Die Datenherkunft ist eine Dataplex-Funktion, mit der Sie verfolgen können, wie sich Daten durch Ihre Systeme bewegen – woher sie kommen, wohin sie übergeben werden und welche Transformationen auf sie angewendet werden.
Warum benötigen Sie eine Datenabfolge?
Bei der Arbeit mit großen Datenmengen werden Daten häufig in Entitäten umgewandelt, die auf die Anforderungen eines bestimmten Projekts zugeschnitten sind: Textdateien, Tabellen, Berichte, Dashboards, Modelle.
Angenommen, Sie haben einen Onlineshop, in dem Sie jeden Kauf in einer einzigen SQL-Tabelle erfassen. Um Ihren Analysten die Arbeit mit den Daten zu erleichtern, führen Sie Jobs aus, mit denen Informationen aus dieser einzelnen Tabelle extrahiert und kleinere Tabellen nach Region, Marke oder Sonderangebotspreis erstellt werden. Ihre Analysten beginnen dann damit, weitere Transformationen durchzuführen und diese kleineren Tabellen mit anderen Datenquellen zusammenzuführen, um noch mehr Tabellen zu erstellen.
Das kann für Ihre Stakeholder eine große Herausforderung darstellen:
- Datenabnehmer können mit einem Self-Service-Tool nicht feststellen, ob Daten aus einer vertrauenswürdigen Quelle stammen.
- Dateningenieure können die Ursache von Problemen nicht ermitteln, da es keine zuverlässige Möglichkeit gibt, alle Datentransformationen zu verfolgen.
- Dateningenieure und ‑analysten können die möglichen Auswirkungen nicht vollständig beurteilen, bevor sie Tabellen ändern oder löschen.
- Datenverantwortliche können nicht nachvollziehen, wie sensible Daten in der gesamten Organisation verwendet werden, und die Einhaltung der gesetzlichen Bestimmungen nicht gewährleisten.
Die Datenabfolge ist eine Lösung, die Folgendes auf praktische Weise ermöglicht:
- Herkunft und Transformation von Daten mithilfe von Herkunftsabfolgen nachvollziehen
- Fehler im Zusammenhang mit Einträgen und Datenvorgängen auf die Grundursachen zurückführen.
- Bessere Änderungsverwaltung durch Auswirkungensanalyse: Vermeiden Sie Ausfallzeiten oder unerwartete Fehler, verstehen Sie abhängige Einträge und arbeiten Sie mit relevanten Stakeholdern zusammen.
Informationsmodell für die Datenherkunft
In seiner Grundform ist die Herkunftsableitung ein Datensatz, der aus Quellen in Ziele transformiert wird. Die Data Lineage API sammelt diese Informationen und organisiert sie mithilfe der Konzepte „Prozesse“, „Ausführungen“ und „Ereignisse“ in einem hierarchischen Datenmodell.
Prozess
Ein Prozess ist die Definition eines Datentransformationsvorgangs, der für ein bestimmtes System unterstützt wird. Im Zusammenhang mit der BigQuery-Abstammung ist process einer der unterstützten Jobtypen.
Ausführen
Eine Ausführung ist die Ausführung eines Prozesses. Prozesse können mehrere Ausführungen haben.
Ausführungen enthalten Details wie Start- und Endzeit, Status oder zusätzliche Attribute.
Weitere Informationen finden Sie in der Referenz zu run.
Ereignis
Ein Ereignis stellt einen Zeitpunkt dar, zu dem ein Datentransformationsvorgang stattgefunden hat und zu einer Datenübertragung zwischen einer Quell- und einer Zielentität geführt hat.
Ereignisse enthalten eine Liste von Links, die definieren, welcher Eintrag die Quelle und welcher das Ziel eines bestimmten Ereignisses war. Ereignisse werden zwar zum Berechnen von Abfolgen verwendet, sind aber nicht direkt in der Google Cloud Console verfügbar. Sie können sie mit der Data Lineage API erstellen, lesen und löschen, aber nicht aktualisieren.
Beispiel
Im folgenden Beispiel werden Daten zwischen BigQuery-Tabellen kopiert:
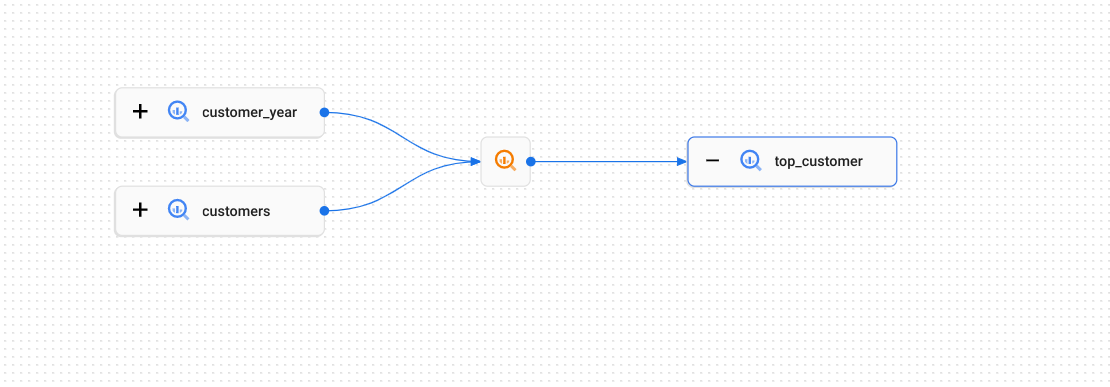
Wie Daten zwischen den Tabellen übertragen werden, wird durch den Abstammungsvorgang beschrieben (im Diagramm durch das Symbol ![]() dargestellt). Dies kann eine SQL-
dargestellt). Dies kann eine SQL-CREATE TABLE AS SELECT-Abfrage oder eine INSERT-Anweisung sein.
Jede Ausführung dieser SQL-Anweisung stellt einen einzelnen Durchlauf dar.
Ausführungen enthalten Ereignisse, in denen aufgezeichnet wird, welche Tabellen als Quellen und welche als Ziele verwendet wurden. In diesem Beispiel sind die Tabellen customer_year und customers die Quellen für die Zieltabelle top_customer.
Stammbaumdiagramm
In Stammbaumdiagrammen werden Informationen dargestellt, die von der Data Lineage API für einen bestimmten Data Catalog-Eintrag erfasst wurden. Ein Stammbaumdiagramm zeigt die Abfolge, die vor oder nach einem einzelnen Stammeintrag liegt. Stamm bezieht sich auf den Eintrag, für den Sie die Stammbaumstruktur aufrufen.
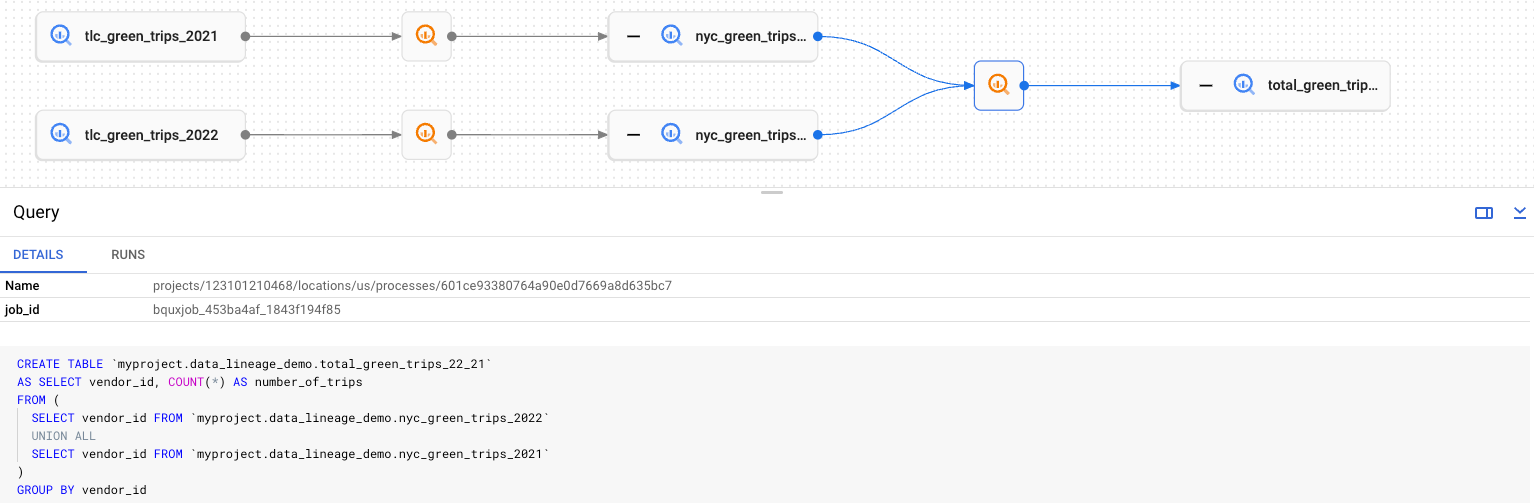
Dataplex verwendet die Data Lineage API, um Einträge zu identifizieren, deren vollständig qualifizierter Name mit Entitäten übereinstimmt, die von der Datenherkunft erkannt werden. Bei abgeglichenen Dataplex-Einträgen können Sie auf der Detailseite auf den Tab Abstammung zugreifen und sich das Diagramm ansehen.
In Stammbaumdiagrammen werden zwei Arten von Elementen dargestellt:
Breite, rechteckige Schaltflächen, die Entitäten darstellen, die beim Erstellen von Stammbauminformationen als Quellen oder Ziele eines Stammbaumereignisses beteiligt sind.
Kleinere quadratische Schaltflächen, die Prozesse darstellen, die für das Erstellen oder Aktualisieren der Quell- oder Zielentitäten verantwortlich sind. Die Prozessschaltflächen verwenden Symbole, die für das Quellsystem spezifisch sind, das sie an die Data Lineage API gesendet hat. Für BigQuery-Jobs wird beispielsweise das Symbol
 verwendet.
verwendet.
Visualisierung des Herkunftspfads
Mithilfe von Visualisierungen des Herkunftspfads können Sie die Herkunftsverbindungen zwischen zwei ausgewählten Ressourcen nachvollziehen. Im Gegensatz dazu zeigt das Herkunftsdiagramm die Herkunft, die sich vor oder nach einem einzelnen Stammeintrag befindet, möglicherweise für mehrere Quellen oder Ziele.
Sie wählen die Stammressource und eine Zielressource aus. In der Google Cloud Console werden dann die Herkunftsverbindungen zwischen den beiden Ressourcen angezeigt. Andere Ressourcen und Prozesse, die sich nicht auf einem Pfad zwischen den beiden Ressourcen befinden, werden in der Pfadvisualisierung ausgeblendet.

Listenansicht für Lineage
In der Listenansicht der Herkunft werden detaillierte Informationen zur Herkunft von Entitäten in einer einzelnen Tabelle angezeigt.
Im Vergleich zum Herkunftsdiagramm, das sich besser für relativ kleine Herkunftsdiagramme eignet, können Sie in der Herkunftslistenansicht Herkunftsinformationen für Entitäten mit vielen Verbindungen aufrufen.
Die folgende Abbildung zeigt ein Beispiel für die Listenansicht der Abfolge in der Google Cloud Console. In der folgenden Liste wird das Bild genauer beschrieben.
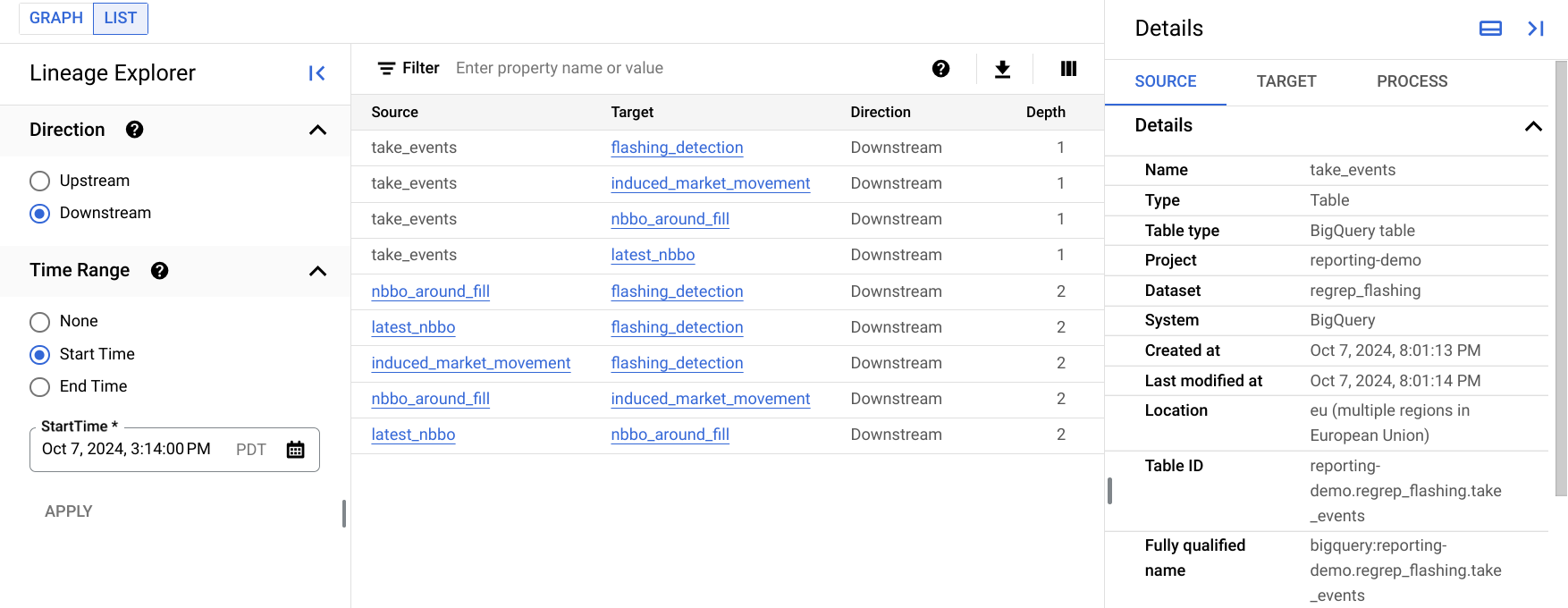
Jede Zeile in der Tabelle stellt einen einzelnen Abstammungslink zwischen zwei Einträgen dar. Im Diagramm werden diese Namen als Abfolgelinks zwischen zwei Einträgen dargestellt, einschließlich aller dazwischen liegenden Prozessknoten. Beispielsweise sind
SourceundTargetAsset-Knoten, zwischen denen sich möglicherweise mehrere Prozessknoten befinden.Mit der Option Richtung wird der Teil des Datenflusses angegeben, der in der Liste in Bezug auf das Stamm-Asset angezeigt werden soll:
Upstream: Hier werden Informationen zur Herkunft für Einträge angezeigt, die Datenquellen für den ausgewählten Eintrag sind. Im Stammbaumdiagramm sind dies die Einträge, die links vom ausgewählten Eintrag angezeigt werden.
Downstream: Hier werden Informationen zur Herkunft für Einträge angezeigt, die den ausgewählten Eintrag verwenden oder davon abgeleitet sind. Im Stammbaumdiagramm sind dies die Einträge, die rechts neben dem ausgewählten Eintrag angezeigt werden.
Mit der Option Zeitraum können Sie Informationen zur Zugehörigkeit nach dem Zeitpunkt filtern, zu dem sie aufgetreten ist:
Beginn: Hier sehen Sie die Lineage nach dem Beginn.
Endzeit: Hier sehen Sie die Lineage bis zu diesem Zeitpunkt.
Die Tiefe gibt an, wie weit eine Quell- oder abgeleitete Ressource von der Stammressource entfernt ist. In der Listenansicht werden bis zu 1.000 Abstammungslinks angezeigt, wobei die maximale Tiefe von der Stammressource 10 Abstammungslinks beträgt. Wenn es Abstammungen außerhalb dieses Bereichs gibt, werden Sie benachrichtigt. Sie können sich die Abfolge außerhalb dieses Bereichs ansehen, indem Sie in der Listenansicht den Namen einer anderen Entität auswählen.
Im Bereich Details finden Sie Informationen zur Quelle und zum Ziel des Links sowie zu allen Prozessen, die diesen Link erstellt haben.
Sie können die in der Tabelle angezeigten Spalten anpassen und die Ergebnisse filtern. Sie können die Ergebnisse auch in eine CSV-Datei exportieren.
Automatisiertes Tracking der Datenherkunft
Wenn Sie die Data Lineage API aktivieren, melden Systeme, die die Datenherkunft unterstützen, ihre Datenübertragungen. Google Cloud Jedes integrierte System kann Informationen zur Herkunft für einen anderen Datenquellenbereich einreichen. Weitere Informationen zu den einzelnen unterstützten Produkten finden Sie in den folgenden Abschnitten.
BigQuery
Wenn Sie die Herkunft der Daten in Ihrem BigQuery-Projekt aktivieren, zeichnet Dataplex automatisch die Herkunftsinformationen für Folgendes auf:
Neue Tabellen aus den folgenden BigQuery-Jobs:
- Kopierjobs
- Ladejobs, bei denen der Cloud Storage-URI verwendet wird, um Daten in einem beliebigen zulässigen Format aus Cloud Storage zu laden*
- Abfragejobs, die die folgende DDL-Anweisung (Data Definition Language) in GoogleSQL verwenden:
Vorhandene Tabellen, die durch die Verwendung der folgenden DML-Anweisungen (Data Manipulation Language) in GoogleSQL entstanden sind:
- SELECT im Zusammenhang mit einem der aufgeführten Tabellentypen:
- INSERT SELECT
- MERGE
- AKTUALISIEREN
- LÖSCHEN
BigQuery-Kopier-, Abfrage- und Ladejobs werden als Prozesse dargestellt. Klicken Sie im Herkunftsdiagramm auf ![]() , um die Prozessdetails aufzurufen.
Jeder Prozess enthält die BigQuery-job_id in der Liste attributes für den letzten BigQuery-Job.
, um die Prozessdetails aufzurufen.
Jeder Prozess enthält die BigQuery-job_id in der Liste attributes für den letzten BigQuery-Job.
Weitere Dienste
Die Datenabfolge unterstützt die Einbindung in die folgendenGoogle Cloud Dienste:
Datenabfolge für benutzerdefinierte Datenquellen
Mit der Data Lineage API in Dataplex können Sie Herkunftsinformationen für jede Datenquelle manuell erfassen, die von den integrierten Systemen nicht unterstützt wird.
In Dataplex können Stammbaumdiagramme für manuell aufgezeichnete Abfolgen erstellt werden, wenn Sie eine fullyQualifiedNames verwenden, die mit den vollständig qualifizierten Namen vorhandener Data Catalog-Einträge übereinstimmt. Wenn Sie die Herkunftsabfolge für eine benutzerdefinierte Datenquelle aufzeichnen möchten, erstellen Sie zuerst einen benutzerdefinierten Data Catalog-Eintrag.
Jeder Prozess für eine benutzerdefinierte Datenquelle kann den Schlüssel sql in der Attributliste enthalten. Der Wert dieses Schlüssels wird verwendet, um den Code-Highlight im Detailbereich des Datenabstammungsdiagramms zu rendern. Die SQL-Anweisung wird genau so angezeigt, wie sie angegeben wurde. Der Nutzer ist dafür verantwortlich, vertrauliche Informationen herauszufiltern. Bei dem Schlüsselnamen sql wird zwischen Groß- und Kleinschreibung unterschieden.
OpenLineage
Wenn Sie bereits OpenLineage verwenden, um Informationen zur Herkunft aus anderen Datenquellen zu erfassen, können Sie OpenLineage-Ereignisse in Dataplex importieren und diese Ereignisse in der Google Cloud Console anzeigen. Weitere Informationen finden Sie unter OpenLineage einbinden.
Beschränkungen
- Alle Informationen zur Herkunft werden nur 30 Tage lang im System aufbewahrt.
- Informationen zur Herkunft bleiben erhalten, nachdem Sie die zugehörige Datenquelle entfernt haben. Wenn Sie also eine BigQuery-Tabelle und den zugehörigen Data Catalog-Eintrag entfernen, können Sie die Herkunftsinformationen für diese Tabelle noch bis zu 30 Tage lang über die API lesen.
Auf Datenherkunft zugreifen
Sie können auf die Funktionen zur Datenherkunft über Folgendes zugreifen:
- Seite mit den Details zum Eintrag in der Dataplex-Weboberfläche in der Google Cloud Console Weitere Informationen finden Sie unter Herkunftsdiagramme ansehen.
- Seite mit Tabellendetails in der BigQuery-Weboberfläche in der Google Cloud Console Weitere Informationen finden Sie unter Herkunftsdiagramme ansehen.
- Seiten „Dataset“ und „Model Registry“ in der Vertex AI-Weboberfläche in der Google Cloud Console Weitere Informationen finden Sie unter Herkunftsdiagramme ansehen.
- Data Lineage API
Preise
Bei Dataplex wird die SKU für die Premium-Verarbeitung verwendet, um die Datenherkunft in Rechnung zu stellen. Weitere Informationen finden Sie unter Preise.
Wenn Sie die Kosten für die Datenableitung von anderen Kosten in der Dataplex Premium-Verarbeitungs-SKU trennen möchten, verwenden Sie im Cloud Billing-Bericht das Label
goog-dataplex-workload-typemit dem WertLINEAGE.Wenn Sie die Data Lineage API
OriginsourceTypemit einem anderen Wert alsCUSTOMaufrufen, fallen zusätzliche Kosten an.
Nächste Schritte
Weitere Informationen zur Verwendung der Datenherkunft mit Google Cloud -Systemen
Informationen zur Verwaltung finden Sie in den aktualisierten IAM-Abschnitten, in den Hinweisen zur Datenableitung und im Hilfeartikel Audit-Logging für die Datenableitung.