Com a linhagem de dados, é possível acompanhar como os dados se movimentam nos sistemas: origem, destino e quais transformações são aplicadas a eles.
Por que você precisa de linhagem de dados?
Trabalhar com grandes conjuntos de dados geralmente envolve transformar dados em entidades adaptadas às necessidades de um projeto específico: arquivos de texto, tabelas, relatórios, painéis, modelos.
Por exemplo, imagine que você tem uma loja on-line em que registra todas as compras em uma única tabela SQL. Para facilitar o trabalho dos analistas com os dados, você começa a executar jobs que extraem informações dessa única tabela e produzem tabelas menores por região, marca ou preço de venda. Em seguida, os analistas fazem o mesmo: realizam mais transformações, mesclando essas tabelas menores com outras fontes de dados para produzir ainda mais tabelas.
Isso pode se tornar um grande desafio para as partes interessadas:
- Os consumidores de dados não podem usar uma ferramenta de autoatendimento para entender se os dados vêm de uma fonte confiável.
- Os engenheiros de dados não conseguem identificar a causa raiz dos problemas devido à falta de uma maneira confiável de rastrear todas as transformações de dados.
- Os engenheiros e analistas de dados não conseguem avaliar totalmente o possível impacto antes de modificar ou excluir tabelas.
- Os administradores de dados não conseguem entender como os dados sensíveis são usados em toda a organização e verificar a adesão aos requisitos regulamentares.
A linhagem de dados é uma solução que oferece uma maneira prática de fazer o seguinte:
- Entenda como os dados são extraídos e transformados com a ajuda de gráficos de linhagem.
- Rastreie erros relacionados a entradas e operações de dados até as causas raízes.
- Melhore o gerenciamento de mudanças com a análise de impacto: evite tempo de inatividade ou erros inesperados, entenda as entradas dependentes e colabore com as partes interessadas relevantes.
Modelo de informações de linhagem de dados
Na forma básica, a linhagem é um registro de dados transformados de origens para destinos. A API Data Lineage coleta essas informações e as organiza em um modelo de dados hierárquico usando os conceitos de processos, execuções e eventos.
Processo
Um processo é a definição de uma operação de transformação de dados compatível com
um sistema específico. No contexto da linhagem do BigQuery, um process é um dos tipos de job compatíveis.
Executar
Uma execução é a realização de um processo. Os processos podem ter várias execuções.
As execuções contêm detalhes como horários de início e término, estado ou atributos adicionais.
Para mais informações, consulte a
referência do recurso run.
Evento
Um evento representa um ponto no tempo em que uma operação de transformação de dados ocorreu e resultou na movimentação de dados entre uma origem e uma entidade de destino.
Os eventos contêm uma lista de links que definem qual entrada foi a origem e qual foi o destino em um evento específico. Embora os eventos sejam usados para calcular gráficos de linhagem, eles não são expostos diretamente no console do Google Cloud . É possível criar, ler e excluir (mas não atualizar) usando a API Data Lineage.
Exemplo
Considere o exemplo a seguir, em que os dados são copiados entre tabelas do BigQuery:
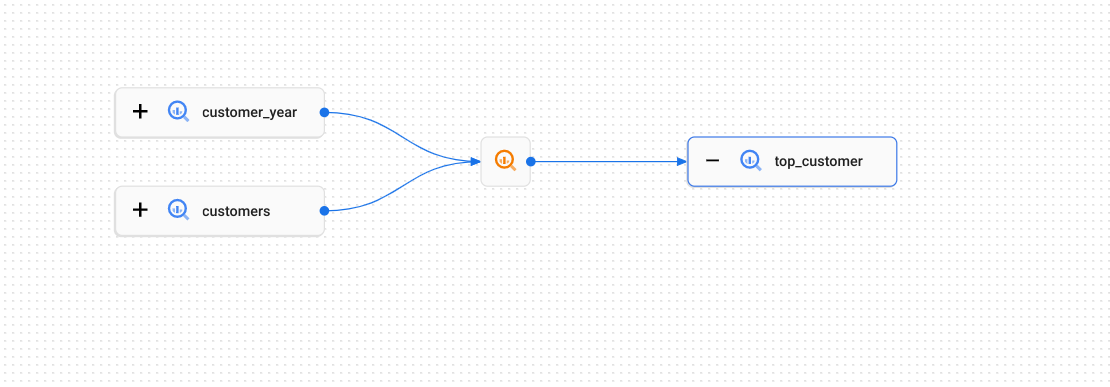
A movimentação de dados entre as tabelas é descrita pelo processo de linhagem (representado no gráfico pelo ícone ![]() ): pode ser uma consulta SQL
): pode ser uma consulta SQL CREATE TABLE AS SELECT ou uma instrução INSERT.
Cada execução dessa instrução SQL constitui uma execução individual.
As execuções contêm eventos que registram quais tabelas foram usadas como fontes e quais como destinos. Neste exemplo, as tabelas customer_year e customers são a origem da tabela top_customer de destino.
Gráfico de linhagem
Os gráficos de linhagem representam informações coletadas pela API Data Lineage para uma determinada entrada do catálogo universal do Dataplex. Um gráfico de linhagem mostra a linhagem upstream ou downstream de uma única entrada raiz. Raiz se refere à entrada de linhagem que você está visualizando.
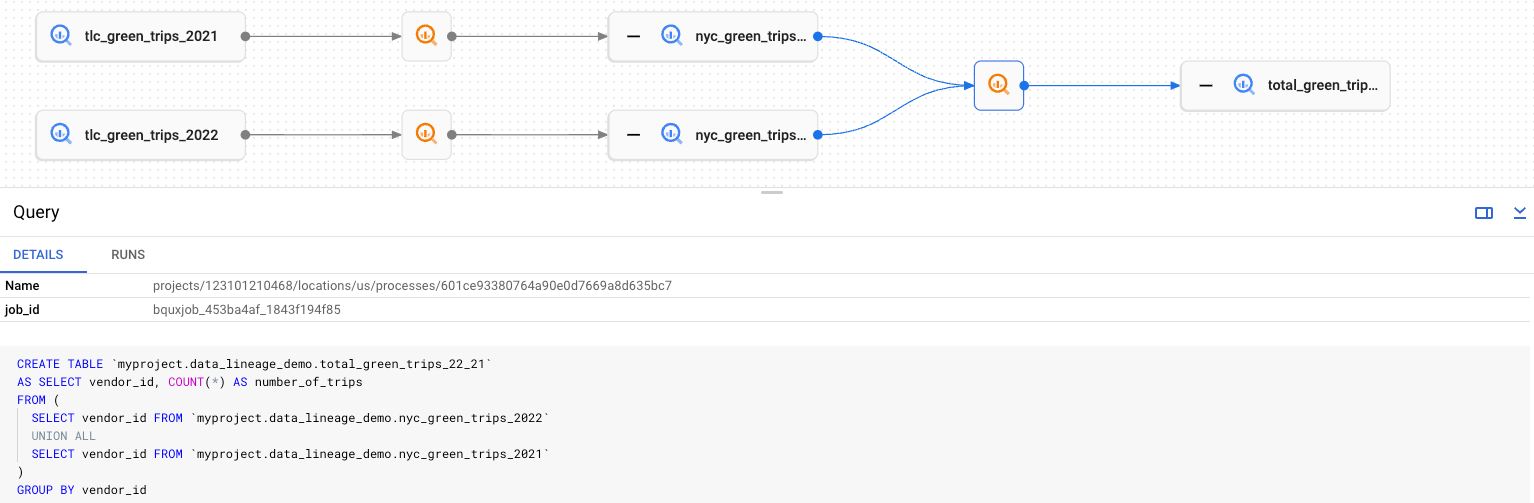
O Dataplex Universal Catalog funciona com a API Data Lineage para identificar entradas cujo nome totalmente qualificado corresponde a entidades reconhecidas pela linhagem de dados. Para entradas correspondentes do Dataplex Universal Catalog, acesse a guia Linhagem na página de detalhes e confira o gráfico.
Os gráficos de linhagem mostram dois tipos de elementos:
Botões retangulares largos que representam entidades envolvidas na construção de informações de linhagem como origens ou destinos de um evento de linhagem.
Botões quadrados menores que representam processos responsáveis por criar ou atualizar as entidades de origem ou destino. Os botões de processo usam ícones específicos do sistema de origem que os informou à API Data Lineage. Por exemplo, os jobs do BigQuery usam o ícone
 .
.
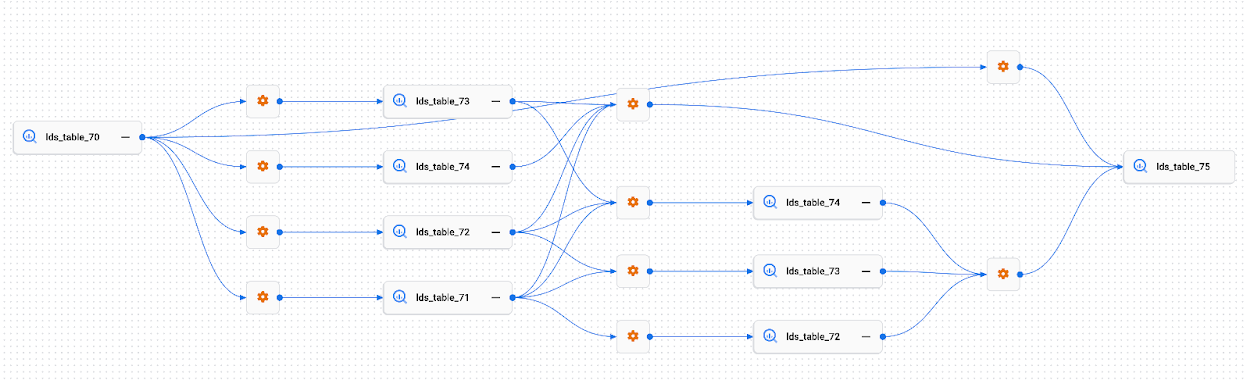
Visualização do caminho de linhagem
As visualizações de caminho de linhagem ajudam a entender os links de linhagem entre dois recursos selecionados. Isso contrasta com o gráfico de linhagem, que mostra a linhagem upstream ou downstream de uma única entrada raiz, potencialmente para várias fontes ou destinos.
Você escolhe o recurso raiz e um recurso de destino, e o consoleGoogle Cloud mostra os links de linhagem entre os dois recursos. Outros recursos e processos que não estão em um caminho entre os dois recursos são ocultados da visualização de caminho.
Visualização em lista da linhagem
A visualização em lista de linhagem mostra informações detalhadas sobre as entidades em uma única tabela.
Em comparação com o gráfico de linhagem, que é melhor para visualizar gráficos relativamente pequenos, a visualização em lista permite conferir informações de linhagem para entidades com muitas conexões.
A imagem a seguir mostra um exemplo da visualização em lista de linhagem no console doGoogle Cloud . A lista a seguir descreve a imagem com mais detalhes.
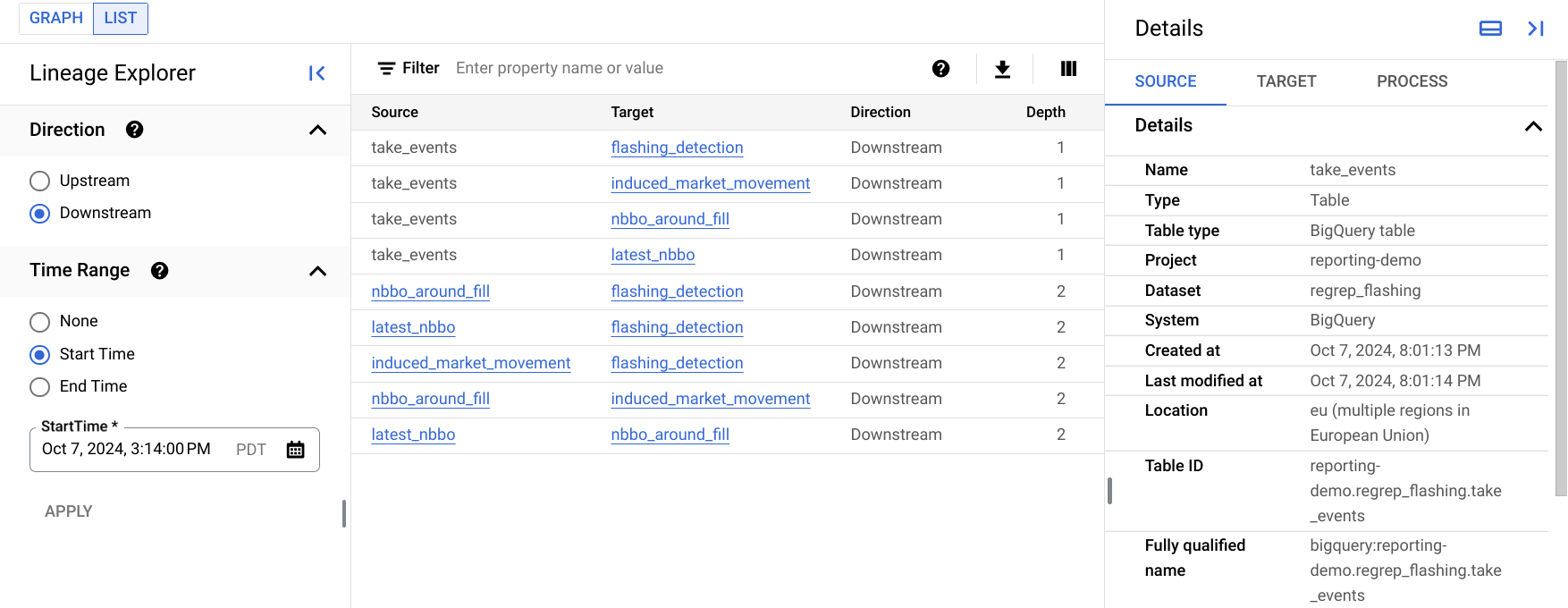
Cada linha na tabela representa um único link de linhagem entre duas entradas. No gráfico, esses nomes são representados como os links de linhagem entre duas entradas, incluindo os nós de processo intermediários. Por exemplo,
SourceeTargetsão nós de recursos, com possivelmente vários nós de processo entre eles.A opção Direção especifica a parte do fluxo de dados a ser mostrada na lista, em relação ao recurso raiz:
Upstream: mostra informações de linhagem para entradas que são fontes de dados da entrada selecionada. No gráfico de linhagem, essas entradas aparecem à esquerda da entrada selecionada.
Downstream: mostra informações de linhagem para entradas que usam ou são derivadas da entrada selecionada. No gráfico de linhagem, essas entradas são as que aparecem à direita da entrada selecionada.
Com a opção Período, é possível filtrar informações de linhagem com base no momento em que ela ocorreu:
Horário de início: mostra a linhagem que ocorreu após o horário de início.
Horário de término: mostra a linhagem que ocorreu antes do horário de término.
Profundidade se refere à distância de um recurso de origem ou derivado do recurso raiz. A visualização em lista mostra até 1.000 links de linhagem, com profundidade máxima de 10 links do recurso raiz. Se houver alguma linhagem fora desse intervalo, você vai receber uma notificação. Para ver a linhagem fora desse intervalo, selecione o nome de outra entidade na visualização em lista.
O painel Detalhes mostra informações sobre a origem e o destino do link, além de todos os processos que o criaram.
É possível personalizar as colunas exibidas na tabela e filtrar os resultados. Também é possível exportar os resultados para um arquivo CSV.
Rastreamento automatizado da linhagem de dados
Quando você ativa a API Data Lineage,os sistemas Google Cloud que oferecem suporte à linhagem de dados começam a informar a movimentação dos dados. Cada sistema integrado pode enviar informações de linhagem para um intervalo diferente de fontes de dados. Para mais informações sobre cada produto compatível, consulte as seções a seguir.
BigQuery
A ativação da linhagem de dados no projeto do BigQuery faz com que o Dataplex Universal Catalog registre automaticamente as informações de linhagem para:
Novas tabelas como resultado dos seguintes jobs do BigQuery:
- Jobs de cópia
- Jobs de carregamento que usam o URI do Cloud Storage para carregar dados em qualquer formato permitido do Cloud Storage
- Jobs de consulta que usam a seguinte linguagem de definição de dados (DDL) no GoogleSQL:
Tabelas criadas como resultado do uso das seguintes instruções da linguagem de manipulação de dados (DML) no GoogleSQL:
- SELECT em relação a qualquer um dos tipos de tabela listados:
- INSERT SELECT
- MERGE
- ATUALIZAR
- EXCLUIR
Os jobs de cópia, consulta e carregamento do BigQuery são representados como processos. Para ver os detalhes do processo, clique em ![]() no gráfico de linhagem.
Cada processo contém o job_id do BigQuery na lista de atributos do job mais recente do BigQuery.
no gráfico de linhagem.
Cada processo contém o job_id do BigQuery na lista de atributos do job mais recente do BigQuery.
Outros serviços
A linhagem de dados é compatível com a integração aos seguintes serviços do Google Cloud :
Linhagem de dados para fontes de dados personalizadas
É possível usar a API Data Lineage para registrar informações de linhagem manualmente em qualquer fonte de dados que não seja compatível com os sistemas integrados.
O Dataplex Universal Catalog pode criar gráficos de linhagem para linhagem registrada manualmente se você usar um
fullyQualifiedName que corresponda aos nomes totalmente
qualificados das entradas atuais do Dataplex Universal Catalog. Se você quiser registrar a linhagem de uma fonte de dados personalizada, primeiro crie uma entrada personalizada.
Cada processo para fonte de dados personalizada pode conter a chave sql na lista de atributos. O valor dessa chave será usado para renderizar o destaque do código no painel de detalhes do gráfico de linhagem de dados. A instrução SQL será mostrada como foi
fornecida. O usuário é responsável por filtrar informações sensíveis. O nome da chave sql diferencia maiúsculas de minúsculas.
OpenLineage
Se você já usa o OpenLineage para coletar informações de linhagem de outras fontes de dados, é possível importar eventos do OpenLineage para o Dataplex Universal Catalog e mostrar esses eventos no console Google Cloud . Para mais detalhes, consulte Integrar com o OpenLineage.
Limitações
- Todas as informações de linhagem são mantidas no sistema por apenas 30 dias.
- As informações de linhagem persistem depois que você remove a fonte de dados relacionada. Ou seja, se você remover uma tabela do BigQuery e a entrada dela no Dataplex Universal Catalog, ainda poderá ler a linhagem dessa tabela usando a API por até 30 dias.
Acessar a linhagem de dados
Para mais informações sobre como acessar a linhagem de dados, consulte Usar a linhagem de dados com sistemas Google Cloud e a API Data Lineage.
Preços
O Dataplex Universal Catalog usa a SKU de processamento premium para cobrar pela linhagem de dados. Para saber mais informações, consulte Preços.
Para separar as cobranças de linhagem de dados de outras cobranças na SKU de processamento premium do Dataplex Universal Catalog, no relatório de faturamento do Cloud, use o rótulo
goog-dataplex-workload-typecom o valorLINEAGE.Se você chamar a API Data Lineage
OriginsourceTypecom um valor diferente deCUSTOM, isso vai gerar custos adicionais.
A seguir
Siga um guia de início rápido para rastrear a linhagem de dados dos jobs de cópia e consulta de uma tabela do BigQuery.
Aprenda a usar a linhagem de dados com sistemas Google Cloud .
Para informações administrativas, consulte considerações sobre linhagem e registro de auditoria de linhagem de dados.