このチュートリアルでは、Dataflow SQL を使用して Pub/Sub のデータ ストリームを BigQuery テーブルのデータと結合する方法について説明します。
目標
このチュートリアルの内容は次のとおりです。
- Pub/Sub ストリーミング データと BigQuery テーブルデータを結合する Dataflow SQL クエリを作成します。
- Dataflow SQL UI から Dataflow ジョブをデプロイします。
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
- Dataflow
- Cloud Storage
- Pub/Sub
- Data Catalog
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. - gcloud CLI をインストールして初期化します。インストール オプションを、次の中から選択します。場合によっては、このチュートリアルで使用するプロジェクトに
projectプロパティを設定する必要があります。 - Google Cloud コンソールで Dataflow SQL ウェブ UI に移動します。最後にアクセスしたプロジェクトが開きます。別のプロジェクトに切り替えるには、Dataflow SQL ウェブ UI の先頭に表示されているプロジェクト名をクリックし、使用するプロジェクトを検索します。
Dataflow SQL ウェブ UI に移動 transactionsという名前の Pub/Sub トピック - Pub/Sub トピックのサブスクリプションを介して送信されるトランザクション データのストリーム。各トランザクションのデータには、購入した商品、販売価格、購入場所などの情報が含まれています。Pub/Sub トピックを作成したら、トピックにメッセージを公開するスクリプトを作成します。このチュートリアルの後半で、このスクリプトを実行します。us_state_salesregionsという名前の BigQuery テーブル - 州と販売地域をマッピングするテーブル。このテーブルを作成する前に、BigQuery データセットを作成する必要があります。- BigQuery ウェブ UI で、BigQuery データセットを作成します。BigQuery データセットは、テーブルを格納する最上位のコンテナです。BigQuery のテーブルはデータセットに属している必要があります。
- [エクスプローラ] パネルで、プロジェクトのアクションを開きます。メニューで、[データセットを作成] をクリックします。次のスクリーンショットでは、
dataflow-sqlがプロジェクト ID です。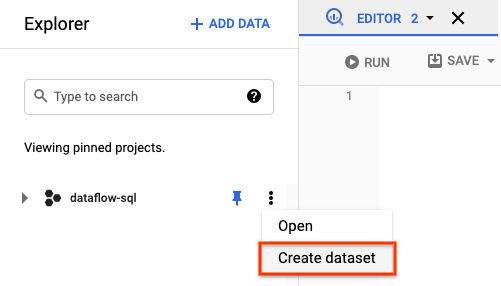
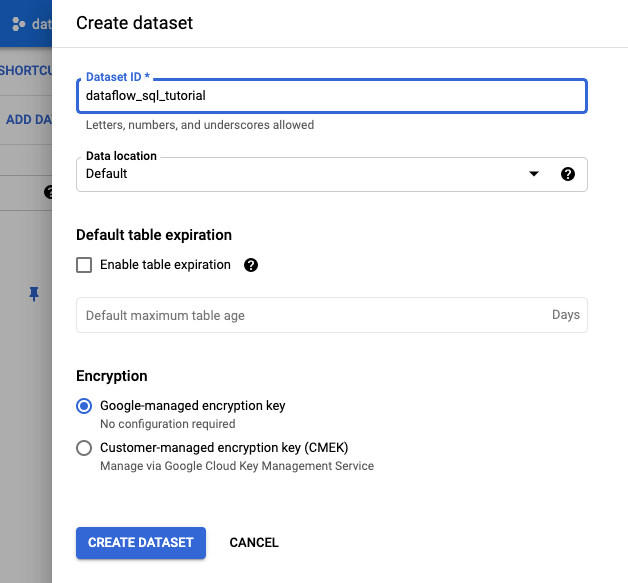
- 表示された [データセットを作成] パネルで、[データセット ID] に「
dataflow_sql_tutorial」と入力します。 - [データのロケーション] で、メニューからオプションを選択します。
- [データセットを作成] をクリックします。
- [エクスプローラ] パネルで、プロジェクトのアクションを開きます。メニューで、[データセットを作成] をクリックします。次のスクリーンショットでは、
- BigQuery テーブルを作成します。
- テキスト ファイルを作成し、名前を
us_state_salesregions.csvにします。 us_state_salesregions.csvに次のデータをコピーして貼り付けます。次のステップで、このデータを BigQuery テーブルに読み込みます。state_id,state_code,state_name,sales_region 1,MO,Missouri,Region_1 2,SC,South Carolina,Region_1 3,IN,Indiana,Region_1 6,DE,Delaware,Region_2 15,VT,Vermont,Region_2 16,DC,District of Columbia,Region_2 19,CT,Connecticut,Region_2 20,ME,Maine,Region_2 35,PA,Pennsylvania,Region_2 38,NJ,New Jersey,Region_2 47,MA,Massachusetts,Region_2 54,RI,Rhode Island,Region_2 55,NY,New York,Region_2 60,MD,Maryland,Region_2 66,NH,New Hampshire,Region_2 4,CA,California,Region_3 8,AK,Alaska,Region_3 37,WA,Washington,Region_3 61,OR,Oregon,Region_3 33,HI,Hawaii,Region_4 59,AS,American Samoa,Region_4 65,GU,Guam,Region_4 5,IA,Iowa,Region_5 32,NV,Nevada,Region_5 11,PR,Puerto Rico,Region_6 17,CO,Colorado,Region_6 18,MS,Mississippi,Region_6 41,AL,Alabama,Region_6 42,AR,Arkansas,Region_6 43,FL,Florida,Region_6 44,NM,New Mexico,Region_6 46,GA,Georgia,Region_6 48,KS,Kansas,Region_6 52,AZ,Arizona,Region_6 56,TN,Tennessee,Region_6 58,TX,Texas,Region_6 63,LA,Louisiana,Region_6 7,ID,Idaho,Region_7 12,IL,Illinois,Region_7 13,ND,North Dakota,Region_7 31,MN,Minnesota,Region_7 34,MT,Montana,Region_7 36,SD,South Dakota,Region_7 50,MI,Michigan,Region_7 51,UT,Utah,Region_7 64,WY,Wyoming,Region_7 9,NE,Nebraska,Region_8 10,VA,Virginia,Region_8 14,OK,Oklahoma,Region_8 39,NC,North Carolina,Region_8 40,WV,West Virginia,Region_8 45,KY,Kentucky,Region_8 53,WI,Wisconsin,Region_8 57,OH,Ohio,Region_8 49,VI,United States Virgin Islands,Region_9 62,MP,Commonwealth of the Northern Mariana Islands,Region_9
- BigQuery UI の [エクスプローラ] パネルでプロジェクトを開き、
dataflow_sql_tutorialデータセットを表示します。 dataflow_sql_tutorialデータセットのアクション メニューを開き、[開く] をクリックします。- [テーブルを作成] をクリックします。
![BigQuery データセット エクスプローラの [テーブルを作成] ボタン。](https://cloud.google.com/static/dataflow/images/sql-create-table.png?hl=ja)
- 表示された [テーブルを作成] パネルで、次の操作を行います。
- [テーブルの作成元] で [アップロード] を選択します。
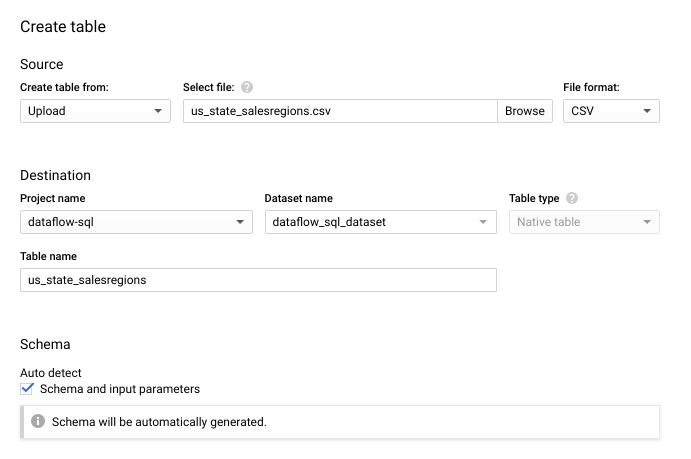
- [ファイルを選択] で [参照] をクリックし、作成した
us_state_salesregions.csvファイルを選択します。 - [テーブル] に「
us_state_salesregions」と入力します。 - [スキーマ] で、[自動検出] を選択します。
- [詳細オプション] をクリックして、[詳細オプション] セクションを開きます。
- [スキップするヘッダー行] に「
1」と入力し、[テーブルを作成] をクリックします。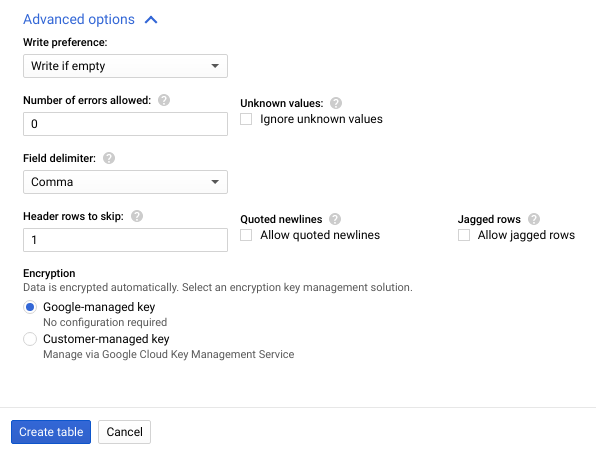
- [テーブルの作成元] で [アップロード] を選択します。
- [エクスプローラ] パネルで、
us_state_salesregionsをクリックします。[スキーマ] には、自動生成されたスキーマが表示されます。[プレビュー] には、テーブルのデータが表示されます。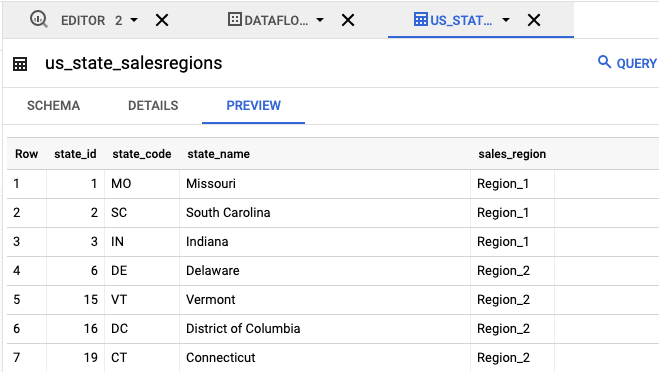
- テキスト ファイルを作成し、名前を
テキスト ファイルを作成し、名前を
transactions_schema.yamlにします。次のスキーマ テキストをコピーしてtransactions_schema.yamlに貼り付けます。- column: event_timestamp description: Pub/Sub event timestamp mode: REQUIRED type: TIMESTAMP - column: tr_time_str description: Transaction time string mode: NULLABLE type: STRING - column: first_name description: First name mode: NULLABLE type: STRING - column: last_name description: Last name mode: NULLABLE type: STRING - column: city description: City mode: NULLABLE type: STRING - column: state description: State mode: NULLABLE type: STRING - column: product description: Product mode: NULLABLE type: STRING - column: amount description: Amount of transaction mode: NULLABLE type: FLOATGoogle Cloud CLI を使用してスキーマを割り当てます。
a. 次のコマンドを使用して、gcloud CLI を更新します。gcloud CLI のバージョンは 242.0.0 以降にする必要があります。
gcloud components update
b. コマンドライン ウィンドウで次のコマンドを実行します。project-id はプロジェクト ID に置き換え、path-to-file は
transactions_schema.yamlファイルのパスに置き換えます。gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`project-id`.transactions' \ --schema-from-file=path-to-file/transactions_schema.yaml
コマンドのパラメータと許可されるスキーマ ファイルの形式については、gcloud data-catalog entries update のドキュメント ページをご覧ください。
c.
transactionsPub/Sub トピックにスキーマが正常に割り当てられたことを確認します。project-id は、実際のプロジェクト ID に置き換えます。gcloud data-catalog entries lookup 'pubsub.topic.`project-id`.transactions'
SQL ワークスペースに移動します。
[Dataflow SQL 編集者] パネルの検索バーで、
projectid=project-id transactionsを検索します。project-id は、実際のプロジェクト ID に置き換えます。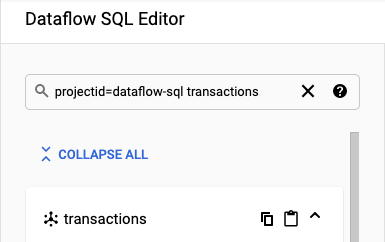
- Dataflow SQL UI の [Dataflow SQL 編集者] パネルで [トランザクション] をクリックするか、「
projectid=project-id system=cloud_pubsub」と入力して Pub/Sub トピックを検索し、トピックを選択します。 [スキーマ] の下に、Pub/Sub トピックに割り当てられたスキーマが表示されます。
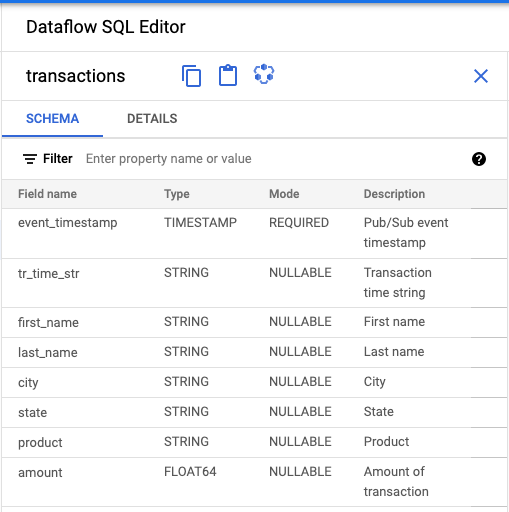
クエリエディタで、[ジョブを作成] をクリックします。
表示された [Dataflow ジョブの作成] パネルで、次の操作を行います。
- [Destination] で、[BigQuery] を選択します。
- データセット ID に [
dataflow_sql_tutorial] を選択します。 - テーブル名に「
sales」と入力します。
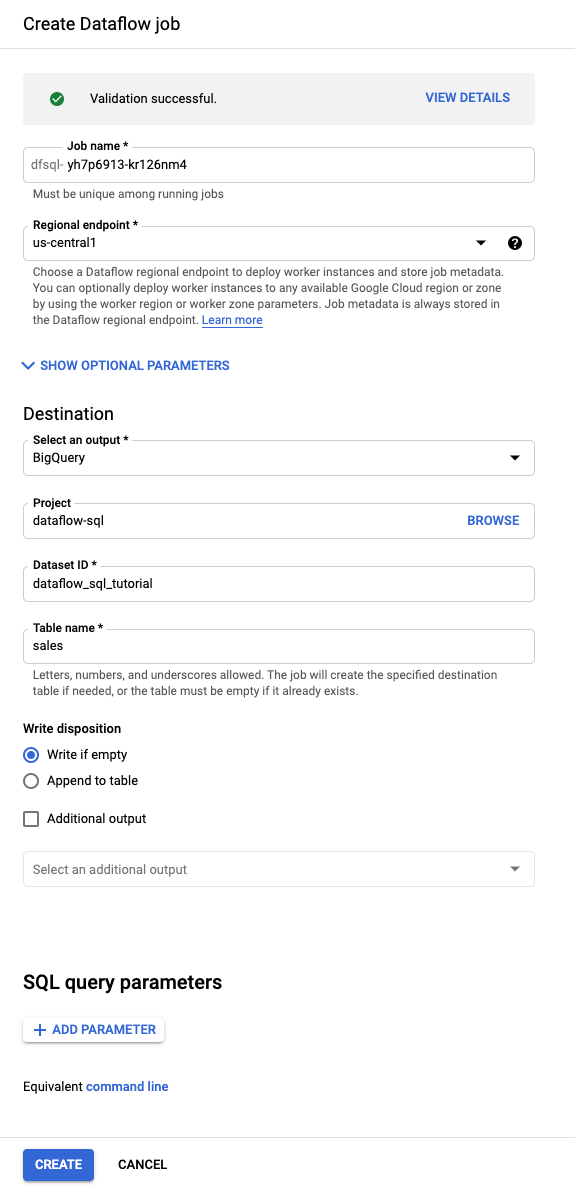
(省略可)Dataflow では、Dataflow SQL ジョブに最適な設定が自動的に選択されますが、オプション パラメータのメニューを開いて、次のパイプライン オプションを手動で指定することもできます。
- ワーカーの最大数
- ゾーン
- サービス アカウントのメール
- マシンタイプ
- 追加テスト
- ワーカー IP アドレスの構成
- ネットワーク
- サブネットワーク
[作成] をクリックします。Dataflow ジョブの実行が開始されるまでに数分かかります。
Dataflow の [ジョブ] ページで、編集するジョブをクリックします。
[ジョブの詳細] ページの [ジョブ情報] パネルにある [パイプライン オプション] で SQL クエリを見つけます。queryString の行を見つけます。
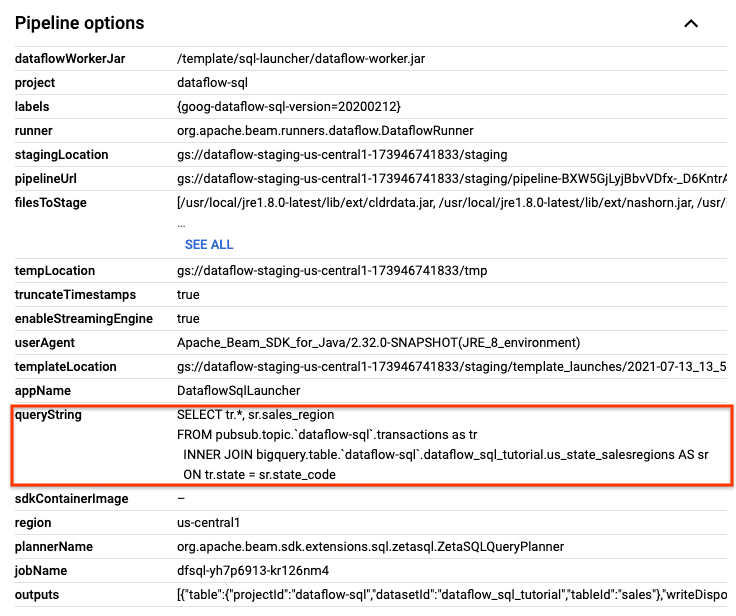
次の SQL クエリをコピーして SQL ワークスペースの [Dataflow SQL 編集者] に貼り付け、タンブリング ウィンドウを追加します。project-id は、実際のプロジェクト ID に置き換えます。
SELECT sr.sales_region, TUMBLE_START("INTERVAL 15 SECOND") AS period_start, SUM(tr.amount) as amount FROM pubsub.topic.`project-id`.transactions AS tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code GROUP BY sr.sales_region, TUMBLE(tr.event_timestamp, "INTERVAL 15 SECOND")
変更したクエリを使用して新しいジョブを作成するには、[ジョブを作成] をクリックします。
transactions_injector.py公開スクリプトが実行されている場合は、それを停止します。実行中の Dataflow ジョブを停止します。 Google Cloud コンソールで Dataflow ウェブ UI に移動します。
このチュートリアルで作成したジョブごとに、次の操作を行います。
ジョブの名前をクリックします。
[ジョブの詳細] ページで、[停止] をクリックします。[ジョブの停止] ダイアログが開き、ジョブの停止方法に関する選択肢が表示されます。
[キャンセル] を選択します。
[ジョブを停止] をクリックします。サービスはすべてのデータの取り込みと処理をできる限り早く停止します。[キャンセル] は処理を即時に停止するため、処理中のデータが失われる可能性があります。ジョブの停止には数分かかることがあります。
BigQuery データセットを削除します。 Google Cloud コンソールで BigQuery ウェブ UI に移動します。
[エクスプローラ] パネルの [リソース] セクションで、作成した dataflow_sql_tutorial データセットをクリックします。
詳細パネルで [削除] をクリックします。確認ダイアログが表示されます。
[データセットの削除] ダイアログ ボックスで「
delete」と入力して削除コマンドを確認し、[削除] をクリックします。
Pub/Sub トピックを削除します。 Google Cloud コンソールで Pub/Sub の [トピック] ページに移動します。
「
transactions」トピックを選択します。[削除] をクリックして、トピックを完全に削除します。確認ダイアログが表示されます。
[トピックの削除] ダイアログ ボックスで「
delete」を入力して削除コマンドを確認し、[削除] をクリックします。Pub/Sub サブスクリプション ページに移動します。
transactionsの残りのサブスクリプションを選択します。実行中のジョブがない場合、サブスクリプションが表示されない可能性があります。[削除] をクリックして、サブスクリプションを完全に削除します。確認ダイアログで [削除] をクリックします。
Cloud Storage で Dataflow ステージング バケットを削除します。 Google Cloud コンソールで Cloud Storage の [バケット] ページに移動します。
Dataflow ステージング バケットを選択します。
[削除] をクリックしてバケットを削除します。確認ダイアログが表示されます。
[バケットの削除] ダイアログ ボックスで「
DELETE」と入力して削除コマンドを確認し、[削除] をクリックします。
サンプルソースを作成する
サンプルで使用するソースを作成します。このチュートリアルのサンプルでは、次のソースを使用します。
BigQuery データセットとテーブルを作成する
Pub/Sub トピックにスキーマを割り当てる
スキーマを割り当てると、Pub/Sub トピックデータに SQL クエリを実行できます。現在、Dataflow SQL では、Pub/Sub トピックのメッセージは JSON 形式でシリアル化されます。
Pub/Sub トピックのサンプル transactions にスキーマを割り当てるには:
Pub/Sub ソースを検索する
Dataflow SQL UI では、アクセス権を持つプロジェクトの Pub/Sub データソース オブジェクトを検索できます。フルネームを覚える必要がありません。
このチュートリアルの例では、Dataflow SQL エディタに移動して、作成した transactions Pub/Sub トピックを検索します。
スキーマを表示する
SQL クエリを作成する
Dataflow SQL UI で、Dataflow ジョブに実行する SQL クエリを作成します。
次の SQL クエリはデータ拡充クエリです。州と販売地域をマッピングする BigQuery テーブル(us_state_salesregions)を使用して、sales_region フィールドを Pub/Sub イベント ストリーム(transactions)に新たに追加します。
次の SQL クエリをコピーして、クエリエディタに貼り付けます。project-id は実際のプロジェクト ID に置き換えます。
SELECT tr.*, sr.sales_region FROM pubsub.topic.`project-id`.transactions as tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code
Dataflow SQL UI でクエリを入力すると、クエリ検証ツールによりクエリ構文が検証されます。クエリが有効な場合、緑色のチェックマーク アイコンが表示されます。クエリが無効な場合は、赤色の感嘆符アイコンが表示されます。クエリ構文が無効な場合は、バリデータ アイコンをクリックすると、修正が必要な箇所に関する情報が表示されます。
次のスクリーンショットでは、クエリエディタに有効なクエリが入力されています。緑色のチェックマークが表示されています。

SQL クエリを実行する Dataflow ジョブを作成する
SQL クエリを実行するには、Dataflow SQL UI から Dataflow ジョブを作成します。
Dataflow ジョブを表示する
Dataflow は、SQL クエリを Apache Beam パイプラインに変換します。[ジョブを表示] をクリックして Dataflow ウェブ UI を開き、パイプラインのグラフィカル表現を表示します。
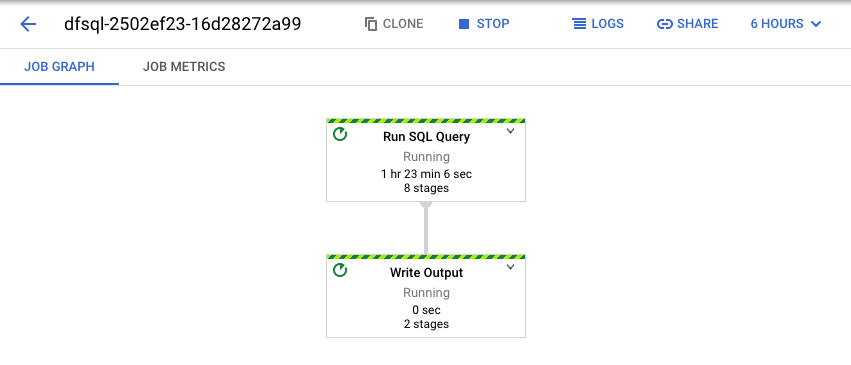
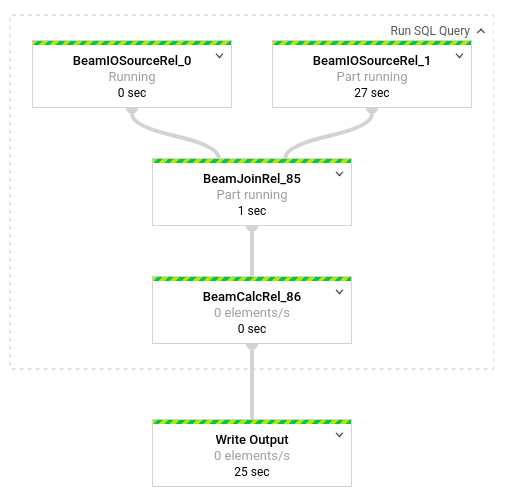
パイプライン内で発生している変換の詳細を確認するには、それぞれのボックスをクリックします。たとえば、「Run SQL Query」というラベルのボックスをクリックすると、バックグラウンドで実行されたオペレーションが表示されます。
最初の 2 つのボックスは、結合した 2 つの入力を表しています。1 つは Pub/Sub トピックの transactions で、もう 1 つは BigQuery テーブルの us_state_salesregions です。
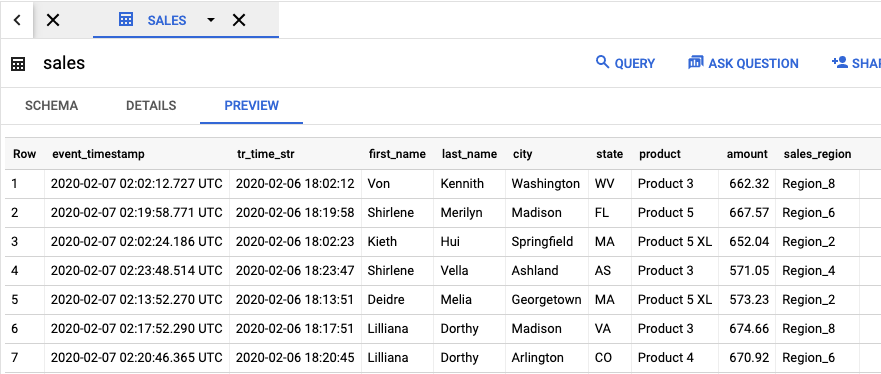
ジョブの結果が含まれる出力テーブルを表示するには、BigQuery UI に移動します。[エクスプローラ] パネルのプロジェクトで、作成した dataflow_sql_tutorial データセットをクリックします。出力テーブル sales をクリックします。出力テーブルの内容が [プレビュー] タブに表示されます。
以前に実行されたジョブを表示してクエリを編集する
Dataflow UI では、過去のジョブとクエリが Dataflow の [ジョブ] ページに保存されます。
ジョブ履歴リストを使用して、以前の SQL クエリを確認できます。たとえば、販売地域別の販売数を 15 秒ごとに集計するようにクエリを変更できます。[ジョブ] ページを使用して、このチュートリアルで開始した実行中のジョブにアクセスし、SQL クエリをコピーして、変更したクエリを使用して別のジョブを実行します。
クリーンアップ
このチュートリアルで使用したリソースについて、Cloud 請求先アカウントに課金されないようにする手順は次のとおりです。
次のステップ
- Dataflow SQL の概要を確認する。
- ストリーミング パイプラインの基本について学ぶ。
- Dataflow SQL リファレンスを確認する。
- Cloud Next 2019 で行われたストリーミング分析のデモを見る。