Dataplex adalah data fabric yang menyatukan data terdistribusi dan mengotomatiskan pengelolaan dan tata kelola data untuk data tersebut.
Dataplex memungkinkan Anda melakukan hal berikut:
- Buat mesh data khusus domain di seluruh data yang disimpan di beberapa projectGoogle Cloud , tanpa perpindahan data apa pun.
- Kelola dan pantau data secara konsisten dengan satu kumpulan izin.
- Temukan dan pilih metadata di berbagai silo menggunakan kemampuan katalog. Untuk mengetahui informasi selengkapnya, lihat Ringkasan Katalog Dataplex.
- Buat kueri metadata dengan aman menggunakan BigQuery dan alat open source, seperti Spark SQL, Presto, dan HiveQL.
- Menjalankan tugas pengelolaan siklus proses dan kualitas data, termasuk tugas Spark serverless.
- (Tidak digunakan lagi) Jelajahi data menggunakan lingkungan Spark serverless yang terkelola sepenuhnya dengan akses ke notebook dan kueri Spark SQL.
Mengapa menggunakan Dataplex?
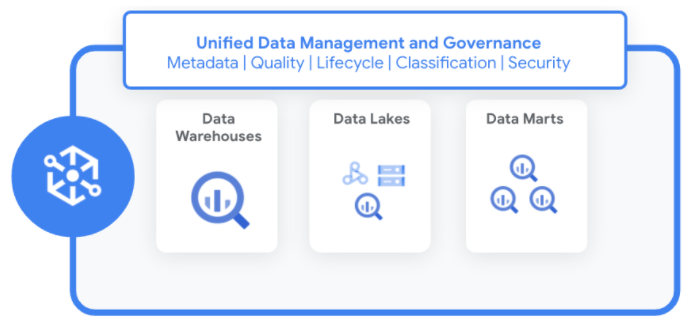
Perusahaan memiliki data yang didistribusikan di seluruh data lake, data warehouse, dan data mart. Dengan Dataplex, Anda dapat melakukan hal berikut:
- Data Discover
- Seleksi data
- Menyatukan data tanpa pemindahan data
- Mengatur data berdasarkan kebutuhan bisnis Anda
- Mengelola, memantau, dan mengatur data secara terpusat
Dataplex memungkinkan Anda menstandarkan dan menyatukan metadata, kebijakan keamanan, tata kelola, klasifikasi, dan pengelolaan siklus proses data di seluruh data terdistribusi ini.
Cara kerja Dataplex
Dataplex mengelola data dengan cara yang tidak memerlukan perpindahan atau duplikasi data. Saat Anda mengidentifikasi sumber data baru, Dataplex mengumpulkan metadata untuk data terstruktur dan tidak terstruktur, menggunakan pemeriksaan kualitas data bawaan untuk meningkatkan integritas.
Dataplex secara otomatis mendaftarkan semua metadata di metastore terpadu. Anda dapat mengakses data dan metadata menggunakan berbagai layanan dan alat, termasuk:
- Layanan dan fiturGoogle Cloud , seperti BigQuery, Dataproc Metastore, dan Dataplex Catalog.
- Alat open source, seperti Apache Spark dan Presto.
Terminologi
Dataplex memisahkan sistem penyimpanan data yang mendasarinya, dengan menggunakan konstruksi berikut:
Data lake: Konstruksi logis yang mewakili domain data atau unit bisnis. Misalnya, untuk mengatur data berdasarkan penggunaan grup, Anda dapat menyiapkan data lake untuk setiap departemen (misalnya, retail, penjualan, keuangan).
Zona: Subdomain dalam data lake, yang berguna untuk mengategorikan data berdasarkan hal berikut:
- Tahap: misalnya, landing, analisis data mentah, kurasi, dan data science kurasi
- Penggunaan: misalnya, kontrak data
- Batasan: misalnya, kontrol keamanan dan tingkat akses pengguna
Ada dua jenis zona:
Zona mentah: berisi data dalam format mentah dan tidak tunduk pada pemeriksaan jenis yang ketat.
Zona pilihan: berisi data yang sudah dibersihkan, diformat, dan siap untuk analisis. Data berbentuk kolom, dipartisi Hive, dan disimpan dalam file Parquet, Avro, Orc, atau tabel BigQuery. Data akan melalui pemeriksaan jenis, misalnya, untuk melarang penggunaan file CSV karena performanya tidak sebaik untuk akses SQL.
Aset: dipetakan ke data yang disimpan di Cloud Storage atau BigQuery. Anda dapat memetakan data yang disimpan dalam project Google Cloud terpisah sebagai aset ke dalam satu zona.
Entitas: mewakili metadata untuk data terstruktur dan semiterstruktur (misalnya, tabel), dan data tidak terstruktur (misalnya, set file).
Kasus penggunaan umum
Bagian ini menguraikan kasus penggunaan umum untuk menggunakan Dataplex.
Mesh data yang berfokus pada domain
Dengan jenis mesh data ini, data diatur ke dalam beberapa domain dalam
perusahaan—misalnya, Sales, Customers, dan Products. Anda dapat
mendesentralisasi kepemilikan data. Anda dapat berlangganan data dari berbagai
domain. Misalnya, data scientist dan data analyst dapat mengambil dari berbagai
domain untuk mencapai tujuan bisnis seperti machine learning dan business
intelligence.
Dalam diagram berikut, domain diwakili oleh data lake Dataplex dan dimiliki oleh produser data terpisah. Produsen data memiliki kontrol pembuatan, pemilihan, dan akses di domain mereka. Konsumen data kemudian dapat meminta akses ke data lake (domain) atau zona (subdomain) untuk analisis mereka.
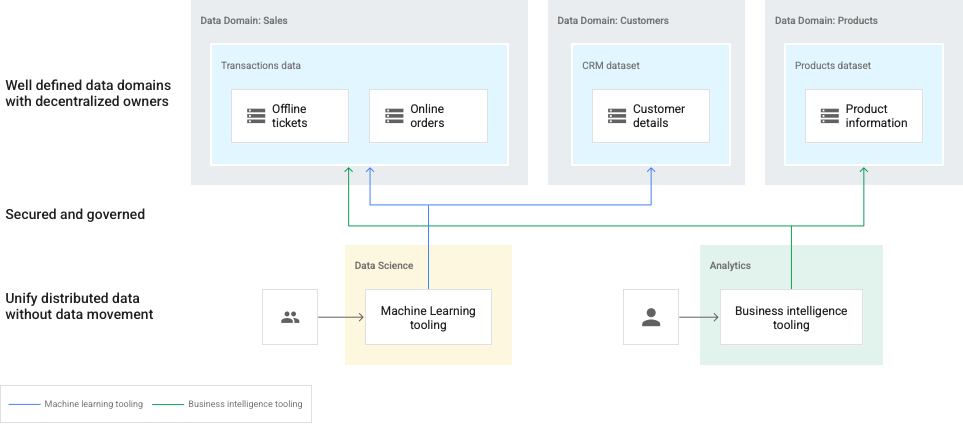
Dalam hal ini, pengelola data perlu mempertahankan pandangan menyeluruh tentang seluruh lanskap data.
Diagram ini mencakup elemen berikut:
- Dataplex: mesh dari beberapa domain data
- Domain: data lake untuk data
Sales,Customers, danProduct - Zona dalam domain: untuk setiap tim atau untuk menyediakan kontrak data terkelola
- Aset: data yang disimpan di bucket Cloud Storage atau set data BigQuery, yang dapat berada dalam project Google Cloudterpisah dari mesh Dataplex Anda
Anda dapat memperluas skenario ini dengan mengelompokkan data yang berada dalam zona menjadi lapisan mentah dan yang diseleksi. Anda dapat melakukan pendekatan ini dengan membuat zona untuk setiap permutasi domain dan data mentah atau yang diseleksi:
- Penjualan mentah
- Penjualan yang diseleksi
- Pelanggan mentah
- Dikurasi pelanggan
- Produk mentah
- Produk pilihan
Tingkatan data berdasarkan kesiapan
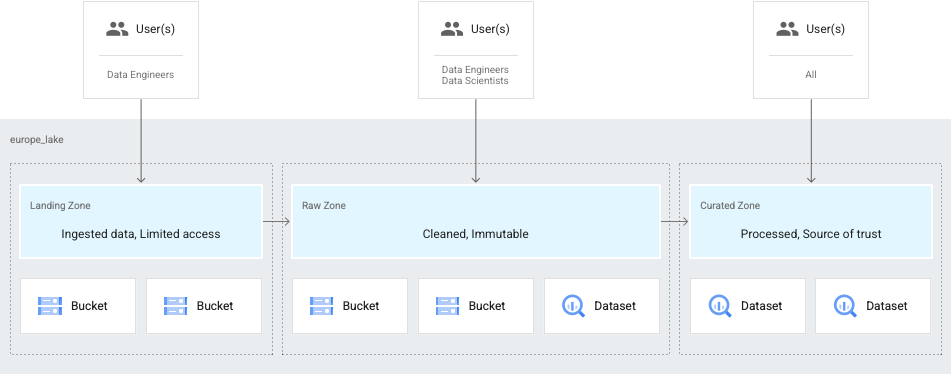
Kasus penggunaan umum lainnya adalah saat data Anda hanya dapat diakses oleh engineer data, lalu dioptimalkan dan disediakan untuk data scientist dan analis. Dalam hal ini, Anda dapat menyiapkan lake untuk memiliki hal berikut:
- Zona landing untuk data yang dapat diakses engineer.
- Zona mentah untuk data yang tersedia bagi ilmuwan data dan analis.
Langkah berikutnya
- Mulai menggunakan Dataplex
- Membuat mesh data
- Membuat data lake
- Menemukan kemampuan katalog di Dataplex