Sie können nach den folgenden Datenassets suchen:
- Mit Analytics Hub verknüpfte Datasets
- BigQuery-Datasets, -Tabellen, -Ansichten und -Modelle
- Bigtable-Instanzen, -Cluster und -Tabellen (einschließlich Details zur Spaltenfamilie)
- Tag-Vorlagen, Eintragsgruppen und benutzerdefinierte Einträge für Data Catalog
- Dataplex-Lakes, -Zonen, -Tabellen und -Datensätze
- Dataproc Metastore-Dienste, ‑Datenbanken und ‑Tabellen
- Pub/Sub-Datenströme
- Spanner-Instanzen, ‑Datenbanken, ‑Tabellen und ‑Ansichten
- Vertex AI-Modelle, Datasets und Vertex AI Feature Store-Ressourcen
- Assets in Unternehmensdatensilos, die mit Data Catalog verbunden sind
Suchbereich
Je nach Berechtigungen können die Suchergebnisse variieren. Die Suchergebnisse in Data Catalog sind nach Ihrer Rolle eingegrenzt.
Hier finden Sie Informationen zu den verschiedenen IAM-Rollen und -Berechtigungen, die für den Data Catalog verfügbar sind. Wenn Sie beispielsweise BigQuery-Metadaten-Lesezugriff auf ein Objekt haben, wird dieses Objekt in Ihren Data Catalog-Suchergebnissen angezeigt.
In der folgenden Liste sind die Mindestberechtigungen aufgeführt, die für die Suche erforderlich sind:
Zum Suchen nach einer Tabelle benötigen Sie die
bigquery.tables.get-Berechtigung für diese Tabelle.Zur Suche nach einem Dataset benötigen Sie die Berechtigung
bigquery.datasets.getfür dieses Dataset.Wenn Sie nach Metadaten für einen Datensatz oder eine Tabelle suchen möchten, benötigen Sie die IAM-Rolle
roles/bigquery.metadataViewer.Wenn Sie nach allen Ressourcen in einem Projekt oder einer Organisation suchen möchten, benötigen Sie die Berechtigung
datacatalog.catalogs.searchAll. Sie funktioniert unabhängig vom Quellsystem für alle Ressourcen.
Wenn Sie Zugriff auf eine BigQuery-Tabelle, aber nicht auf das Dataset haben, das diese Tabelle enthält, wird die Tabelle trotzdem in der Data Catalog-Suche wie erwartet angezeigt. Die gleiche Zugriffslogik gilt für alle unterstützten Systeme wie Pub/Sub und Data Catalog selbst.
Probleme in der Suche aufrufen
Data Catalog-Suchabfragen garantieren keine vollständige Trefferquote. Ergebnisse, die Ihrer Abfrage entsprechen, werden möglicherweise auch auf nachfolgenden Ergebnisseiten nicht zurückgegeben. Außerdem können die zurückgegebenen (und nicht zurückgegebenen) Ergebnisse variieren, wenn Sie Suchanfragen wiederholen.
Wenn Trefferquotenprobleme auftreten und Sie die Ergebnisse nicht in einer bestimmten Reihenfolge abrufen müssen, sollten Sie den Parameter orderBy beim Aufrufen der Methode Katalogsuche auf default setzen.
Verwenden Sie das Flag admin_search.
Wenn Sie das Flag admin_search in der Suchanfrage verwenden, wird der vollständige Abruf sichergestellt.
Für die Administratorsuche muss die Berechtigung datacatalog.catalogs.searchAll für alle Projekte und Organisationen im Suchumfang festgelegt sein. Bei Verwendung von admin_search ist nur default orderBy zulässig.
Nach Datum getrennte Tabellen
Data Catalog aggregiert nach Datum fragmentierte Tabellen zu einem einzigen logischen Eintrag. Dieser Eintrag hat dasselbe Schema wie die Tabelle mit dem neuesten Datum und enthält zusammengefasste Informationen über die Gesamtzahl der Shards. Der Eintrag bezieht sich auf die Zugriffsebene des Datasets, zu dem er gehört. In der Data Catalog-Suche werden diese logischen Einträge nur angezeigt, wenn der Nutzer Zugriff auf das Dataset hat, in dem sie enthalten sind. Einzelne datumsfragmentierte Tabellen werden in der Data Catalog-Suche nicht angezeigt, auch wenn sie in Data Catalog vorhanden sind und getaggt werden können.
Filter
Mit Filtern können Sie die Suchergebnisse eingrenzen. Alle Filter werden in Abschnitten gruppiert:
- Mit Bereich können Sie die Suche auf Elemente mit Markierungen beschränken.
- Systeme wie BigQuery, Pub/Sub, Dataplex, Dataproc Metastore, benutzerdefinierte Systeme, Vertex AI und Data Catalog selbst. Das Data Catalog-System enthält Dateisätze und benutzerdefinierte Einträge.
- Lakes und Zonen stammen aus Dataplex.
- Datentypen wie Datenstreams, Datasets, Data Lakes, Zonen, Dateisätze, Modelle, Tabellen, Ansichten, Dienste, Datenbanken und benutzerdefinierte Typen.
- Unter Projekte werden alle verfügbaren Projekte aufgelistet.
- Unter Tags werden alle verfügbaren Tag-Vorlagen (und ihre einzelnen Felder) aufgelistet.
- Datasets stammen aus BigQuery und Vertex AI.
- Öffentliche Datasets sind öffentlich verfügbare Daten aus BigQuery.
Sie können Filter aus mehreren Abschnitten kombinieren, um Assets zu finden, die mit mindestens einer Bedingung aus jedem ausgewählten Abschnitt übereinstimmen. Mehrere Filter, die in einem einzelnen Bereich ausgewählt wurden, werden mit dem logischen Operator OR ausgewertet. Betrachten Sie beispielsweise die folgende Filterkombination:
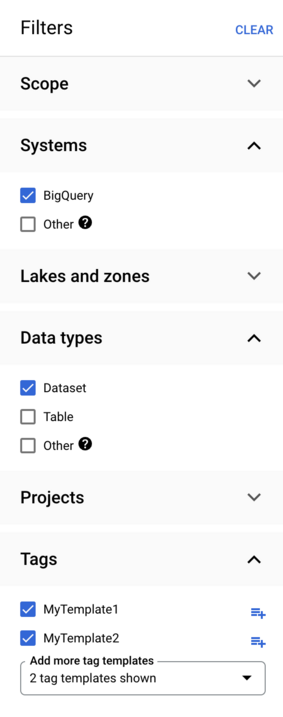
Data Catalog sucht nach Folgendem:
BigQuery-Datasets, die mit der Vorlage
MyTemplate1getaggt sindBigQuery-Datasets, die mit der Vorlage
MyTemplate2getaggt sindBigQuery-Tabellen, die mit der Vorlage
MyTemplate1getaggt sindBigQuery-Tabellen, die mit der Vorlage
MyTemplate2getaggt sind
Nach Tag-Wert filtern
Mit den Filtern Tags können Sie nach Assets suchen, die mit einer bestimmten Vorlage getaggt sind. Über das Menü Anpassen können Sie die Ergebnisse weiter eingrenzen und nach bestimmten Tag-Werten filtern. Die Filterbedingungen für Tag-Werte hängen vom Datentyp des Tag-Felds ab. Für Datums-/Uhrzeit- und Zahlenfelder können Sie beispielsweise ein bestimmtes Datum oder einen Bereich angeben.
Sichtbarkeit von Filtern
Die in den einzelnen Abschnitten angezeigten Filter hängen von der aktuellen Suchanfrage im Feld Suchen ab. Der gesamte Satz von Suchergebnissen kann Einträge enthalten, die mit der aktuellen Abfrage übereinstimmen. Die Filter, die diesen Einträgen entsprechen, werden jedoch möglicherweise nicht im Bereich Filter angezeigt.
Nach Datenassets suchen
Console
Console
Rufen Sie in der Google Cloud Console die Seite der Dataplex-Suche auf.
Wählen Sie unter Suchplattform auswählen als Suchmodus Data Catalog aus.
Geben Sie Ihre Suchanfrage in das Suchfeld ein oder verwenden Sie den Bereich Filter, um die Suchparameter zu verfeinern.
Sie können die folgenden Filter manuell hinzufügen:
- Fügen Sie unter Projekte einen Projektfilter hinzu. Klicken Sie auf Projekt hinzufügen, suchen Sie nach einem bestimmten Projekt, wählen Sie es aus und klicken Sie auf Öffnen.
- Fügen Sie unter Tags einen Tag-Vorlagenfilter hinzu. Klicken Sie auf das Menü Weitere Tag-Vorlagen hinzufügen, suchen Sie nach einer bestimmten Vorlage, wählen Sie sie aus und klicken Sie auf OK.
Wenn Sie zusätzlich zu den für Sie verfügbaren Assets nach Datenassets suchen möchten, die in Google Cloud öffentlich verfügbar sind, wählen Sie Öffentliche Datasets einschließen aus. Google Cloud
Außerdem haben Sie folgende Möglichkeiten:
Filtern Sie Ihre Suche, indem Sie im Suchfeld den Suchbegriffen ein keyword:value hinzufügen:
Keyword Beschreibung name:Übereinstimmung mit dem Namen des Datenassets column:Übereinstimmung mit dem Spaltennamen oder dem verschachtelten Spaltennamen description:Übereinstimmung mit der Tabellenbeschreibung Für eine Tag-Suche stellen Sie den Suchbegriffen im Suchfeld einen der folgenden Tag-Suchbegriffe voran:
Tag Beschreibung tag:project-name.tag_template_nameStimmt mit Tag-Namen überein. tag:project-name.tag_template_name.keyStimmt mit Tag-Schlüssel überein. tag:project-name.tag_template_name.key:valueStimmt mit Tag- key:string value-Paar überein
Tipps zu Suchausdrücken
Setzen Sie den Suchausdruck in Anführungszeichen ("
search terms"), wenn er Leerzeichen enthält.Sie können dem Schlüsselwort „NOT“ voranstellen (in Großbuchstaben), um die logische Negation des Filters
keyword:termzu berücksichtigen. Sie können auch die Booleschen Operatoren "AND" und "OR" (in Großbuchstaben) verwenden, um Suchausdrücke zu kombinieren.Beispiel:
NOT column:termlistet alle Spalten mit Ausnahme derjenigen auf, die dem angegebenen Begriff entsprechen. Eine Liste mit Suchbegriffen und anderen Begriffen, die Sie in einem Data Catalog-Suchausdruck verwenden können, finden Sie unter Data Catalog-Suchsyntax.
Suchbeispiel
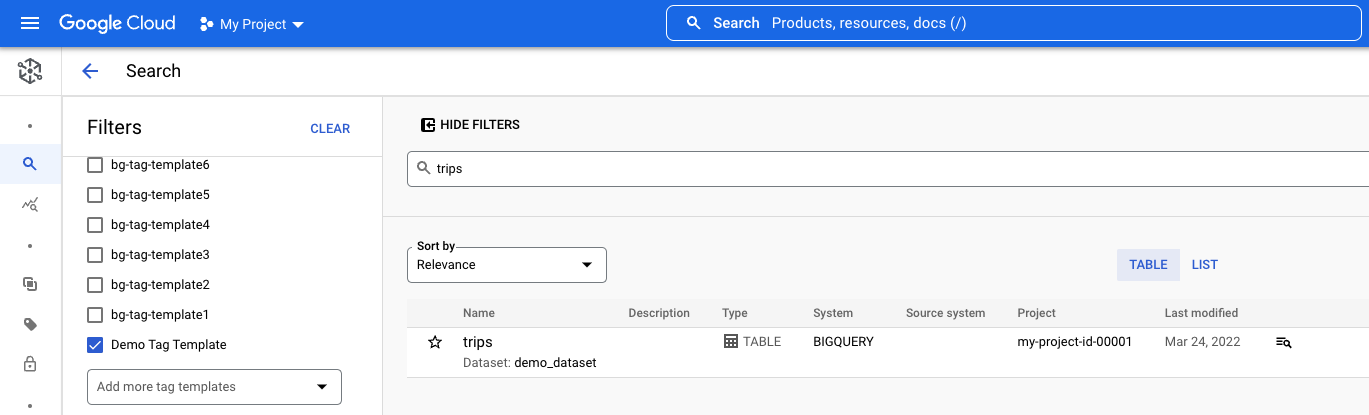
Angenommen, Sie möchten nach der Tabelle trips suchen, die Sie im Artikel BigQuery-Tabelle mithilfe von Data Catalog taggen eingerichtet haben:
- Geben Sie im Suchfeld
tripsein und klicken Sie auf Suchen. Wählen Sie im Bereich Filter Folgendes aus:
- Wählen Sie im Bereich Systeme die Option BigQuery aus, um Datenassets mit demselben Namen auszuschließen, die zu anderen Systemen gehören.
- Wählen Sie im Abschnitt Projekte Ihre Projekt-ID aus, um Daten-Assets aus anderen Projekten auszuschließen. Wenn Ihr Projekt nicht angezeigt wird, klicken Sie auf Projekt hinzufügen und wählen Sie es aus.
- Wählen Sie im Bereich Tags die Option Demo-Tag-Vorlage aus, um zu sehen, ob ein Tag, das diese Vorlage verwendet, an die Tabelle
tripsangehängt wird. Wenn diese Vorlage nicht angezeigt wird, klicken Sie auf Weitere Tag-Vorlagen hinzufügen, suchen Sie die Tag-Vorlage, wählen Sie sie aus und klicken Sie auf OK.
Bei allen ausgewählten Filtern sollten die Suchergebnisse nur einen Eintrag enthalten – die BigQuery-Tabelle trips in Ihrem Projekt mit dem angehängten Tag, das die Vorlage Demo Tag Template verwendet.
Java
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für Java in der Data Catalog-Kurzanleitung mit Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Data Catalog Java API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich beim Data Catalog zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für Node.js in der Data Catalog-Kurzanleitung mit Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Data Catalog Node.js API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich beim Data Catalog zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für Python in der Data Catalog-Kurzanleitung mit Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Data Catalog Python API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich beim Data Catalog zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
REST UND BEFEHLSZEILE
REST
Wenn Sie keinen Zugriff auf Cloud Client-Bibliotheken für Ihre Sprache haben oder die API mit REST-Anfragen testen möchten, sehen Sie sich die folgenden Beispiele an und lesen Sie die Dokumentation zur Data Catalog REST API.
1. Katalog durchgehen
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- organization-id: GCP-Organisations-ID
- project-id: GCP-Projekt-ID
HTTP-Methode und URL:
POST https://datacatalog.googleapis.com/v1/catalog:search
JSON-Text anfordern:
{
"query":"trips",
"scope":{
"includeOrgIds":[
"organization-id"
]
}
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"results":[
{
"searchResultType":"ENTRY",
"searchResultSubtype":"entry.table",
"relativeResourceName":"projects/project-id/locations/US/entryGroups/@bigquery/entries/entry1-id",
"linkedResource":"//bigquery.googleapis.com/projects/project-id/datasets/demo_dataset/tables/taxi_trips"
},
{
"searchResultType":"ENTRY",
"searchResultSubtype":"entry.table",
"relativeResourceName":"projects/project-id/locations/US/entryGroups/@bigquery/entries/entry2-id",
"linkedResource":"//bigquery.googleapis.com/projects/project-id/datasets/demo_dataset/tables/tlc_yellow_trips_2018"
}
]
}
Tabellendetails ansehen
Im Data Catalog können Sie sich Tabellendetails ansehen.
Rufen Sie in der Google Cloud Console die Seite der Dataplex-Suche auf.
Wählen Sie unter Suchplattform auswählen als Suchmodus Data Catalog aus.
Geben Sie in das Suchfeld den Namen eines Datensatzes mit einer Tabelle ein.
Wenn Sie beispielsweise die Kurzanleitung zum Tagging einer BigQuery-Tabelle mit dem Data Catalog abgeschlossen haben, können Sie nach
demo-datasetsuchen und die Tabelletripsauswählen.Klicken Sie auf die Tabelle.
Die Seite mit den Details zur BigQuery-Tabelle wird geöffnet.
Die Tabelle enthält die folgenden Abschnitte:
Details zur BigQuery-Tabelle Enthält Informationen wie die Erstellungszeit, die Zeit der letzten Änderung, die Ablaufzeit, Ressourcen-URLs und Labels.
Tags: Hier werden die angewendeten Tags aufgeführt.Sie können die Tags auf dieser Seite bearbeiten und die Tag-Vorlage aufrufen. Klicken Sie auf das Symbol Aktionen.
Schema- und Spalten-Tags Hier werden das angewendete Schema und seine Werte aufgeführt.
Lieblingseinträge mit einem Stern markieren und danach suchen
Wenn Sie häufig dieselben Daten-Assets aufrufen, können Sie ihre Einträge in eine personalisierte Liste aufnehmen, indem Sie sie mit Sternen markieren.
Rufen Sie in der Google Cloud Console die Seite Dataplex Search auf.
Wählen Sie unter Suchplattform auswählen als Suchmodus Data Catalog aus.
Suchen Sie das gewünschte Asset und markieren Sie es auf eine der folgenden beiden Arten:
- Klicken Sie in den Suchergebnissen neben dem Eintrag auf .
- Klicken Sie auf den Namen des Eintrags, um die Detailseite zu öffnen, und dann oben in der Aktionsleiste auf das Symbol STERN.
Sie können bis zu 200 Einträge mit einem Stern markieren.
Mit einem Stern markierte Einträge werden auf der Suchergebnisseite in der Liste Mit Stern markierte Einträge angezeigt, bevor Sie eine Suchanfrage in die Suchleiste eingeben. Diese Liste ist nur für Sie sichtbar.
Wenn Sie nur nach getaggten Einträgen suchen möchten, wählen Sie im Bereich Filter unter Umfang die Option Gemarkiert aus.
Sie können auch die entsprechenden Methoden der Data Catalog API verwenden, um Einträge mit einem Stern zu markieren oder die Markierung aufzuheben. Verwenden Sie bei der Suche nach Assets den Parameter starredOnly im Objekt scope. Weitere Informationen finden Sie unter catalog.search.