K-익명성은 레코드의 재식별성을 나타내는 데이터 세트의 속성입니다. 데이터 세트에 있는 각 개인의 유사 식별자가 동일한 데이터 세트에 있는 최소 k – 1명의 다른 사람과 동일한 경우 해당 데이터 세트는 k-익명성을 가집니다.
데이터 세트의 하나 이상의 열 또는 필드를 기준으로 k-익명성 값을 계산할 수 있습니다. 이 주제에서는 Sensitive Data Protection을 사용하여 데이터 세트의 k-익명성 값을 계산하는 방법을 보여줍니다. 계속 진행하기 전에 k-익명성 또는 일반 위험 분석에 대한 자세한 내용은 위험 분석 개념 주제를 참조하세요.
시작하기 전에
계속하기 전에 다음 작업을 완료했는지 확인하세요.
- Google 계정으로 로그인합니다.
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다. 프로젝트 선택기로 이동
- Google Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
- Sensitive Data Protection을 사용 설정합니다. Sensitive Data Protection 사용 설정
- 분석할 BigQuery 데이터 세트를 선택합니다. Sensitive Data Protection은 BigQuery 테이블을 스캔하여 k-익명성 측정항목을 계산합니다.
- 데이터 세트에서 식별자(해당되는 경우)와 하나 이상의 유사 식별자를 확인합니다. 자세한 내용은 위험 분석 용어 및 기법을 참조하세요.
k-익명성 계산
Sensitive Data Protection은 위험 분석 작업이 실행될 때마다 위험 분석을 수행합니다. 먼저 Google Cloud 콘솔을 사용하거나 DLP API 요청을 전송하거나 Sensitive Data Protection 클라이언트 라이브러리를 사용하여 작업을 만들어야 합니다.
콘솔
Google Cloud 콘솔에서 위험 분석 만들기 페이지로 이동합니다.
입력 데이터 선택 섹션에서 테이블이 포함된 프로젝트의 프로젝트 ID, 테이블의 데이터세트 ID, 테이블 이름을 입력하여 스캔할 BigQuery 테이블을 지정합니다.
계산할 개인정보 보호 측정항목에서 k-익명성을 선택합니다.
작업 ID 섹션에서 작업에 커스텀 식별자를 제공하고 Sensitive Data Protection이 데이터를 처리할 리소스 위치를 선택할 수 있습니다. 완료되었으면 계속을 클릭합니다.
필드 정의 섹션에서 k-익명성 위험 작업의 식별자 및 유사 식별자를 지정합니다. Sensitive Data Protection은 이전 단계에서 지정한 BigQuery 테이블의 메타데이터에 액세스하고 필드 목록을 채우려고 시도합니다.
- 적절한 체크박스를 선택하여 필드를 식별자(ID) 또는 유사 식별자(QI)로 지정합니다. 0개 또는 1개의 식별자와 1개 이상의 유사 식별자를 선택해야 합니다.
- Sensitive Data Protection에서 필드를 채울 수 없으면 필드 이름 입력을 클릭하여 필드를 하나 이상 직접 입력하고 각 필드를 식별자나 유사 식별자로 설정합니다. 완료되었으면 계속을 클릭합니다.
작업 추가 섹션에서 위험 작업이 완료되면 수행할 작업(선택사항)을 추가할 수 있습니다. 사용 가능한 옵션은 다음과 같습니다.
- BigQuery에 저장: 위험 분석 스캔의 결과를 BigQuery 테이블에 저장합니다.
Pub/Sub에 게시: Pub/Sub 주제에 알림을 게시합니다.
이메일로 알림: 결과가 포함된 이메일을 전송합니다. 완료되면 만들기를 클릭합니다.
k-익명성 위험 분석 작업이 즉시 시작됩니다.
C#
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
using Google.Api.Gax.ResourceNames;
using Google.Cloud.Dlp.V2;
using Google.Cloud.PubSub.V1;
using Newtonsoft.Json;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
using static Google.Cloud.Dlp.V2.Action.Types;
using static Google.Cloud.Dlp.V2.PrivacyMetric.Types;
public class RiskAnalysisCreateKAnonymity
{
public static AnalyzeDataSourceRiskDetails.Types.KAnonymityResult KAnonymity(
string callingProjectId,
string tableProjectId,
string datasetId,
string tableId,
string topicId,
string subscriptionId,
IEnumerable<FieldId> quasiIds)
{
var dlp = DlpServiceClient.Create();
// Construct + submit the job
var KAnonymityConfig = new KAnonymityConfig
{
QuasiIds = { quasiIds }
};
var config = new RiskAnalysisJobConfig
{
PrivacyMetric = new PrivacyMetric
{
KAnonymityConfig = KAnonymityConfig
},
SourceTable = new BigQueryTable
{
ProjectId = tableProjectId,
DatasetId = datasetId,
TableId = tableId
},
Actions =
{
new Google.Cloud.Dlp.V2.Action
{
PubSub = new PublishToPubSub
{
Topic = $"projects/{callingProjectId}/topics/{topicId}"
}
}
}
};
var submittedJob = dlp.CreateDlpJob(
new CreateDlpJobRequest
{
ParentAsProjectName = new ProjectName(callingProjectId),
RiskJob = config
});
// Listen to pub/sub for the job
var subscriptionName = new SubscriptionName(callingProjectId, subscriptionId);
var subscriber = SubscriberClient.CreateAsync(
subscriptionName).Result;
// SimpleSubscriber runs your message handle function on multiple
// threads to maximize throughput.
var done = new ManualResetEventSlim(false);
subscriber.StartAsync((PubsubMessage message, CancellationToken cancel) =>
{
if (message.Attributes["DlpJobName"] == submittedJob.Name)
{
Thread.Sleep(500); // Wait for DLP API results to become consistent
done.Set();
return Task.FromResult(SubscriberClient.Reply.Ack);
}
else
{
return Task.FromResult(SubscriberClient.Reply.Nack);
}
});
done.Wait(TimeSpan.FromMinutes(10)); // 10 minute timeout; may not work for large jobs
subscriber.StopAsync(CancellationToken.None).Wait();
// Process results
var resultJob = dlp.GetDlpJob(new GetDlpJobRequest
{
DlpJobName = DlpJobName.Parse(submittedJob.Name)
});
var result = resultJob.RiskDetails.KAnonymityResult;
for (var bucketIdx = 0; bucketIdx < result.EquivalenceClassHistogramBuckets.Count; bucketIdx++)
{
var bucket = result.EquivalenceClassHistogramBuckets[bucketIdx];
Console.WriteLine($"Bucket {bucketIdx}");
Console.WriteLine($" Bucket size range: [{bucket.EquivalenceClassSizeLowerBound}, {bucket.EquivalenceClassSizeUpperBound}].");
Console.WriteLine($" {bucket.BucketSize} unique value(s) total.");
foreach (var bucketValue in bucket.BucketValues)
{
// 'UnpackValue(x)' is a prettier version of 'x.toString()'
Console.WriteLine($" Quasi-ID values: [{String.Join(',', bucketValue.QuasiIdsValues.Select(x => UnpackValue(x)))}]");
Console.WriteLine($" Class size: {bucketValue.EquivalenceClassSize}");
}
}
return result;
}
public static string UnpackValue(Value protoValue)
{
var jsonValue = JsonConvert.DeserializeObject<Dictionary<string, object>>(protoValue.ToString());
return jsonValue.Values.ElementAt(0).ToString();
}
}
Go
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
import (
"context"
"fmt"
"io"
"strings"
"time"
dlp "cloud.google.com/go/dlp/apiv2"
"cloud.google.com/go/dlp/apiv2/dlppb"
"cloud.google.com/go/pubsub"
)
// riskKAnonymity computes the risk of the given columns using K Anonymity.
func riskKAnonymity(w io.Writer, projectID, dataProject, pubSubTopic, pubSubSub, datasetID, tableID string, columnNames ...string) error {
// projectID := "my-project-id"
// dataProject := "bigquery-public-data"
// pubSubTopic := "dlp-risk-sample-topic"
// pubSubSub := "dlp-risk-sample-sub"
// datasetID := "nhtsa_traffic_fatalities"
// tableID := "accident_2015"
// columnNames := "state_number" "county"
ctx := context.Background()
client, err := dlp.NewClient(ctx)
if err != nil {
return fmt.Errorf("dlp.NewClient: %w", err)
}
// Create a PubSub Client used to listen for when the inspect job finishes.
pubsubClient, err := pubsub.NewClient(ctx, projectID)
if err != nil {
return err
}
defer pubsubClient.Close()
// Create a PubSub subscription we can use to listen for messages.
// Create the Topic if it doesn't exist.
t := pubsubClient.Topic(pubSubTopic)
topicExists, err := t.Exists(ctx)
if err != nil {
return err
}
if !topicExists {
if t, err = pubsubClient.CreateTopic(ctx, pubSubTopic); err != nil {
return err
}
}
// Create the Subscription if it doesn't exist.
s := pubsubClient.Subscription(pubSubSub)
subExists, err := s.Exists(ctx)
if err != nil {
return err
}
if !subExists {
if s, err = pubsubClient.CreateSubscription(ctx, pubSubSub, pubsub.SubscriptionConfig{Topic: t}); err != nil {
return err
}
}
// topic is the PubSub topic string where messages should be sent.
topic := "projects/" + projectID + "/topics/" + pubSubTopic
// Build the QuasiID slice.
var q []*dlppb.FieldId
for _, c := range columnNames {
q = append(q, &dlppb.FieldId{Name: c})
}
// Create a configured request.
req := &dlppb.CreateDlpJobRequest{
Parent: fmt.Sprintf("projects/%s/locations/global", projectID),
Job: &dlppb.CreateDlpJobRequest_RiskJob{
RiskJob: &dlppb.RiskAnalysisJobConfig{
// PrivacyMetric configures what to compute.
PrivacyMetric: &dlppb.PrivacyMetric{
Type: &dlppb.PrivacyMetric_KAnonymityConfig_{
KAnonymityConfig: &dlppb.PrivacyMetric_KAnonymityConfig{
QuasiIds: q,
},
},
},
// SourceTable describes where to find the data.
SourceTable: &dlppb.BigQueryTable{
ProjectId: dataProject,
DatasetId: datasetID,
TableId: tableID,
},
// Send a message to PubSub using Actions.
Actions: []*dlppb.Action{
{
Action: &dlppb.Action_PubSub{
PubSub: &dlppb.Action_PublishToPubSub{
Topic: topic,
},
},
},
},
},
},
}
// Create the risk job.
j, err := client.CreateDlpJob(ctx, req)
if err != nil {
return fmt.Errorf("CreateDlpJob: %w", err)
}
fmt.Fprintf(w, "Created job: %v\n", j.GetName())
// Wait for the risk job to finish by waiting for a PubSub message.
// This only waits for 10 minutes. For long jobs, consider using a truly
// asynchronous execution model such as Cloud Functions.
ctx, cancel := context.WithTimeout(ctx, 10*time.Minute)
defer cancel()
err = s.Receive(ctx, func(ctx context.Context, msg *pubsub.Message) {
// If this is the wrong job, do not process the result.
if msg.Attributes["DlpJobName"] != j.GetName() {
msg.Nack()
return
}
msg.Ack()
time.Sleep(500 * time.Millisecond)
j, err := client.GetDlpJob(ctx, &dlppb.GetDlpJobRequest{
Name: j.GetName(),
})
if err != nil {
fmt.Fprintf(w, "GetDlpJob: %v", err)
return
}
h := j.GetRiskDetails().GetKAnonymityResult().GetEquivalenceClassHistogramBuckets()
for i, b := range h {
fmt.Fprintf(w, "Histogram bucket %v\n", i)
fmt.Fprintf(w, " Size range: [%v,%v]\n", b.GetEquivalenceClassSizeLowerBound(), b.GetEquivalenceClassSizeUpperBound())
fmt.Fprintf(w, " %v unique values total\n", b.GetBucketSize())
for _, v := range b.GetBucketValues() {
var qvs []string
for _, qv := range v.GetQuasiIdsValues() {
qvs = append(qvs, qv.String())
}
fmt.Fprintf(w, " QuasiID values: %s\n", strings.Join(qvs, ", "))
fmt.Fprintf(w, " Class size: %v\n", v.GetEquivalenceClassSize())
}
}
// Stop listening for more messages.
cancel()
})
if err != nil {
return fmt.Errorf("Receive: %w", err)
}
return nil
}
Java
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
import com.google.api.core.SettableApiFuture;
import com.google.cloud.dlp.v2.DlpServiceClient;
import com.google.cloud.pubsub.v1.AckReplyConsumer;
import com.google.cloud.pubsub.v1.MessageReceiver;
import com.google.cloud.pubsub.v1.Subscriber;
import com.google.privacy.dlp.v2.Action;
import com.google.privacy.dlp.v2.Action.PublishToPubSub;
import com.google.privacy.dlp.v2.AnalyzeDataSourceRiskDetails.KAnonymityResult;
import com.google.privacy.dlp.v2.AnalyzeDataSourceRiskDetails.KAnonymityResult.KAnonymityEquivalenceClass;
import com.google.privacy.dlp.v2.AnalyzeDataSourceRiskDetails.KAnonymityResult.KAnonymityHistogramBucket;
import com.google.privacy.dlp.v2.BigQueryTable;
import com.google.privacy.dlp.v2.CreateDlpJobRequest;
import com.google.privacy.dlp.v2.DlpJob;
import com.google.privacy.dlp.v2.FieldId;
import com.google.privacy.dlp.v2.GetDlpJobRequest;
import com.google.privacy.dlp.v2.LocationName;
import com.google.privacy.dlp.v2.PrivacyMetric;
import com.google.privacy.dlp.v2.PrivacyMetric.KAnonymityConfig;
import com.google.privacy.dlp.v2.RiskAnalysisJobConfig;
import com.google.privacy.dlp.v2.Value;
import com.google.pubsub.v1.ProjectSubscriptionName;
import com.google.pubsub.v1.ProjectTopicName;
import com.google.pubsub.v1.PubsubMessage;
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
import java.util.stream.Collectors;
@SuppressWarnings("checkstyle:AbbreviationAsWordInName")
class RiskAnalysisKAnonymity {
public static void main(String[] args) throws Exception {
// TODO(developer): Replace these variables before running the sample.
String projectId = "your-project-id";
String datasetId = "your-bigquery-dataset-id";
String tableId = "your-bigquery-table-id";
String topicId = "pub-sub-topic";
String subscriptionId = "pub-sub-subscription";
calculateKAnonymity(projectId, datasetId, tableId, topicId, subscriptionId);
}
public static void calculateKAnonymity(
String projectId, String datasetId, String tableId, String topicId, String subscriptionId)
throws ExecutionException, InterruptedException, IOException {
// Initialize client that will be used to send requests. This client only needs to be created
// once, and can be reused for multiple requests. After completing all of your requests, call
// the "close" method on the client to safely clean up any remaining background resources.
try (DlpServiceClient dlpServiceClient = DlpServiceClient.create()) {
// Specify the BigQuery table to analyze
BigQueryTable bigQueryTable =
BigQueryTable.newBuilder()
.setProjectId(projectId)
.setDatasetId(datasetId)
.setTableId(tableId)
.build();
// These values represent the column names of quasi-identifiers to analyze
List<String> quasiIds = Arrays.asList("Age", "Mystery");
// Configure the privacy metric for the job
List<FieldId> quasiIdFields =
quasiIds.stream()
.map(columnName -> FieldId.newBuilder().setName(columnName).build())
.collect(Collectors.toList());
KAnonymityConfig kanonymityConfig =
KAnonymityConfig.newBuilder().addAllQuasiIds(quasiIdFields).build();
PrivacyMetric privacyMetric =
PrivacyMetric.newBuilder().setKAnonymityConfig(kanonymityConfig).build();
// Create action to publish job status notifications over Google Cloud Pub/Sub
ProjectTopicName topicName = ProjectTopicName.of(projectId, topicId);
PublishToPubSub publishToPubSub =
PublishToPubSub.newBuilder().setTopic(topicName.toString()).build();
Action action = Action.newBuilder().setPubSub(publishToPubSub).build();
// Configure the risk analysis job to perform
RiskAnalysisJobConfig riskAnalysisJobConfig =
RiskAnalysisJobConfig.newBuilder()
.setSourceTable(bigQueryTable)
.setPrivacyMetric(privacyMetric)
.addActions(action)
.build();
// Build the request to be sent by the client
CreateDlpJobRequest createDlpJobRequest =
CreateDlpJobRequest.newBuilder()
.setParent(LocationName.of(projectId, "global").toString())
.setRiskJob(riskAnalysisJobConfig)
.build();
// Send the request to the API using the client
DlpJob dlpJob = dlpServiceClient.createDlpJob(createDlpJobRequest);
// Set up a Pub/Sub subscriber to listen on the job completion status
final SettableApiFuture<Boolean> done = SettableApiFuture.create();
ProjectSubscriptionName subscriptionName =
ProjectSubscriptionName.of(projectId, subscriptionId);
MessageReceiver messageHandler =
(PubsubMessage pubsubMessage, AckReplyConsumer ackReplyConsumer) -> {
handleMessage(dlpJob, done, pubsubMessage, ackReplyConsumer);
};
Subscriber subscriber = Subscriber.newBuilder(subscriptionName, messageHandler).build();
subscriber.startAsync();
// Wait for job completion semi-synchronously
// For long jobs, consider using a truly asynchronous execution model such as Cloud Functions
try {
done.get(15, TimeUnit.MINUTES);
} catch (TimeoutException e) {
System.out.println("Job was not completed after 15 minutes.");
return;
} finally {
subscriber.stopAsync();
subscriber.awaitTerminated();
}
// Build a request to get the completed job
GetDlpJobRequest getDlpJobRequest =
GetDlpJobRequest.newBuilder().setName(dlpJob.getName()).build();
// Retrieve completed job status
DlpJob completedJob = dlpServiceClient.getDlpJob(getDlpJobRequest);
System.out.println("Job status: " + completedJob.getState());
System.out.println("Job name: " + dlpJob.getName());
// Get the result and parse through and process the information
KAnonymityResult kanonymityResult = completedJob.getRiskDetails().getKAnonymityResult();
List<KAnonymityHistogramBucket> histogramBucketList =
kanonymityResult.getEquivalenceClassHistogramBucketsList();
for (KAnonymityHistogramBucket result : histogramBucketList) {
System.out.printf(
"Bucket size range: [%d, %d]\n",
result.getEquivalenceClassSizeLowerBound(), result.getEquivalenceClassSizeUpperBound());
for (KAnonymityEquivalenceClass bucket : result.getBucketValuesList()) {
List<String> quasiIdValues =
bucket.getQuasiIdsValuesList().stream()
.map(Value::toString)
.collect(Collectors.toList());
System.out.println("\tQuasi-ID values: " + String.join(", ", quasiIdValues));
System.out.println("\tClass size: " + bucket.getEquivalenceClassSize());
}
}
}
}
// handleMessage injects the job and settableFuture into the message reciever interface
private static void handleMessage(
DlpJob job,
SettableApiFuture<Boolean> done,
PubsubMessage pubsubMessage,
AckReplyConsumer ackReplyConsumer) {
String messageAttribute = pubsubMessage.getAttributesMap().get("DlpJobName");
if (job.getName().equals(messageAttribute)) {
done.set(true);
ackReplyConsumer.ack();
} else {
ackReplyConsumer.nack();
}
}
}Node.js
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
// Import the Google Cloud client libraries
const DLP = require('@google-cloud/dlp');
const {PubSub} = require('@google-cloud/pubsub');
// Instantiates clients
const dlp = new DLP.DlpServiceClient();
const pubsub = new PubSub();
// The project ID to run the API call under
// const projectId = 'my-project';
// The project ID the table is stored under
// This may or (for public datasets) may not equal the calling project ID
// const tableProjectId = 'my-project';
// The ID of the dataset to inspect, e.g. 'my_dataset'
// const datasetId = 'my_dataset';
// The ID of the table to inspect, e.g. 'my_table'
// const tableId = 'my_table';
// The name of the Pub/Sub topic to notify once the job completes
// TODO(developer): create a Pub/Sub topic to use for this
// const topicId = 'MY-PUBSUB-TOPIC'
// The name of the Pub/Sub subscription to use when listening for job
// completion notifications
// TODO(developer): create a Pub/Sub subscription to use for this
// const subscriptionId = 'MY-PUBSUB-SUBSCRIPTION'
// A set of columns that form a composite key ('quasi-identifiers')
// const quasiIds = [{ name: 'age' }, { name: 'city' }];
async function kAnonymityAnalysis() {
const sourceTable = {
projectId: tableProjectId,
datasetId: datasetId,
tableId: tableId,
};
// Construct request for creating a risk analysis job
const request = {
parent: `projects/${projectId}/locations/global`,
riskJob: {
privacyMetric: {
kAnonymityConfig: {
quasiIds: quasiIds,
},
},
sourceTable: sourceTable,
actions: [
{
pubSub: {
topic: `projects/${projectId}/topics/${topicId}`,
},
},
],
},
};
// Create helper function for unpacking values
const getValue = obj => obj[Object.keys(obj)[0]];
// Run risk analysis job
const [topicResponse] = await pubsub.topic(topicId).get();
const subscription = await topicResponse.subscription(subscriptionId);
const [jobsResponse] = await dlp.createDlpJob(request);
const jobName = jobsResponse.name;
console.log(`Job created. Job name: ${jobName}`);
// Watch the Pub/Sub topic until the DLP job finishes
await new Promise((resolve, reject) => {
const messageHandler = message => {
if (message.attributes && message.attributes.DlpJobName === jobName) {
message.ack();
subscription.removeListener('message', messageHandler);
subscription.removeListener('error', errorHandler);
resolve(jobName);
} else {
message.nack();
}
};
const errorHandler = err => {
subscription.removeListener('message', messageHandler);
subscription.removeListener('error', errorHandler);
reject(err);
};
subscription.on('message', messageHandler);
subscription.on('error', errorHandler);
});
setTimeout(() => {
console.log(' Waiting for DLP job to fully complete');
}, 500);
const [job] = await dlp.getDlpJob({name: jobName});
const histogramBuckets =
job.riskDetails.kAnonymityResult.equivalenceClassHistogramBuckets;
histogramBuckets.forEach((histogramBucket, histogramBucketIdx) => {
console.log(`Bucket ${histogramBucketIdx}:`);
console.log(
` Bucket size range: [${histogramBucket.equivalenceClassSizeLowerBound}, ${histogramBucket.equivalenceClassSizeUpperBound}]`
);
histogramBucket.bucketValues.forEach(valueBucket => {
const quasiIdValues = valueBucket.quasiIdsValues
.map(getValue)
.join(', ');
console.log(` Quasi-ID values: {${quasiIdValues}}`);
console.log(` Class size: ${valueBucket.equivalenceClassSize}`);
});
});
}
await kAnonymityAnalysis();PHP
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
use Google\Cloud\Dlp\V2\RiskAnalysisJobConfig;
use Google\Cloud\Dlp\V2\BigQueryTable;
use Google\Cloud\Dlp\V2\DlpJob\JobState;
use Google\Cloud\Dlp\V2\Action;
use Google\Cloud\Dlp\V2\Action\PublishToPubSub;
use Google\Cloud\Dlp\V2\Client\DlpServiceClient;
use Google\Cloud\Dlp\V2\CreateDlpJobRequest;
use Google\Cloud\Dlp\V2\FieldId;
use Google\Cloud\Dlp\V2\GetDlpJobRequest;
use Google\Cloud\Dlp\V2\PrivacyMetric;
use Google\Cloud\Dlp\V2\PrivacyMetric\KAnonymityConfig;
use Google\Cloud\PubSub\PubSubClient;
/**
* Computes the k-anonymity of a column set in a Google BigQuery table.
*
* @param string $callingProjectId The project ID to run the API call under
* @param string $dataProjectId The project ID containing the target Datastore
* @param string $topicId The name of the Pub/Sub topic to notify once the job completes
* @param string $subscriptionId The name of the Pub/Sub subscription to use when listening for job
* @param string $datasetId The ID of the dataset to inspect
* @param string $tableId The ID of the table to inspect
* @param string[] $quasiIdNames Array columns that form a composite key (quasi-identifiers)
*/
function k_anonymity(
string $callingProjectId,
string $dataProjectId,
string $topicId,
string $subscriptionId,
string $datasetId,
string $tableId,
array $quasiIdNames
): void {
// Instantiate a client.
$dlp = new DlpServiceClient();
$pubsub = new PubSubClient();
$topic = $pubsub->topic($topicId);
// Construct risk analysis config
$quasiIds = array_map(
function ($id) {
return (new FieldId())->setName($id);
},
$quasiIdNames
);
$statsConfig = (new KAnonymityConfig())
->setQuasiIds($quasiIds);
$privacyMetric = (new PrivacyMetric())
->setKAnonymityConfig($statsConfig);
// Construct items to be analyzed
$bigqueryTable = (new BigQueryTable())
->setProjectId($dataProjectId)
->setDatasetId($datasetId)
->setTableId($tableId);
// Construct the action to run when job completes
$pubSubAction = (new PublishToPubSub())
->setTopic($topic->name());
$action = (new Action())
->setPubSub($pubSubAction);
// Construct risk analysis job config to run
$riskJob = (new RiskAnalysisJobConfig())
->setPrivacyMetric($privacyMetric)
->setSourceTable($bigqueryTable)
->setActions([$action]);
// Listen for job notifications via an existing topic/subscription.
$subscription = $topic->subscription($subscriptionId);
// Submit request
$parent = "projects/$callingProjectId/locations/global";
$createDlpJobRequest = (new CreateDlpJobRequest())
->setParent($parent)
->setRiskJob($riskJob);
$job = $dlp->createDlpJob($createDlpJobRequest);
// Poll Pub/Sub using exponential backoff until job finishes
// Consider using an asynchronous execution model such as Cloud Functions
$attempt = 1;
$startTime = time();
do {
foreach ($subscription->pull() as $message) {
if (
isset($message->attributes()['DlpJobName']) &&
$message->attributes()['DlpJobName'] === $job->getName()
) {
$subscription->acknowledge($message);
// Get the updated job. Loop to avoid race condition with DLP API.
do {
$getDlpJobRequest = (new GetDlpJobRequest())
->setName($job->getName());
$job = $dlp->getDlpJob($getDlpJobRequest);
} while ($job->getState() == JobState::RUNNING);
break 2; // break from parent do while
}
}
print('Waiting for job to complete' . PHP_EOL);
// Exponential backoff with max delay of 60 seconds
sleep(min(60, pow(2, ++$attempt)));
} while (time() - $startTime < 600); // 10 minute timeout
// Print finding counts
printf('Job %s status: %s' . PHP_EOL, $job->getName(), JobState::name($job->getState()));
switch ($job->getState()) {
case JobState::DONE:
$histBuckets = $job->getRiskDetails()->getKAnonymityResult()->getEquivalenceClassHistogramBuckets();
foreach ($histBuckets as $bucketIndex => $histBucket) {
// Print bucket stats
printf('Bucket %s:' . PHP_EOL, $bucketIndex);
printf(
' Bucket size range: [%s, %s]' . PHP_EOL,
$histBucket->getEquivalenceClassSizeLowerBound(),
$histBucket->getEquivalenceClassSizeUpperBound()
);
// Print bucket values
foreach ($histBucket->getBucketValues() as $percent => $valueBucket) {
// Pretty-print quasi-ID values
print(' Quasi-ID values:' . PHP_EOL);
foreach ($valueBucket->getQuasiIdsValues() as $index => $value) {
print(' ' . $value->serializeToJsonString() . PHP_EOL);
}
printf(
' Class size: %s' . PHP_EOL,
$valueBucket->getEquivalenceClassSize()
);
}
}
break;
case JobState::FAILED:
printf('Job %s had errors:' . PHP_EOL, $job->getName());
$errors = $job->getErrors();
foreach ($errors as $error) {
var_dump($error->getDetails());
}
break;
case JobState::PENDING:
print('Job has not completed. Consider a longer timeout or an asynchronous execution model' . PHP_EOL);
break;
default:
print('Unexpected job state. Most likely, the job is either running or has not yet started.');
}
}Python
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
import concurrent.futures
from typing import List
import google.cloud.dlp
from google.cloud.dlp_v2 import types
import google.cloud.pubsub
def k_anonymity_analysis(
project: str,
table_project_id: str,
dataset_id: str,
table_id: str,
topic_id: str,
subscription_id: str,
quasi_ids: List[str],
timeout: int = 300,
) -> None:
"""Uses the Data Loss Prevention API to compute the k-anonymity of a
column set in a Google BigQuery table.
Args:
project: The Google Cloud project id to use as a parent resource.
table_project_id: The Google Cloud project id where the BigQuery table
is stored.
dataset_id: The id of the dataset to inspect.
table_id: The id of the table to inspect.
topic_id: The name of the Pub/Sub topic to notify once the job
completes.
subscription_id: The name of the Pub/Sub subscription to use when
listening for job completion notifications.
quasi_ids: A set of columns that form a composite key.
timeout: The number of seconds to wait for a response from the API.
Returns:
None; the response from the API is printed to the terminal.
"""
# Create helper function for unpacking values
def get_values(obj: types.Value) -> int:
return int(obj.integer_value)
# Instantiate a client.
dlp = google.cloud.dlp_v2.DlpServiceClient()
# Convert the project id into a full resource id.
topic = google.cloud.pubsub.PublisherClient.topic_path(project, topic_id)
parent = f"projects/{project}/locations/global"
# Location info of the BigQuery table.
source_table = {
"project_id": table_project_id,
"dataset_id": dataset_id,
"table_id": table_id,
}
# Convert quasi id list to Protobuf type
def map_fields(field: str) -> dict:
return {"name": field}
quasi_ids = map(map_fields, quasi_ids)
# Tell the API where to send a notification when the job is complete.
actions = [{"pub_sub": {"topic": topic}}]
# Configure risk analysis job
# Give the name of the numeric column to compute risk metrics for
risk_job = {
"privacy_metric": {"k_anonymity_config": {"quasi_ids": quasi_ids}},
"source_table": source_table,
"actions": actions,
}
# Call API to start risk analysis job
operation = dlp.create_dlp_job(request={"parent": parent, "risk_job": risk_job})
def callback(message: google.cloud.pubsub_v1.subscriber.message.Message) -> None:
if message.attributes["DlpJobName"] == operation.name:
# This is the message we're looking for, so acknowledge it.
message.ack()
# Now that the job is done, fetch the results and print them.
job = dlp.get_dlp_job(request={"name": operation.name})
print(f"Job name: {job.name}")
histogram_buckets = (
job.risk_details.k_anonymity_result.equivalence_class_histogram_buckets
)
# Print bucket stats
for i, bucket in enumerate(histogram_buckets):
print(f"Bucket {i}:")
if bucket.equivalence_class_size_lower_bound:
print(
" Bucket size range: [{}, {}]".format(
bucket.equivalence_class_size_lower_bound,
bucket.equivalence_class_size_upper_bound,
)
)
for value_bucket in bucket.bucket_values:
print(
" Quasi-ID values: {}".format(
map(get_values, value_bucket.quasi_ids_values)
)
)
print(
" Class size: {}".format(
value_bucket.equivalence_class_size
)
)
subscription.set_result(None)
else:
# This is not the message we're looking for.
message.drop()
# Create a Pub/Sub client and find the subscription. The subscription is
# expected to already be listening to the topic.
subscriber = google.cloud.pubsub.SubscriberClient()
subscription_path = subscriber.subscription_path(project, subscription_id)
subscription = subscriber.subscribe(subscription_path, callback)
try:
subscription.result(timeout=timeout)
except concurrent.futures.TimeoutError:
print(
"No event received before the timeout. Please verify that the "
"subscription provided is subscribed to the topic provided."
)
subscription.close()
REST
새로운 위험 분석 작업을 실행하여 k-익명성을 계산하려면 projects.dlpJobs 리소스에 요청을 보냅니다. 여기서 PROJECT_ID는 프로젝트 식별자를 나타냅니다.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
요청에는 다음 요소로 구성된 RiskAnalysisJobConfig 객체가 포함됩니다.
PrivacyMetric객체. 여기에서KAnonymityConfig객체를 포함하여 k-익명성을 계산하도록 지정합니다.BigQueryTable객체. 다음을 모두 포함하여 스캔할 BigQuery 테이블을 지정합니다.projectId: 테이블이 포함된 프로젝트의 프로젝트 IDdatasetId: 테이블의 데이터 세트 IDtableId: 테이블의 이름
작업 완료 시 실행할 작업을 나타내는 하나 이상의
Action객체 집합(주어진 순서에 따름). 각Action객체는 다음 작업 중 하나를 포함할 수 있습니다.SaveFindings객체: 위험 분석 스캔의 결과를 BigQuery 테이블에 저장합니다.JobNotificationEmails객체: 결과가 포함된 이메일을 보냅니다.
KAnonymityConfig객체 내에서 다음을 지정합니다.quasiIds[]: k-익명성을 계산할 때 스캔하고 사용할 하나 이상의 유사 식별자(FieldId객체). 여러 개의 유사 식별자를 지정하는 경우 하나의 복합 키로 간주됩니다. 구조체 및 반복 데이터 유형은 지원되지 않지만 중첩 필드는 그 자체가 구조체이거나 반복 필드에 중첩되지 않는 한 지원됩니다.entityId: 선택사항인 식별자 값. 설정되면 k-익명성을 계산할 때 각각의 고유한entityId에 해당하는 모든 행을 그룹화해야 합니다. 일반적으로entityId는 고객 ID 또는 사용자 ID와 같이 순 사용자를 나타내는 열입니다.entityId가 유사 식별자 값이 서로 다른 여러 행에 나타나는 경우 이러한 행은 조인을 통해 해당 항목을 위한 유사 식별자로 사용되는 멀티 세트를 형성합니다. 항목 ID에 대한 자세한 내용은 위험 분석 개념 항목의 항목 ID 및 k-익명성 계산을 참조하세요.
DLP API에 요청을 전송하면 위험 분석 작업이 시작됩니다.
완료된 위험 분석 작업 나열
현재 프로젝트에서 실행된 위험 분석 작업의 목록을 볼 수 있습니다.
콘솔
Google Cloud 콘솔에서 실행 중이고 이전에 실행된 위험 분석 작업을 나열하려면 다음을 수행합니다.
Google Cloud 콘솔에서 Sensitive Data Protection을 엽니다.
페이지 상단의 작업 및 작업 트리거 탭을 클릭합니다.
위험 작업 탭을 클릭합니다.
위험 작업 목록이 표시됩니다.
프로토콜
실행 중이고 이전에 실행된 위험 분석 작업을 나열하려면 projects.dlpJobs 리소스에 GET 요청을 보냅니다. 작업 유형 필터(?type=RISK_ANALYSIS_JOB)를 추가하면 응답의 범위를 위험 분석 작업으로 좁힙니다.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
수신하는 응답에는 현재 및 이전 위험 분석 작업의 JSON 표현이 포함됩니다.
k-익명성 작업 결과 보기
Google Cloud 콘솔의 Sensitive Data Protection에는 완료된 k-익명성 작업의 시각화 기능이 기본 제공됩니다. 이전 섹션의 안내를 따른 후 위험 분석 작업 목록에서 결과를 확인할 작업을 선택합니다. 작업이 성공적으로 실행되었다고 가정하면 위험 분석 세부정보 페이지 상단에 다음과 같이 표시됩니다.

페이지 상단에 작업 ID를 포함한 k-익명성 위험 작업에 대한 정보가 나와 있으며 컨테이너에는 리소스 위치가 표시됩니다.
k-익명성 계산 결과를 보려면 K-익명성 탭을 클릭합니다. 위험 분석 작업의 구성을 보려면 구성 탭을 클릭합니다.
K-익명성 탭에는 먼저 항목 ID(있는 경우)와 k-익명성을 계산하는 데 사용되는 유사 식별자가 나열됩니다.
위험 차트
재식별 위험 차트의 y축은 고유 행과 고유 유사 식별자 조합에 대한 데이터 손실의 잠재적 비율이며 x축은 k-익명성 값입니다. 차트의 색상도 위험 가능성도 나타냅니다. 파란색이 어두울수록 위험이 높으며 밝을 수록 위험이 적습니다.
k-익명성 값이 높으면 재식별 위험이 줄어듭니다. 그러나 k-익명성 값을 높이려면 총 행의 높은 비율과 높은 고유 유사 식별자 조합을 삭제해야 할 수 있으며 이는 데이터의 유용성을 낮춥니다. 특정 k-익명성 값의 특정 잠재적 백분율 손실 값을 보려면 차트 위로 마우스 커서를 가져가세요. 스크린샷과 같이 차트에 도움말이 표시됩니다.
특정 k-익명성 값에 대한 자세한 내용을 보려면 해당 데이터 포인트를 클릭합니다. 차트 아래에 자세한 설명이 표시되고 샘플 데이터 테이블이 페이지 아래쪽에 표시됩니다.
위험 샘플 데이터 표
위험 작업 결과 페이지의 두 번째 구성요소는 샘플 데이터 테이블입니다. 지정된 대상 k-익명성 값에 대한 유사 식별자 조합을 표시합니다.
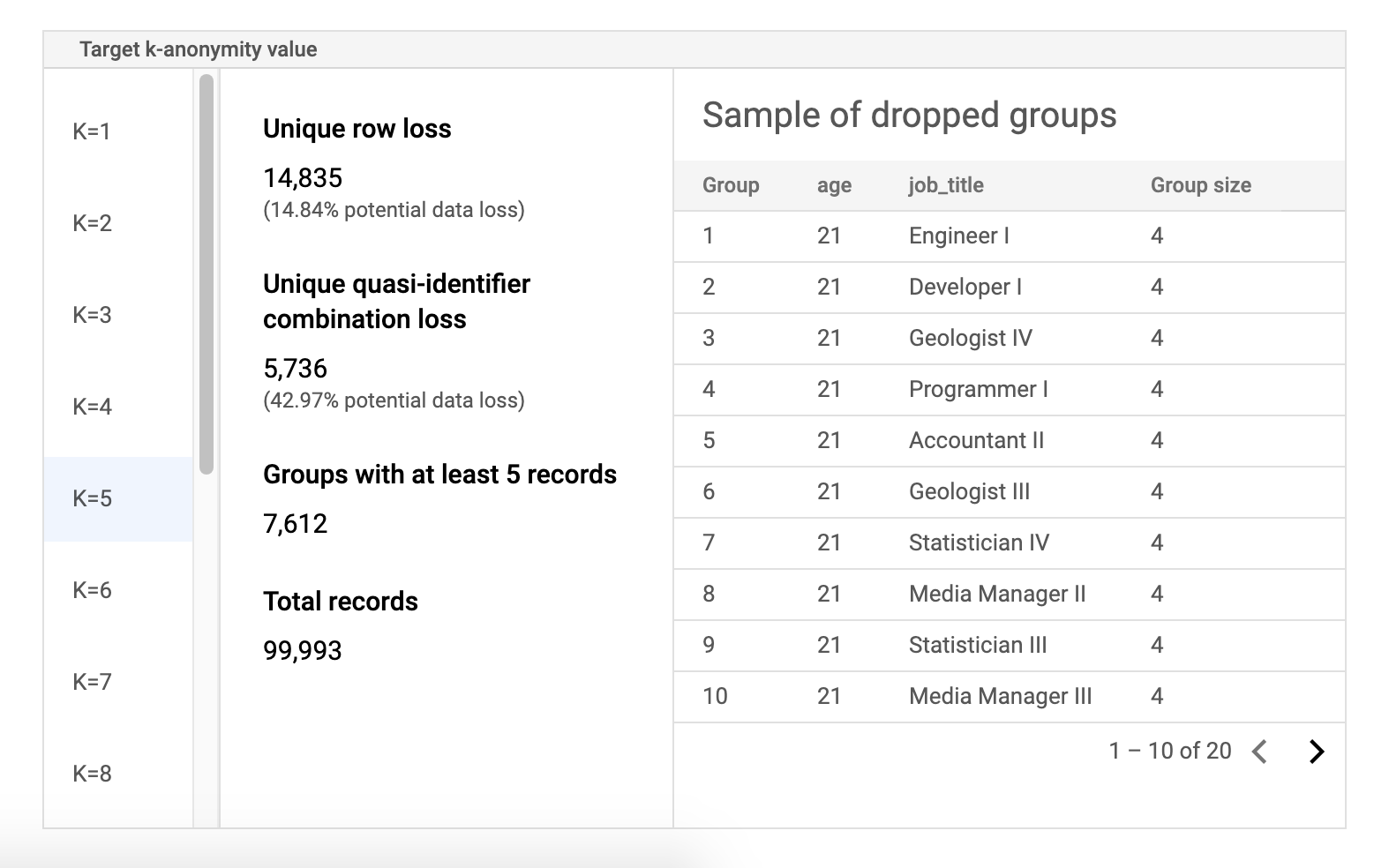
테이블의 첫 번째 열에는 k-익명성 값이 나열됩니다. k-익명성 값을 클릭하면 값을 얻기 위해 삭제되어야 할 해당 샘플 데이터가 표시됩니다.
두 번째 열은 고유한 행 및 유사 식별자 조합의 잠재적 데이터 손실과 최소 k 레코드가 있는 그룹 수와 총 레코드 수를 표시합니다.
마지막 열에는 유사 식별자 조합을 공유하는 그룹의 샘플과 해당 조합에 존재하는 레코드 수가 표시됩니다.
REST를 사용하여 작업 세부정보 검색
REST API를 사용하여 k-익명성 위험 분석 작업의 결과를 검색하려면 다음 GET 요청을 projects.dlpJobs 리소스에 보냅니다. PROJECT_ID를 프로젝트 ID로 바꾸고 JOB_ID를 결과를 가져올 작업 식별자로 바꿉니다.
작업 ID는 작업 시작 시 반환되었으며 모든 작업을 나열하여 검색할 수도 있습니다.
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
요청은 작업 인스턴스가 포함된 JSON 객체를 반환합니다. 분석 결과는 AnalyzeDataSourceRiskDetails 객체의 "riskDetails" 키 내에 있습니다. 자세한 내용은 DlpJob 리소스의 API 참조를 확인하세요.
코드 샘플: 항목 ID를 사용하여 k-익명성 계산
이 예시에서는 항목 ID를 사용하여 k-익명성을 계산하는 위험 분석 작업을 만듭니다.
항목 ID에 대한 자세한 내용은 항목 ID 및 k-익명성 계산을 참조하세요.
C#
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
using System;
using System.Collections.Generic;
using System.Linq;
using Google.Api.Gax.ResourceNames;
using Google.Cloud.Dlp.V2;
using Newtonsoft.Json;
public class CalculateKAnonymityOnDataset
{
public static DlpJob CalculateKAnonymitty(
string projectId,
string datasetId,
string sourceTableId,
string outputTableId)
{
// Construct the dlp client.
var dlp = DlpServiceClient.Create();
// Construct the k-anonymity config by setting the EntityId as user_id column
// and two quasi-identifiers columns.
var kAnonymity = new PrivacyMetric.Types.KAnonymityConfig
{
EntityId = new EntityId
{
Field = new FieldId { Name = "Name" }
},
QuasiIds =
{
new FieldId { Name = "Age" },
new FieldId { Name = "Mystery" }
}
};
// Construct risk analysis job config by providing the source table, privacy metric
// and action to save the findings to a BigQuery table.
var riskJob = new RiskAnalysisJobConfig
{
SourceTable = new BigQueryTable
{
ProjectId = projectId,
DatasetId = datasetId,
TableId = sourceTableId,
},
PrivacyMetric = new PrivacyMetric
{
KAnonymityConfig = kAnonymity,
},
Actions =
{
new Google.Cloud.Dlp.V2.Action
{
SaveFindings = new Google.Cloud.Dlp.V2.Action.Types.SaveFindings
{
OutputConfig = new OutputStorageConfig
{
Table = new BigQueryTable
{
ProjectId = projectId,
DatasetId = datasetId,
TableId = outputTableId
}
}
}
}
}
};
// Construct the request by providing RiskJob object created above.
var request = new CreateDlpJobRequest
{
ParentAsLocationName = new LocationName(projectId, "global"),
RiskJob = riskJob
};
// Send the job request.
DlpJob response = dlp.CreateDlpJob(request);
Console.WriteLine($"Job created successfully. Job name: ${response.Name}");
return response;
}
}
Go
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
import (
"context"
"fmt"
"io"
"strings"
"time"
dlp "cloud.google.com/go/dlp/apiv2"
"cloud.google.com/go/dlp/apiv2/dlppb"
)
// Uses the Data Loss Prevention API to compute the k-anonymity of a
// column set in a Google BigQuery table.
func calculateKAnonymityWithEntityId(w io.Writer, projectID, datasetId, tableId string, columnNames ...string) error {
// projectID := "your-project-id"
// datasetId := "your-bigquery-dataset-id"
// tableId := "your-bigquery-table-id"
// columnNames := "age" "job_title"
ctx := context.Background()
// Initialize a client once and reuse it to send multiple requests. Clients
// are safe to use across goroutines. When the client is no longer needed,
// call the Close method to cleanup its resources.
client, err := dlp.NewClient(ctx)
if err != nil {
return err
}
// Closing the client safely cleans up background resources.
defer client.Close()
// Specify the BigQuery table to analyze
bigQueryTable := &dlppb.BigQueryTable{
ProjectId: "bigquery-public-data",
DatasetId: "samples",
TableId: "wikipedia",
}
// Configure the privacy metric for the job
// Build the QuasiID slice.
var q []*dlppb.FieldId
for _, c := range columnNames {
q = append(q, &dlppb.FieldId{Name: c})
}
entityId := &dlppb.EntityId{
Field: &dlppb.FieldId{
Name: "id",
},
}
kAnonymityConfig := &dlppb.PrivacyMetric_KAnonymityConfig{
QuasiIds: q,
EntityId: entityId,
}
privacyMetric := &dlppb.PrivacyMetric{
Type: &dlppb.PrivacyMetric_KAnonymityConfig_{
KAnonymityConfig: kAnonymityConfig,
},
}
// Specify the bigquery table to store the findings.
// The "test_results" table in the given BigQuery dataset will be created if it doesn't
// already exist.
outputbigQueryTable := &dlppb.BigQueryTable{
ProjectId: projectID,
DatasetId: datasetId,
TableId: tableId,
}
// Create action to publish job status notifications to BigQuery table.
outputStorageConfig := &dlppb.OutputStorageConfig{
Type: &dlppb.OutputStorageConfig_Table{
Table: outputbigQueryTable,
},
}
findings := &dlppb.Action_SaveFindings{
OutputConfig: outputStorageConfig,
}
action := &dlppb.Action{
Action: &dlppb.Action_SaveFindings_{
SaveFindings: findings,
},
}
// Configure the risk analysis job to perform
riskAnalysisJobConfig := &dlppb.RiskAnalysisJobConfig{
PrivacyMetric: privacyMetric,
SourceTable: bigQueryTable,
Actions: []*dlppb.Action{
action,
},
}
// Build the request to be sent by the client
req := &dlppb.CreateDlpJobRequest{
Parent: fmt.Sprintf("projects/%s/locations/global", projectID),
Job: &dlppb.CreateDlpJobRequest_RiskJob{
RiskJob: riskAnalysisJobConfig,
},
}
// Send the request to the API using the client
dlpJob, err := client.CreateDlpJob(ctx, req)
if err != nil {
return err
}
fmt.Fprintf(w, "Created job: %v\n", dlpJob.GetName())
// Build a request to get the completed job
getDlpJobReq := &dlppb.GetDlpJobRequest{
Name: dlpJob.Name,
}
timeout := 15 * time.Minute
startTime := time.Now()
var completedJob *dlppb.DlpJob
// Wait for job completion
for time.Since(startTime) <= timeout {
completedJob, err = client.GetDlpJob(ctx, getDlpJobReq)
if err != nil {
return err
}
if completedJob.GetState() == dlppb.DlpJob_DONE {
break
}
time.Sleep(30 * time.Second)
}
if completedJob.GetState() != dlppb.DlpJob_DONE {
fmt.Println("Job did not complete within 15 minutes.")
}
// Retrieve completed job status
fmt.Fprintf(w, "Job status: %v", completedJob.State)
fmt.Fprintf(w, "Job name: %v", dlpJob.Name)
// Get the result and parse through and process the information
kanonymityResult := completedJob.GetRiskDetails().GetKAnonymityResult()
for _, result := range kanonymityResult.GetEquivalenceClassHistogramBuckets() {
fmt.Fprintf(w, "Bucket size range: [%d, %d]\n", result.GetEquivalenceClassSizeLowerBound(), result.GetEquivalenceClassSizeLowerBound())
for _, bucket := range result.GetBucketValues() {
quasiIdValues := []string{}
for _, v := range bucket.GetQuasiIdsValues() {
quasiIdValues = append(quasiIdValues, v.GetStringValue())
}
fmt.Fprintf(w, "\tQuasi-ID values: %s", strings.Join(quasiIdValues, ","))
fmt.Fprintf(w, "\tClass size: %d", bucket.EquivalenceClassSize)
}
}
return nil
}
Java
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
import com.google.cloud.dlp.v2.DlpServiceClient;
import com.google.privacy.dlp.v2.Action;
import com.google.privacy.dlp.v2.Action.SaveFindings;
import com.google.privacy.dlp.v2.AnalyzeDataSourceRiskDetails.KAnonymityResult;
import com.google.privacy.dlp.v2.AnalyzeDataSourceRiskDetails.KAnonymityResult.KAnonymityEquivalenceClass;
import com.google.privacy.dlp.v2.AnalyzeDataSourceRiskDetails.KAnonymityResult.KAnonymityHistogramBucket;
import com.google.privacy.dlp.v2.BigQueryTable;
import com.google.privacy.dlp.v2.CreateDlpJobRequest;
import com.google.privacy.dlp.v2.DlpJob;
import com.google.privacy.dlp.v2.EntityId;
import com.google.privacy.dlp.v2.FieldId;
import com.google.privacy.dlp.v2.GetDlpJobRequest;
import com.google.privacy.dlp.v2.LocationName;
import com.google.privacy.dlp.v2.OutputStorageConfig;
import com.google.privacy.dlp.v2.PrivacyMetric;
import com.google.privacy.dlp.v2.PrivacyMetric.KAnonymityConfig;
import com.google.privacy.dlp.v2.RiskAnalysisJobConfig;
import com.google.privacy.dlp.v2.Value;
import java.io.IOException;
import java.time.Duration;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
@SuppressWarnings("checkstyle:AbbreviationAsWordInName")
public class RiskAnalysisKAnonymityWithEntityId {
public static void main(String[] args) throws IOException, InterruptedException {
// TODO(developer): Replace these variables before running the sample.
// The Google Cloud project id to use as a parent resource.
String projectId = "your-project-id";
// The BigQuery dataset id to be used and the reference table name to be inspected.
String datasetId = "your-bigquery-dataset-id";
String tableId = "your-bigquery-table-id";
calculateKAnonymityWithEntityId(projectId, datasetId, tableId);
}
// Uses the Data Loss Prevention API to compute the k-anonymity of a column set in a Google
// BigQuery table.
public static void calculateKAnonymityWithEntityId(
String projectId, String datasetId, String tableId) throws IOException, InterruptedException {
// Initialize client that will be used to send requests. This client only needs to be created
// once, and can be reused for multiple requests. After completing all of your requests, call
// the "close" method on the client to safely clean up any remaining background resources.
try (DlpServiceClient dlpServiceClient = DlpServiceClient.create()) {
// Specify the BigQuery table to analyze
BigQueryTable bigQueryTable =
BigQueryTable.newBuilder()
.setProjectId(projectId)
.setDatasetId(datasetId)
.setTableId(tableId)
.build();
// These values represent the column names of quasi-identifiers to analyze
List<String> quasiIds = Arrays.asList("Age", "Mystery");
// Create a list of FieldId objects based on the provided list of column names.
List<FieldId> quasiIdFields =
quasiIds.stream()
.map(columnName -> FieldId.newBuilder().setName(columnName).build())
.collect(Collectors.toList());
// Specify the unique identifier in the source table for the k-anonymity analysis.
FieldId uniqueIdField = FieldId.newBuilder().setName("Name").build();
EntityId entityId = EntityId.newBuilder().setField(uniqueIdField).build();
KAnonymityConfig kanonymityConfig = KAnonymityConfig.newBuilder()
.addAllQuasiIds(quasiIdFields)
.setEntityId(entityId)
.build();
// Configure the privacy metric to compute for re-identification risk analysis.
PrivacyMetric privacyMetric =
PrivacyMetric.newBuilder().setKAnonymityConfig(kanonymityConfig).build();
// Specify the bigquery table to store the findings.
// The "test_results" table in the given BigQuery dataset will be created if it doesn't
// already exist.
BigQueryTable outputbigQueryTable =
BigQueryTable.newBuilder()
.setProjectId(projectId)
.setDatasetId(datasetId)
.setTableId("test_results")
.build();
// Create action to publish job status notifications to BigQuery table.
OutputStorageConfig outputStorageConfig =
OutputStorageConfig.newBuilder().setTable(outputbigQueryTable).build();
SaveFindings findings =
SaveFindings.newBuilder().setOutputConfig(outputStorageConfig).build();
Action action = Action.newBuilder().setSaveFindings(findings).build();
// Configure the risk analysis job to perform
RiskAnalysisJobConfig riskAnalysisJobConfig =
RiskAnalysisJobConfig.newBuilder()
.setSourceTable(bigQueryTable)
.setPrivacyMetric(privacyMetric)
.addActions(action)
.build();
// Build the request to be sent by the client
CreateDlpJobRequest createDlpJobRequest =
CreateDlpJobRequest.newBuilder()
.setParent(LocationName.of(projectId, "global").toString())
.setRiskJob(riskAnalysisJobConfig)
.build();
// Send the request to the API using the client
DlpJob dlpJob = dlpServiceClient.createDlpJob(createDlpJobRequest);
// Build a request to get the completed job
GetDlpJobRequest getDlpJobRequest =
GetDlpJobRequest.newBuilder().setName(dlpJob.getName()).build();
DlpJob completedJob = null;
// Wait for job completion
try {
Duration timeout = Duration.ofMinutes(15);
long startTime = System.currentTimeMillis();
do {
completedJob = dlpServiceClient.getDlpJob(getDlpJobRequest);
TimeUnit.SECONDS.sleep(30);
} while (completedJob.getState() != DlpJob.JobState.DONE
&& System.currentTimeMillis() - startTime <= timeout.toMillis());
} catch (InterruptedException e) {
System.out.println("Job did not complete within 15 minutes.");
}
// Retrieve completed job status
System.out.println("Job status: " + completedJob.getState());
System.out.println("Job name: " + dlpJob.getName());
// Get the result and parse through and process the information
KAnonymityResult kanonymityResult = completedJob.getRiskDetails().getKAnonymityResult();
for (KAnonymityHistogramBucket result :
kanonymityResult.getEquivalenceClassHistogramBucketsList()) {
System.out.printf(
"Bucket size range: [%d, %d]\n",
result.getEquivalenceClassSizeLowerBound(), result.getEquivalenceClassSizeUpperBound());
for (KAnonymityEquivalenceClass bucket : result.getBucketValuesList()) {
List<String> quasiIdValues =
bucket.getQuasiIdsValuesList().stream()
.map(Value::toString)
.collect(Collectors.toList());
System.out.println("\tQuasi-ID values: " + String.join(", ", quasiIdValues));
System.out.println("\tClass size: " + bucket.getEquivalenceClassSize());
}
}
}
}
}
Node.js
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
// Imports the Google Cloud Data Loss Prevention library
const DLP = require('@google-cloud/dlp');
// Instantiates a client
const dlp = new DLP.DlpServiceClient();
// The project ID to run the API call under.
// const projectId = "your-project-id";
// The ID of the dataset to inspect, e.g. 'my_dataset'
// const datasetId = 'my_dataset';
// The ID of the table to inspect, e.g. 'my_table'
// const sourceTableId = 'my_source_table';
// The ID of the table where outputs are stored
// const outputTableId = 'my_output_table';
async function kAnonymityWithEntityIds() {
// Specify the BigQuery table to analyze.
const sourceTable = {
projectId: projectId,
datasetId: datasetId,
tableId: sourceTableId,
};
// Specify the unique identifier in the source table for the k-anonymity analysis.
const uniqueIdField = {name: 'Name'};
// These values represent the column names of quasi-identifiers to analyze
const quasiIds = [{name: 'Age'}, {name: 'Mystery'}];
// Configure the privacy metric to compute for re-identification risk analysis.
const privacyMetric = {
kAnonymityConfig: {
entityId: {
field: uniqueIdField,
},
quasiIds: quasiIds,
},
};
// Create action to publish job status notifications to BigQuery table.
const action = [
{
saveFindings: {
outputConfig: {
table: {
projectId: projectId,
datasetId: datasetId,
tableId: outputTableId,
},
},
},
},
];
// Configure the risk analysis job to perform.
const riskAnalysisJob = {
sourceTable: sourceTable,
privacyMetric: privacyMetric,
actions: action,
};
// Combine configurations into a request for the service.
const createDlpJobRequest = {
parent: `projects/${projectId}/locations/global`,
riskJob: riskAnalysisJob,
};
// Send the request and receive response from the service
const [createdDlpJob] = await dlp.createDlpJob(createDlpJobRequest);
const jobName = createdDlpJob.name;
// Waiting for a maximum of 15 minutes for the job to get complete.
let job;
let numOfAttempts = 30;
while (numOfAttempts > 0) {
// Fetch DLP Job status
[job] = await dlp.getDlpJob({name: jobName});
// Check if the job has completed.
if (job.state === 'DONE') {
break;
}
if (job.state === 'FAILED') {
console.log('Job Failed, Please check the configuration.');
return;
}
// Sleep for a short duration before checking the job status again.
await new Promise(resolve => {
setTimeout(() => resolve(), 30000);
});
numOfAttempts -= 1;
}
// Create helper function for unpacking values
const getValue = obj => obj[Object.keys(obj)[0]];
// Print out the results.
const histogramBuckets =
job.riskDetails.kAnonymityResult.equivalenceClassHistogramBuckets;
histogramBuckets.forEach((histogramBucket, histogramBucketIdx) => {
console.log(`Bucket ${histogramBucketIdx}:`);
console.log(
` Bucket size range: [${histogramBucket.equivalenceClassSizeLowerBound}, ${histogramBucket.equivalenceClassSizeUpperBound}]`
);
histogramBucket.bucketValues.forEach(valueBucket => {
const quasiIdValues = valueBucket.quasiIdsValues
.map(getValue)
.join(', ');
console.log(` Quasi-ID values: {${quasiIdValues}}`);
console.log(` Class size: ${valueBucket.equivalenceClassSize}`);
});
});
}
await kAnonymityWithEntityIds();PHP
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
use Google\Cloud\Dlp\V2\DlpServiceClient;
use Google\Cloud\Dlp\V2\RiskAnalysisJobConfig;
use Google\Cloud\Dlp\V2\BigQueryTable;
use Google\Cloud\Dlp\V2\DlpJob\JobState;
use Google\Cloud\Dlp\V2\Action;
use Google\Cloud\Dlp\V2\Action\SaveFindings;
use Google\Cloud\Dlp\V2\EntityId;
use Google\Cloud\Dlp\V2\PrivacyMetric\KAnonymityConfig;
use Google\Cloud\Dlp\V2\PrivacyMetric;
use Google\Cloud\Dlp\V2\FieldId;
use Google\Cloud\Dlp\V2\OutputStorageConfig;
/**
* Computes the k-anonymity of a column set in a Google BigQuery table with entity id.
*
* @param string $callingProjectId The project ID to run the API call under.
* @param string $datasetId The ID of the dataset to inspect.
* @param string $tableId The ID of the table to inspect.
* @param string[] $quasiIdNames Array columns that form a composite key (quasi-identifiers).
*/
function k_anonymity_with_entity_id(
// TODO(developer): Replace sample parameters before running the code.
string $callingProjectId,
string $datasetId,
string $tableId,
array $quasiIdNames
): void {
// Instantiate a client.
$dlp = new DlpServiceClient();
// Specify the BigQuery table to analyze.
$bigqueryTable = (new BigQueryTable())
->setProjectId($callingProjectId)
->setDatasetId($datasetId)
->setTableId($tableId);
// Create a list of FieldId objects based on the provided list of column names.
$quasiIds = array_map(
function ($id) {
return (new FieldId())
->setName($id);
},
$quasiIdNames
);
// Specify the unique identifier in the source table for the k-anonymity analysis.
$statsConfig = (new KAnonymityConfig())
->setEntityId((new EntityId())
->setField((new FieldId())
->setName('Name')))
->setQuasiIds($quasiIds);
// Configure the privacy metric to compute for re-identification risk analysis.
$privacyMetric = (new PrivacyMetric())
->setKAnonymityConfig($statsConfig);
// Specify the bigquery table to store the findings.
// The "test_results" table in the given BigQuery dataset will be created if it doesn't
// already exist.
$outBigqueryTable = (new BigQueryTable())
->setProjectId($callingProjectId)
->setDatasetId($datasetId)
->setTableId('test_results');
$outputStorageConfig = (new OutputStorageConfig())
->setTable($outBigqueryTable);
$findings = (new SaveFindings())
->setOutputConfig($outputStorageConfig);
$action = (new Action())
->setSaveFindings($findings);
// Construct risk analysis job config to run.
$riskJob = (new RiskAnalysisJobConfig())
->setPrivacyMetric($privacyMetric)
->setSourceTable($bigqueryTable)
->setActions([$action]);
// Submit request.
$parent = "projects/$callingProjectId/locations/global";
$job = $dlp->createDlpJob($parent, [
'riskJob' => $riskJob
]);
$numOfAttempts = 10;
do {
printf('Waiting for job to complete' . PHP_EOL);
sleep(10);
$job = $dlp->getDlpJob($job->getName());
if ($job->getState() == JobState::DONE) {
break;
}
$numOfAttempts--;
} while ($numOfAttempts > 0);
// Print finding counts
printf('Job %s status: %s' . PHP_EOL, $job->getName(), JobState::name($job->getState()));
switch ($job->getState()) {
case JobState::DONE:
$histBuckets = $job->getRiskDetails()->getKAnonymityResult()->getEquivalenceClassHistogramBuckets();
foreach ($histBuckets as $bucketIndex => $histBucket) {
// Print bucket stats.
printf('Bucket %s:' . PHP_EOL, $bucketIndex);
printf(
' Bucket size range: [%s, %s]' . PHP_EOL,
$histBucket->getEquivalenceClassSizeLowerBound(),
$histBucket->getEquivalenceClassSizeUpperBound()
);
// Print bucket values.
foreach ($histBucket->getBucketValues() as $percent => $valueBucket) {
// Pretty-print quasi-ID values.
printf(' Quasi-ID values:' . PHP_EOL);
foreach ($valueBucket->getQuasiIdsValues() as $index => $value) {
print(' ' . $value->serializeToJsonString() . PHP_EOL);
}
printf(
' Class size: %s' . PHP_EOL,
$valueBucket->getEquivalenceClassSize()
);
}
}
break;
case JobState::FAILED:
printf('Job %s had errors:' . PHP_EOL, $job->getName());
$errors = $job->getErrors();
foreach ($errors as $error) {
var_dump($error->getDetails());
}
break;
case JobState::PENDING:
printf('Job has not completed. Consider a longer timeout or an asynchronous execution model' . PHP_EOL);
break;
default:
printf('Unexpected job state. Most likely, the job is either running or has not yet started.');
}
}Python
Sensitive Data Protection의 클라이언트 라이브러리를 설치하고 사용하는 방법은 Sensitive Data Protection 클라이언트 라이브러리를 참조하세요.
Sensitive Data Protection에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
import time
from typing import List
import google.cloud.dlp_v2
from google.cloud.dlp_v2 import types
def k_anonymity_with_entity_id(
project: str,
source_table_project_id: str,
source_dataset_id: str,
source_table_id: str,
entity_id: str,
quasi_ids: List[str],
output_table_project_id: str,
output_dataset_id: str,
output_table_id: str,
) -> None:
"""Uses the Data Loss Prevention API to compute the k-anonymity using entity_id
of a column set in a Google BigQuery table.
Args:
project: The Google Cloud project id to use as a parent resource.
source_table_project_id: The Google Cloud project id where the BigQuery table
is stored.
source_dataset_id: The id of the dataset to inspect.
source_table_id: The id of the table to inspect.
entity_id: The column name of the table that enables accurately determining k-anonymity
in the common scenario wherein several rows of dataset correspond to the same sensitive
information.
quasi_ids: A set of columns that form a composite key.
output_table_project_id: The Google Cloud project id where the output BigQuery table
is stored.
output_dataset_id: The id of the output BigQuery dataset.
output_table_id: The id of the output BigQuery table.
"""
# Instantiate a client.
dlp = google.cloud.dlp_v2.DlpServiceClient()
# Location info of the source BigQuery table.
source_table = {
"project_id": source_table_project_id,
"dataset_id": source_dataset_id,
"table_id": source_table_id,
}
# Specify the bigquery table to store the findings.
# The output_table_id in the given BigQuery dataset will be created if it doesn't
# already exist.
dest_table = {
"project_id": output_table_project_id,
"dataset_id": output_dataset_id,
"table_id": output_table_id,
}
# Convert quasi id list to Protobuf type
def map_fields(field: str) -> dict:
return {"name": field}
# Configure column names of quasi-identifiers to analyze
quasi_ids = map(map_fields, quasi_ids)
# Tell the API where to send a notification when the job is complete.
actions = [{"save_findings": {"output_config": {"table": dest_table}}}]
# Configure the privacy metric to compute for re-identification risk analysis.
# Specify the unique identifier in the source table for the k-anonymity analysis.
privacy_metric = {
"k_anonymity_config": {
"entity_id": {"field": {"name": entity_id}},
"quasi_ids": quasi_ids,
}
}
# Configure risk analysis job.
risk_job = {
"privacy_metric": privacy_metric,
"source_table": source_table,
"actions": actions,
}
# Convert the project id into a full resource id.
parent = f"projects/{project}/locations/global"
# Call API to start risk analysis job.
response = dlp.create_dlp_job(
request={
"parent": parent,
"risk_job": risk_job,
}
)
job_name = response.name
print(f"Inspection Job started : {job_name}")
# Waiting for a maximum of 15 minutes for the job to be completed.
job = dlp.get_dlp_job(request={"name": job_name})
no_of_attempts = 30
while no_of_attempts > 0:
# Check if the job has completed
if job.state == google.cloud.dlp_v2.DlpJob.JobState.DONE:
break
if job.state == google.cloud.dlp_v2.DlpJob.JobState.FAILED:
print("Job Failed, Please check the configuration.")
return
# Sleep for a short duration before checking the job status again
time.sleep(30)
no_of_attempts -= 1
# Get the DLP job status
job = dlp.get_dlp_job(request={"name": job_name})
if job.state != google.cloud.dlp_v2.DlpJob.JobState.DONE:
print("Job did not complete within 15 minutes.")
return
# Create helper function for unpacking values
def get_values(obj: types.Value) -> str:
return str(obj.string_value)
# Print out the results.
print(f"Job name: {job.name}")
histogram_buckets = (
job.risk_details.k_anonymity_result.equivalence_class_histogram_buckets
)
# Print bucket stats
for i, bucket in enumerate(histogram_buckets):
print(f"Bucket {i}:")
if bucket.equivalence_class_size_lower_bound:
print(
f"Bucket size range: [{bucket.equivalence_class_size_lower_bound}, "
f"{bucket.equivalence_class_size_upper_bound}]"
)
for value_bucket in bucket.bucket_values:
print(
f"Quasi-ID values: {get_values(value_bucket.quasi_ids_values[0])}"
)
print(f"Class size: {value_bucket.equivalence_class_size}")
else:
print("No findings.")