Las tareas de calidad de los datos de Dataplex te permiten definir y ejecutar verificaciones de calidad de los datos en tablas de BigQuery y Cloud Storage. Las tareas de calidad de los datos de Dataplex también te permiten aplicar controles de datos regulares en entornos de BigQuery.
Cuándo crear tareas de calidad de los datos de Dataplex
Las tareas de calidad de los datos de Dataplex pueden ayudarte con lo siguiente:
- Validar datos como parte de una canalización de producción de datos.
- Supervisar de forma rutinaria la calidad de los conjuntos de datos en función de tus expectativas.
- Crear informes sobre la calidad de los datos para satisfacer los requisitos regulatorios.
Ventajas
- Especificaciones personalizables. Puedes usar la sintaxis YAML altamente flexible para declarar tus reglas de calidad de los datos.
- Implementación sin servidores. Dataplex no necesita ninguna configuración de infraestructura.
- Copia cero y pushdown automático. Las verificaciones de YAML se convierten en SQL y se envían a BigQuery, lo que no genera copias de datos.
- Verificaciones de calidad de los datos programables. Puedes programar verificaciones de calidad de los datos mediante el programador sin servidores en Dataplex o usar la API de Dataplex a través de programadores externos como Cloud Composer para la integración de canalizaciones.
- Experiencia administrada. Dataplex usa un motor de calidad de los datos de código abierto, CloudDQ, para ejecutar verificaciones de calidad de los datos. Sin embargo, Dataplex proporciona una experiencia administrada sin interrupciones para realizar las verificaciones de calidad de los datos.
Cómo funciona
En el siguiente diagrama, se muestra cómo funcionan las tareas de calidad de los datos de Dataplex:
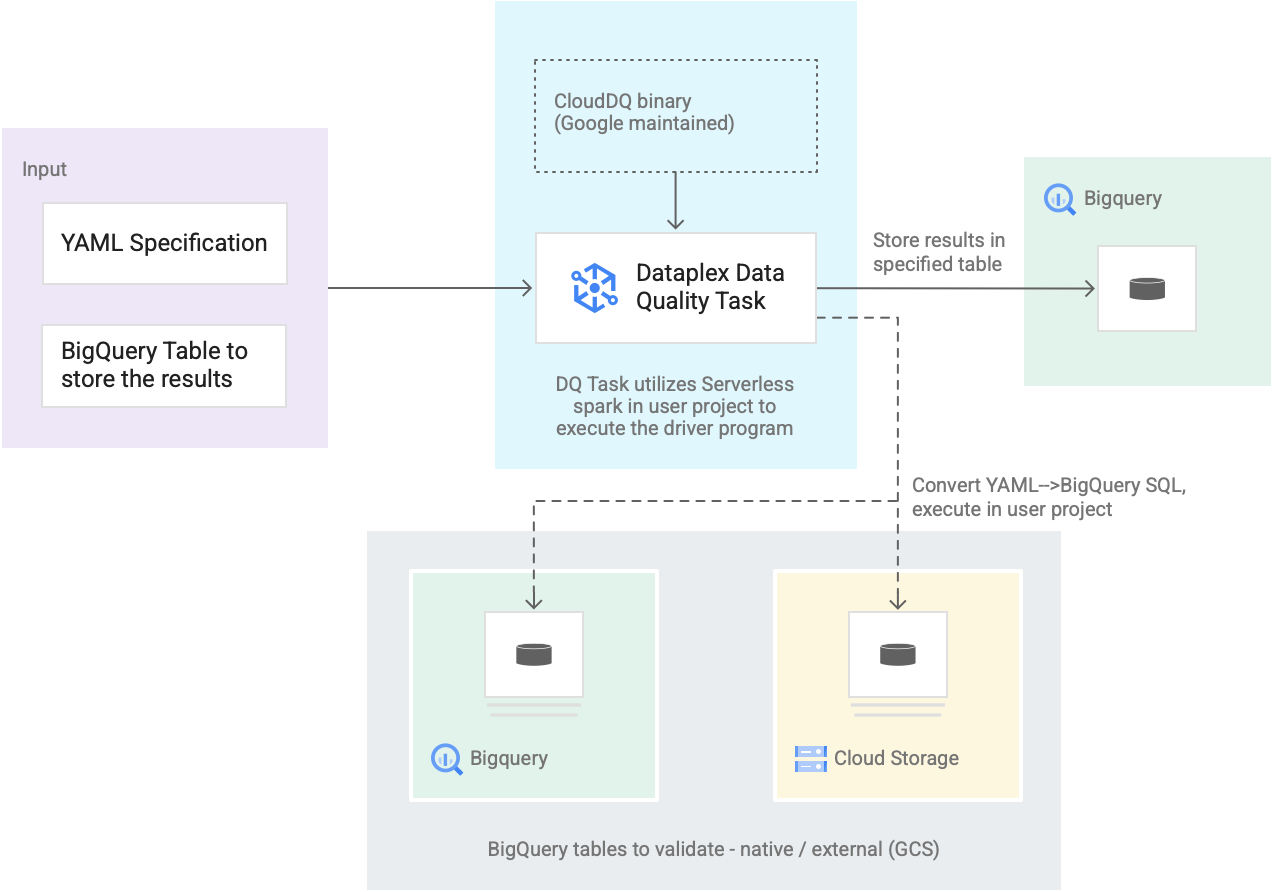
- Entrada de los usuarios
- Especificación de YAML: Un conjunto de uno o más archivos YAML que definen reglas de calidad de los datos según la sintaxis de especificación. Almacenas los archivos YAML en un bucket de Cloud Storage en tu proyecto. Los usuarios pueden ejecutar varias reglas de forma simultánea, y estas se pueden aplicar a diferentes tablas de BigQuery, incluidas las tablas en diferentes conjuntos de datos o proyectos de Google Cloud. La especificación admite ejecuciones incrementales solo para validar datos nuevos. Para crear una especificación YAML, consulta Crea un archivo de especificación.
- Tabla de resultados de BigQuery: Es una tabla especificada por el usuario en la que se almacenan los resultados de la validación de calidad de los datos. El proyecto de Google Cloud en el que reside esta tabla puede ser un proyecto diferente del que se usa en la tarea de calidad de los datos de Dataplex.
- Tablas para validar
- Dentro de la especificación YAML, debes especificar qué tablas deseas validar para qué reglas, también conocidas como una vinculación de reglas. Las tablas pueden ser tablas nativas de BigQuery o tablas externas de BigQuery en Cloud Storage. La especificación YAML te permite especificar tablas dentro o fuera de una zona de Dataplex.
- Las tablas de BigQuery y Cloud Storage que se validan en una sola ejecución pueden pertenecer a diferentes proyectos.
- Tarea de calidad de los datos de Dataplex: Una tarea de calidad de los datos de Dataplex se configura con un objeto binario PySpark precompilado y mantenido de CloudDQ, y toma la especificación YAML y la tabla de resultados de BigQuery como entrada. Al igual que otras tareas de Dataplex, la tarea de calidad de los datos de Dataplex se ejecuta en un entorno de Spark sin servidores, convierte la especificación YAML en consultas de BigQuery y, luego, ejecuta esas consultas en las tablas que se definen en el archivo de especificación.
Costos
Cuando ejecutas tareas de calidad de los datos de Dataplex, se te cobra por el uso de BigQuery y Dataproc sin servidores (lotes).
La tarea de calidad de los datos de Dataplex convierte el archivo de especificación en consultas de BigQuery y los ejecuta en el proyecto del usuario. Consulta Precios de BigQuery.
Dataplex usa Spark para ejecutar el programa de controlador CloudDQ de código abierto precompilado y mantenido por Google para convertir la especificación del usuario en consultas de BigQuery. Consulta Precios de Dataproc Serverless.
No se aplican cargos por usar Dataplex para organizar datos o por usar el programador sin servidores en Dataplex para programar verificaciones de calidad de los datos. Consulta Precios de Dataplex.