이 주제에서는 Sensitive Data Protection을 사용하여 데이터 세트의 k-익명성을 측정하고 Looker Studio에서 이를 시각화하는 방법을 보여줍니다. 이렇게 하면 위험을 더 정확히 파악하고, 데이터를 수정 또는 익명화하는 경우 감수해야 하는 유용성 측면의 타협을 평가하는 데 도움이 됩니다.
이 주제는 주로k-익명성 재식별 위험 분석 측정항목의 시각화에 대해 다루지만 같은 방법을 사용하여 l -다양성 측정항목도 시각화할 수 있습니다.
이 주제에서는 사용자가 k-익명성의 개념과 데이터 세트 내에서 레코드의 재식별성을 평가하는 이유를 이미 잘 알고 있다고 가정합니다. 또한 Sensitive Data Protection을 사용한 k-익명성 계산 방법과 Looker Studio 사용 방법도 최소한 어느 정도 알고 있는 것이 좋습니다.
소개
익명화 기법은 데이터를 처리 또는 사용하는 중에 대상의 개인정보를 보호하는 데 유용할 수 있습니다. 그러나 데이터 세트가 충분히 익명화되었는지 여부를 어떻게 알 수 있을까요? 또한 익명화가 사용 사례 측면에서 지나치게 많은 데이터 손실로 이어졌는지 여부는 어떻게 알 수 있을까요? 즉, 데이터 기반의 의사 결정을 내리려면 재식별성 위험과 데이터의 유용성을 어떻게 비교해야 할까요?
데이터 세트의 k-익명성 값을 계산하면 데이터 세트 레코드의 재식별성을 평가하여 이러한 질문에 대한 답을 찾는 데 도움이 됩니다. Sensitive Data Protection에는 개발자가 지정한 유사 식별자를 기준으로 데이터 세트의 k-익명성 값을 계산하는 기본 제공 기능이 포함되어 있습니다. 이 기능을 사용하면 특정 열 또는 열 조합의 익명화로 얻게 되는 데이터 세트가 재식별될 가능성이 높은지 또는 낮은지 신속하게 평가할 수 있습니다.
데이터 세트 예시
다음은 대용량 데이터 세트 예시의 처음 몇 행입니다.
user_id |
age |
title |
score |
|---|---|---|---|
602-61-8588 |
24 |
Biostatistician III |
733 |
771-07-8231 |
46 |
Executive Secretary |
672 |
618-96-2322 |
69 |
Programmer I |
514 |
... |
... |
... |
... |
이 튜토리얼에서는 유사 식별자에 중점을 두므로 user_id에 대해서는 다루지 않습니다. 실제 시나리오에서는 user_id를 적절히 수정하거나 토큰화해야 합니다. score 열은 이 데이터 세트에 독점적으로 사용되는 열이며 공격자가 다른 수단을 통해 습득할 가능성이 낮으므로 분석에 포함하지 않습니다. 여기서는 남은 age 및 title 열에 집중합니다. 공격자는 이 두 열을 사용하여 다른 데이터 소스를 통해 개인에 대해 알아낼 가능성이 있습니다. 이 데이터 세트와 관련하여 답을 찾아야 하는 질문은 다음과 같습니다.
- 두 개의 유사 식별자(
age및title)는 익명화된 데이터의 전체적인 재식별 위험에 어떤 영향을 미치나요? - 익명화 변환 적용은 이 위험에 어떤 영향을 미치나요?
age와 title의 조합이 소수의 사용자 그룹으로 연결되지 않도록 해야 합니다. 예를 들어 데이터 세트에 직무가 프로그래머 I이고 69세인 사용자가 단 한 명이라고 가정해 보겠습니다. 공격자는 이 정보를 인구통계 또는 다른 가용 정보와 교차 참조하여 그 사람이 누구인지 알아내고 score의 가치를 확인할 수 있습니다.
이 현상에 대한 자세한 내용은 위험 분석 개념 주제의 '항목 ID 및 k-익명성 계산' 섹션을 참조하세요.
1단계 : 데이터 세트의 k-익명성 계산
먼저 Sensitive Data Protection에서 다음 JSON을 DlpJob 리소스에 전송하여 데이터 세트의 k-익명성을 계산합니다. 이 JSON 내에서 항목 ID를 user_id 열로 설정하고 두 개의 유사 식별자를 age 및 title 열로 모두 식별합니다. 또한 Sensitive Data Protection이 결과를 새 BigQuery 테이블에 저장하도록 지정합니다.
JSON 입력:
POST https://dlp.googleapis.com/v2/projects/dlp-demo-2/dlpJobs
{
"riskJob": {
"sourceTable": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "dlp_test_data_kanon"
},
"privacyMetric": {
"kAnonymityConfig": {
"entityId": {
"field": {
"name": "id"
}
},
"quasiIds": [
{
"name": "age"
},
{
"name": "job_title"
}
]
}
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "test_results"
}
}
}
}
]
}
}
k-익명성 작업이 완료되면 Sensitive Data Protection이 작업 결과를 dlp-demo-2.dlp_testing.test_results라는 BigQuery 테이블로 보냅니다.
2단계: 결과를 Looker Studio에 연결
다음으로, 1단계에서 생성한 BigQuery 테이블을 Looker Studio의 새 보고서에 연결합니다.
Looker Studio를 엽니다.
만들기 > 보고서를 클릭합니다.
보고서에 데이터 추가 창에서 데이터에 연결 아래 BigQuery를 클릭합니다. BigQuery 테이블에 액세스하도록 Looker Studio를 승인해야 할 수도 있습니다.
열 선택기에서 내 프로젝트를 선택합니다. 그런 다음 프로젝트, 데이터 세트, 테이블을 선택합니다. 완료되었으면 추가를 클릭합니다. 이 보고서에 데이터를 추가하라는 알림이 표시되면 보고서에 추가를 클릭합니다.
이제 k-익명성 스캔 결과가 새 데이터 Looker Studio에 추가되었습니다. 다음 단계에서는 차트를 만듭니다.
3단계: 차트 만들기
차트를 삽입하고 구성하려면 다음 안내를 따르세요.
- Looker Studio에 값 테이블이 나타나면 해당 테이블을 선택하고 삭제를 눌러 삭제합니다.
- 삽입 메뉴에서 콤보 차트를 클릭합니다.
- 차트를 표시할 캔버스에서 클릭하여 사각형을 그립니다.
다음으로 데이터 탭에서 차트 데이터를 구성하여 버킷의 다양한 크기 및 값 범위의 효과가 차트에 표시되도록 합니다.
- 아래와 같이 각 필드를 가리키고 X를 클릭하여 다음 제목 아래의 필드를 지웁니다.
- 기간 측정기준
- 측정기준
- 측정항목
- 정렬
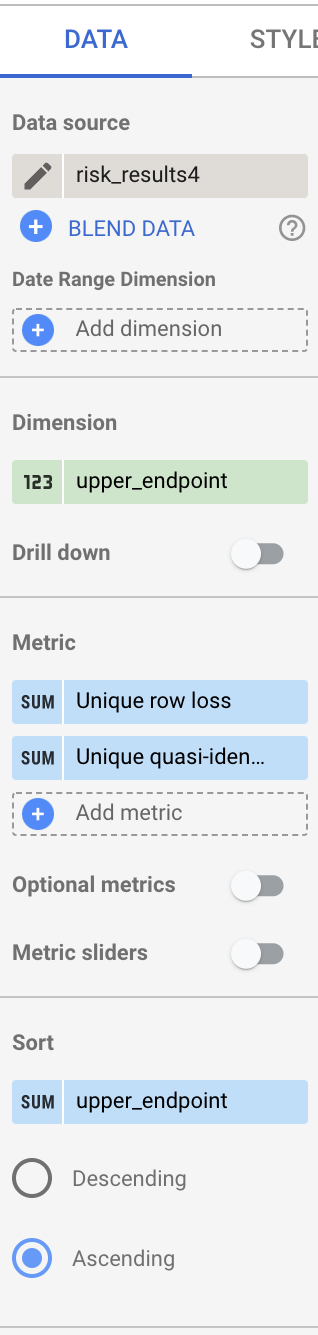
- 모든 필드가 비어 있으면 사용 가능한 필드 열에서 upper_endpoint 필드를 측정기준 제목으로 드래그합니다.
- upper_endpoint 필드를 정렬 제목으로 드래그한 다음 오름차순을 선택합니다.
- bucket_size 및 bucket_value_count 필드를 모두 측정항목 제목으로 드래그합니다.
- bucket_size 측정항목 왼쪽의 아이콘을 가리키면 수정 아이콘이 표시됩니다.
수정 아이콘을 클릭한 후 다음을 실행합니다.
- 이름 필드에
Unique row loss를 입력합니다. - 유형 아래에서 백분율을 선택합니다.
- 비교 계산에서 전체 대비 비율을 선택합니다.
- 계산 실행 아래에서 합계 실행을 선택합니다.
- 이름 필드에
- bucket_value_count 측정항목의 이전 단계를 반복하되 이름 필드에
Unique quasi-identifier combination loss를 입력합니다.
마치면 열은 다음과 같이 표시됩니다.
마지막으로, 차트를 구성하여 두 측정항목의 선 차트를 표시합니다.
- 창 오른쪽에서 스타일 탭을 클릭합니다.
- 계열 #1과 계열 #2에서 모두 선을 선택합니다.
- 최종 차트를 보려면 창 오른쪽 상단의 보기 버튼을 클릭합니다.
다음은 위의 단계를 완료한 차트 예시입니다.
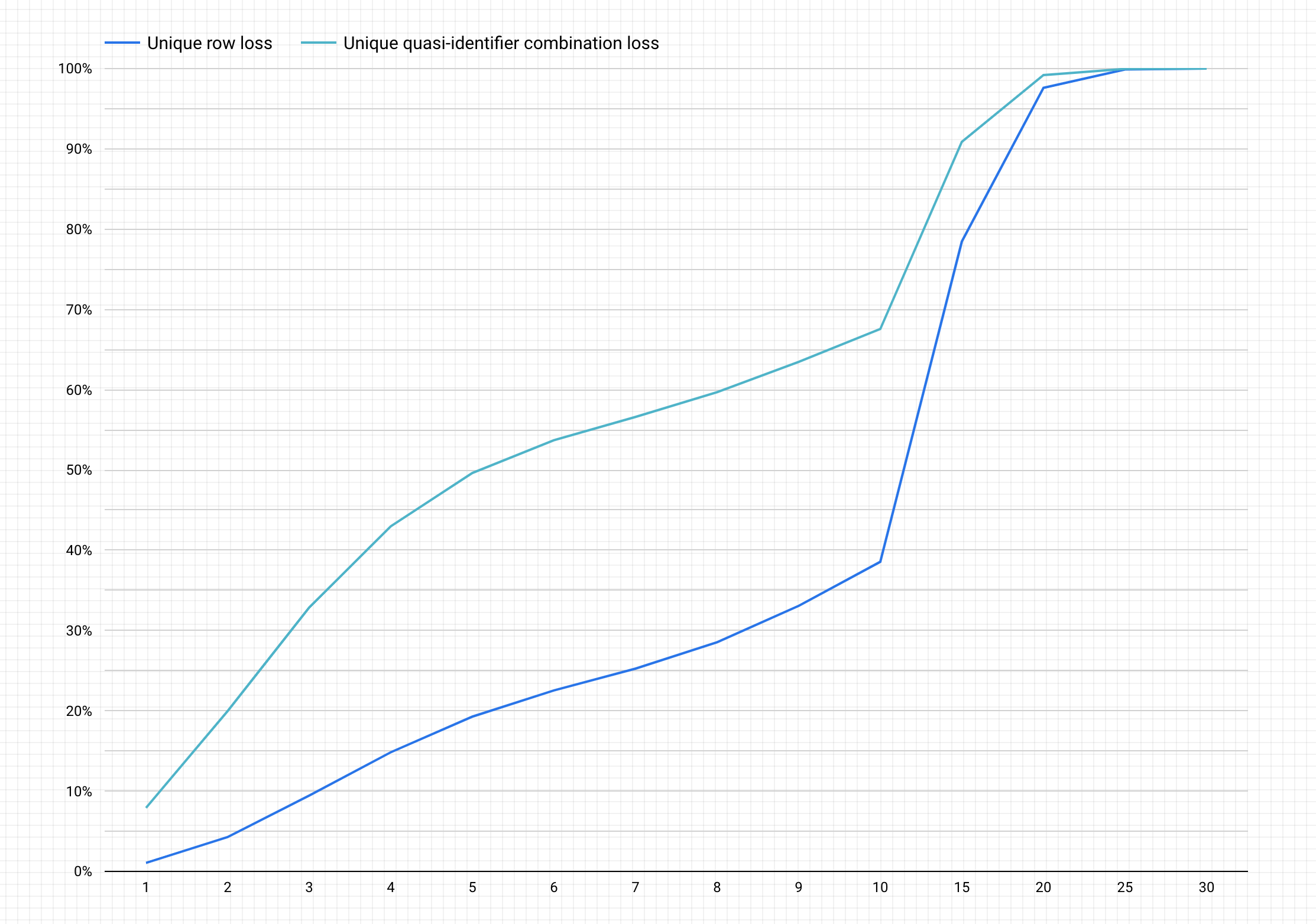
차트 해석
생성된 차트에서 y축은 고유 행과 고유 유사 식별자 조합에 대한 데이터 손실의 잠재적 비율을 나타내고 x축은 k-익명성 값을 나타냅니다.
k-익명성 값이 높으면 재식별 위험이 줄어듭니다. 그러나 k-익명성 값을 높이려면 총 행의 높은 비율과 높은 고유 유사 식별자 조합을 삭제해야 할 수 있으며 이는 데이터의 유용성을 낮춥니다.
다행히 데이터 삭제가 재식별 위험을 줄일 수 있는 유일한 방법은 아닙니다. 다른 익명화 기술로 손실과 유용성 간의 균형을 더 적절히 맞출 수 있습니다. 예를 들어 높은 k-익명성 값 및 이 데이터 세트와 관련된 데이터 손실의 문제를 해결하려면 연령 또는 직무를 버케팅하여 연령/직무 조합의 고유성을 낮출 수 있습니다. 예를 들어 20~25, 25~30, 30~35 등의 범위로 연령 버케팅을 시도할 수 있습니다. 그 방법에 대한 자세한 내용은 일반화 및 버케팅과 텍스트 콘텐츠의 민감한 정보 익명화를 참조하세요.