목표
Dataproc Hub를 사용하여 Dataproc 클러스터에서 실행되는 단일 사용자 JupyterLab 노트북 환경을 만듭니다.
노트북 만들기 및 Dataproc 클러스터에서 Spark 작업 실행하기
클러스터 삭제 및 Cloud Storage에 노트북 보존하기
시작하기 전에
- 관리자는
notebooks.instances.use권한을 부여해야 합니다(Identity and Access Management(IAM) 역할 설정 참조).
Dataproc Hub에서 Dataproc JupyterLab 클러스터 만들기
Google Cloud 콘솔의 Dataproc→Workbench 페이지에서 사용자 관리 노트북 탭을 선택합니다.
관리자가 만든 Dataproc Hub 인스턴스가 나열된 행에서 JupyterLab 열기를 클릭합니다.
- Google Cloud 콘솔에 액세스할 수 없다면 관리자가 공유한 Dataproc Hub 인스턴스 URL을 웹브라우저에 입력합니다.
Jupyterhub→Dataproc 옵션 페이지에서 클러스터 구성과 영역을 선택합니다. 사용 설정되면 맞춤설정을 지정한 후 만들기를 클릭합니다.
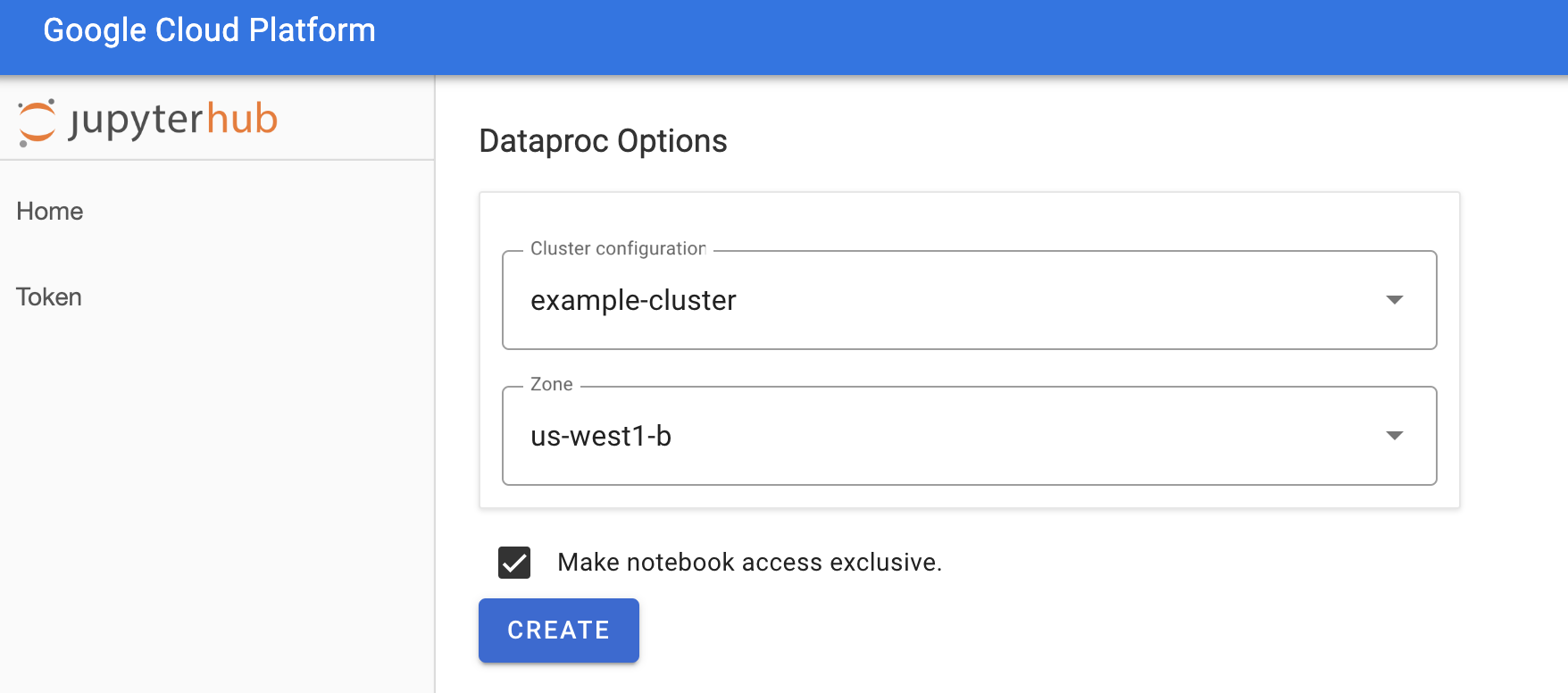
Dataproc 클러스터가 생성되면 클러스터에서 실행 중인 JupyterLab 인터페이스로 리디렉션됩니다.
노트북 만들기 및 Spark 작업 실행
JupyterLab 인터페이스 왼쪽 패널에서
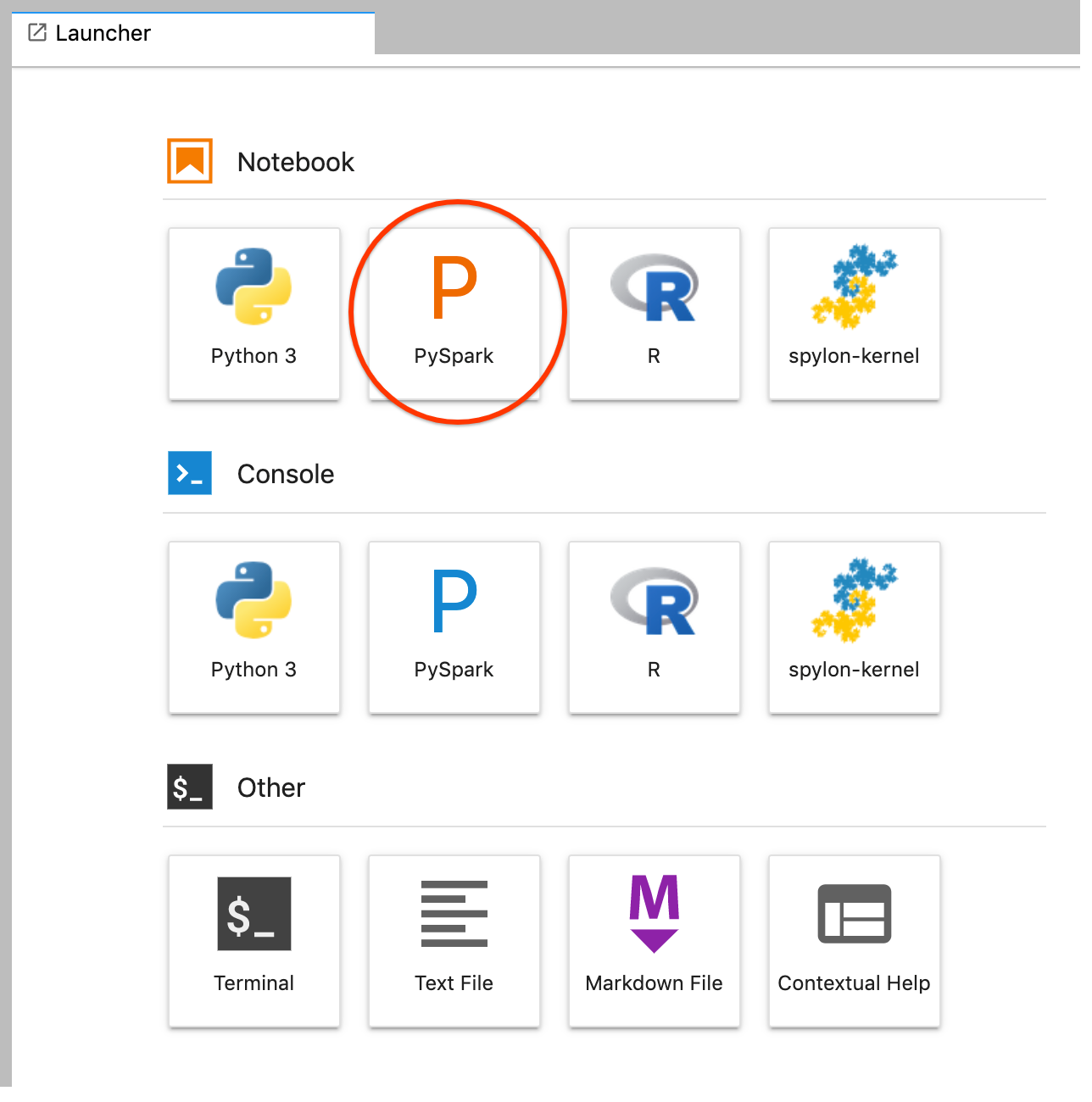
GCS(Cloud Storage)를 클릭합니다.JupyterLab 런처에서 PySpark 노트북을 만듭니다.
PySpark 커널은 SparkContext를 초기화합니다(
sc변수 사용). SparkContext를 검사하고 노트북에서 Spark 작업을 실행할 수 있습니다.rdd = (sc.parallelize(['lorem', 'ipsum', 'dolor', 'sit', 'amet', 'lorem']) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b)) print(rdd.collect())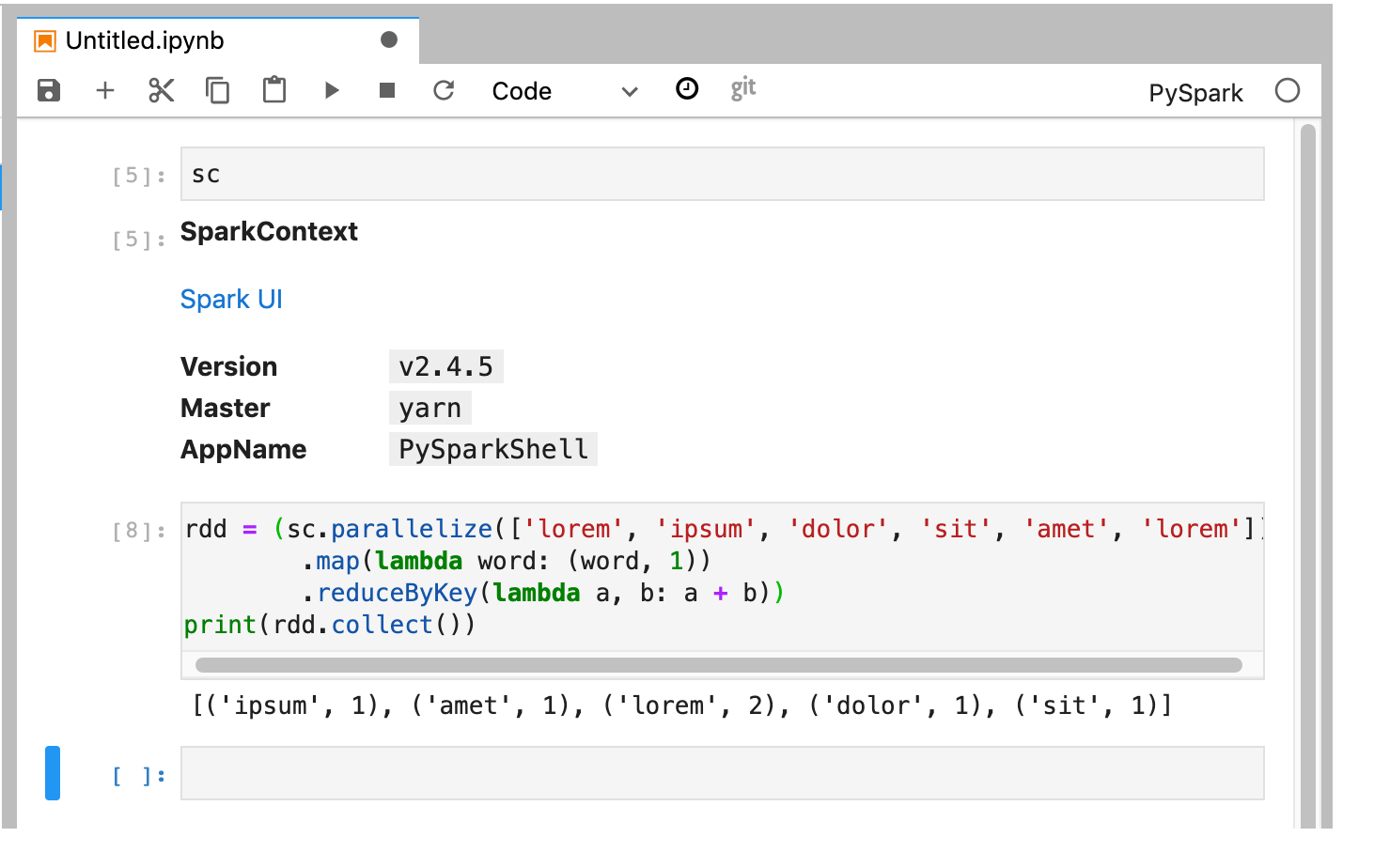
노트북의 이름을 지정하고 저장합니다. 노트북은 Dataproc 클러스터가 삭제된 후에도 Cloud Storage에 저장되고 유지됩니다.
Dataproc 클러스터 종료
JupyterLab 인터페이스에서 파일→Hub 제어판을 선택하여 Jupyterhub 페이지를 엽니다.
내 클러스터 중지를 클릭하여 Dataproc 클러스터를 삭제하는 JupyterLab 서버를 종료(삭제)합니다.
다음 단계
- GitHub에서 Dataproc의 Spark 및 Jupyter 노트북 살펴보기