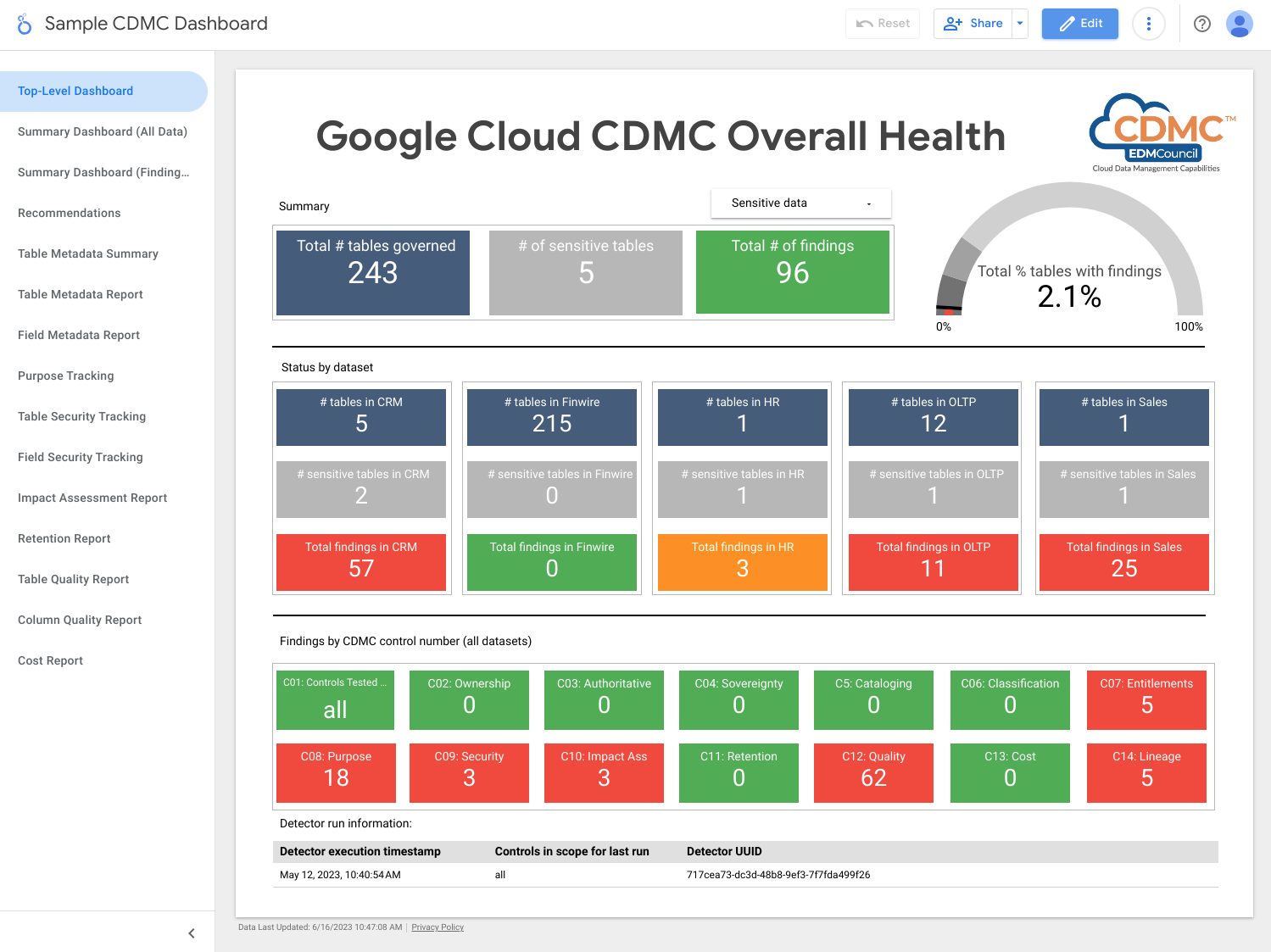
다음 스크린샷은 데이터 애셋별 발견 항목의 샘플 뷰를 보여줍니다.
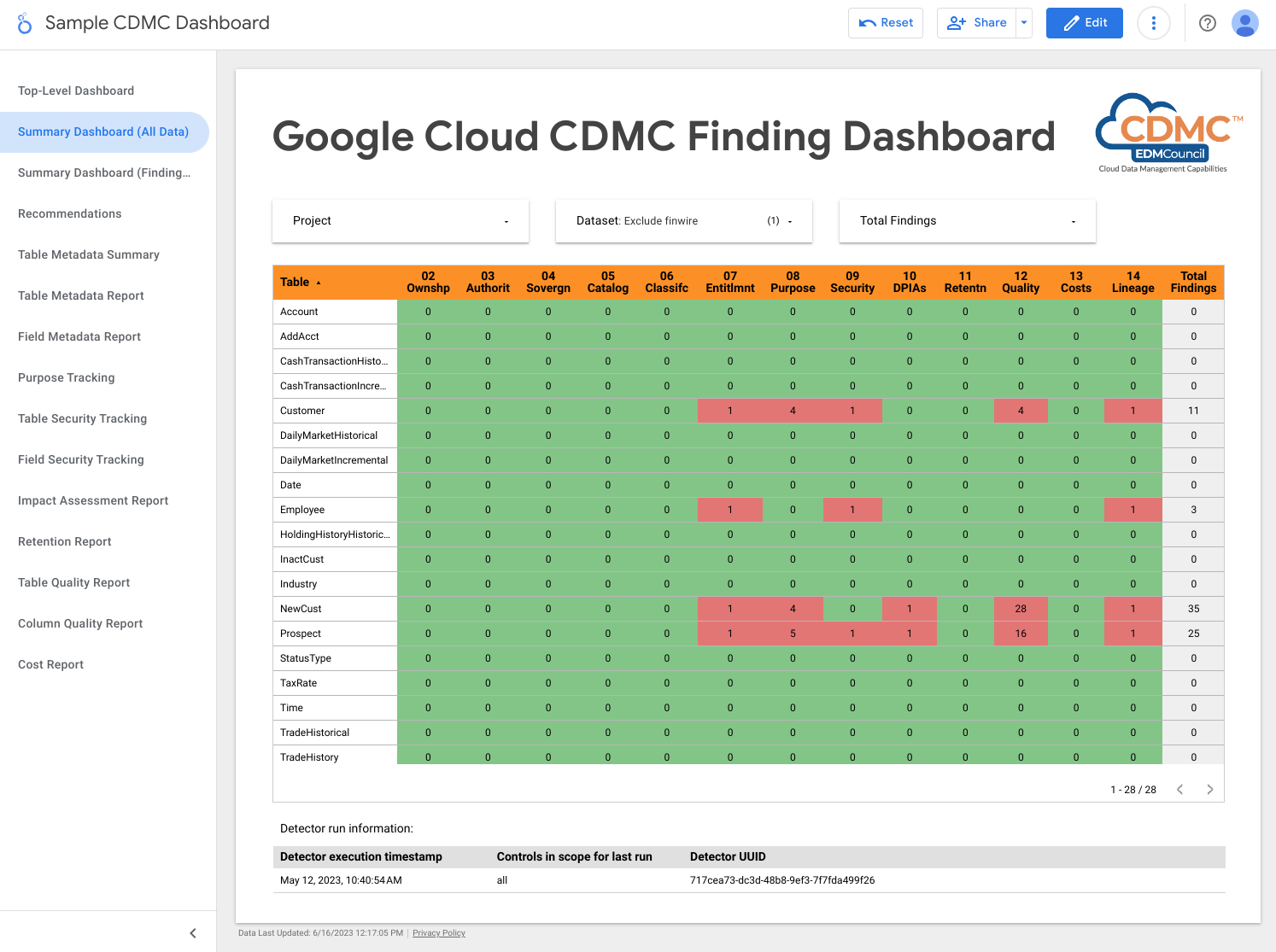
2. 마이그레이션된 데이터와 클라우드 생성 데이터 모두에 대해 데이터 소유권이 설정됨
이 제어 방법의 요구사항을 충족하기 위해 이 아키텍처는 BigQuery 데이터 웨어하우스에서 데이터를 자동으로 검토하고 모든 민감한 정보에 대해 소유자가 식별되었음을 나타내는 데이터 분류 태그를 추가합니다.
Data Catalog는 기술 메타데이터 및 비즈니스 메타데이터 등 두 가지 유형의 메타데이터를 처리합니다. 지정된 프로젝트의 경우 Data Catalog는 BigQuery 데이터 세트, 테이블, 뷰를 자동으로 분류하고 기술 메타데이터를 채웁니다. 카탈로그와 데이터 애셋 간 동기화는 거의 실시간으로 유지됩니다.
아키텍처는 Tag Engine을 사용하여 Data Catalog의 CDMC controls 태그 템플릿에 다음 비즈니스 메타데이터 태그를 추가합니다.
is_sensitive: 데이터 애셋에 민감한 정보가 포함되어 있는지 여부(데이터 분류용 제어 6 참조)owner_name: 데이터 소유자owner_email: 소유자의 이메일 주소
태그는 데이터 거버넌스 프로젝트의 참조 BigQuery 테이블에 저장된 기본값을 사용하여 채워집니다.
기본적으로 아키텍처는 테이블 수준에서 소유권 메타데이터를 설정하지만, 메타데이터가 열 수준에서 설정되도록 아키텍처를 변경할 수 있습니다. 자세한 내용은 Data Catalog 태그 및 태그 템플릿을 참조하세요.
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- BigQuery 데이터 웨어하우스 2개: 하나는 기밀 데이터를 저장하고 다른 하나는 데이터 애셋 소유권의 기본값을 저장합니다.
- Data Catalog는 태그 템플릿 및 태그를 통해 소유권 메타데이터를 저장합니다.
- 다음과 같은 2개의 Cloud Run 인스턴스:
- 한 인스턴스는 태그가 적용되었는지 확인하고 결과를 게시하는 Report Engine을 실행합니다.
- 또 다른 인스턴스는 보안 데이터 웨어하우스의 데이터에 태그를 지정하는 Tag Engine을 실행합니다.
- Pub/Sub는 발견 항목을 게시합니다.
이 제어와 관련된 문제를 감지하기 위해 아키텍처는 민감한 정보에 소유자 이름 태그가 할당되었는지 검사합니다.
3. 데이터 소싱 및 소비가 자동화에 의해 관리되고 지원됨
이 제어에는 데이터 애셋 분류와 신뢰할 수 있는 소스 및 승인된 배포자의 데이터 등록이 필요합니다. 아키텍처는 Data Catalog를 사용하여 is_authoritative 태그를 CDMC
controls 태그 템플릿에 추가합니다. 이 태그는 데이터 애셋이 권한 소스에서 시작되었는지 여부를 정의합니다.
Data Catalog는 기술 메타데이터와 비즈니스 메타데이터를 사용하여 BigQuery 데이터 세트, 테이블, 뷰를 카탈로그로 작성합니다. 기술 메타데이터는 자동으로 채워지며 프로비저닝 지점의 위치인 리소스 URL을 포함합니다. 비즈니스 메타데이터는 태그 엔진 구성 파일에 정의되며 is_authoritative 태그를 포함합니다.
다음 예약된 실행 시간 중 Tag Engine은 BigQuery의 참조 테이블에 저장된 기본값을 이용해서 CDMC controls 태그 템플릿의 is_authoritative 태그를 채웁니다.
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- BigQuery 데이터 웨어하우스 2개: 하나는 기밀 데이터를 저장하고 다른 하나는 데이터 애셋 권한 소스의 기본값을 저장합니다.
- Data Catalog는 태그를 통해 권한 소스 메타데이터를 저장합니다.
- 다음과 같은 2개의 Cloud Run 인스턴스:
- 한 인스턴스는 태그가 적용되었는지 확인하고 결과를 게시하는 Report Engine을 실행합니다.
- 또 다른 인스턴스는 보안 데이터 웨어하우스의 데이터에 태그를 지정하는 Tag Engine을 실행합니다.
- Pub/Sub는 발견 항목을 게시합니다.
이 제어와 관련된 문제를 감지하기 위해 아키텍처는 민감한 정보에 권한 소스 태그가 할당되었는지 확인합니다.
4. 데이터 주권 및 해외 간 데이터 이동 관리
이 제어를 사용하려면 아키텍처가 리전별 스토리지 요구사항에 따라 데이터 레지스트리를 검사하고 사용 규칙을 적용해야 합니다. 보고서는 데이터 애셋의 지리적 위치를 설명합니다.
아키텍처는 Data Catalog를 사용하여 approved_storage_location 태그를 CDMC controls 태그 템플릿에 추가합니다. 이 태그는 데이터 애셋을 저장하도록 허용되는 지리적 위치를 정의합니다.
데이터의 실제 위치는 BigQuery 테이블 세부정보에 기술 메타데이터로 저장됩니다. BigQuery에서는 관리자가 데이터 세트 또는 테이블의 위치를 변경할 수 없습니다. 대신 관리자가 데이터 위치를 변경하려면 데이터 세트를 복사해야 합니다.
리소스 위치 조직 정책 서비스 제약조건은 데이터를 저장할 수 있는 Google Cloud 리전을 정의합니다. 기본적으로 아키텍처는 기밀 데이터 프로젝트에 제약조건을 설정하지만 원하는 경우 조직 또는 폴더 수준에서 제약조건을 설정할 수 있습니다. Tag Engine은 허용된 위치를 Data Catalog 태그 템플릿에 복제하고 approved_storage_location 태그에 위치를 저장합니다. Security Command Center 프리미엄 등급을 활성화하고 다른 사용자가 리소스 위치 조직 정책 서비스 제약조건을 업데이트하면 Security Command Center는 업데이트된 정책 외부에 저장된 리소스에 대한 취약점 발견 항목을 생성합니다.
Access Context Manager는 데이터 애셋에 액세스하기 전에 사용자가 있어야 하는 지리적 위치를 정의합니다. 액세스 수준을 사용하여 요청을 시작할 수 있는 리전을 지정할 수 있습니다. 그런 후 기밀 데이터 프로젝트의 VPC 서비스 제어 경계에 액세스 정책을 추가합니다.
BigQuery는 데이터 이동을 추적하기 위해 모든 작업에 대해 전체 감사 추적을 수행하고 각 데이터 세트에 대해 쿼리합니다. 감사 추적은 BigQuery 정보 스키마 작업 뷰에 저장됩니다.
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- 조직 정책 서비스는 리소스 위치 제약조건을 정의하고 적용합니다.
- Access Context Manager는 사용자가 데이터를 액세스할 수 있는 위치를 정의합니다.
- BigQuery 데이터 웨어하우스 두 개: 하나는 기밀 데이터를 저장하고 다른 하나는 위치 정책을 검사하는 데 사용되는 원격 함수를 호스팅합니다.
- Data Catalog는 승인된 스토리지 위치를 태그로 저장합니다.
- 다음과 같은 2개의 Cloud Run 인스턴스:
- 한 인스턴스는 태그가 적용되었는지 확인하고 결과를 게시하는 Report Engine을 실행합니다.
- 또 다른 인스턴스는 보안 데이터 웨어하우스의 데이터에 태그를 지정하는 Tag Engine을 실행합니다.
- Pub/Sub는 발견 항목을 게시합니다.
- Cloud Logging은 감사 로그를 작성합니다.
- Security Command Center는 리소스 위치 또는 데이터 액세스와 관련된 발견 항목을 보고합니다.
이 제어와 관련된 문제가 감지되도록 아키텍처에는 승인된 위치 태그에 민감한 정보 위치가 포함되어 있는지에 대한 발견 사항이 포함됩니다.
5. Data Catalog가 구현 및 사용되며 상호 운용이 가능
이 제어 방법을 사용하려면 Data Catalog가 있어야 하고 아키텍처가 신규 및 업데이트된 애셋을 스캔하여 필요에 따라 메타데이터를 추가할 수 있어야 합니다.
이 제어의 요구사항을 충족하기 위해 아키텍처는 Data Catalog를 사용합니다. Data Catalog는 BigQuery 데이터 세트, 테이블, 뷰를 포함하여Google Cloud 애셋을 자동으로 로깅합니다. BigQuery에서 새 테이블을 만들면 Data Catalog가 새 테이블의 기술 메타데이터와 스키마를 자동으로 등록합니다. BigQuery에서 테이블을 업데이트하면 Data Catalog가 거의 즉시 해당 항목을 업데이트합니다.
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- BigQuery 데이터 웨어하우스 2개: 하나는 기밀 데이터를 저장하고 다른 하나는 비기밀 데이터를 저장합니다.
- Data Catalog는 테이블 및 필드의 기술 메타데이터를 저장합니다.
기본적으로 이 아키텍처에서 Data Catalog는 BigQuery의 기술 메타데이터를 저장합니다. 필요한 경우 Data Catalog를 다른 데이터 소스와 통합할 수 있습니다.
6. 데이터 분류 정의 및 사용
이 평가를 사용하려면 데이터가 PII인지, 클라이언트를 식별하는지, 조직이 정의하는 다른 표준을 충족하는지와 같은 민감도에 따라 데이터를 분류해야 합니다. 이 제어의 요구사항을 충족하기 위해 아키텍처는 데이터 애셋 및 민감도에 대한 보고서를 만듭니다. 이 보고서를 사용하여 민감도 설정이 올바른지 확인할 수 있습니다. 또한 새로운 데이터 애셋 또는 기존 데이터 애셋의 변경사항으로 인해 Data Catalog가 업데이트됩니다.
분류는 테이블 수준 및 열 수준에서 Data Catalog 태그 템플릿의 sensitive_category 태그에 저장됩니다. 분류 참조 테이블을 통해 사용 가능한 Sensitive Data Protection 정보 유형(infoType)의 순위를 높이고 더 민감한 콘텐츠의 순위를 높일 수 있습니다.
이 제어의 요구사항을 충족하기 위해 아키텍처는 Sensitive Data Protection, Data Catalog, Tag Engine을 사용하여 BigQuery 테이블의 민감한 열에 다음 태그를 추가합니다.
is_sensitive: 데이터 애셋에 민감한 정보가 포함되는지 여부입니다.sensitive_category: 데이터의 카테고리. 다음 필드 중 하나를 사용해야 합니다.- 민감한 개인 식별 정보
- 개인 식별 정보
- 민감한 개인 정보
- 개인 정보
- 공개 정보
요구사항에 맞게 데이터 카테고리를 변경할 수 있습니다. 예를 들어 자료 비공개 정보(MNPI) 분류를 추가할 수 있습니다.
Sensitive Data Protection가 데이터를 검사한 후 Tag Engine은 애셋별 DLP results 테이블을 읽어 발견 항목을 컴파일합니다. 테이블에 하나 이상의 민감한 infoType 열이 포함된 경우 가장 현저한 infoType이 결정되고 민감한 열과 전체 테이블이 모두 최고 등급의 카테고리로 태그 지정됩니다. 또한 Tag Engine은 해당 정책 태그를 열에 할당하고 is_sensitive 불리언 태그를 테이블에 할당합니다.
Cloud Scheduler를 사용하여 Sensitive Data Protection 검사를 자동화할 수 있습니다.
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- 4개의 BigQuery 데이터 웨어하우스에 다음 정보가 저장됩니다.
- 기밀 데이터
- Sensitive Data Protection 결과 정보
- 데이터 분류 참조 데이터
- 태그 내보내기 정보
- Data Catalog는 분류 태그를 저장합니다.
- Sensitive Data Protection는 애셋에서 민감한 infoType을 검사합니다.
- Compute Engine은 각 BigQuery 데이터 세트에 대해 Sensitive Data Protection 작업을 트리거하는 검사 데이터 세트 스크립트를 실행합니다.
- 다음과 같은 2개의 Cloud Run 인스턴스:
- 한 인스턴스는 태그가 적용되었는지 확인하고 결과를 게시하는 Report Engine을 실행합니다.
- 또 다른 인스턴스는 보안 데이터 웨어하우스의 데이터에 태그를 지정하는 Tag Engine을 실행합니다.
- Pub/Sub는 발견 항목을 게시합니다.
이 제어와 관련된 문제를 감지하기 위해 아키텍처에는 다음 발견 항목이 포함됩니다.
- 민감한 정보에 민감한 카테고리 태그가 할당되었는지 여부
- 민감한 정보에 열 수준의 민감도 유형 태그가 할당되었는지 여부
7. 데이터 사용 권한을 관리, 적용, 추적
기본적으로 작성자 및 소유자에게만 민감한 정보에 대한 사용 권한과 액세스 권한이 할당됩니다. 또한 이 제어 방법을 사용하려면 아키텍처가 민감한 정보에 대한 모든 액세스를 추적할 수 있어야 합니다.
이 제어의 요구사항을 충족하기 위해 아키텍처는 BigQuery에서 cdmc
sensitive data classification 정책 태그 분류를 사용하여 BigQuery 테이블의 기밀 데이터가 포함된 열에 대한 액세스를 제어합니다. 분류에는 다음 정책 태그가 포함됩니다.
- 민감한 개인 식별 정보
- 개인 식별 정보
- 민감한 개인 정보
- 개인 정보
정책 태그를 사용하면 BigQuery 테이블에서 민감한 열을 볼 수 있는 사용자를 제어할 수 있습니다. 이 아키텍처는 Sensitive Data Protection infoType에서 파생된 민감도 분류에 이러한 정책 태그를 매핑합니다. 예를 들어 sensitive_personal_identifiable_information 정책 태그와 민감한 카테고리는 AGE, DATE_OF_BIRTH, PHONE_NUMBER, EMAIL_ADDRESS와 같은 infoType에 매핑됩니다.
이 아키텍처는 Identity and Access Management(IAM)를 사용하여 데이터에 액세스해야 하는 그룹, 사용자, 서비스 계정을 관리합니다. 테이블 수준 액세스를 위해 지정된 애셋에 IAM 권한이 부여됩니다. 또한 정책 태그 기반의 열 수준 액세스는 민감한 정보 애셋에 대해 세부적인 액세스를 허용합니다. 기본적으로 사용자에게는 정의된 정책 태그가 포함된 열에 대한 액세스 권한이 없습니다.
인증된 사용자만 데이터에 액세스할 수 있도록 보장하기 위해Google Cloud 는 사용자 인증을 위해 기존 ID 공급업체와 제휴할 수 있는 Cloud ID를 사용합니다.
또한 이 제어를 사용하려면 아키텍처가 사용 권한이 정의되지 않은 데이터 애셋을 정기적으로 확인해야 합니다. Cloud Scheduler에서 관리되는 감지기는 다음 시나리오를 확인합니다.
- 데이터 애셋에 민감한 카테고리가 포함되지만 관련 정책 태그가 없습니다.
- 카테고리가 정책 태그와 일치하지 않습니다.
이러한 시나리오가 발생하면 감지기는 Pub/Sub에서 게시한 발견 항목을 생성한 다음 Dataflow에 의해 BigQuery의 events 테이블에 기록됩니다. 그런 후 1. 데이터 제어 규정 준수에 설명된 대로 교정 도구를 사용하여 발견 항목을 배포할 수 있습니다.
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- BigQuery 데이터 웨어하우스는 세부적인 액세스 제어를 위해 기밀 데이터 및 정책 태그 바인딩을 저장합니다.
- IAM은 액세스를 관리합니다.
- Data Catalog는 민감한 카테고리에 대해 테이블 수준 및 열 수준 태그를 저장합니다.
- 다음과 같은 2개의 Cloud Run 인스턴스:
- 한 인스턴스는 태그가 적용되었는지 확인하고 결과를 게시하는 Report Engine을 실행합니다.
- 또 다른 인스턴스는 보안 데이터 웨어하우스의 데이터에 태그를 지정하는 Tag Engine을 실행합니다.
이 제어와 관련된 문제를 감지하기 위해 아키텍처는 민감한 정보에 해당 정책 태그가 있는지 확인합니다.
8. 윤리적인 액세스, 사용, 데이터 결과 관리
이 제어를 사용하려면 아키텍처가 승인된 소비 목적 목록을 포함하여 데이터 제공업체와 데이터 소비자의 데이터 공유 계약을 모두 저장해야 합니다. 민감한 정보의 소비 용도는 쿼리 라벨을 사용하여 BigQuery에 저장된 사용 권한에 매핑됩니다.
소비자가 BigQuery에서 민감한 정보를 쿼리할 때는 해당 사용 권한과 일치하는 유효한 목적(예: SET @@query_label = “use:3”;)을 지정해야 합니다.
아키텍처는 Data Catalog를 사용하여 다음 태그를 CDMC controls 태그 템플릿에 추가합니다. 이러한 태그는 데이터 제공업체와의 데이터 공유 계약을 나타냅니다.
approved_use: 데이터 애셋의 승인된 사용 또는 사용자sharing_scope_geography: 데이터 애셋을 공유할 수 있는 지리적 위치 목록sharing_scope_legal_entity: 데이터 애셋을 공유할 수 있는 합의된 주체 목록
별개의 BigQuery 데이터 웨어하우스에 다음 테이블이 있는 entitlement_management 데이터 세트가 포함됩니다.
provider_agreement: 합의된 법인 및 지리적 범위를 포함하여 데이터 제공업체와의 데이터 공유 계약. 이 데이터는shared_scope_geography및sharing_scope_legal_entity태그의 기본값입니다.consumer_agreement: 합의된 법인 및 지리적 범위를 포함하여 데이터 소비자의 데이터 공유 계약. 각 계약은 데이터 애셋의 IAM 바인딩과 연결됩니다.use_purpose: 데이터 애셋의 사용 설명 및 허용되는 작업과 같은 소비 목적data_asset: 애셋 이름과 데이터 소유자 세부정보와 같은 데이터 애셋 관련 정보
데이터 공유 계약을 감사하기 위해 BigQuery는 각 데이터 세트에 따라 모든 작업 및 쿼리에 대해 전체 감사 추적을 유지합니다. 감사 추적은 BigQuery 정보 스키마 작업 뷰에 저장됩니다. 쿼리 라벨을 세션과 연결하고 세션 내에서 쿼리를 실행한 후에는 해당 쿼리 라벨이 있는 쿼리의 감사 로그를 수집할 수 있습니다. 자세한 내용은 BigQuery의 감사 로그 참조를 확인하세요.
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- BigQuery 데이터 웨어하우스 두 개: 하나는 기밀 데이터를 저장하고 다른 하나는 제공업체 및 소비자 데이터 공유 계약과 승인된 사용 목적을 포함하는 사용 권한 데이터를 저장합니다.
- Data Catalog는 제공업체 데이터 공유 계약 정보를 태그로 저장합니다.
- 다음과 같은 2개의 Cloud Run 인스턴스:
- 한 인스턴스는 태그가 적용되었는지 확인하고 결과를 게시하는 Report Engine을 실행합니다.
- 또 다른 인스턴스는 보안 데이터 웨어하우스의 데이터에 태그를 지정하는 Tag Engine을 실행합니다.
- Pub/Sub는 발견 항목을 게시합니다.
이 제어와 관련된 문제를 감지하기 위해 아키텍처에는 다음 발견 항목이 포함됩니다.
entitlement_management데이터 세트에 데이터 애셋에 대한 항목이 있는지 여부- 만료된 사용 사례가 있는 민감한 테이블에서 작업을 수행할지 여부(예:
consumer_agreement table의valid_until_date가 전달됨) - 민감한 테이블에서 잘못된 라벨 키를 사용하여 작업이 수행되는지 여부
- 민감한 테이블에서 비어 있거나 승인되지 않은 사용 사례 라벨 값을 사용하여 작업이 수행되는지 여부
- 승인되지 않은 작업 메서드(예:
SELECT또는INSERT)를 사용하여 민감한 테이블을 쿼리하는지 여부 - 민감한 정보를 쿼리할 때 소비자가 지정한 기록된 목적이 데이터 공유 계약과 일치하는지 여부
9. 데이터가 보호되고 제어가 입증됨
이 제어를 사용하려면 민감한 정보를 보호하고 이러한 제어 레코드를 제공하기 위해 데이터 암호화 및 익명화를 구현해야 합니다.
이 아키텍처는 저장 데이터 암호화가 포함된 Google 기본 보안을 기반으로 합니다. 또한 이 아키텍처를 사용하면 고객 관리 암호화 키(CMEK)를 사용하여 자체 키를 관리할 수 있습니다. Cloud KMS를 사용하면 소프트웨어 지원 암호화 키 또는 FIPS 140-2 Level 3 검증 하드웨어 보안 모듈(HSM)로 데이터를 암호화할 수 있습니다.
이 아키텍처는 정책 태그를 통해 구성된 열 수준 동적 데이터 마스킹을 사용하고 별개의 VPC 서비스 제어 경계 내에 기밀 데이터를 저장합니다. 또한 애플리케이션 수준의 익명화를 추가할 수 있으며, 온프레미스에서 또는 데이터 수집 파이프라인 중에 이를 구현할 수 있습니다.
기본적으로 아키텍처는 HSM으로 CMEK 암호화를 구현하지만 Cloud External Key Manager(Cloud EKM)도 지원합니다.
다음 표에서는 이 아키텍처가 us-central1 리전에 대해 구현하는 보안 정책 예시를 보여줍니다. 리전마다 다른 정책 추가를 포함하여 요구사항에 맞게 정책을 조정할 수 있습니다.
| 데이터 민감도 | 기본 암호화 방법 | 기타 허용되는 암호화 방법 | 기본 익명화 방법 | 기타 허용되는 익명화 방법 |
|---|---|---|---|---|
| 공개 정보 | 기본 암호화 | 모두 | 없음 | 모두 |
| 민감한 개인 식별 정보 | HSM을 사용한 CMEK | EKM | 무효화 | SHA-256 해시 또는 기본 마스킹 값 |
| 개인 식별 정보 | HSM을 사용한 CMEK | EKM | SHA-256 해시 | 무효화 또는 기본 마스킹 값 |
| 민감한 개인 정보 | HSM을 사용한 CMEK | EKM | 기본 마스킹 값 | SHA-256 해시 또는 무효화 |
| 개인 정보 | HSM을 사용한 CMEK | EKM | 기본 마스킹 값 | SHA-256 해시 또는 무효화 |
이 아키텍처는 Data Catalog를 사용하여 encryption_method 태그를 태그 수준 CDMC controls 태그 템플릿에 추가합니다. encryption_method는 데이터 애셋에서 사용하는 암호화 방법을 정의합니다.
또한 아키텍처는 특정 필드에 적용되는 익명화 방법을 식별하기 위해 security policy template 태그를 만듭니다. 이 아키텍처에는 동적 데이터 마스킹을 사용하여 적용되는 platform_deid_method가 사용됩니다. app_deid_method를 추가하고 보안 데이터 웨어하우스 청사진에 포함된 Dataflow 및 Sensitive Data Protection 데이터 수집 파이프라인을 사용하여 채울 수 있습니다.
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- Dataflow의 선택적 인스턴스 두 개: 하나는 애플리케이션 수준 익명화를 수행하고 다른 하나는 재식별을 수행합니다.
- BigQuery 데이터 웨어하우스 세 개: 하나는 기밀 데이터를 저장하고 다른 하나는 비기밀 데이터를 저장하고 세 번째는 보안 정책을 저장합니다.
- Data Catalog는 암호화 및 익명화 태그 템플릿을 저장합니다.
- 다음과 같은 2개의 Cloud Run 인스턴스:
- 한 인스턴스는 태그가 적용되었는지 확인하고 결과를 게시하는 Report Engine을 실행합니다.
- 또 다른 인스턴스는 보안 데이터 웨어하우스의 데이터에 태그를 지정하는 Tag Engine을 실행합니다.
- Pub/Sub 게시 발견 항목
이 제어와 관련된 문제를 감지하기 위해 아키텍처에는 다음 발견 항목이 포함됩니다.
- 암호화 방법 태그의 값이 지정된 민감도 및 위치에 허용되는 암호화 방법과 일치하지 않습니다.
- 테이블에 민감한 열이 포함되지만 보안 정책 템플릿 태그에 유효하지 않은 플랫폼 수준의 익명화 방법이 포함됩니다.
- 테이블에 민감한 열이 포함되지만 보안 정책 템플릿 태그가 누락되었습니다.
10. 데이터 개인 정보 보호 프레임워크가 정의되고 운영됨
이 제어를 사용하려면 아키텍처에서 Data Catalog 및 분류를 검사하여 데이터 보호 영향 평가(DPIA) 보고서 또는 개인 정보 보호 영향 평가(PIA) 보고서를 만들어야 하는지 결정해야 합니다. 개인 정보 보호 평가는 지역과 규제 기관에 따라 크게 달라집니다. 영향 평가가 필요한지 확인하려면 아키텍처가 데이터 상주와 정보주체의 상주를 고려해야 합니다.
아키텍처는 Data Catalog를 사용하여 다음 태그를 Impact assessment 태그 템플릿에 추가합니다.
subject_locations: 이 애셋의 데이터로 참조되는 주체의 위치입니다.is_dpia: 이 애셋에 대한 데이터 개인 정보 보호 영향 평가(DPIA)가 완료되었는지 여부입니다.is_pia: 이 애셋에 대한 개인 정보 보호 영향 평가(PIA)가 완료되었는지 여부입니다.impact_assessment_reports: 영향 평가 보고서가 저장되는 위치에 대한 외부 링크입니다.most_recent_assessment: 가장 최근의 영향 평가 날짜입니다.oldest_assessment: 첫 번째 영향 평가 날짜입니다.
Tag Engine은 제어 6에 정의된 대로 각각의 민감한 정보 애셋에 이러한 태그를 추가합니다. 감지기는 데이터 상주, 주체 위치, 데이터 민감도(예: PII인지 여부), 필요한 영향 평가 유형(PIA 또는 DPIA)의 유효한 조합을 포함하는 BigQuery의 정책 테이블에 따라 이러한 태그의 유효성을 검증합니다.
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- 4개의 BigQuery 데이터 웨어하우스에 다음 정보가 저장됩니다.
- 기밀 데이터
- 비기밀 데이터
- 영향 평가 정책 및 사용 권한 타임스탬프
- 대시보드에 사용되는 태그 내보내기
- Data Catalog는 태그 템플릿 내의 태그에 영향 평가 세부정보를 저장합니다.
- 다음과 같은 2개의 Cloud Run 인스턴스:
- 한 인스턴스는 태그가 적용되었는지 확인하고 결과를 게시하는 Report Engine을 실행합니다.
- 또 다른 인스턴스는 보안 데이터 웨어하우스의 데이터에 태그를 지정하는 Tag Engine을 실행합니다.
- Pub/Sub는 발견 항목을 게시합니다.
이 제어와 관련된 문제를 감지하기 위해 아키텍처에는 다음 발견 항목이 포함됩니다.
- 민감한 정보가 영향 평가 템플릿 없이 존재합니다.
- 민감한 정보가 DPIA 또는 PIA 보고서 링크 없이 존재합니다.
- 태그가 정책 테이블의 요구사항을 충족하지 않습니다.
- 영향 평가가 소비자 계약 테이블의 데이터 애셋에 대해 최근에 승인된 사용 권한보다 오래되었습니다.
11. 데이터 수명주기 계획 및 관리
이 제어를 사용하려면 데이터 수명 주기 정책이 있고 적용되는지 확인하기 위해 모든 데이터 애셋을 검사하는 기능이 필요합니다.
아키텍처는 Data Catalog를 사용하여 다음 태그를 CDMC controls 태그 템플릿에 추가합니다.
retention_period: 테이블을 보관하는 기간(일)expiration_action: 보관 기간이 종료될 때 테이블을 보관처리 또는 삭제할지 여부
기본적으로 아키텍처에는 다음 보관 기간 및 만료 작업이 사용됩니다.
| 데이터 카테고리 | 보관 기간(일) | 만료 작업 |
|---|---|---|
| 민감한 개인 식별 정보 | 60 | 삭제 |
| 개인 식별 정보 | 90 | 보관처리 |
| 민감한 개인 정보 | 180 | 보관처리 |
| 개인정보 | 180 | 보관처리 |
BigQuery용 오픈소스 애셋인 Record Manager는 위에 표시된 태그 값과 구성 파일을 기반으로 BigQuery 테이블의 삭제 및 보관처리를 자동화합니다. 삭제 절차는 테이블에 만료일 설정하고 Record Manager 구성에 정의된 만료 시간으로 스냅샷 테이블을 만듭니다. 기본적으로 만료 시간은 30일입니다. 소프트 삭제 기간 중에는 테이블을 복원할 수 있습니다. 보관 절차 중에는 보관 기간을 경과하는 각 BigQuery 테이블에 대해 외부 테이블이 생성됩니다. 이 테이블은 Cloud Storage에 parquet 형식으로 저장되며 Data Catalog의 메타데이터를 사용하여 외부 파일에 태그 지정을 허용하는 BigLake 테이블로 업그레이드됩니다.
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- BigQuery 데이터 웨어하우스 2개: 하나는 기밀 데이터를 저장하고 다른 하나는 데이터 보관 정책을 저장합니다.
- Cloud Storage 인스턴스 두 개: 하나는 아카이브 스토리지를 제공하고 다른 하나는 레코드를 저장합니다.
- Data Catalog는 태그 템플릿 및 태그에 보관 기간 및 작업을 저장합니다.
- Cloud Run 인스턴스 2개: 하나는 Record Manager를 실행하고 다른 하나는 감지기를 배포합니다.
- 다음과 같은 Cloud Run 인스턴스 3개:
- 한 인스턴스는 태그가 적용되었는지 확인하고 결과를 게시하는 Report Engine을 실행합니다.
- 또 다른 인스턴스는 보안 데이터 웨어하우스의 데이터에 태그를 지정하는 Tag Engine을 실행합니다.
- 또 다른 인스턴스는 BigQuery 테이블의 삭제 및 보관처리를 자동화하는 Record Manager를 실행합니다.
- Pub/Sub는 발견 항목을 게시합니다.
이 제어와 관련된 문제를 감지하기 위해 아키텍처에는 다음 발견 항목이 포함됩니다.
- 민감한 애셋의 경우 보관 방법이 애셋 위치의 정책과 일치하는지 확인합니다.
- 민감한 애셋의 경우 보관 기간이 애셋 위치의 정책과 일치하는지 확인합니다.
12. 데이터 품질 관리됨
이 제어를 사용하려면 데이터 프로파일링 또는 사용자 정의 측정항목을 기반으로 데이터 품질을 측정할 수 있는 기능이 필요합니다.
아키텍처에는 개별 값 또는 집계 값에 대한 데이터 품질 규칙을 정의하고 특정 테이블 열에 기준점을 할당할 수 있는 기능이 포함되어 있습니다. 여기에는 정확성 및 완전성에 대한 태그 템플릿이 포함됩니다. Data Catalog는 각 태그 템플릿에 다음 태그를 추가합니다.
column_name: 측정항목이 적용되는 열의 이름metric: 측정항목 또는 품질 규칙의 이름rows_validated: 검증된 행 수success_percentage: 이 측정항목을 충족하는 값의 비율acceptable_threshold: 이 측정항목에 허용되는 기준meets_threshold: 품질평가점수(success_percentage값)가 허용되는 기준을 충족하는지 여부most_recent_run: 측정항목 또는 품질 규칙이 실행된 최근 시간
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- BigQuery 데이터 웨어하우스 세 개: 하나는 민감한 정보를 저장하고, 다른 하나는 민감하지 않은 데이터를 저장하고, 세 번째는 품질 규칙 측정항목을 저장합니다.
- Data Catalog는 태그 템플릿 및 태그에 데이터 품질 결과를 저장합니다.
- Cloud Scheduler는 Cloud Data Quality Engine이 실행되는 시점을 정의합니다.
- 다음과 같은 Cloud Run 인스턴스 3개:
- 한 인스턴스는 태그가 적용되었는지 확인하고 결과를 게시하는 Report Engine을 실행합니다.
- 또 다른 인스턴스는 보안 데이터 웨어하우스의 데이터에 태그를 지정하는 Tag Engine을 실행합니다.
- 세 번째 인스턴스는 Cloud Data Quality Engine을 실행합니다.
- Cloud Data Quality Engine은 데이터 품질 규칙을 정의하고 테이블 및 열의 데이터 품질 검사를 예약합니다.
- Pub/Sub는 발견 항목을 게시합니다.
Looker Studio 대시보드에는 테이블 수준 및 열 수준 모두의 데이터 품질 보고서가 표시됩니다.
이 제어와 관련된 문제를 감지하기 위해 아키텍처에는 다음 발견 항목이 포함됩니다.
- 데이터가 민감하지만 데이터 품질 태그 템플릿이 적용되지 않았습니다(정확성 및 완전성).
- 데이터가 민감하지만 데이터 품질 태그가 민감한 열에 적용되지 않았습니다.
- 데이터는 민감하지만 데이터 품질 결과가 규칙에 설정된 기준점 내에 있지 않습니다.
- 데이터는 민감하지 않으며 데이터 품질 결과가 규칙에 의해 설정된 기준점 내에 있지 않습니다.
Cloud Data Quality Engine의 대안으로 Dataplex Universal Catalog 데이터 품질 태스크를 구성할 수 있습니다.
13. 비용 관리 원칙 수립 및 적용됨
이 제어를 사용하려면 데이터 애셋을 검사하여 정책 요구사항 및 데이터 아키텍처를 기반으로 비용 사용량을 확인하는 기능이 필요합니다. 비용 측정항목은 포괄적이어야 하며 스토리지 사용 및 이동으로만 제한되지 않아야 합니다.
아키텍처는 Data Catalog를 사용하여 다음 태그를 cost_metrics 태그 템플릿에 추가합니다.
total_query_bytes_billed: 이번 달 초부터 이 데이터 애셋에 청구된 총 쿼리 바이트 수입니다.total_storage_bytes_billed: 이번 달 초부터 이 데이터 애셋에 청구된 총 스토리지 바이트 수입니다.total_bytes_transferred: 이 데이터 애셋으로 리전 간 전송된 바이트의 합계입니다.estimated_query_cost: 이번 달 데이터 애셋의 예상 쿼리 비용입니다(미국 달러).estimated_storage_cost: 이번 달 데이터 애셋의 예상 스토리지 비용입니다(미국 달러).estimated_egress_cost: 데이터 애셋이 대상 테이블로 사용된 이번 달의 예상 이그레스(미국 달러)입니다.
이 아키텍처는 Cloud Billing에서 cloud_pricing_export라는 BigQuery 테이블로 가격 책정 정보를 내보냅니다.
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- Cloud Billing은 결제 정보를 제공합니다.
- Data Catalog는 태그 템플릿 및 태그에 비용 정보를 저장합니다.
- BigQuery는 내보낸 가격 책정 정보와 기본 제공 INFORMATION_SCHEMA 뷰를 통해 쿼리 기록 작업 정보를 저장합니다.
- 다음과 같은 2개의 Cloud Run 인스턴스:
- 한 인스턴스는 태그가 적용되었는지 확인하고 결과를 게시하는 Report Engine을 실행합니다.
- 또 다른 인스턴스는 보안 데이터 웨어하우스의 데이터에 태그를 지정하는 Tag Engine을 실행합니다.
- Pub/Sub는 발견 항목을 게시합니다.
이 제어와 관련된 문제를 감지하기 위해 아키텍처는 연관된 비용 측정항목이 없는 민감한 정보 애셋이 있는지 확인합니다.
14. 데이터 출처 및 계보 이해
이 제어를 사용하려면 소스에서 데이터 애셋의 추적 가능성을 검사하고 데이터 애셋 계보의 변경사항을 검사하는 기능이 필요합니다.
데이터 출처 및 계보에 대한 정보를 유지하기 위해 이 아키텍처는 Data Catalog에 기본 제공 데이터 계보 기능을 사용합니다. 또한 데이터 수집 스크립트는 최종 소스를 정의하고 이 소스를 데이터 계보 그래프의 새 노드로 추가합니다.
이 제어의 요구사항을 충족하기 위해 아키텍처는 Data Catalog를 사용하여 ultimate_source 태그를 CDMC
controls 태그 템플릿에 추가합니다. ultimate_source 태그는 이 데이터 애셋의 소스를 정의합니다.
다음 다이어그램은 이 제어에 적용되는 서비스를 보여줍니다.

이 제어의 요구사항을 충족하기 위해 아키텍처는 다음 서비스를 사용합니다.
- BigQuery 데이터 웨어하우스 2개: 하나는 기밀 데이터를 저장하고 다른 하나는 최종 데이터 소스를 저장합니다.
- Data Catalog는 태그 템플릿 및 태그에 최종 소스를 저장합니다.
- 데이터 수집 스크립트는 Cloud Storage에서 데이터를 로드하고, 최종 소스를 정의하고, 이 소스를 데이터 계보 그래프에 추가합니다.
- 다음과 같은 2개의 Cloud Run 인스턴스:
- 한 인스턴스는 태그가 적용되었는지 확인하고 결과를 게시하는 Report Engine을 실행합니다.
- 또 다른 인스턴스는 보안 데이터 웨어하우스의 데이터에 태그를 지정하는 Tag Engine을 실행합니다.
- Pub/Sub는 발견 항목을 게시합니다.
이 제어와 관련된 문제를 감지하기 위해 아키텍처에는 다음 검사가 포함됩니다.
- 민감한 정보가 최종 소스 태그 없이 식별되었습니다.
- 민감한 정보 애셋의 계보 그래프가 채워지지 않았습니다.
태그 참조
이 섹션에서는 이 아키텍처에서 CDMC 키 제어 요구사항을 충족하기 위해 사용되는 태그 템플릿 및 태그에 대해 설명합니다.
테이블 수준 CDMC 제어 태그 템플릿
다음 표에서는 CDMC 제어 태그 템플릿에 속하고 테이블에 적용되는 태그를 보여줍니다.
| 태그 | 태그 ID | 관련 키 제어 |
|---|---|---|
| 승인된 스토리지 위치 | approved_storage_location |
4 |
| 승인된 사용 | approved_use |
8 |
| 데이터 소유자 이메일 | data_owner_email |
2 |
| 데이터 소유자 이름 | data_owner_name |
2 |
| 암호화 방법 | encryption_method |
9 |
| 만료 작업 | expiration_action |
11 |
| 권한 있음 | is_authoritative |
3 |
| 민감성 여부 | is_sensitive |
6 |
| 민감한 카테고리 | sensitive_category |
6 |
| 공유 범위 지역 | sharing_scope_geography |
8 |
| 공유 범위 법인 | sharing_scope_legal_entity |
8 |
| 보관 기간 | retention_period |
11 |
| 최종 소스 | ultimate_source |
14 |
영향 평가 태그 템플릿
다음 표에서는 영향 평가 태그 템플릿에 속하고 테이블에 적용되는 태그를 보여줍니다.
| 태그 | 태그 ID | 관련 키 제어 |
|---|---|---|
| 주체 위치 | subject_locations |
10 |
| DPIA 영향 평가 여부 | is_dpia |
10 |
| PIA 영향 평가 여부 | is_pia |
10 |
| 영향 평가 보고서 | impact_assessment_reports |
10 |
| 최근 영향 평가 | most_recent_assessment |
10 |
| 가장 오래된 영향 평가 | oldest_assessment |
10 |
비용 측정항목 태그 템플릿
다음 표에서는 비용 측정항목 태그 템플릿에 속하고 테이블에 적용되는 태그를 보여줍니다.
| 태그 | 탭 ID | 관련 키 제어 |
|---|---|---|
| 예상 쿼리 비용 | estimated_query_cost |
13 |
| 예상 스토리지 비용 | estimated_storage_cost |
13 |
| 예상 이그레스 비용 | estimated_egress_cost |
13 |
| 청구된 총 쿼리 바이트 | total_query_bytes_billed |
13 |
| 청구된 총 스토리지 바이트 수 | total_storage_bytes_billed |
13 |
| 전송된 총 바이트 | total_bytes_transferred |
13 |
데이터 민감도 태그 템플릿
다음 표에서는 데이터 민감도 태그 템플릿에 속하고 필드에 적용되는 태그를 보여줍니다.
| 태그 | 태그 ID | 관련 키 제어 |
|---|---|---|
| 민감한 필드 | sensitive_field |
6 |
| 민감한 유형 | sensitive_category |
6 |
보안 정책 태그 템플릿
다음 표에서는 보안 정책 태그 템플릿에 속하고 필드에 적용되는 태그를 보여줍니다.
| 태그 | 태그 ID | 관련 키 제어 |
|---|---|---|
| 애플리케이션 익명화 방법 | app_deid_method |
9 |
| 플랫폼 익명화 방법 | platform_deid_method |
9 |
데이터 품질 태그 템플릿
다음 표에서는 완전성 및 정확성 데이터 품질 태그 템플릿에 속하고 필드에 적용되는 태그를 보여줍니다.
| 태그 | 태그 ID | 관련 키 제어 |
|---|---|---|
| 허용 가능한 기준점 | acceptable_threshold |
12 |
| 열 이름 | column_name |
12 |
| 기준점 충족 | meets_threshold |
12 |
| 측정항목 | metric |
12 |
| 최근 실행 | most_recent_run |
12 |
| 검증된 행 | rows_validated |
12 |
| 성공률 | success_percentage |
12 |
필드 수준 CDMC 정책 태그
다음 표에는 CDMC 민감한 정보 분류 정책 태그 분류에 속하고 필드에 적용되는 정책 태그가 나와 있습니다. 이러한 정책 태그는 필드 수준 액세스를 제한하고 플랫폼 수준 데이터 익명화를 사용 설정합니다.
| 데이터 분류 | 태그 이름 | 관련 키 제어 |
|---|---|---|
| 개인 식별 정보 | personal_identifiable_information |
7 |
| 개인 정보 | personal_information |
7 |
| 민감한 개인 식별 정보 | sensitive_personal_identifiable_information |
7 |
| 민감한 개인 정보 | sensitive_personal_data |
7 |
자동 입력된 기술 메타데이터
다음 표에서는 모든 BigQuery 데이터 애셋에 대해 기본적으로 Data Catalog에서 동기화되는 기술 메타데이터를 보여줍니다.
| 메타데이터 | 관련 키 제어 |
|---|---|
| 애셋 유형 | — |
| 생성 시간 | — |
| 만료 시간 | 11 |
| 위치 | 4 |
| 리소스 URL | 3 |
다음 단계
- CDMC 자세히 알아보기
- 보안 데이터 웨어하우스 청사진에 사용되는 보안 제어 수단 알아보기
- Data Catalog 둘러보기
- Dataplex Universal Catalog 자세히 알아보기
- Tag Engine 자세히 알아보기
- GitHub에서 Google Cloud CDMC 참조 아키텍처를 사용하여 이 솔루션 구현