La derivazione dei dati è una funzionalità di Dataplex che consente di monitorare il modo in cui i dati vengono spostati nei sistemi: da dove provengono, dove vengono inviati e a quali trasformazioni sono sottoposti.
Perché hai bisogno della genealogia dei dati?
Gestire set di dati di grandi dimensioni spesso comporta la trasformazione dei dati in entità personalizzate in base alle esigenze di un progetto specifico: file di testo, tabelle, report, dashboard, modelli.
Ad esempio, immagina di avere un negozio online in cui registri ogni acquisto in una singola tabella SQL. Per semplificare il lavoro degli analisti con i dati, inizia a eseguire job che estraggono le informazioni da questa singola tabella e producono tabelle più piccole per regione, marca o prezzo di vendita. Gli analisti poi fanno lo stesso: eseguono ulteriori trasformazioni, unendo queste tabelle più piccole con altre origini dati per produrre ancora più tabelle.
Questo può rappresentare una grande sfida per gli stakeholder:
- I consumatori di dati non possono utilizzare uno strumento self-service per capire se i dati provengono da una fonte autorevole.
- I data engineer non riescono a individuare la causa principale dei problemi a causa della mancanza di un modo affidabile per monitorare tutte le trasformazioni dei dati.
- I data engineer e gli analisti non possono valutare completamente il possibile impatto prima di modificare o eliminare le tabelle.
- I responsabili dei dati non sono in grado di capire in che modo vengono utilizzati i dati sensibili all'interno dell'organizzazione e di garantire il rispetto dei requisiti normativi.
La tracciabilità dei dati è una soluzione che offre un modo pratico per svolgere le seguenti operazioni:
- Scopri come vengono recuperati e trasformati i dati con l'aiuto dei grafici di derivazione.
- Trace gli errori di traccia relativi alle voci e alle operazioni sui dati e individua le cause di fondo.
- Migliora la gestione delle modifiche tramite l'analisi dell'impatto: evita i tempi di riposo o gli errori imprevisti, comprendi le voci dipendenti e collabora con gli stakeholder pertinenti.
Modello di informazioni sulla derivazione dei dati
Nella sua forma di base, la derivazione è un record dei dati trasformati da origini a destinazioni. L'API Data Lineage raccoglie queste informazioni e le organizza in un modello dei dati gerarchico utilizzando i concetti di processi, esecuzioni ed eventi.
Processo
Un processo è la definizione di un'operazione di trasformazione dei dati supportata per un sistema specifico. Nel contesto della struttura di BigQuery,
process è uno dei tipi di job supportati.
Esegui
Per esecuzione si intende l'esecuzione di un processo. I processi possono avere più esecuzioni.
Le esecuzioni contengono dettagli come ora di inizio e di fine, stato o attributi aggiuntivi.
Per ulteriori informazioni, consulta il
riferimento alla risorsa run.
Evento
Un evento rappresenta un punto nel tempo in cui è stata eseguita un'operazione di trasformazione dei dati e ha comportato il trasferimento dei dati tra un'entità di origine e una di destinazione.
Gli eventi contengono un elenco di link che definiscono quale voce era la sorgente e quale era la destinazione in un determinato evento. Sebbene gli eventi vengano utilizzati per calcolare i grafici di eredità, non sono esposti direttamente nella console Google Cloud. Puoi crearli, leggerli ed eliminarli (ma non aggiornarli) utilizzando l'API Data Lineage.
Esempio
Considera il seguente esempio in cui i dati vengono copiati tra le tabelle BigQuery:
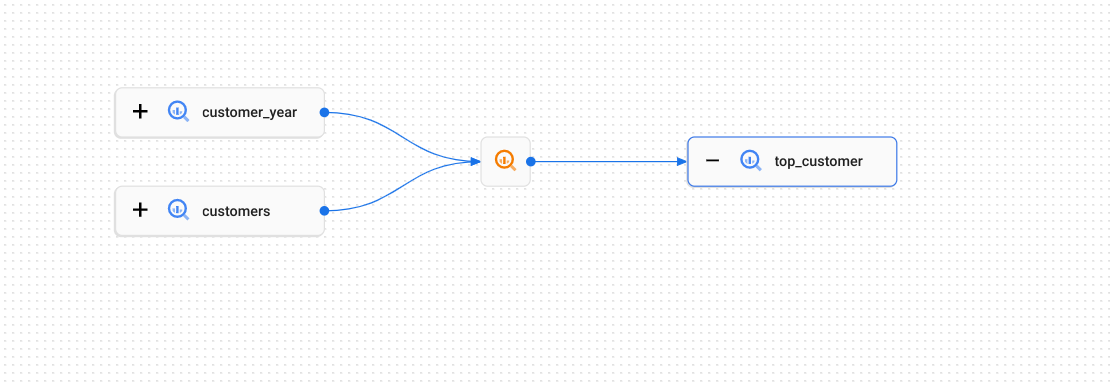
Il modo in cui i dati si spostano tra le tabelle è descritto dal processo di generazione (rappresentato nel grafico dall'icona ![]() ): può essere una query
): può essere una query CREATE TABLE AS SELECT SQL o un'istruzione INSERT.
Ogni esecuzione di questa istruzione SQL costituirà una singola esecuzione.
Le esecuzioni contengono eventi che registrano le tabelle utilizzate come origini e come destinazioni. In questo esempio, le tabelle customer_year e customers sono entrambe l'origine per la tabella di destinazione top_customer.
Grafo di derivazione
I grafici di derivazione rappresentano le informazioni raccolte dall'API Data Lineage per una determinata voce di Data Catalog. Un grafico di derivazione mostra la derivazione che si trova a monte o a valle di una singola voce principale. Radice si riferisce alla voce per la quale stai visualizzando la sequenza.
Dataplex funziona con l'API Data Lineage per identificare le voci il cui nome completamente qualificato corrisponde alle entità riconosciute dalla derivazione dei dati. Per le voci Dataplex corrispondenti, puoi accedere alla scheda Linage nella pagina dei dettagli e visualizzare il grafico.
I grafici della struttura mostrano due tipi di elementi:
Pulsanti rettangolari larghi che rappresentano le entità coinvolte nella costruzione delle informazioni sulla struttura come origini o destinazioni di un evento della struttura.
Pulsanti quadrati più piccoli che rappresentano le procedure responsabili della creazione o dell'aggiornamento delle entità di origine o di destinazione. I pulsanti di elaborazione utilizzano icone specifiche per il sistema di origine che li ha segnalati all'API Data Lineage. Ad esempio, i job BigQuery utilizzano l'icona
 .
.
Visualizzazione del percorso di derivazione
Le visualizzazioni del percorso di derivazione ti aiutano a comprendere i collegamenti di derivazione tra due risorse selezionate. (A differenza del grafico della struttura, che mostra la struttura a monte o a valle di una singola voce principale, potenzialmente per più origini o destinazioni).
Scegli la risorsa principale e una risorsa di destinazione e la console Google Cloud mostra i collegamenti di derivazione tra le due risorse. Altre risorse e procedure che non si trovano su un percorso tra le due risorse vengono nascoste nella visualizzazione del percorso.

Visualizzazione elenco della derivazione
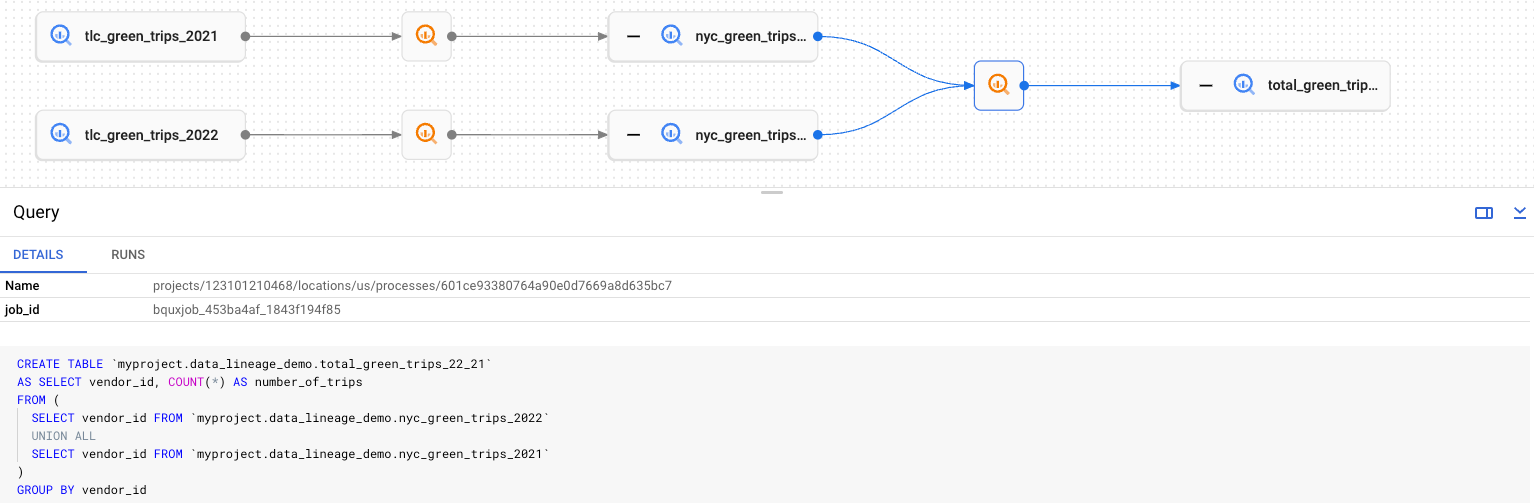
La visualizzazione elenco della struttura mostra informazioni dettagliate sulla struttura delle entità in una singola tabella.
Rispetto al grafico della struttura, che è più adatto per visualizzare grafici della struttura relativamente piccoli, la visualizzazione elenco della struttura consente di visualizzare le informazioni sulla struttura per le entità con molte connessioni.
L'immagine seguente mostra un esempio della visualizzazione elenco della cronologia nella console Google Cloud. L'elenco che segue descrive l'immagine in modo più dettagliato.

Ogni riga della tabella rappresenta un singolo collegamento della cronologia tra due voci. Nel grafico, questi nomi sono rappresentati come i collegamenti di derivazione tra due voci, inclusi eventuali nodi di processo intermedi. Ad esempio,
SourceeTargetsono nodi di asset, con eventualmente più nodi di processo intermedi.L'opzione Direzione specifica la parte del flusso di dati da visualizzare nell'elenco in relazione all'asset principale:
A monte: mostra le informazioni sulla derivazione per le voci che sono origini dati per la voce selezionata. Nel grafico della struttura, queste voci sono quelle visualizzate a sinistra della voce selezionata.
A valle: mostra le informazioni sulla struttura per le voci che utilizzano o derivano dalla voce selezionata. Nel grafico della struttura, queste voci sono quelle visualizzate a destra della voce selezionata.
L'opzione Intervallo di tempo ti consente di filtrare le informazioni sulla struttura in base all'ora in cui si è verificata:
Ora di inizio: mostra la derivazione avvenuta dopo l'ora di inizio.
Ora di fine: mostra la derivazione avvenuta prima dell'ora di fine.
La profondità indica la distanza dalla risorsa principale di una risorsa di origine o derivata. La visualizzazione elenco mostra fino a 1000 link di albero genealogico, con una profondità massima dalla risorsa principale pari a 10 link di albero genealogico. Se esiste un lignaggio al di fuori di questo intervallo, riceverai una notifica. Puoi visualizzare la linea di discendenza al di fuori di questo intervallo selezionando il nome di un'entità diversa nella visualizzazione elenco.
Il riquadro Dettagli mostra informazioni sull'origine del link, sul target del link e su tutte le procedure che hanno creato questo link.
Puoi personalizzare le colonne visualizzate nella tabella e filtrare i risultati. Puoi anche esportare i risultati in un file CSV.
Monitoraggio automatico della derivazione dei dati
Quando attivi l'API Data Lineage, Google Cloud i sistemi che supportano la derivazione dei dati iniziano a registrare il movimento dei dati. Ogni sistema integrato può inviare informazioni sulla provenienza per una gamma diversa di origini dati. Per ulteriori informazioni su ogni prodotto supportato, consulta le sezioni che seguono.
BigQuery
Se attivi la consistenza dei dati nel tuo progetto BigQuery, Dataplex registra automaticamente le informazioni sulla consistenza per:
Nuove tabelle come risultato dei seguenti job BigQuery:
- Job di copia
- Job di caricamento che utilizzano l'URI Cloud Storage per caricare i dati in qualsiasi formato consentito da Cloud Storage*
- Job di query che utilizzano il seguente linguaggio di definizione dei dati (DDL) in GoogleSQL:
Tabelle esistenti a seguito dell'utilizzo delle seguenti istruzioni DML (Data Manipulation Language) in GoogleSQL:
- SELECT in relazione a uno dei tipi di tabelle elencati:
- INSERT SELECT
- UNIONE
- AGGIORNAMENTO
- ELIMINA
I job di copia, query e caricamento di BigQuery sono rappresentati come processi. Per visualizzare i dettagli della procedura,
fai clic su
![]() nel grafico della struttura.
Ogni processo contiene job_id di BigQuery
nell'elenco
attributes
per il job BigQuery più recente.
nel grafico della struttura.
Ogni processo contiene job_id di BigQuery
nell'elenco
attributes
per il job BigQuery più recente.
Altri servizi
La definizione dell'origine dei dati supporta l'integrazione con i seguenti Google Cloud servizi:
Ricerca della cronologia dei dati per le origini dati personalizzate
Puoi utilizzare l'API Data Lineage in Dataplex per registrare manualmente le informazioni sulla derivazione per qualsiasi origine dati non supportata dai sistemi integrati.
Dataplex può creare grafici di derivazione per la registrazione manuale della derivazione se utilizzi un fullyQualifiedNames che corrisponda ai nomi completamente qualificati delle voci esistenti di Data Catalog. Se vuoi registrare la cronologia per un'origine dati personalizzata, crea prima una voce del Data Catalog personalizzata.
Ogni processo per l'origine dati personalizzata può contenere la chiave sql nell'elenco degli attributi. Il valore di questa chiave verrà utilizzato per evidenziare il codice nel riquadro dei dettagli del grafico della struttura dei dati. L'istruzione SQL verrà visualizzata come fornito. L'utente è responsabile del filtraggio delle informazioni sensibili. Il nome della chiave sql è sensibile alle maiuscole.
OpenLineage
Se utilizzi già OpenLineage per raccogliere informazioni sulla cronologia da altre origini dati, puoi importare gli eventi OpenLineage in Dataplex e visualizzarli nella console Google Cloud. Per maggiori dettagli, vedi Eseguire l'integrazione con OpenLineage.
Limitazioni
- Tutte le informazioni sulla cronologia vengono conservate nel sistema per solo 30 giorni.
- Le informazioni sulla cronologia rimangono invariate dopo la rimozione dell'origine dati correlata. In altre parole, se rimuovi una tabella BigQuery e la relativa voce di Data Catalog, puoi comunque leggere la relativa origine utilizzando l'API per un massimo di 30 giorni.
Accedere alla derivazione dei dati
Puoi accedere alle funzionalità di organizzazione dei dati utilizzando quanto segue:
- Pagina dei dettagli della voce nell'interfaccia web di Dataplex nella console Google Cloud. Consulta Visualizzare i grafici della struttura.
- Pagina dei dettagli della tabella nell'interfaccia web di BigQuery nella console Google Cloud. Consulta Visualizzare i grafici della struttura.
- Pagine Set di dati e Model Registry nell'interfaccia web di Vertex AI nella console Google Cloud. Consulta Visualizzare i grafici della struttura.
- API Data Lineage
Prezzi
Dataplex utilizza lo SKU di elaborazione premium per addebitare la derivazione dei dati. Per ulteriori informazioni, consulta la sezione Prezzi.
Per separare gli addebiti per la creazione della cronologia dei dati da altri addebiti nello SKU di elaborazione premium di Dataplex, nel report Fatturazione cloud, utilizza l'etichetta
goog-dataplex-workload-typecon il valoreLINEAGE.Se chiami l'API Data Lineage
OriginsourceTypecon un valore diverso daCUSTOM, si verificano costi aggiuntivi.
Passaggi successivi
Scopri come monitorare la consistenza dei dati per i processi di copia e query delle tabelle BigQuery.
Scopri come utilizzare la concatenazione dei dati con i Google Cloud sistemi.
Per informazioni amministrative, consulta le sezioni IAM aggiornate, le considerazioni sulla struttura e l'audit logging della struttura dei dati.