Dataplex는 분산 데이터를 통합하고 해당 데이터의 관리 및 거버넌스를 자동화하는 데이터 패브릭입니다.
Dataplex는 다음과 같은 기능을 제공합니다.
- 데이터 이동 없이 여러 Google Cloud 프로젝트에 저장된 데이터를 망라하는 도메인별 데이터 메시 구축
- 단일 권한 모음으로 데이터를 일관되게 관리 및 모니터링
- 카탈로그 기능을 사용하여 다양한 사일로의 메타데이터를 탐색 및 선별. 자세한 내용은 Dataplex Catalog 개요를 참조하세요.
- BigQuery 및 Spark SQL, Presto, HiveQL과 같은 오픈소스 도구를 사용하여 메타데이터를 안전하게 쿼리
- 서버리스 Spark 작업을 포함해 데이터 품질 및 데이터 수명 주기 관리 작업 실행
- (지원 중단됨) 노트북 및 Spark SQL 쿼리에 액세스할 수 있는 완전 관리형 서버리스 Spark 환경을 사용하여 데이터를 탐색합니다.
Dataplex를 사용해야 하는 이유
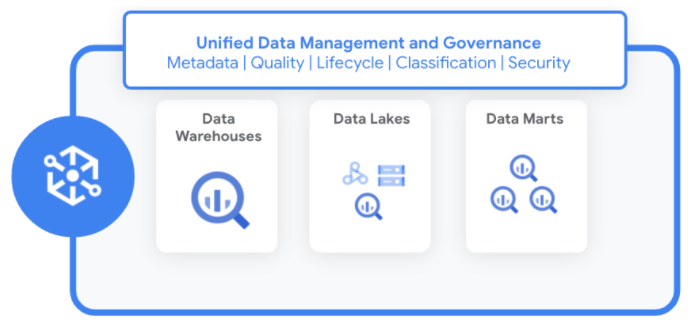
기업의 데이터는 여러 데이터 레이크, 데이터 웨어하우스, 데이터 마트에 분산되어 있습니다. Dataplex를 사용하면 다음을 수행할 수 있습니다.
- 데이터 검색
- 데이터 선별
- 데이터 이동 없이 데이터 통합
- 비즈니스 요구사항에 따라 데이터 정리
- 데이터를 중앙에서 관리, 모니터링, 거버넌스
Dataplex를 사용하면 이와 같이 분산된 데이터를 망라하여 메타데이터, 보안 정책, 거버넌스, 분류, 데이터 수명 주기 관리를 표준화하고 통합할 수 있습니다.
Dataplex 작동 방식
Dataplex는 데이터 이동이나 복제가 불필요한 방식으로 데이터를 관리합니다. 새 데이터 소스를 식별하면서 Dataplex는 무결성을 개선하기 위해 기본 제공 데이터 품질 검사를 사용하여 구조화된 데이터와 구조화되지 않은 데이터 모두에 대해 메타데이터를 가져옵니다.
Dataplex는 모든 메타데이터를 통합 Metastore에 자동으로 등록합니다. 다음을 비롯한 다양한 서비스와 도구를 사용하여 데이터와 메타데이터에 액세스할 수 있습니다.
- BigQuery, Dataproc Metastore, Data Catalog와 같은 Google Cloud 서비스
- Apache Spark, Presto와 같은 오픈소스 도구
용어
Dataplex는 다음과 같은 구조를 사용하여 기본 데이터 스토리지 시스템을 추상화합니다.
레이크: 데이터 도메인 또는 사업부를 나타내는 논리적 구조입니다. 예를 들어 그룹의 사용 현황에 따라 데이터를 정리하려면 각 부서 (예: 소매, 영업, 재무)에 대한 레이크를 설정하면 됩니다.
영역: 레이크 내의 하위 도메인으로, 다음과 같이 데이터를 분류하는 데 유용합니다.
- 단계: 랜딩, 원시, 선별된 데이터 분석, 선별된 데이터 과학 등
- 사용: 데이터 계약 등
- 제한사항: 보안 제어 및 사용자 액세스 수준 등
영역에는 두 가지 유형이 있습니다.
원시 영역: 원시 형식이며 엄격한 유형 확인이 적용되지 않는 데이터를 포함합니다.
선별된 영역: 정리되고 형식이 지정되어 분석 준비가 완료된 데이터를 포함합니다. 데이터는 열 형식이고 하이브 파티션이 적용되며 Parquet, Avro, Orc 파일 또는 BigQuery 테이블에 저장됩니다. 데이터는 유형 확인을 거칩니다. 예를 들어 CSV 파일은 SQL 액세스 성능이 떨어지므로 사용이 금지됩니다.
애셋: Cloud Storage 또는 BigQuery에 저장된 데이터에 매핑됩니다. 별도의 Google Cloud 프로젝트에 저장된 데이터를 단일 영역에 애셋으로 매핑할 수 있습니다.
항목: 구조화 및 반구조화된 데이터(예: 테이블)와 구조화되지 않은 데이터 (예: 파일 세트)의 메타데이터를 나타냅니다.
일반 사용 사례
이 섹션에서는 Dataplex 사용의 일반적인 사용 사례를 간략히 설명합니다.
도메인 중심 데이터 메시
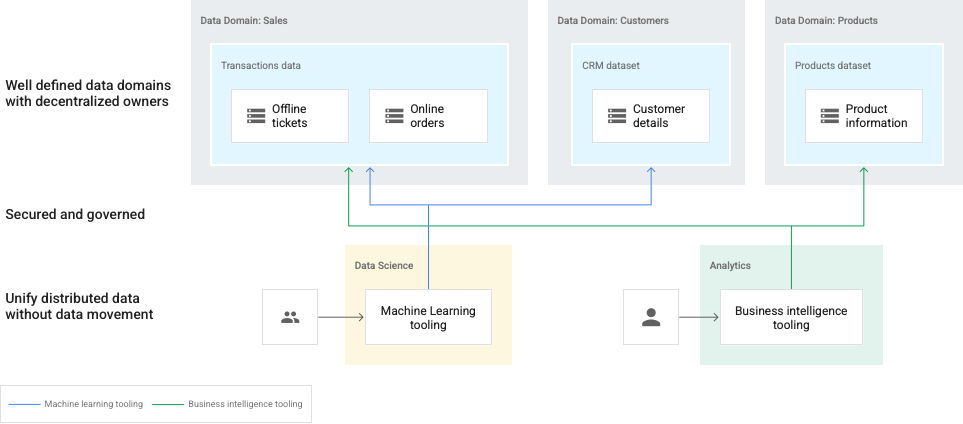
이 유형의 데이터 메시를 사용하면 데이터가 기업 내 여러 도메인(예: Sales, Customers, Products)으로 정리됩니다. 데이터 소유권을 분산할 수 있습니다. 여러 도메인의 데이터를 구독할 수 있습니다. 예를 들어 데이터 과학자와 데이터 분석가는 여러 도메인의 데이터를 가져와서 머신러닝, 비즈니스 인텔리전스와 같은 비즈니스 목표를 달성할 수 있습니다.
다음 다이어그램에서 도메인은 Dataplex 레이크로 표현되며 개별 데이터 생산자가 소유합니다. 데이터 생산자는 자신의 도메인에서 생성, 선별, 액세스 제어를 소유합니다. 데이터 소비자는 분석을 위해 레이크(도메인) 또는 영역(하위 도메인)에 대한 액세스를 요청할 수 있습니다.
이 경우 데이터 관리자가 항상 전체 데이터 환경을 종합적으로 파악하고 있어야 합니다.
이 다이어그램에는 다음 요소가 포함됩니다.
- Dataplex: 여러 데이터 도메인으로 구성된 메시
- 도메인:
Sales,Customers,Product데이터용 레이크 - 도메인 내 영역: 개별 팀에서 사용하거나 관리형 데이터 계약을 제공합니다.
- 애셋: Cloud Storage 버킷 또는 BigQuery 데이터 세트에 저장된 데이터이며 Dataplex 메시가 아닌 별도의 Google Cloud 프로젝트에 있을 수 있습니다.
영역에 속한 데이터를 원시 레이어와 선별된 레이어로 나누면 이 시나리오를 확장할 수 있습니다. 이를 위해 도메인, 원시 데이터, 선별된 데이터를 각각 조합하여 영역을 만들 수 있습니다.
- 영업 원시
- 영업 선별
- 고객 원시
- 고객 선별
- 제품 원시
- 제품 선별
준비 상태에 따른 데이터 계층 분류
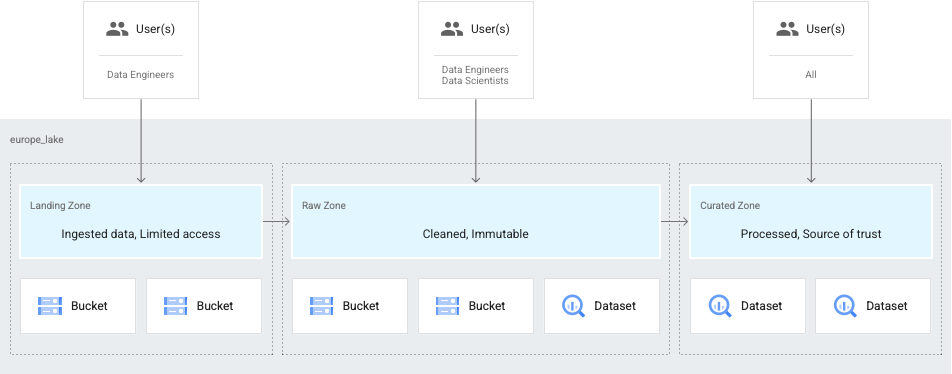
또 다른 일반적인 사용 사례는 데이터 엔지니어만 데이터에 액세스할 수 있고 이후에 데이터를 정제하여 데이터 과학자와 분석가에게 제공하는 경우입니다. 이 경우 다음과 같이 레이크를 설정할 수 있습니다.
- 엔지니어가 액세스할 수 있는 데이터의 도착 영역
- 데이터 과학자와 분석가에게 제공되는 원시 데이터 영역
다음 단계
- Dataplex 시작하기
- 데이터 메시 빌드
- 레이크 만들기
- Dataplex의 카탈로그 기능 살펴보기