Dataplex 是一种数据结构脉络,可统一分布式数据并自动执行数据管理和治理。
借助 Dataplex,您可以执行以下操作:
- 跨存储在多个Google Cloud 项目中的数据构建特定于领域的数据网格,而无需移动任何数据。
- 使用一组权限一致地治理和监控数据。
- 使用目录功能跨各种孤岛发现和管理元数据。 如需了解详情,请参阅 Dataplex Catalog 概览。
- 使用 BigQuery 和 Spark SQL、Presto 和 HiveQL 等开源工具安全地查询元数据。
- 运行数据质量和数据生命周期管理任务,包括无服务器 Spark 任务。
- (已弃用)使用全代管式无服务器 Spark 环境探索数据,并访问笔记本和 Spark SQL 查询。
为何使用 Dataplex?
企业的数据分布在数据湖、数据仓库和数据集市中。使用 Dataplex,您可以执行以下操作:
- 发现数据
- 管理数据
- 在不移动任何数据的情况下统一数据
- 根据业务需求整理数据
- 集中管理、监控和治理数据
借助 Dataplex,您可以对这些分布式数据的元数据、安全政策、治理、分类和数据生命周期管理进行标准化和统一。
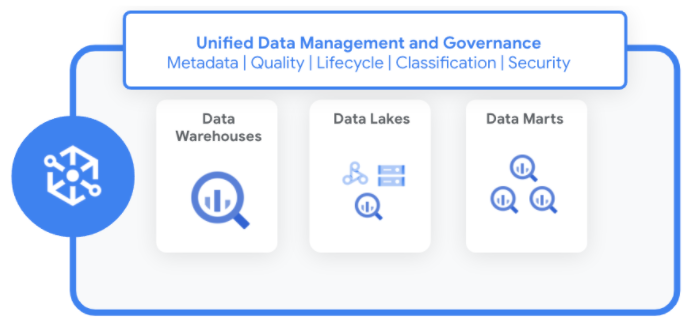
Dataplex 的工作原理
借助 Dataplex,您可以在不移动或复制数据的情况下管理数据。在您识别新数据源时,Dataplex 会利用内置数据质量检查功能收集结构化和非结构化数据的元数据,以增强完整性。
Dataplex 会自动将所有元数据注册到统一的 Metastore 中。您可以使用各种服务和工具(包括以下服务和工具)访问数据和元数据:
- Google Cloud 服务,例如 BigQuery、Dataproc Metastore、Data Catalog。
- Apache Spark 和 Presto 等开源工具。
术语
Dataplex 使用以下结构来提取底层数据存储系统:
数据湖:表示数据网域或业务部门的逻辑结构。例如,若要根据群组使用情况整理数据,您可以为每个部门(例如零售、销售、财务)设置一个数据湖。
区域:数据湖中的子网域,可用于按以下条件对数据进行分类:
- 阶段:例如着陆页、原始数据、管理的数据分析和管理的数据科学
- 用途:例如数据协定
- 限制:例如,安全控制措施和用户访问权限级别
区域有两种类型:
原始区域:包含原始格式的数据,不需要进行严格的类型检查。
精选区域:包含经过清理、格式化并准备好用于分析的数据。数据是列式、Hive 分区数据,并存储在 Parquet、Avro、ORC 文件或 BigQuery 表中。数据会接受类型检查,例如禁止使用 CSV 文件,因为它们在 SQL 访问方面表现不佳。
素材资源:映射到存储在 Cloud Storage 或 BigQuery 中的数据。 您可以将存储在单独的 Google Cloud 项目中的资产映射到单个可用区。
实体:表示结构化数据和半结构化数据(例如表)以及非结构化数据(例如文件集)的元数据。
常见使用场景
本部分概述了使用 Dataplex 的常见用例。
以网域为中心的数据网格
在这种数据网格中,数据会整理到企业内的多个领域(例如 Sales、Customers 和 Products)。您可以分散数据所有权。您可以订阅来自不同网域的数据。例如,数据科学家和数据分析师可以从不同的领域中提取数据,以实现机器学习和商业智能等业务目标。
在下图中,网域由 Dataplex 数据湖表示,由不同的数据生产者拥有。数据生产者负责在其网域中进行创建、管理和访问权限控制。然后,数据使用者可以请求访问数据湖(网域)或区域(子网域),以进行分析。
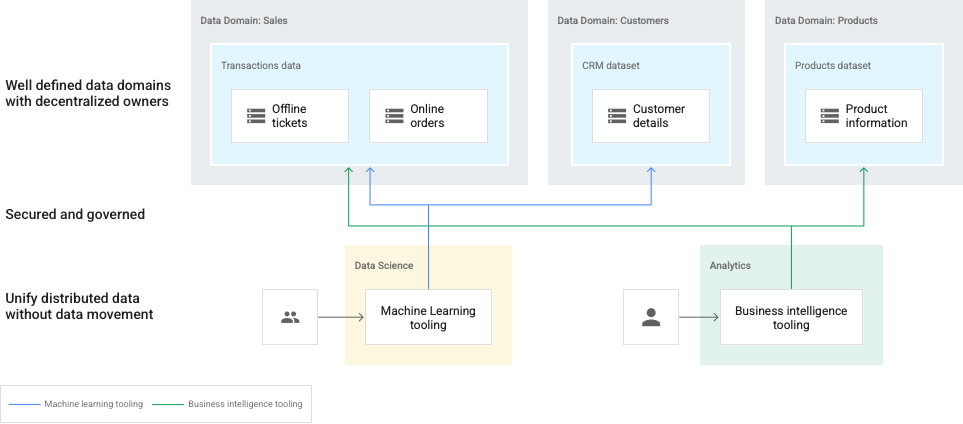
在这种情况下,数据管理员需要保留对整个数据环境的整体视图。
该图包含以下元素:
- Dataplex:多个数据网域的网格
- 领域:
Sales、Customers和Product数据的数据湖 - 网域内的区域:适用于各个团队或提供受管数据协定
- 资产:存储在 Cloud Storage 存储桶或 BigQuery 数据集中的数据,这些数据可以存在于与 Dataplex 网格的 Google Cloud项目不同的项目中
您可以将区域内的数据细分为原始图层和经过整理的图层,从而扩展此场景。您可以通过为网域和原始数据或经过整理的数据的每个排列创建可用区来实现此方法:
- 销售原始数据
- 精选的销售
- 客户(原始)
- 由客户挑选
- 商品原始数据
- 精选商品
根据准备情况进行数据分层
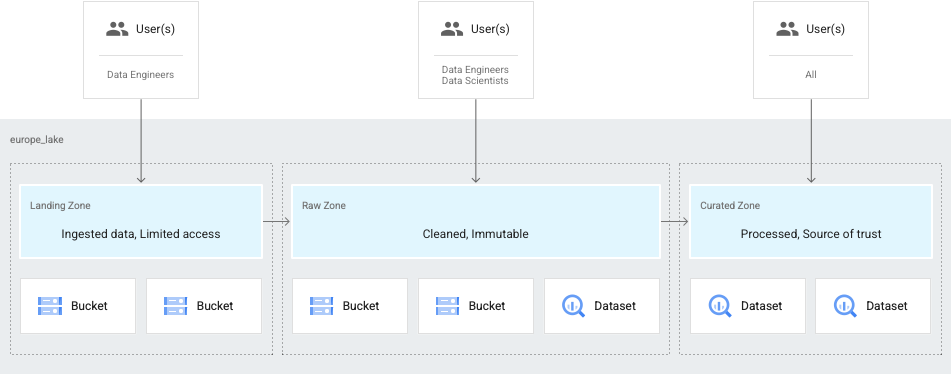
另一个常见用例是,只有数据工程师可以访问您的数据,之后数据经过优化后才会提供给数据科学家和分析师。在这种情况下,您可以构建一个数据湖,其中包含:
- 工程师可以访问的数据的着陆区。
- 数据科学家和分析师可访问的原始数据区域。
后续步骤
- 开始使用 Dataplex
- 构建数据网格
- 创建数据湖
- 探索 Dataplex 中的目录功能