Dataplex è un data fabric che unifica i dati distribuiti e automatizza la gestione e la governance dei dati.
Dataplex ti consente di:
- Creare un mesh di dati specifici di dominio tra quelli archiviati in più progetti Google Cloud, senza che debbano essere spostati.
- Governare e monitorare i dati in modo coerente con un unico set di autorizzazioni.
- Trova e seleziona i metadati in vari silos utilizzando le funzionalità di catalogo. Per saperne di più, consulta la panoramica di Dataplex Catalog.
- Esegui query sui metadati in modo sicuro utilizzando BigQuery e strumenti open source, come Spark SQL, Presto e HiveQL.
- Eseguire attività relative alla qualità dei dati e alla gestione del loro ciclo di vita, comprese le attività Spark serverless.
- (Ritirata) Esplora i dati utilizzando ambienti Spark completamente gestiti e serverless con accesso a blocchi note e query Spark SQL.
Perché utilizzare Dataplex?
Le aziende hanno dati distribuiti su data lake, data warehouse e data mart. Con Dataplex, puoi:
- Dati rilevati
- Seleziona i dati
- Unifica i dati senza spostarli
- Organizza i dati in base alle esigenze della tua attività
- Gestire, monitorare e governare i dati a livello centralizzato
Dataplex ti consente di standardizzare e unificare i metadati, i criteri di sicurezza, la governance, la classificazione e la gestione del ciclo di vita dei dati tra questi dati distribuiti.
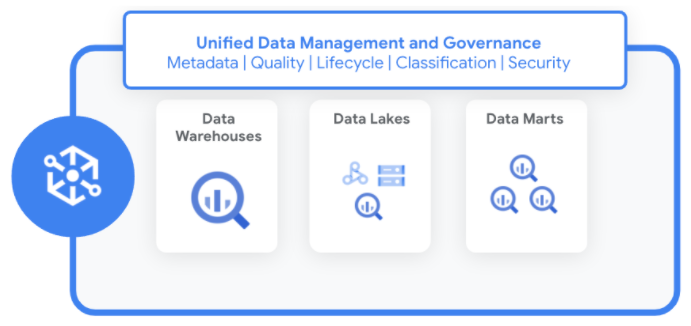
Come funziona Dataplex
Dataplex gestisce i dati in un modo da non richiedere lo spostamento o la duplicazione dei dati. Man mano che identifichi nuove origini dati, Dataplex raccoglie i metadati sia per i dati strutturati che per quelli non strutturati, utilizzando i controlli di qualità dei dati integrati per migliorare l'integrità.
Dataplex registra automaticamente tutti i metadati in un metastore unificato. Puoi accedere a dati e metadati utilizzando vari servizi e strumenti, tra cui:
- Servizi Google Cloud, come BigQuery, Dataproc Metastore, Data Catalog.
- Strumenti open source come Apache Spark e Presto.
Terminologia
Dataplex esegue l'astrazione dei sistemi di archiviazione dei dati sottostanti utilizzando i seguenti costrutti:
Lake: un costrutto logico che rappresenta un dominio dati o un'unità aziendale. Ad esempio, per organizzare i dati in base all'utilizzo del gruppo, puoi configurare un lake per ogni reparto (ad esempio, vendita al dettaglio, vendite, finanza).
Zona: un sottodominio all'interno di un lake, utile per classificare i dati in base a quanto segue:
- Fase: ad esempio, analisi dei dati non elaborati, curati, di destinazione e data science curata
- Utilizzo: ad esempio, contratto di dati
- Limitazioni: ad esempio, controlli di sicurezza e livelli di accesso utente
Esistono due tipi di zone:
Zona non elaborata: contiene dati nel formato non elaborato e non soggetti a un rigoroso controllo del tipo.
Zona selezionata: contiene dati puliti, formattati e pronti per l'analisi. I dati sono colonnari, partizionati da Hive e archiviati in file Parquet, Avro, ORC o tabelle BigQuery. I dati vengono sottoposti a controllo di tipo, ad esempio per vietare l'uso di file CSV perché hanno un rendimento inferiore per l'accesso SQL.
Asset: mappa i dati archiviati in Cloud Storage o BigQuery. Puoi mappare i dati archiviati in progetti Google Cloud separati come asset in una singola zona.
Entità: rappresenta i metadati per i dati strutturati e semistrutturati (ad es. tabella) e non strutturati (ad es. set di file).
Casi d'uso comuni
Questa sezione illustra i casi d'uso comuni di Dataplex.
Un data mesh incentrato sul dominio
Con questo tipo di mesh di dati, i dati sono organizzati in più domini all'interno di un'azienda, ad esempio Sales, Customers e Products. Puoi
decentralizzare la proprietà dei dati. Puoi iscriverti ai dati di diversi
domini. Ad esempio, i data scientist e gli analisti di dati possono estrarre informazioni da diversi ambiti per raggiungere obiettivi aziendali come il machine learning e l'analisi di business.
Nel seguente diagramma, i domini sono rappresentati da lake Dataplex e sono di proprietà di produttori di dati distinti. I produttori di dati sono proprietari della creazione, della selezione e controllo dell'accesso nei propri domini. I consumatori di dati possono quindi richiedere accesso ai lake (domini) o alle zone (sottodomini) per le loro analisi.
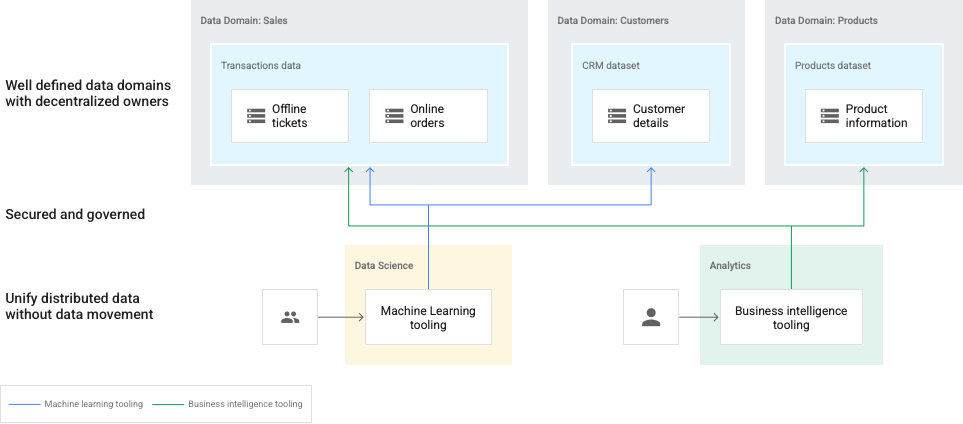
In questo caso, gli steward dei dati devono mantenere una visione olistica dell'intero panorama dei dati.
Questo diagramma include i seguenti elementi:
- Dataplex: un mesh di più domini di dati
- Dominio: lake per i dati di
Sales,CustomerseProduct - Zona all'interno di un dominio: per singoli team o per fornire contratti di gestione dei dati
- Asset: dati archiviati in un bucket Cloud Storage o in un set di dati BigQuery, che possono trovarsi in un progetto Google Cloud distinto dal tuo mesh Dataplex
Puoi estendere questo scenario suddividendo i dati all'interno delle zone in livelli non elaborati e selezionati. Puoi realizzare questo approccio creando zone per ogni permutazione di un dominio e dati non elaborati o selezionati:
- Dati non elaborati sulle vendite
- Selezionate
- Dati non elaborati dei clienti
- Clienti selezionati
- Prodotti non elaborati
- Prodotti selezionati
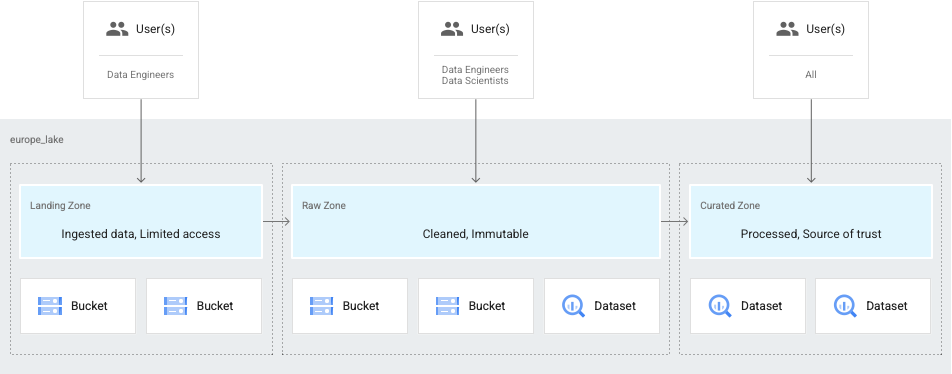
Livelli di dati in base alla preparazione
Un altro caso d'uso comune è quando i dati sono accessibili solo ai data engineer, e in un secondo momento vengono perfezionati e resi disponibili a data scientist e analisti. In questo caso, puoi configurare un lake in modo che abbia quanto segue:
- Una zona di destinazione per i dati a cui possono accedere gli ingegneri.
- Una zona non elaborata per i dati disponibili per i data scientist e gli analisti.
Passaggi successivi
- Inizia a utilizzare Dataplex
- Creare un mesh di dati
- Creare un lake
- Scopri le funzionalità del catalogo in Dataplex