本教程介绍如何使用 Dataflow SQL 将来自 Pub/Sub 的数据流与 BigQuery 表中的数据联接起来。
目标
在本教程中,您将执行以下操作:
- 编写 Dataflow SQL 查询,该查询将 Pub/Sub 流式数据与 BigQuery 表中的数据联接起来。
- 从 Dataflow SQL 界面部署 Dataflow 作业。
费用
在本文档中,您将使用 Google Cloud 的以下收费组件:
- Dataflow
- Cloud Storage
- Pub/Sub
- Data Catalog
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. - 安装并初始化 gcloud CLI。请选择一个安装选项。
您可能需要将
project属性设置为要用于本演示的项目。 - 转到 Google Cloud 控制台中的 Dataflow SQL 网页界面。这将打开您最近访问的项目。如需切换到其他项目,请点击 BigQuery SQL 网页界面顶部的项目名称,然后搜索要使用的项目。
转到 Dataflow SQL 网页界面
创建示例来源
如果您希望按照本教程中提供的示例进行操作,请创建以下来源并在本教程的步骤中使用。
- Pub/Sub 主题
transactions- 通过订阅 Pub/Sub 主题收到的交易信息数据流。每笔交易的数据包括购买的产品、售价以及发生购买交易的城市和州等信息。创建 Pub/Sub 主题后,您可以创建一个将消息发布到主题的脚本。您将在本教程的后续部分中运行此脚本。 - BigQuery 表格
us_state_salesregions- 提供州与销售区域对应关系的表格。在创建此表之前,您需要创建 BigQuery 数据集。
创建 BigQuery 数据集和表
- 在 BigQuery 网页界面上创建 BigQuery 数据集。BigQuery 数据集是用于包含表格的顶层容器。BigQuery 表必须属于一个数据集。
- 在探索器面板中,打开项目对应的操作。在菜单中,点击创建数据集。在以下屏幕截图中,项目 ID 为
dataflow-sql。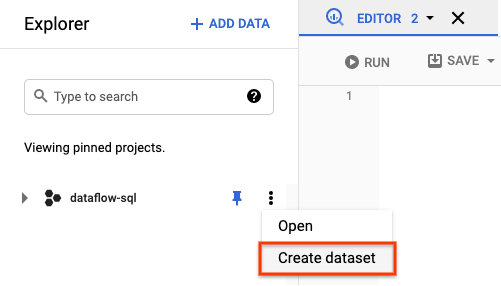
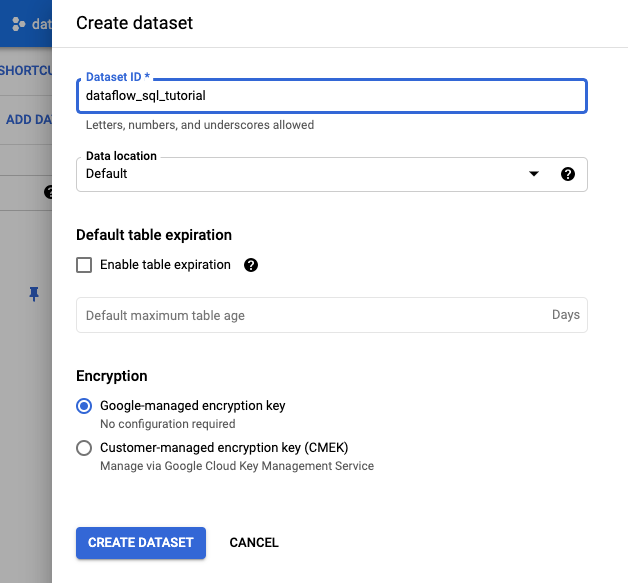
- 在打开的创建数据集面板中,对于数据集 ID,输入
dataflow_sql_tutorial。 - 对于数据位置,从菜单中选择一个选项。
- 点击创建数据集。
- 在探索器面板中,打开项目对应的操作。在菜单中,点击创建数据集。在以下屏幕截图中,项目 ID 为
- 创建 BigQuery 表。
- 创建一个文本文件并将其命名为
us_state_salesregions.csv。 - 将以下数据复制并粘贴到
us_state_salesregions.csv中。 在接下来的步骤中,您需要将这些数据加载到 BigQuery 表中。state_id,state_code,state_name,sales_region 1,MO,Missouri,Region_1 2,SC,South Carolina,Region_1 3,IN,Indiana,Region_1 6,DE,Delaware,Region_2 15,VT,Vermont,Region_2 16,DC,District of Columbia,Region_2 19,CT,Connecticut,Region_2 20,ME,Maine,Region_2 35,PA,Pennsylvania,Region_2 38,NJ,New Jersey,Region_2 47,MA,Massachusetts,Region_2 54,RI,Rhode Island,Region_2 55,NY,New York,Region_2 60,MD,Maryland,Region_2 66,NH,New Hampshire,Region_2 4,CA,California,Region_3 8,AK,Alaska,Region_3 37,WA,Washington,Region_3 61,OR,Oregon,Region_3 33,HI,Hawaii,Region_4 59,AS,American Samoa,Region_4 65,GU,Guam,Region_4 5,IA,Iowa,Region_5 32,NV,Nevada,Region_5 11,PR,Puerto Rico,Region_6 17,CO,Colorado,Region_6 18,MS,Mississippi,Region_6 41,AL,Alabama,Region_6 42,AR,Arkansas,Region_6 43,FL,Florida,Region_6 44,NM,New Mexico,Region_6 46,GA,Georgia,Region_6 48,KS,Kansas,Region_6 52,AZ,Arizona,Region_6 56,TN,Tennessee,Region_6 58,TX,Texas,Region_6 63,LA,Louisiana,Region_6 7,ID,Idaho,Region_7 12,IL,Illinois,Region_7 13,ND,North Dakota,Region_7 31,MN,Minnesota,Region_7 34,MT,Montana,Region_7 36,SD,South Dakota,Region_7 50,MI,Michigan,Region_7 51,UT,Utah,Region_7 64,WY,Wyoming,Region_7 9,NE,Nebraska,Region_8 10,VA,Virginia,Region_8 14,OK,Oklahoma,Region_8 39,NC,North Carolina,Region_8 40,WV,West Virginia,Region_8 45,KY,Kentucky,Region_8 53,WI,Wisconsin,Region_8 57,OH,Ohio,Region_8 49,VI,United States Virgin Islands,Region_9 62,MP,Commonwealth of the Northern Mariana Islands,Region_9
- 在 BigQuery 界面的探索器面板中,展开您的项目以查看
dataflow_sql_tutorial数据集。 - 打开
dataflow_sql_tutorial数据集的操作菜单,然后点击打开。 - 点击创建表。
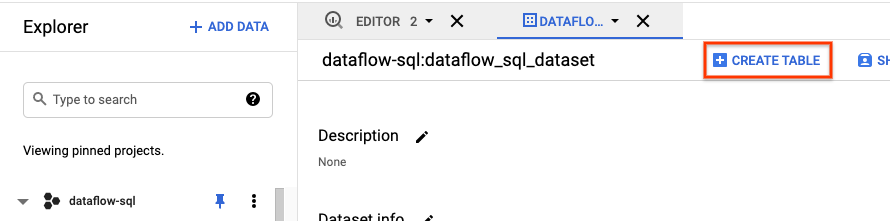
- 在打开的创建表面板中,执行以下操作:
- 在基于以下数据创建表部分,选择上传。
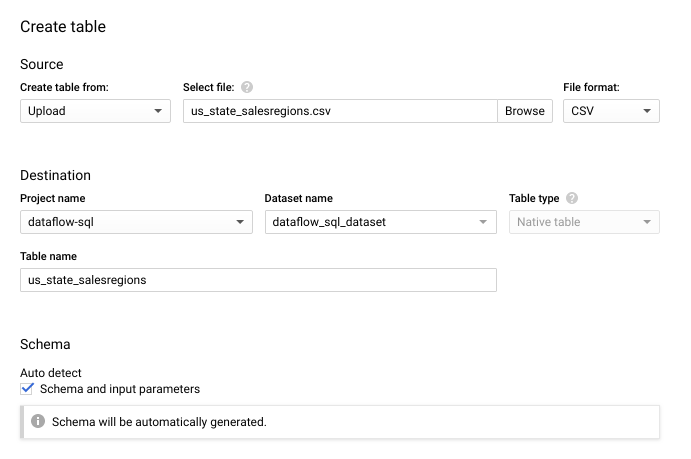
- 对于选择文件,点击浏览,然后选择
us_state_salesregions.csv文件。 - 对于表,输入
us_state_salesregions。 - 在架构下,选择自动检测。
- 点击高级选项以展开高级选项部分。
- 对于需跳过的标题行数,输入
1,然后点击创建表。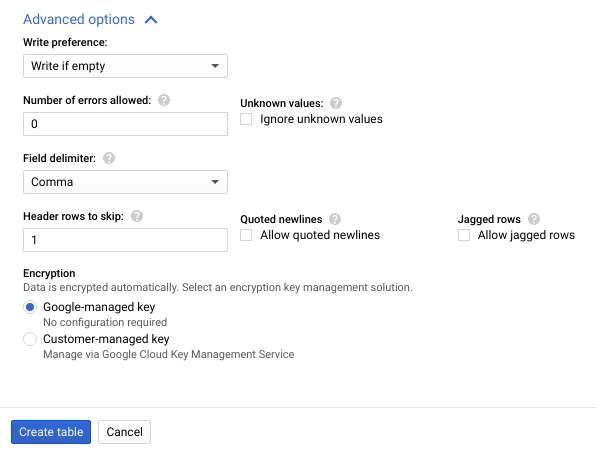
- 在基于以下数据创建表部分,选择上传。
- 在探索器面板中,点击
us_state_salesregions。在架构下,您可以查看自动生成的架构。在预览下,您可以看到表数据。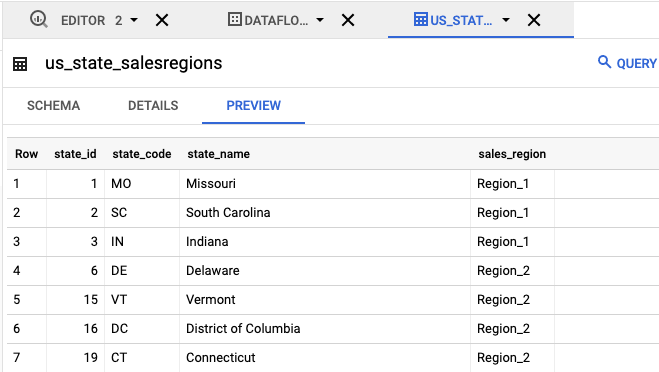
- 创建一个文本文件并将其命名为
为您的 Pub/Sub 主题分配架构
通过分配架构,您可以对 Pub/Sub 主题数据运行 SQL 查询。当前,Dataflow SQL 要求将 Pub/Sub 主题中的消息序列化为 JSON 格式。
如需为示例 Pub/Sub 主题 transactions 分配架构,请执行以下操作:
创建一个文本文件并将其命名为
transactions_schema.yaml。将以下架构文本复制并粘贴到transactions_schema.yaml。- column: event_timestamp description: Pub/Sub event timestamp mode: REQUIRED type: TIMESTAMP - column: tr_time_str description: Transaction time string mode: NULLABLE type: STRING - column: first_name description: First name mode: NULLABLE type: STRING - column: last_name description: Last name mode: NULLABLE type: STRING - column: city description: City mode: NULLABLE type: STRING - column: state description: State mode: NULLABLE type: STRING - column: product description: Product mode: NULLABLE type: STRING - column: amount description: Amount of transaction mode: NULLABLE type: FLOAT使用 Google Cloud CLI 分配架构。
a. 使用以下命令更新 gcloud CLI。确保 gcloud CLI 的版本为 242.0.0 或更高版本。
gcloud components update
b. 在命令行窗口中运行以下命令。将 project-id 替换为您的项目 ID,将 path-to-file 替换为
transactions_schema.yaml文件的路径。gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`project-id`.transactions' \ --schema-from-file=path-to-file/transactions_schema.yaml
如需详细了解命令的参数和允许使用的架构文件格式,请参阅 gcloud data-catalog entries update 的文档页面。
c. 确认您的架构已成功分配给
transactionsPub/Sub 主题。请将 project-id 替换为您的项目 ID。gcloud data-catalog entries lookup 'pubsub.topic.`project-id`.transactions'
查找 Pub/Sub 来源
使用 Dataflow SQL 界面,您可以找到自己有权访问的任何项目的 Pub/Sub 数据源对象,因此您不必记住这些对象的完整名称。
对于本教程中的示例,前往 Dataflow SQL 编辑器并搜索您创建的 transactions Pub/Sub 主题:
前往 SQL 工作区。
在 Dataflow SQL 编辑器面板的搜索栏中,搜索
projectid=project-id transactions。请将 project-id 替换为您的项目 ID。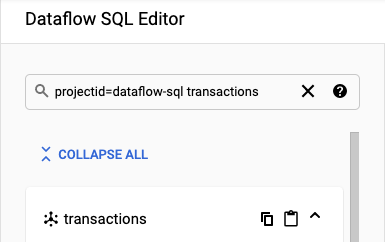
查看架构
- 在 Dataflow SQL 界面的 Dataflow SQL 编辑器面板中,点击事务或者输入
projectid=project-id system=cloud_pubsub来搜索 Pub/Sub 主题,然后选择主题。 在架构下,您可以查看分配给 Pub/Sub 主题的架构。
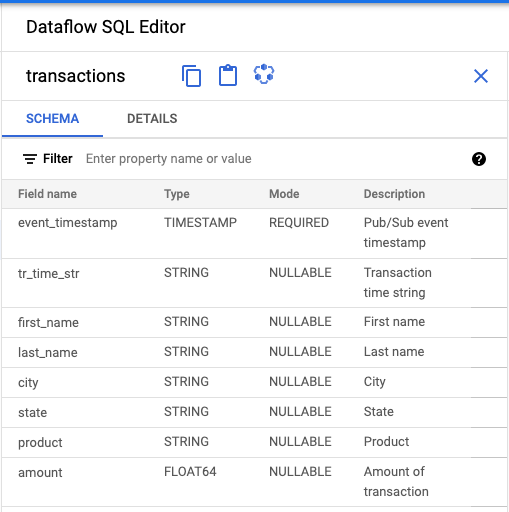
创建 SQL 查询
您可以在 Dataflow SQL 界面上创建运行 Dataflow 作业的 SQL 查询。
以下 SQL 查询为数据扩充查询。该查询会向 Pub/Sub 事件流 (transactions) 额外添加一个字段 sales_region,该字段使用州与销售区域对应关系 BigQuery 表 (us_state_salesregions)。
复制以下 SQL 查询并粘贴到查询编辑器中。将 project-id 替换为您的项目 ID。
SELECT tr.*, sr.sales_region FROM pubsub.topic.`project-id`.transactions as tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code
在 Dataflow SQL 界面中输入查询时,查询验证器会验证查询语法。如果查询有效,会显示一个绿色对勾标记图标。如果查询无效,则会显示一个红色感叹号图标。如果查询语法无效,您可以点击验证器图标,查看有关您需要解决的问题的相关信息。
以下屏幕截图展示了查询编辑器中的有效查询。验证器显示绿色对勾标记。

创建 Dataflow 作业以运行 SQL 查询
如需运行 SQL 查询,请通过 Dataflow SQL 界面创建 Dataflow 作业。
在查询编辑器中,点击创建作业。
在打开的创建 Dataflow 作业面板中:
- 对于目标位置,选择 BigQuery。
- 对于数据集 ID,选择
dataflow_sql_tutorial。 - 在表名称部分,输入
sales。
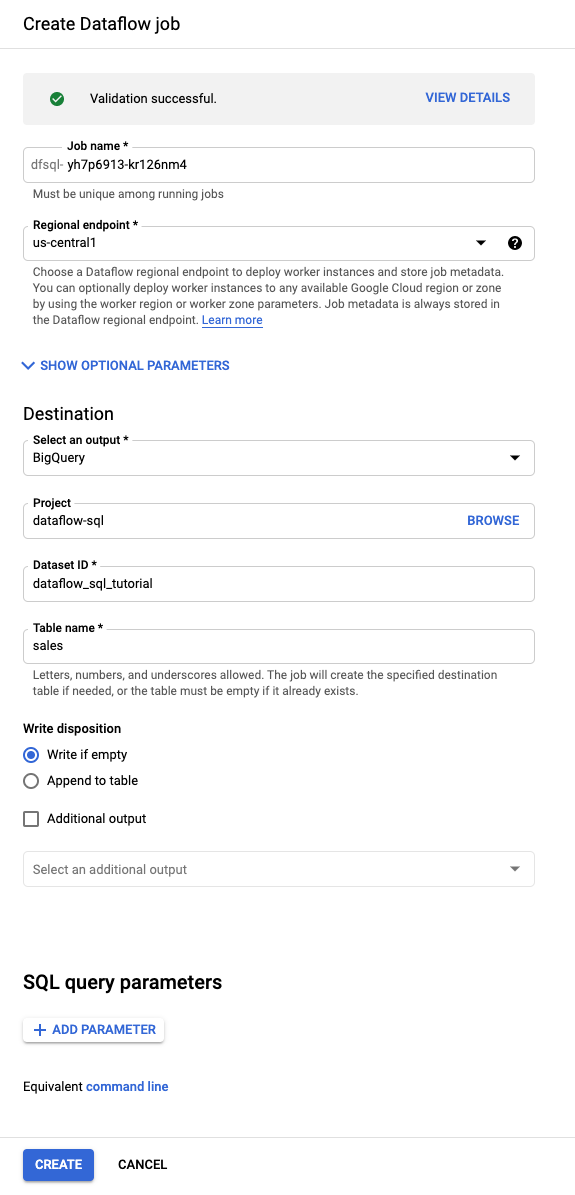
可选:Dataflow 会自动选择最适合您的 Dataflow SQL 作业的设置,但您可以展开可选参数菜单,手动指定以下流水线选项:
- 工作器数量上限
- 可用区
- 服务账号电子邮件地址
- 机器类型
- 其他实验
- 工作器 IP 地址配置
- 网络
- 子网
点击创建。Dataflow 作业需要几分钟才能开始运行。
查看 Dataflow 作业
Dataflow 将您的 SQL 查询转换为 Apache Beam 流水线。点击查看作业以打开 Dataflow 网页界面,您可以在其中查看流水线的图形表示。
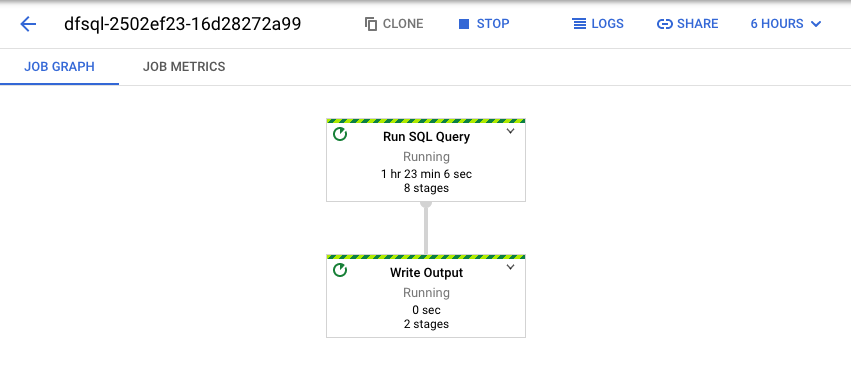
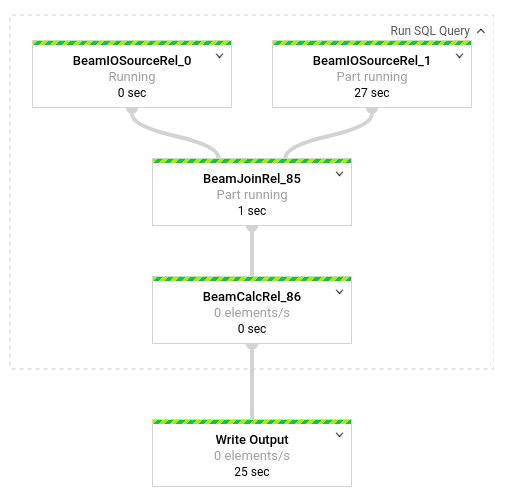
如需查看流水线中发生的转换详情,请点击这些框。例如,如果您点击图形表示中标有运行 SQL 查询的第一个框,则会出现一个图形,显示后台进行的操作。
最前面的两个框表示您联接的两个输入:Pub/Sub 主题 transactions 和 BigQuery 表 us_state_salesregions。
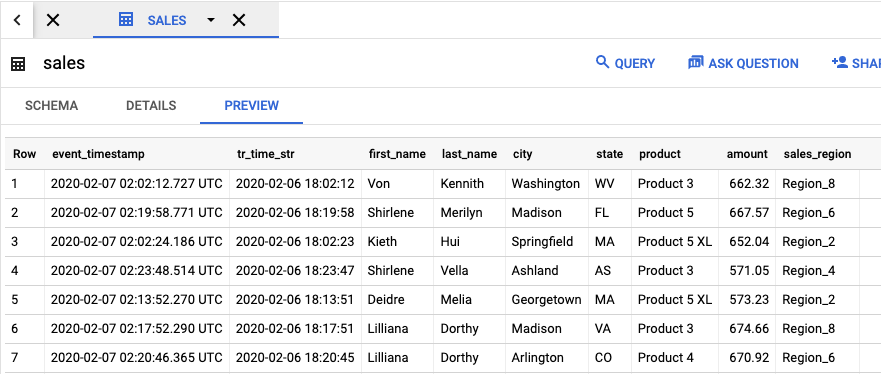
如需查看包含作业结果的输出表,请前往 BigQuery 界面。在探索器面板的项目中,点击您创建的 dataflow_sql_tutorial 数据集。然后,点击输出表 sales。预览标签页会显示该输出表的内容。
查看历史作业并修改查询
Dataflow 界面在 Dataflow 作业页面中存储历史作业和查询。
您可以使用作业历史记录列表查看之前的 SQL 查询。例如,您希望修改查询,每 15 秒按销售区域汇总销售额。您可以通过作业页面访问您在本教程前面部分启动并正在运行的作业,复制 SQL 查询,并使用修改后的查询运行另一个作业。
在 Dataflow 作业页面中,点击要修改的作业。
在作业详细信息页面的作业信息面板中,在流水线选项下找到 SQL 查询。查找 queryString 所在的行。
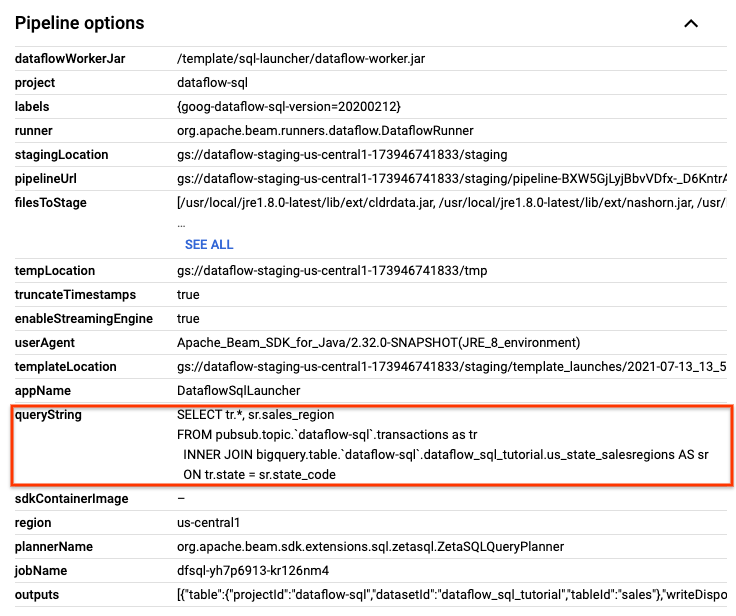
将以下 SQL 查询复制并粘贴到 SQL 工作区的 Dataflow SQL 编辑器中,以添加翻转窗口。 请将 project-id 替换为您的项目 ID。
SELECT sr.sales_region, TUMBLE_START("INTERVAL 15 SECOND") AS period_start, SUM(tr.amount) as amount FROM pubsub.topic.`project-id`.transactions AS tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code GROUP BY sr.sales_region, TUMBLE(tr.event_timestamp, "INTERVAL 15 SECOND")
点击创建作业以使用修改后的查询创建新作业。
清理
为避免因本教程中使用的资源导致您的 Cloud Billing 账号产生费用,请执行以下操作:
如果
transactions_injector.py发布脚本仍在运行,请将其停止。停止正在运行的 Dataflow 作业。转到 Google Cloud 控制台中的 Dataflow 网页界面。
针对您按照本演示创建的每个作业,执行以下步骤:
点击作业的名称。
在作业详情页面上,点击停止。系统会显示停止作业对话框,其中包含停止作业的选项:
选择取消。
点击停止作业。该服务将尽可能快地停止所有数据注入和处理操作。由于使用取消选项会立即停止处理过程,因此您可能会丢失所有“传输中”数据。停止作业可能需要几分钟。
删除 BigQuery 数据集。转到 Google Cloud 控制台中的 BigQuery 网页界面。
在探索器面板的资源部分中,点击您创建的 dataflow_sql_tutorial 数据集。
在详细信息面板中,点击删除。此时会打开一个确认对话框。
在删除数据集对话框中,输入
delete以确认删除命令,然后点击删除。
删除 Pub/Sub 主题。转到 Google Cloud 控制台中的 Pub/Sub 主题页面。
选择
transactions主题。点击删除以永久删除该主题。 此时会打开一个确认对话框。
在删除主题对话框中,输入
delete以确认删除命令,然后点击删除。转到 Pub/Sub 订阅页面。
选择要
transactions的任何剩余订阅。如果您的作业不再运行,则可能不会有任何订阅。点击删除以永久删除该订阅。 在确认对话框中点击删除。
删除 Cloud Storage 中的 Dataflow 暂存存储分区。进入 Google Cloud 控制台中的 Cloud Storage 存储桶页面。
选择 Dataflow 暂存存储桶。
点击删除以永久删除该存储分区。 此时会打开一个确认对话框。
在删除存储桶对话框中,输入
DELETE以确认删除命令,然后点击删除。
后续步骤
- 参阅 Dataflow SQL 简介。
- 了解流处理流水线基础知识。
- 探索 Dataflow SQL 参考。
- 观看 Cloud Next 2019 大会的流式分析演示视频。