Dataplex es un tejido de datos que unifica los datos distribuidos y automatiza la administración y el control de esos datos.
Dataplex te permite hacer lo siguiente:
- Compila una malla de datos específica del dominio en los datos almacenados en varios proyectos deGoogle Cloud sin mover los datos.
- Controlar y supervisar los datos de forma coherente con un solo conjunto de permisos.
- Descubre y selecciona metadatos en varios silos con las funciones de catálogo. Para obtener más información, consulta Descripción general de Dataplex Catalog.
- Consulta metadatos de forma segura con BigQuery y herramientas de código abierto, como Spark SQL, Presto y HiveQL.
- Ejecutar tareas de administración del ciclo de vida y la calidad de los datos, incluidas las tareas sin servidores de Spark
- (Obsoleto) Explorar los datos usando entornos sin servidores de Spark completamente administrados con acceso a notebooks y consultas en Spark SQL
¿Por qué usar Dataplex?
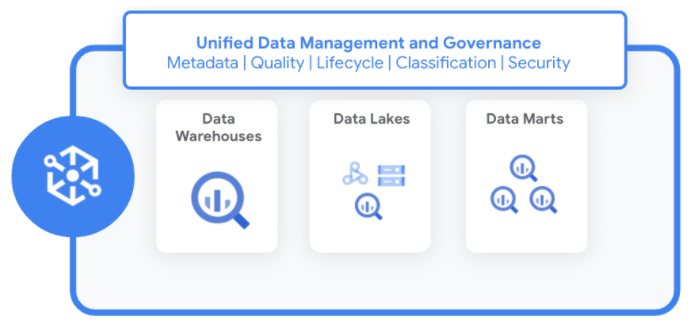
Las empresas tienen datos distribuidos en data lakes, almacenes de datos y data marts. Con Dataplex, puedes hacer lo siguiente:
- Datos descubiertos
- Selecciona los datos
- Unifica los datos sin moverlos
- Organiza los datos según las necesidades de tu empresa
- Administra, supervisa y controla los datos de forma centralizada
Dataplex te permite estandarizar y unificar los metadatos, las políticas de seguridad, el control, la clasificación y la administración del ciclo de vida de los datos en estos datos distribuidos.
Cómo funciona Dataplex
Dataplex administra los datos de un modo que no requiere movimientos ni duplicación de datos. A medida que identificas nuevas fuentes de datos, Dataplex recopila los metadatos de los datos estructurados y no estructurados mediante verificaciones de calidad de los datos integradas para mejorar la integridad.
Dataplex registra automáticamente todos los metadatos en un almacén de metadatos unificado. Puedes acceder a los datos y metadatos con varios servicios y herramientas, incluidos los siguientes:
- Google Cloud , como BigQuery, Dataproc Metastore y Data Catalog.
- Herramientas de código abierto, como Apache Spark y Presto
Terminología
Dataplex abstrae los sistemas de almacenamiento de datos subyacentes con las siguientes construcciones:
Data lake: Es una construcción lógica que representa un dominio de datos o una unidad de negocios. Por ejemplo, para organizar los datos en función del uso del grupo, puedes configurar un lake para cada departamento (por ejemplo, venta minorista, ventas, finanzas).
Zona: Es un subdominio dentro de un lake que es útil para categorizar los datos según lo siguiente:
- Etapa: por ejemplo, destino, análisis de datos sin procesar, seleccionados y ciencia de datos seleccionados
- Uso: por ejemplo, contrato de datos
- Restricciones: por ejemplo, controles de seguridad y niveles de acceso de los usuarios
Existen dos tipos de zonas:
Zona sin procesar: Contiene datos en formato sin procesar y no está sujeta a verificaciones estrictas de tipos.
Zona seleccionada: Contiene datos limpios, con formato y listos para el análisis. Los datos son de tipo columna, están particionados por Hive y se almacenan en archivos Parquet, Avro, ORC o tablas de BigQuery. Los datos se someten a una verificación de tipo, por ejemplo, para prohibir el uso de archivos CSV porque no tienen un buen rendimiento para el acceso a SQL.
Recurso: Se asigna a los datos almacenados en Cloud Storage o BigQuery. Puedes asignar datos almacenados en proyectos Google Cloud separados como recursos a una sola zona.
Entidad: Representa los metadatos de los datos estructurados y semiestructurados (por ejemplo, una tabla) y los datos no estructurados (por ejemplo, un conjunto de archivos).
Casos de uso habituales
En esta sección, se describen casos de uso comunes de Dataplex.
Una malla de datos centrada en el dominio
Con este tipo de malla de datos, los datos se organizan en varios dominios dentro de una
empresa, por ejemplo, Sales, Customers y Products. Puedes descentralizar la propiedad de los datos. Puedes suscribirte a datos de diferentes dominios. Por ejemplo, los científicos de datos y los analistas de datos pueden extraer información de diferentes dominios para lograr objetivos comerciales, como el aprendizaje automático y la inteligencia empresarial.
En el siguiente diagrama, los dominios están representados por lagos de Dataplex y son propiedad de productores de datos independientes. Los productores de datos son propietarios de la creación, la selección y el control de acceso en sus dominios. Luego, los consumidores de datos pueden solicitar acceso a los lakes (dominios) o zonas (subdominios) para su análisis.
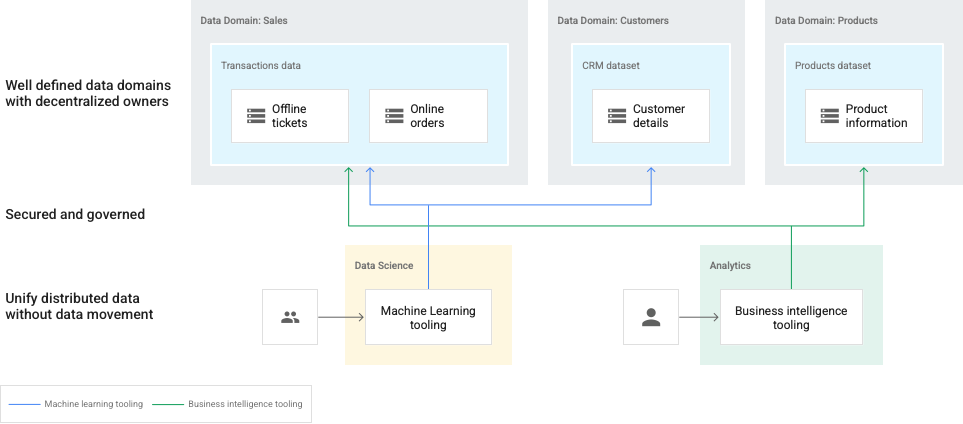
En este caso, los administradores de datos deben mantener una vista holística de todo el panorama de datos.
Este diagrama incluye los siguientes elementos:
- Dataplex: una malla de varios dominios de datos
- Dominio: Lagos para datos de
Sales,CustomersyProduct - Zona dentro de un dominio: Para equipos individuales o para proporcionar contratos de datos administrados
- Recursos: Datos almacenados en un bucket de Cloud Storage o un conjunto de datos de BigQuery, que pueden existir en un proyecto Google Cloudindependiente de tu malla de Dataplex
Puedes ampliar esta situación si desglosas los datos que se encuentran dentro de las zonas en capas sin procesar y seleccionadas. Para lograr este enfoque, crea zonas para cada variación de un dominio y datos sin procesar o seleccionados:
- Ventas sin procesar
- Fuentes seleccionadas
- Clientes sin procesar
- Clientes seleccionados
- Productos sin procesar
- Productos seleccionados
Agrupamiento de datos según el nivel de preparación
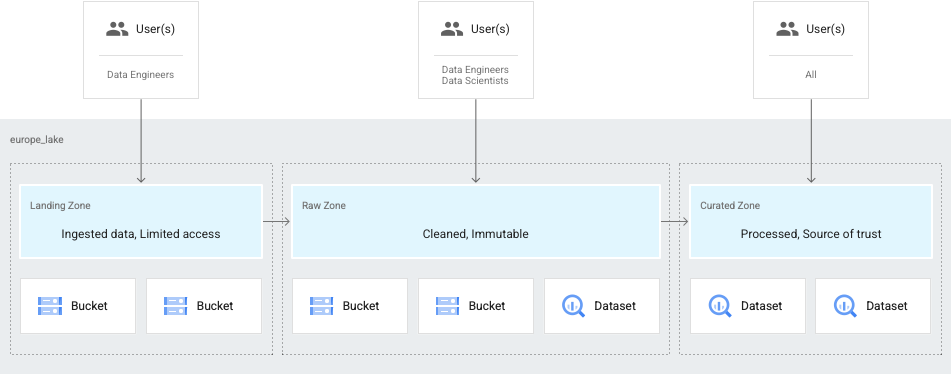
Otro caso de uso común es cuando únicamente los ingenieros de datos tienen acceso a tus datos y esos datos, luego, se definen mejor y se ponen a disposición de los analistas y científicos de datos. En este caso, puedes configurar un data lake para que tenga los siguientes elementos:
- Una zona de destino para los datos a los que pueden acceder los ingenieros.
- Una zona sin procesar para los datos que están disponibles para los científicos de datos y los analistas.
¿Qué sigue?
- Comienza a usar Dataplex
- Crea una malla de datos
- Cómo crear un lake
- Descubre las funciones del catálogo en Dataplex