RunInference API を使用すると、複数のモデルを含むパイプラインを構築できます。マルチモデル パイプラインは、複数の ML モデルを必要とするビジネス上の問題を解決するための A/B テストの実施や、アンサンブルの構築などのタスクに役立ちます。
複数のモデルを使用する
次のコードサンプルは、RunInference 変換を使用して複数のモデルをパイプラインに追加する方法を示しています。
複数のモデルでパイプラインを構築する場合、次の 2 つのパターンのいずれかを使用できます。
- A/B 分岐パターン: 入力データの一部が 1 つのモデルに送信され、残りのデータは 2 番目のモデルに送信されます。
- シーケンス パターン: 入力データは 2 つのモデルを順に通過します。
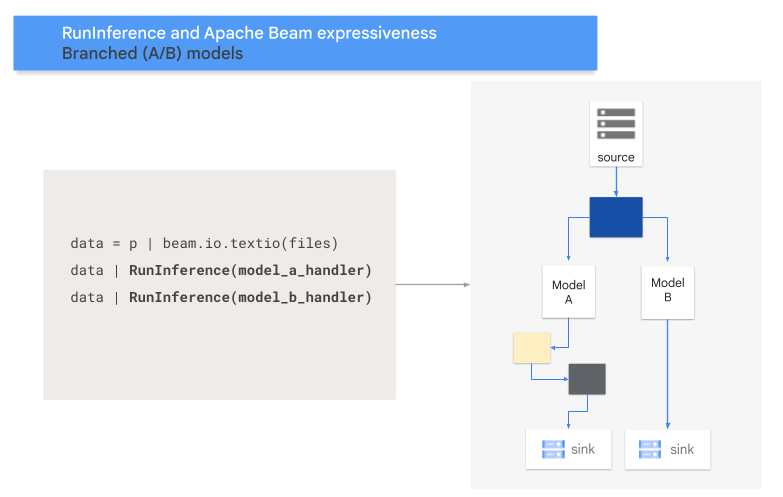
A/B パターン
次のコードは、RunInference 変換を使用して A/B パターンをパイプラインに追加する方法を示しています。
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('a_source')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = data | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A と MODEL_HANDLER_B は、モデルハンドラのセットアップ コードです。
次の図は、このプロセスを視覚的に表したものです。
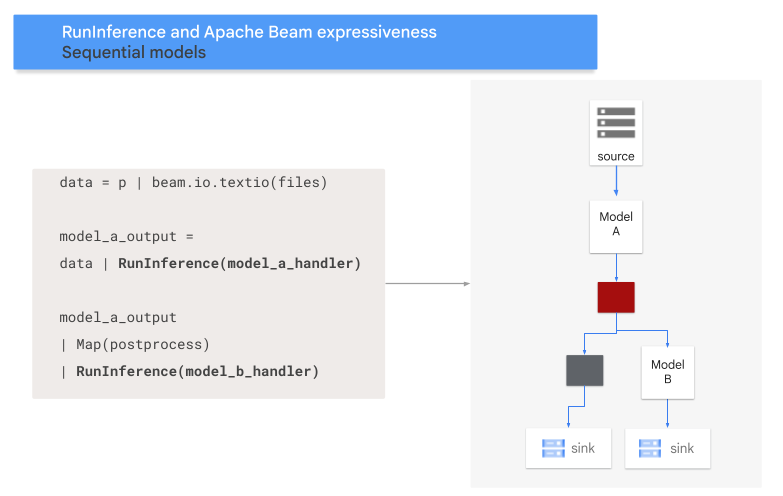
シーケンス パターン
次のコードは、RunInference 変換を使用してシーケンス パターンをパイプラインに追加する方法を示しています。
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('A_SOURCE')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = model_a_predictions | beam.Map(some_post_processing) | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A と MODEL_HANDLER_B は、モデルハンドラのセットアップ コードです。
次の図は、このプロセスを視覚的に表したものです。
モデルをキーにマッピングする
キー付きモデルハンドラを使用すると、複数のモデルを読み込んでキーにマッピングできます。モデルをキーにマッピングすると、同じ RunInference 変換で異なるモデルを使用できます。次の例では、CONFIG_1 を使用して 1 つのモデルを読み込み、CONFIG_2 を使用して 2 つ目のモデルを読み込む、キー付きモデルハンドラを使用しています。パイプラインは、CONFIG_1 に関連付けられたモデルを使用して、KEY_1 に関連付けられたサンプルに対して推論を実行します。CONFIG_2 に関連付けられたモデルは、KEY_2 と KEY_3 に関連付けられた例に対して推論を実行します。
from apache_beam.ml.inference.base import KeyedModelHandler
keyed_model_handler = KeyedModelHandler([
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2))
])
with pipeline as p:
data = p | beam.Create([
('KEY_1', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_2', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_3', torch.tensor([[1,2,3],[4,5,6],...])),
])
predictions = data | RunInference(keyed_model_handler)
詳細な例については、異なる方法でトレーニングされた複数のモデルを使用して ML 推論を実行するをご覧ください。
メモリを管理する
複数のモデルを同時に読み込むと、メモリ不足エラー(OOM)が発生する可能性があります。キー付きモデルハンドラを使用する場合、Apache Beam はメモリに読み込まれるモデルの数を自動的に制限しません。すべてのモデルがメモリに収まらない場合、メモリ不足エラーが発生し、パイプラインは失敗します。
この問題を回避するには、max_models_per_worker_hint パラメータを使用して、同時にメモリに読み込まれるモデルの数を制限します。次の例では、max_models_per_worker_hint パラメータを含むキー付きモデルハンドラを使用しています。max_models_per_worker_hint パラメータ値が 2 に設定されているため、パイプラインは各 SDK ワーカー プロセスで最大 2 つのモデルを同時に読み込めます。
mhs = [
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2)),
KeyModelMapping(['KEY_4'], PytorchModelHandlerTensor(CONFIG_3)),
KeyModelMapping(['KEY_5', 'KEY_5', 'KEY_6'], PytorchModelHandlerTensor(CONFIG_4)),
]
keyed_model_handler = KeyedModelHandler(mhs, max_models_per_worker_hint=2)
パイプラインを設計する際は、モデルとパイプライン変換の両方に十分なメモリをワーカーに用意してください。モデルによって使用されるメモリはすぐには解放されない可能性があるため、OOM を回避するために追加のメモリバッファを含めます。
多くのモデルが存在するときに、max_models_per_worker_hint パラメータの値を小さくすると、メモリ スラッシングが発生する可能性があります。メモリ スラッシングは、メモリの入出力モデルのスワップに過剰な実行時間が使用されると発生します。この問題を回避するには、推論ステップの前に GroupByKey 変換をパイプラインに含めます。GroupByKey 変換により、同じキーとモデルを持つ要素が同じワーカーに配置されます。
詳細
- Apache Beam のドキュメントでマルチモデル パイプラインについて読む。
- トレーニングが異なる複数のモデルで ML 推論を実行する。
- Colab でインタラクティブ ノートブックを実行する。