Vous pouvez utiliser l'API RunInference pour créer des pipelines contenant plusieurs modèles. Les pipelines multi-modèles sont utiles pour des tâches telles que les tests A/B et la création d'ensembles afin de résoudre des problèmes métier nécessitant plusieurs modèles de ML.
Utiliser plusieurs modèles
Les exemples de code suivants montrent comment utiliser la transformation RunInference pour ajouter plusieurs modèles à votre pipeline.
Lorsque vous créez des pipelines avec plusieurs modèles, vous pouvez utiliser l'un des deux modèles suivants :
- Modèle de branche A/B : une partie des données d'entrée est dirigée vers un modèle, et le reste vers un deuxième modèle.
- Schéma de séquence : les données d'entrée traversent deux modèles, l'un après l'autre.
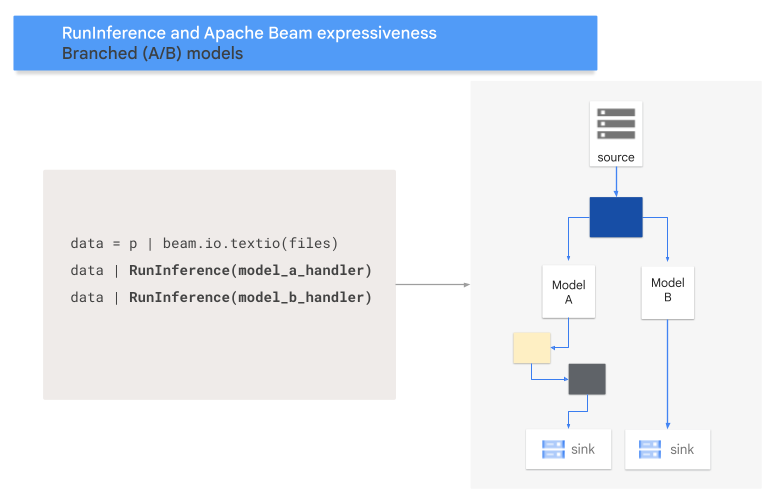
Modèle A/B
Le code suivant montre comment ajouter un modèle A/B à votre pipeline à l'aide de la transformation RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('a_source')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = data | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A et MODEL_HANDLER_B constituent le code de configuration du gestionnaire de modèles.
Le schéma suivant donne une représentation visuelle de ce processus.
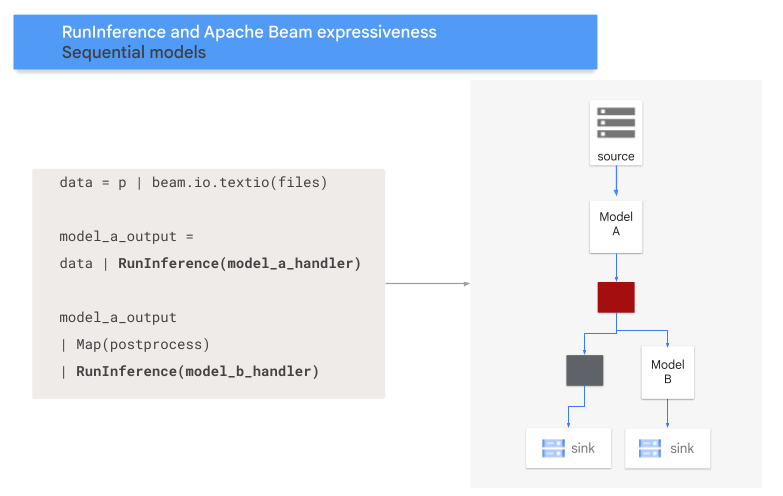
Modèle de séquence
Le code suivant montre comment ajouter un modèle de séquence à votre pipeline à l'aide de la transformation RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('A_SOURCE')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = model_a_predictions | beam.Map(some_post_processing) | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A et MODEL_HANDLER_B constituent le code de configuration du gestionnaire de modèles.
Le schéma suivant donne une représentation visuelle de ce processus.
Mapper des modèles sur des clés
Vous pouvez charger plusieurs modèles et les mapper à des clés à l'aide d'un gestionnaire de modèles à clé.
Le mappage de modèles sur des clés permet d'utiliser différents modèles dans la même transformation RunInference.
L'exemple suivant utilise un gestionnaire de modèles à clé qui charge un modèle à l'aide de CONFIG_1 et un second modèle à l'aide de CONFIG_2.
Le pipeline utilise le modèle associé à CONFIG_1 pour exécuter l'inférence sur des exemples associés à KEY_1.
Le modèle associé à CONFIG_2 exécute l'inférence sur des exemples associés à KEY_2 et KEY_3.
from apache_beam.ml.inference.base import KeyedModelHandler
keyed_model_handler = KeyedModelHandler([
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2))
])
with pipeline as p:
data = p | beam.Create([
('KEY_1', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_2', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_3', torch.tensor([[1,2,3],[4,5,6],...])),
])
predictions = data | RunInference(keyed_model_handler)
Pour obtenir un exemple plus détaillé, consultez la page Exécuter l'inférence ML avec plusieurs modèles entraînés différemment.
Gérer la mémoire
Lorsque vous chargez plusieurs modèles en même temps, vous pouvez rencontrer des erreurs de mémoire insuffisante. Lorsque vous utilisez un gestionnaire de modèles à clé, Apache Beam ne limite pas automatiquement le nombre de modèles chargés en mémoire. Lorsque les modèles ne rentrent pas tous dans la mémoire, une erreur de mémoire insuffisante se produit et le pipeline échoue.
Pour éviter ce problème, utilisez le paramètre max_models_per_worker_hint afin de limiter le nombre de modèles chargés en mémoire en même temps. L'exemple suivant utilise un gestionnaire de modèles à clé avec le paramètre max_models_per_worker_hint.
Comme la valeur du paramètre max_models_per_worker_hint est définie sur 2, le pipeline charge jusqu'à deux modèles sur chaque processus de nœud de calcul du SDK en même temps.
mhs = [
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2)),
KeyModelMapping(['KEY_4'], PytorchModelHandlerTensor(CONFIG_3)),
KeyModelMapping(['KEY_5', 'KEY_5', 'KEY_6'], PytorchModelHandlerTensor(CONFIG_4)),
]
keyed_model_handler = KeyedModelHandler(mhs, max_models_per_worker_hint=2)
Lorsque vous concevez votre pipeline, assurez-vous que les nœuds de calcul disposent de suffisamment de mémoire pour les modèles et pour les transformations de pipeline. Étant donné que la mémoire utilisée par les modèles peut ne pas être libérée immédiatement, pour éviter les OOM, incluez un tampon de mémoire supplémentaire.
Si vous avez de nombreux modèles et que vous utilisez une valeur faible avec le paramètre max_models_per_worker_hint, vous risquez de rencontrer une situation de thrashing de mémoire. Le thrashing de la mémoire se produit lorsque des temps d'exécution excessifs sont utilisés pour échanger des modèles dans la mémoire. Pour éviter ce problème, incluez une transformation GroupByKey dans le pipeline avant l'étape d'inférence. La transformation GroupByKey garantit que les éléments ayant la même clé et le même modèle se trouvent sur le même nœud de calcul.
En savoir plus
- Documentez-vous sur les pipelines multi-modèles dans la documentation d'Apache Beam.
- Exécuter l'inférence ML avec plusieurs modèles entraînés différemment.
- Exécutez un notebook interactif dans Colab.