Les tâches liées à la qualité des données Dataplex Universal Catalog vous permettent de définir et d'exécuter des contrôles de qualité des données sur les tables BigQuery et Cloud Storage. Les tâches liées à la qualité des données Dataplex Universal Catalog vous permettent également d'appliquer des contrôles réguliers des données dans les environnements BigQuery.
Quand créer des tâches de qualité des données Dataplex Universal Catalog ?
Les tâches de qualité des données Dataplex Universal Catalog peuvent vous aider dans les scénarios suivants :
- Validez les données dans le cadre d'un pipeline de production de données.
- Surveiller régulièrement la qualité des ensembles de données par rapport à vos attentes
- Créer des rapports sur la qualité des données pour les exigences réglementaires
Avantages
- Spécifications personnalisables : Vous pouvez utiliser la syntaxe YAML très flexible pour déclarer vos stratégies de qualité des données.
- Mise en œuvre sans serveur. Dataplex Universal Catalog ne nécessite aucune configuration d'infrastructure.
- Aucune copie et pushdown automatique. Les vérifications YAML sont converties en SQL et envoyées à BigQuery. Il n'existe aucune copie de données.
- Vérifications de la qualité des données programmables Vous pouvez planifier des contrôles de qualité des données via le planificateur sans serveur dans Dataplex Universal Catalog, ou utiliser l'API Dataplex via des planificateurs externes tels que Cloud Composer pour l'intégration du pipeline.
- Interface gérée Dataplex Universal Catalog utilise un moteur de qualité des données Open Source, CloudDQ, pour exécuter des contrôles de qualité des données. Cependant, Dataplex Universal Catalog offre une expérience gérée de manière fluide pour effectuer vos contrôles de qualité des données.
Fonctionnement des tâches liées à la qualité des données
Le schéma suivant illustre le fonctionnement des tâches liées à la qualité des données Dataplex Universal Catalog :
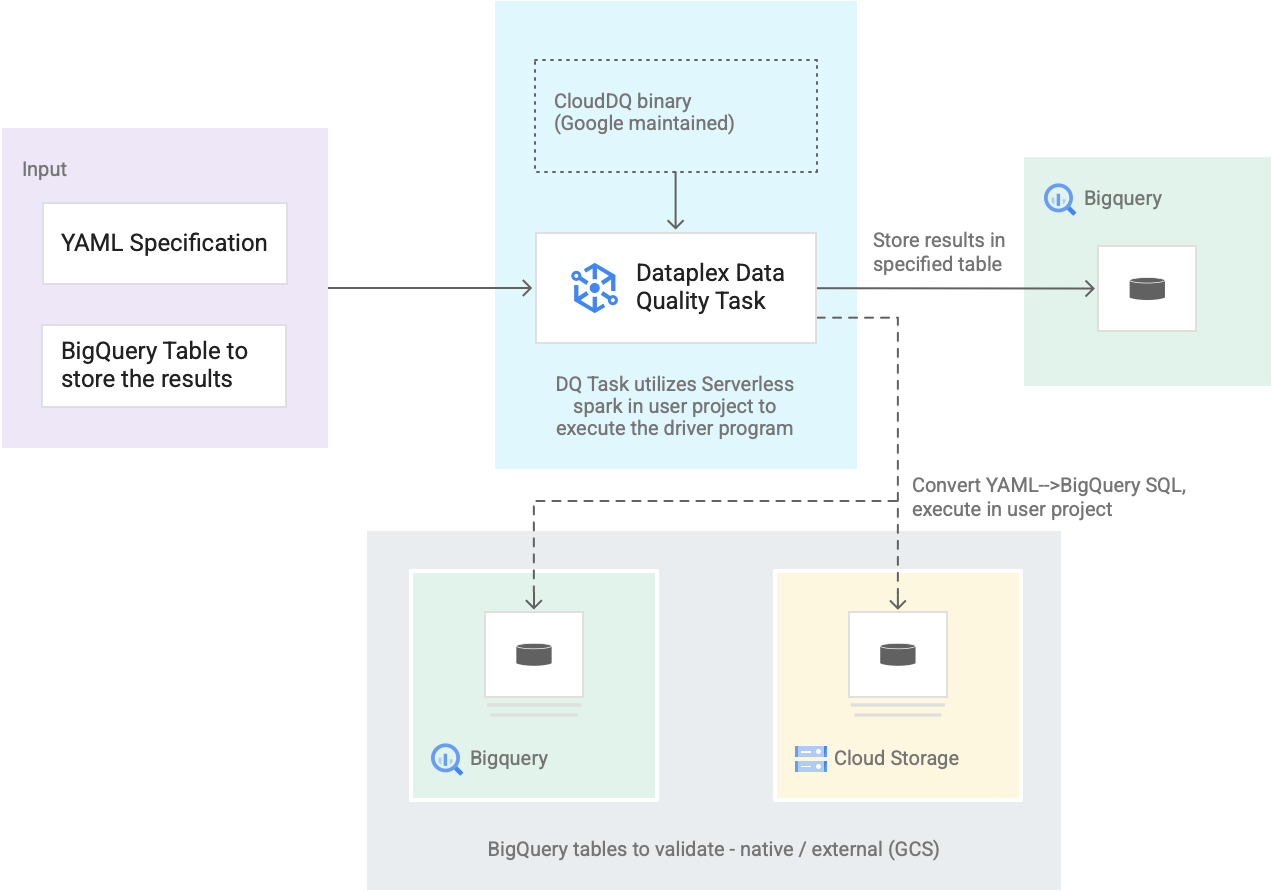
- Entrée des utilisateurs
- Spécification YAML : ensemble d'un ou de plusieurs fichiers YAML définissant des règles de qualité des données en fonction de la syntaxe de spécification. Vous stockez les fichiers YAML dans un bucket Cloud Storage de votre projet. Les utilisateurs peuvent exécuter plusieurs règles simultanément. Ces règles peuvent être appliquées à différentes tables BigQuery, y compris à des tables de différents ensembles de données ou projets Google Cloud. La spécification accepte des exécutions incrémentielles uniquement pour valider les nouvelles données. Pour créer une spécification YAML, consultez la section Créer un fichier de spécification.
- Table des résultats BigQuery : table spécifiée par l'utilisateur dans laquelle les résultats de la validation de la qualité des données sont stockés. Le projet Google Cloud dans lequel réside cette table peut être différent de celui dans lequel la tâche de qualité des données Dataplex Universal Catalog est utilisée.
- Tables à valider
- Dans la spécification YAML, vous devez spécifier les tables que vous souhaitez valider pour quelles règles, également appelée liaison de règle. Il peut s'agir de tables natives BigQuery ou de tables externes BigQuery dans Cloud Storage. La spécification YAML vous permet de spécifier des tables à l'intérieur ou à l'extérieur d'une zone Dataplex Universal Catalog.
- Les tables BigQuery et Cloud Storage validées en une seule exécution peuvent appartenir à des projets différents.
- Tâche de qualité des données Dataplex Universal Catalog : une tâche de qualité des données Dataplex Universal Catalog est configurée avec un binaire CloudDQ PySpark prédéfini et utilise la spécification YAML et la table de résultats BigQuery comme entrée. Comme pour d'autres tâches Dataplex Universal Catalog, la tâche Dataplex Universal Catalog liée à la qualité des données s'exécute dans un environnement Spark sans serveur, convertit la spécification YAML en requêtes BigQuery, puis exécute ces requêtes sur les tables définies dans le fichier de spécification.
Tarifs
Lorsque vous exécutez des tâches de qualité des données Dataplex Universal Catalog, l'utilisation de BigQuery et de Dataproc sans serveur (batches) vous est facturée.
La tâche de qualité des données Dataplex Universal Catalog convertit le fichier de spécification en requêtes BigQuery et les exécute dans le projet utilisateur. Consultez la page sur les tarifs de BigQuery.
Dataplex Universal Catalog utilise Spark pour exécuter le programme de pilote Open Source CloudDQ prédéfini par Google afin de convertir les spécifications de l'utilisateur en requêtes BigQuery. Consultez la page Tarifs de Dataproc sans serveur.
L'utilisation de Dataplex Universal Catalog pour organiser les données et l'utilisation du planificateur sans serveur dans Dataplex Universal Catalog pour planifier les contrôles de qualité des données sont sans frais. Consultez les tarifs de Dataplex Universal Catalog.