Dataplex ist eine Datenstruktur, die verteilte Daten zusammenführt und die Datenverwaltung und Governance für diese Daten automatisiert.
Mit Dataplex haben Sie folgende Möglichkeiten:
- Erstellen Sie ein domainspezifisches Data Mesh über Daten hinweg, die in mehreren Google Cloud-Projekten gespeichert sind, ohne Daten zu verschieben.
- Daten mit einer einzigen Berechtigungsgruppe einheitlich verwalten und überwachen
- Mithilfe von Katalogfunktionen Metadaten in verschiedenen Silos finden und zusammenstellen Weitere Informationen finden Sie in der Übersicht zu Dataplex-Katalog.
- Metadaten sicher mit BigQuery und Open-Source-Tools wie SparkSQL, Presto und HiveQL abfragen
- Aufgaben zur Verwaltung der Datenqualität und des Datenlebenszyklus ausführen, einschließlich serverloser Lösungen Spark-Aufgaben.
- Daten mit vollständig verwalteten, serverlosen Spark-Umgebungen mit einfachem Zugriff auf Notebooks und SparkSQL-Abfragen analysieren
Vorteile von Dataplex
Die Daten sind in Unternehmen auf Data Lakes, Data Warehouses Data-Marts. Mit Dataplex haben Sie folgende Möglichkeiten:
- Daten erkennen
- Daten auswählen
- Daten ohne Datenverschiebung zusammenführen
- Daten basierend auf Ihren Geschäftsanforderungen organisieren
- Daten zentral verwalten, überwachen und steuern
Mit Dataplex können Sie Metadaten standardisieren und vereinheitlichen, Sicherheitsrichtlinien, Governance, Klassifizierung und Verwaltung des Datenlebenszyklus in diesen verteilten Daten verwendet werden.
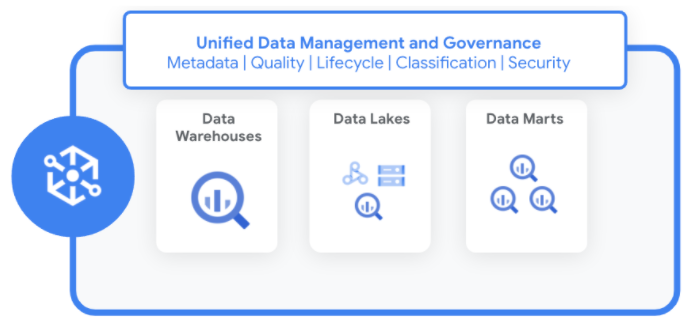
Funktionsweise von Dataplex
Dataplex verwaltet Daten so, dass keine Datenverschiebung erforderlich ist oder Vervielfältigung. Wenn Sie neue Datenquellen identifizieren, erfasst Dataplex die Metadaten sowohl von strukturierten als auch unstrukturierten Daten. Dabei kommen integrierte Datenqualitätsprüfungen zum Einsatz, um die Integrität zu verbessern.
Dataplex registriert alle Metadaten automatisch in einem einheitlichen Metastore. Sie können mithilfe verschiedener Dienste und Tools auf Daten und Metadaten zugreifen einschließlich der folgenden:
- Google Cloud-Dienste wie BigQuery, Dataproc Metastore und Data Catalog
- Open-Source-Tools wie Apache Spark und Presto
Terminologie
Dataplex abstrahiert die zugrunde liegenden Datenspeichersysteme, mithilfe der folgenden Konstrukte:
Lake: Ein logisches Konstrukt, das eine Datendomain oder eine Geschäftseinheit darstellt. Wenn Sie Daten beispielsweise nach Gruppennutzung organisieren möchten, können Sie einen Data Lake für jede Abteilung einrichten (z. B. Einzelhandel, Vertrieb, Finanzen).
Zone: Eine Subdomain innerhalb eines Data Lakes, die sich zum Kategorisieren von Daten nach folgenden Kriterien eignet:
- Phase: Zum Beispiel Landingpage, Rohdaten, kuratierte Datenanalysen und kuratierte Daten Wissenschaft.
- Verwendung: z. B. Datenvertrag.
- Einschränkungen: z. B. Sicherheitsmaßnahmen und Nutzerzugriffsebenen.
Es gibt zwei Arten von Zonen: Rohdaten und kuratierte Daten.
Raw-Zone: Enthält Daten im Rohformat, die keiner strengen Typprüfung unterliegen.
Ausgewählte Zone: Enthält Daten, die bereinigt, formatiert und einsatzbereit sind. Analytics. Die Daten sind spaltenbasiert, mit Hive partitioniert und in Parquet-, Avro-, Orc-Dateien oder BigQuery-Tabellen gespeichert. Die Daten werden typgeprüft, um beispielsweise die Verwendung von CSV-Dateien zu verhindern, da sie beim SQL-Zugriff nicht so leistungsfähig sind.
Asset: Wird Daten zugeordnet, die entweder in Cloud Storage oder BigQuery gespeichert sind. Sie können Daten, die in separaten Google Cloud-Projekten als Assets gespeichert sind, einer einzelnen Zone zuordnen.
Entität: Stellt Metadaten für strukturierte und semistrukturierte Daten (Tabelle) und unstrukturierte Daten (Dateisatz) dar.
Gängige Anwendungsfälle
In diesem Abschnitt werden häufige Anwendungsfälle für die Verwendung von Dataplex beschrieben.
Ein domainzentriertes Daten-Mesh
Bei dieser Art von Data Mesh werden Daten in mehreren Domains innerhalb eines Unternehmens organisiert, z. B. in den Bereichen Vertrieb, Kunden und Produkte. Die Eigentumsrechte an den Daten können dezentralisiert sein. Sie können Daten von verschiedenen Domains abonnieren. So können Datenwissenschaftler und Datenanalysten beispielsweise auf verschiedene Bereiche zurückgreifen, um Geschäftsziele wie maschinelles Lernen und Business Intelligence zu erreichen.
Im folgenden Diagramm werden Domains durch Dataplex dargestellt Data Lakes und separaten Datenerstellern. Datenersteller sind für die Erstellung, Kuratierung und Zugriffssteuerung in ihren Domains verantwortlich. Datenkonsumenten können dann Zugriff auf die Lakes (Domains) oder Zonen (Subdomains) für ihre Analyse.
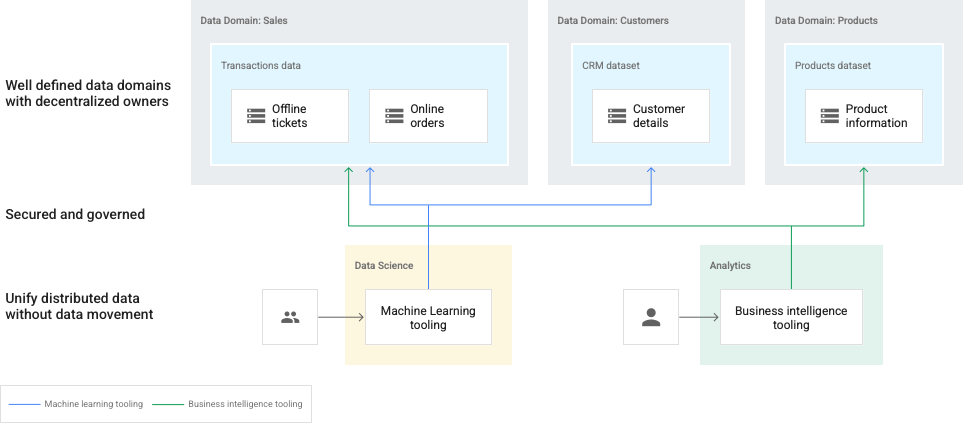
In diesem Fall müssen Datenverwalter einen ganzheitlichen Überblick über die gesamte Datenlandschaft behalten.
Dieses Diagramm enthält die folgenden Elemente:
- Dataplex: Ein Mesh-Netzwerk aus mehreren Datendomains.
- Domain: Datenseen für Verkäufe, Kunden und Produktdaten.
- Zone innerhalb einer Domain: für einzelne Teams oder zum Bereitstellen verwalteter Daten Verträge.
- Assets: Daten, die entweder in einem Cloud Storage-Bucket oder in einem BigQuery-Dataset, das in einer separaten Google Cloud vorhanden sein kann aus Ihrem Dataplex-Mesh abgerufen.
Sie können dieses Szenario erweitern, indem Sie Daten innerhalb der Zonen in Rohdaten untergliedern. und ausgewählte Ebenen. Sie können diesen Ansatz erreichen, indem Sie Zonen für jede Permutation einer Domain und Rohdaten oder kuratierte Daten:
- Rohdaten zu Verkäufen
- Ausgewählte Verkäufe
- Bestandskund*innen
- Von Nutzern zusammengestellt
- Rohprodukte
- Ausgewählte Produkte
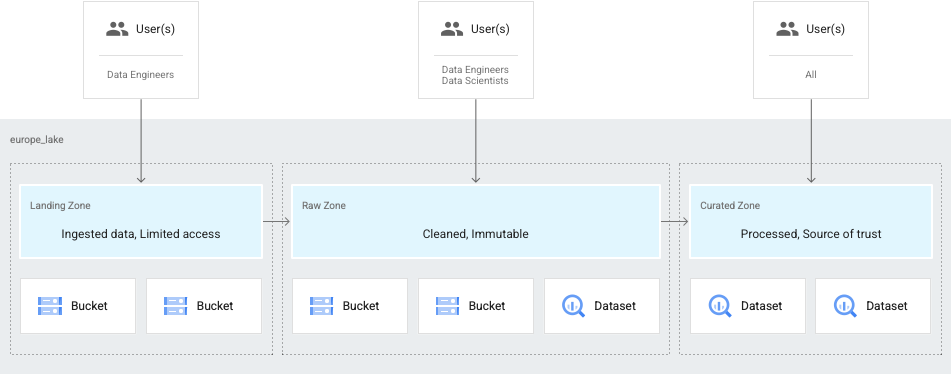
Datenstufen basierend auf der Bereitschaft
Ein weiterer häufiger Anwendungsfall ist, wenn Ihre Daten nur für Data Engineers zugänglich sind, und wird später optimiert und für Data Scientists und Analysten verfügbar gemacht. In diesem Fall können Sie einen See so einrichten, dass er Folgendes hat:
- Eine Rohzone für die Daten, auf die das Engineering-Team zugreifen kann.
- Eine kuratierte Zone für die Daten, die für Data Scientists und Analysten verfügbar sind.
Nächste Schritte
- Erste Schritte mit Dataplex
- Data-Mesh erstellen
- Lake erstellen
- Katalogfunktionen in Dataplex entdecken