Cortex para Meridian
En esta página se detalla el proceso de preparación de datos y automatización en la nube de Google Meridian. Cortex Framework para Meridian simplifica la modelización del mix de marketing (MMM) de código abierto con datos de ventas y multicanal. Cortex Framework simplifica este proceso proporcionando modelos de datos preconfigurados y automatizando la ejecución del modelo de código abierto de Meridian mediante Google Cloud servicios como Colab Enterprise y Workflows.
Una de las principales propuestas de valor de Google Cloud Cortex Framework es proporcionar una base de datos e inteligencia artificial (IA) para la inteligencia empresarial de próxima generación que permita realizar análisis en áreas clave como ventas, marketing, gestión de pedidos y gestión de inventario.
Cortex Framework para marketing proporciona indicadores clave de rendimiento (KPIs) y métricas de plataformas multicanal. Estas métricas son una parte importante del paso de preparación de los datos previos a la modelización para ejecutar el MMM de código abierto más reciente de Google, llamado Meridian. Los anunciantes, las agencias y los partners pueden acelerar el proceso de preparación de datos previo a la modelización aprovechando los cimientos de datos de Google Cloud Cortex Framework.
Cortex para Meridian simplifica el proceso previo a la modelización recogiendo y transformando de forma eficiente los datos de las fuentes de datos principales de Cortex Framework, entre las que se incluyen las siguientes:
Para obtener más información, consulta la documentación de Meridian.
Archivo de configuración
Durante la ejecución del cuaderno, el sistema recupera los parámetros de configuración del archivo cortex_meridian_config.json, que se encuentra en la carpeta configuration
de Cloud Storage.
En la siguiente sección se muestran ejemplos de diferentes archivos YAML de configuración para la ejecución de Meridian:
Ventas
Ejemplo de archivo YAML de configuración de ventas como KPIs:
{
"cortex_bq_project_id": "PROJECT_ID",
"cortex_meridian_marketing_data_set_id": "K9_REPORTING",
"cortex_meridian_marketing_view_name": "CrossMediaSalesInsightsWeeklyAgg",
"column_mappings": {
"controls": [],
"geo": "geo",
"kpi": "number_of_sales_orders",
"media": [
"Tiktok_impression",
"Meta_impression",
"YouTube_impression",
"GoogleAds_impression"
],
"media_spend": [
"Tiktok_spend",
"Meta_spend",
"YouTube_spend",
"GoogleAds_spend"
],
"population": "population",
"revenue_per_kpi": "average_revenue_per_sales_order",
"time": "time"
},
"channel_names": [
"TikTok",
"Meta",
"YouTube",
"GoogleAds"
],
"data_processing": {
"kpi_type": "{USE_CASE_SPECIFIC}",
"roi_mu": {USE_CASE_SPECIFIC},
"roi_sigma": {USE_CASE_SPECIFIC},
"sample": {
"prior": {USE_CASE_SPECIFIC},
"posterior": {
"n_chains": {USE_CASE_SPECIFIC},
"n_adapt": {USE_CASE_SPECIFIC},
"n_burnin": {USE_CASE_SPECIFIC},
"n_keep": {USE_CASE_SPECIFIC}
}
}
}
}
Conversiones
Ejemplos de archivos YAML de configuración para las conversiones como KPIs:
...
"kpi": "conversions",
"revenue_per_kpi": "",
...
En la siguiente tabla se describe el valor de cada parámetro de configuración del archivo cortex_meridian_config.json:
| Parámetro | Significado | Valor predeterminado | Descripción |
cortex_bq_project_id
|
Proyecto con los conjuntos de datos de Cortex Framework. | {PROJECT_ID}
|
El Google Cloud ID del proyecto. |
cortex_meridian_marketing_data_set_id
|
Conjunto de datos de BigQuery con Cortex para la vista Meridian. | El valor de configuración de k9.datasets.reporting en el archivo config.json.
|
El conjunto de datos que contiene la vista cortex_meridian_marketing_view_name.
|
cortex_meridian_marketing_view_name
|
Vista de BigQuery con Cortex para datos de marketing y ventas de Meridian. | "CrossMediaSalesInsightsWeeklyAgg"
|
Vista que contiene datos de marketing y ventas agregados semanalmente. |
column_mappings.controls
|
Opcional: Puede contener los factores de confusión que tengan un efecto causal tanto en la métrica de rendimiento objetivo como en la métrica de medios. | []
|
Para obtener información sobre el modelado de datos de Meridian en variables de control, consulta Variables de control. |
column_mappings.geo
|
Las columnas que proporcionan información geográfica. | "geo"
|
Para obtener información detallada sobre la modelización de datos de Meridian, consulta el artículo Recoger y organizar datos. |
column_mappings.kpi
|
La métrica objetivo del modelo. | "number_of_sales_orders" o "conversions" .
|
Para obtener información detallada sobre la modelización de datos de Meridian, consulta el artículo Recoger y organizar datos. |
column_mappings.media
|
Matriz de columnas que proporciona las impresiones del canal. | [
"Tiktok_impression",
|
Para obtener información detallada sobre la modelización de datos de Meridian, consulta el artículo Recoger y organizar datos. |
column_mappings.media_spend
|
Columnas que proporcionan el gasto del canal. | [
"Tiktok_spend",
|
Para obtener información detallada sobre la modelización de datos de Meridian, consulta el artículo Recoger y organizar datos. |
column_mappings.population
|
La población de cada zona geográfica. | "population"
|
Para obtener información detallada sobre la modelización de datos de Meridian, consulta el artículo Recoger y organizar datos. |
column_mappings.revenue_per_kpi
|
Los ingresos medios de una unidad de KPI. | "average_revenue_per_sales_order" o ""
|
Para obtener información detallada sobre la modelización de datos de Meridian, consulta el artículo Recoger y organizar datos. |
column_mappings.time
|
La columna de hora: inicio de la semana (lunes). | "time"
|
Para obtener información detallada sobre la modelización de datos de Meridian, consulta el artículo Recoger y organizar datos. |
channel_names
|
Array de nombres de canales. | [
"TikTok",
|
Los nombres que se usen para el canal y el índice deben coincidir con column_mappings.media
y column_mappings.media_spend.
|
data_processing.kpi_type
|
El KPI puede ser ingresos u otro KPI que no sea de ingresos. También se puede usar un tipo de KPI que no sea de ingresos aunque, en última instancia, los ingresos sean el KPI. | "{USE_CASE_SPECIFIC}"
|
Para obtener información sobre los detalles del modelado de datos de Meridian para los KPIs, consulta KPI. |
data_processing.roi_mu
|
Distribución previa del retorno de la inversión de cada canal publicitario. roi_mu
(se usa con ROI_M en el cuaderno).
|
{USE_CASE_SPECIFIC}
|
Para obtener información detallada sobre el procesamiento de datos de Meridian, lea y comprenda los siguientes artículos: Configurar el modelo y Referencia de la API. |
data_processing.roi_sigma
|
Distribución previa del retorno de la inversión de cada canal publicitario roi_sigma
(se usa con ROI_M en el cuaderno).
|
{USE_CASE_SPECIFIC}
|
Para obtener información detallada sobre el procesamiento de datos de Meridian, lea y comprenda los artículos Configurar el modelo y Referencia de la API. |
data_processing.sample.prior
|
Número de muestras extraídas de la distribución anterior. | {USE_CASE_SPECIFIC}
|
Para obtener información detallada sobre el tratamiento de datos de Meridian, asegúrese de leer y comprender los artículos Parametrizaciones previas predeterminadas y Referencia de la API. |
data_processing.sample.posterior.n_chains
|
Número de cadenas de MCMC. | {USE_CASE_SPECIFIC}
|
Para obtener información detallada sobre el tratamiento de datos de Meridian, lea y comprenda los artículos Configurar el modelo y Referencia de la API. |
data_processing.sample.posterior.n_adapt
|
Número de dibujos de adaptación por cadena. | {USE_CASE_SPECIFIC}
|
Para obtener información detallada sobre el procesamiento de datos de Meridian, lea y comprenda los artículos Configurar el modelo y Referencia de la API. |
data_processing.sample.posterior.n_burnin
|
Número de dibujos de quemado por cadena. | {USE_CASE_SPECIFIC}
|
Para obtener información detallada sobre el procesamiento de datos de Meridian, lea y comprenda los artículos Configurar el modelo y Referencia de la API. |
data_processing.sample.posterior.n_keep
|
Número de sorteos por cadena que se conservarán para la inferencia. | {USE_CASE_SPECIFIC}
|
Para obtener información detallada sobre el procesamiento de datos de Meridian, lea y comprenda los artículos Configurar el modelo y Referencia de la API. |
Compatibilidad con Meridian
Cortex Framework Data Foundation y Meridian se lanzan por separado. Las notas de la versión de Cortex Framework ofrecen una descripción general de sus lanzamientos y versiones. En el repositorio de GitHub de Meridian, puedes ver las últimas versiones disponibles de Meridian. Los requisitos previos y las recomendaciones del sistema de Meridian están disponibles en la guía del usuario de Meridian.
Las versiones de Cortex Framework Data Foundation se prueban con una versión específica de Meridian. Puedes encontrar el Meridian compatible en el cuaderno de Jupyter, tal como se muestra en la siguiente imagen:

Para actualizar a una versión más reciente de Meridian, modifica la línea correspondiente en el cuaderno. Ten en cuenta que puede que tengas que hacer ajustes adicionales en el código del cuaderno.
Modelo de datos
En esta sección se describe el modelo de datos de CrossMediaSalesInsightsWeeklyAgg mediante el diagrama de relaciones entre entidades (DRE).
Cortex para Meridian se basa en una sola vista, CrossMediaSalesInsightsWeeklyAgg,
para funcionar. La fuente de datos de esta vista se determina mediante el ajuste de configuración k9.Meridian.salesDataSourceType, que puede ser:
BYOD(Incorpora tus propios datos): integración de datos personalizados.SAP_SALES: datos de ventas de sistemas SAP.ORACLE_SALES: datos de ventas de sistemas Oracle EBS.
En la siguiente sección se muestran los diagramas de relaciones entre entidades de CrossMediaForMeridian:
BYOD

CortexForMeridian sin datos de ventas.SAP

CortexForMeridian con datos de SAP.OracleEBS

CortexForMeridian con datos de Oracle EBS.En la siguiente tabla se muestra el esquema detallado de la vista CrossMediaSalesInsightsWeeklyAgg, que forma parte de Cortex para Meridian:
| Columna | Tipo | Descripción |
| geo | Cadena | El área geográfica que se usa para agregar todos los demás valores. |
| Tiempo | Cadena | Dimensión temporal que se usa para agregar todos los demás valores. |
| Tiktok_impression | Entero | Número de veces que se han mostrado tus anuncios en TikTok. |
| Meta_impression | Entero | Número de veces que se han mostrado tus anuncios en Meta. |
| YouTube_impression | Entero | Número de veces que se han mostrado sus anuncios en YouTube. |
| GoogleAds_impression | Entero | Número de veces que se han mostrado sus anuncios en Google Ads. |
| Tiktok_spend | Flotante | La cantidad de dinero que se ha gastado en publicidad en TikTok. |
| Meta_spend | Flotante | El importe que se ha gastado en publicidad en Meta. |
| YouTube_spend | Flotante | El importe que se ha gastado en publicidad en YouTube. |
| GoogleAds_spend | Flotante | El importe que se ha gastado en publicidad en Google Ads. |
| target_currency | Cadena | Moneda objetivo que se usa en todas las columnas de ingresos. |
| en las conversiones | Entero | Conversiones. |
| number_of_sales_orders | Entero | Número de pedidos de venta de Oracle EBS o SAP. |
| average_revenue_per_sales_order | Flotante | Ingresos medios por pedido de ventas de Oracle EBS o SAP. |
| población | Entero | Tamaño de la población de la zona geográfica. |
Implementación
En esta página se describen los pasos para implementar Cortex Framework en Meridian, lo que te permitirá disfrutar de la mejor MMM de su categoría en tu entorno Google Cloud .
Para ver una demo de inicio rápido, consulta Demo de inicio rápido de Meridian.
Arquitectura
Cortex para Meridian usa Cortex Framework para marketing y datos multicanal combinados con datos de ventas. Puede importar datos de ventas de Oracle EBS, SAP u otro sistema de origen.
En el siguiente diagrama se describen los componentes clave de Cortex para Meridian:
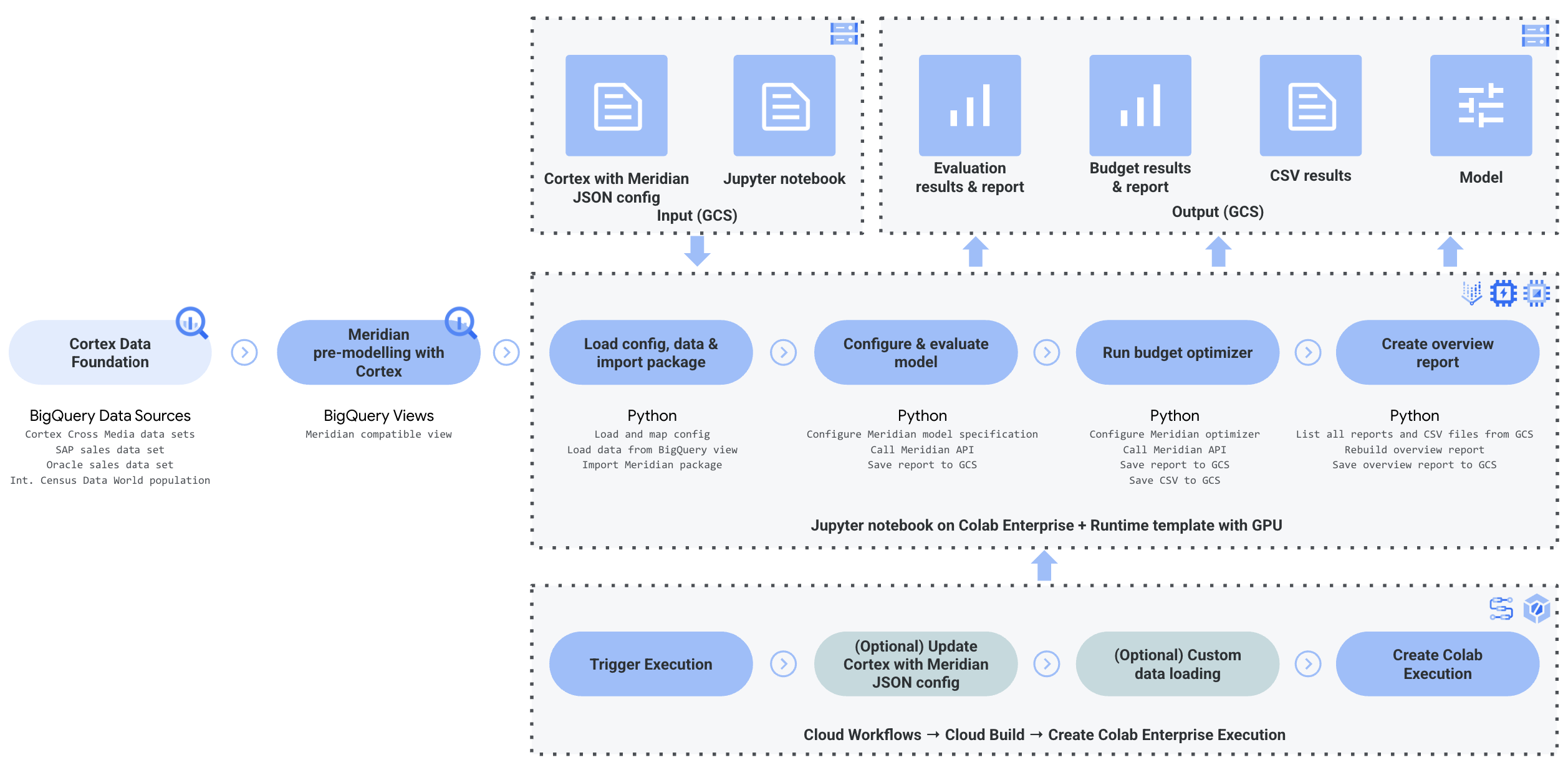
Componentes y servicios de Meridian
Durante la implementación de Cortex Framework Data Foundation (consulta los requisitos previos de implementación), puedes habilitar Cortex para Meridian asignando el valor true a deployMeridian en el archivo config.json. Esta opción inicia una canalización adicional de Cloud Build, que instala los siguientes componentes y servicios necesarios para Meridian:
Vista de BigQuery: se crea una vista en el conjunto de datos de informes de K9 llamado
CrossMediaSalesInsightsWeeklyAgg. De esta forma, se pueden consultar datos de marketing y ventas de Cortex Framework. La implementación real de la vista y las fuentes subyacentes dependen de la fuente de datos de ventas que selecciones durante la implementación.Segmento de Cloud Storage: el
PROJECT_ID-cortex-meridiansegmento contiene todos los artefactos que necesita y produce Cortex para Meridian en las siguientes carpetas:configuration: define los ajustes y los parámetros de Cortex para Meridian. Lo usa el cuaderno de Colab Enterprise durante la ejecución del cuaderno.csv: los datos sin procesar que se obtienen al ejecutar Meridian se guardarán en archivos CSV.models: el modelo generado al ejecutar Meridian se guardará aquí.notebook-run-logs: aquí se guardarán copias de los cuadernos de cada ejecución y los registros.notebooks: contiene el cuaderno principal con el código y la lógica para ejecutar Cortex para Meridian. Este cuaderno se ha diseñado para que puedas personalizarlo aún más y adaptarlo a tus necesidades y requisitos específicos.reporting: Esta es la carpeta en la que se guardarán los informes de las ejecuciones de Meridian. También contiene una plantilla HTML para generar un informe de resumen con enlaces a la salida del informe de Meridian.
Colab Enterprise: Colab Enterprise es un servicio gestionado en Google Cloud que proporciona un entorno seguro y colaborativo para los flujos de trabajo de ciencia de datos y aprendizaje automático con cuadernos de Jupyter. Ofrece funciones como infraestructura gestionada, controles de seguridad de nivel empresarial e integración con otros Google Cloud servicios, lo que la hace adecuada para equipos que trabajan con datos sensibles y requieren un gobierno sólido. Un entorno gestionado para ejecutar el cuaderno de Jupyter.
Cortex para Meridian usa Colab Enterprise para definir una plantilla de tiempo de ejecución con la infraestructura necesaria para automatizar las ejecuciones de Meridian.
Cuando se activa el flujo de trabajo completo, se crea una ejecución. De esta forma, se ejecutará una copia del cuaderno de Jupyter actual desde Cloud Storage con la configuración más reciente.
Flujo de trabajo: un flujo de trabajo de Cloud llamado
cortex-meridian-execute-notebookorquesta la ejecución de todo el flujo de procesamiento de Cortex para Meridian. El flujo de trabajo llamará a la API de Colab Enterprise, que crea un tiempo de ejecución basado en la plantilla de tiempo de ejecución y ejecuta un cuaderno con las configuraciones actuales. Por último, guarda todos los resultados en Cloud Storage.
Imagen 8. Flujos de trabajo de Meridian. Tienes dos opciones de configuración opcionales para el flujo de trabajo:
- Si puedes proporcionar una nueva configuración JSON de Cortex para Meridian como entrada al flujo de trabajo. Si lo haces, el flujo creará una copia de seguridad de la configuración antigua y la actualizará con los datos que hayas introducido. Consulta REPLACE para obtener más información.
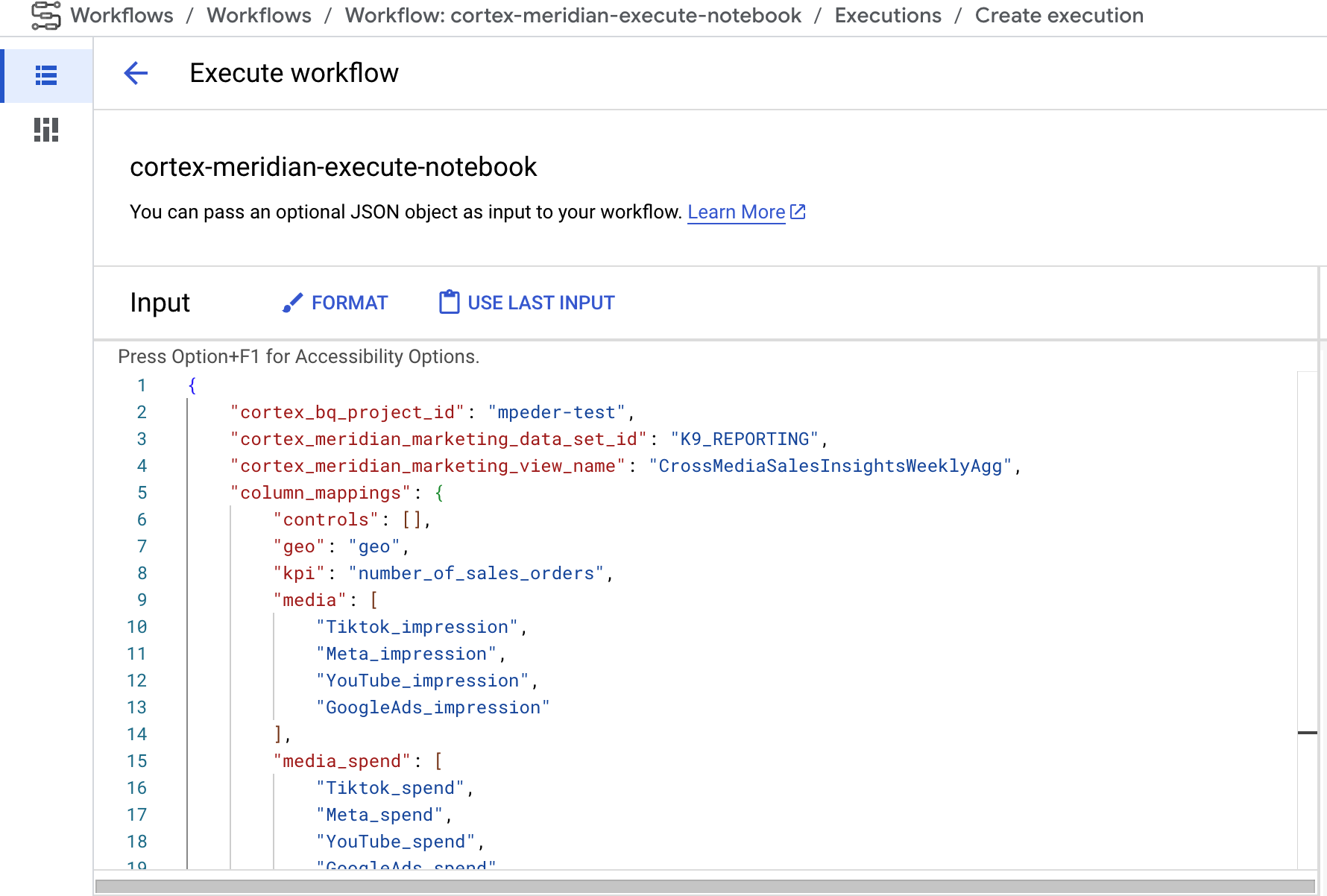
Imagen 9. Ejemplo de modificación y ejecución de un nuevo JSON de entrada. - El paso
pre_notebook_executiones un buen momento para iniciar cualquier tarea adicional que necesites automatizar antes de ejecutar el cuaderno. Por ejemplo, cargar datos de fuentes externas a Google Cloud Cortex Framework.
Cuenta de servicio: se debe proporcionar una cuenta de servicio específica durante la implementación. Es necesario para ejecutar el flujo de trabajo y el cuaderno en Colab Enterprise.
Parámetros de implementación adicionales de Meridian
El archivo config.json configura los ajustes necesarios para ejecutar Meridian con Cortex Framework. Este archivo contiene los siguientes parámetros de Cortex para Meridian:
"k9": {
...
"deployMeridian": false,
...
"Meridian":{
"salesDataSourceType": "",
"salesDatasetID":"",
"deploymentType": "",
"defaultNotebookFile":"meridian_cortex_marketing.ipynb",
"defaultConfigFile":"cortex_meridian_config.json",
"gcsBucketNameSuffix": "cortex-meridian",
"workflow": {
"template": "create_notebook_execution_run.yaml",
"name": "cortex-meridian-execute-notebook",
"region": "us-central1"
},
"runnerServiceAccount": "cortex-meridian-colab-runner",
"colabEnterprise": {
"region": "us-central1",
"runtimeTemplateName": "cortex-meridian-template",
"runtimeMachine_type": "n1-highmem-32",
"runtimeAcceleratorCoreCount": 1,
"runtimeAcceleratorType": "NVIDIA_TESLA_T4",
"executionName": "cortex-meridian-execution",
"notebookRunLogsFolder": "notebook-run-logs"
}
}
}
En la siguiente tabla se describen el valor y la descripción de cada parámetro de Meridian:
| Parámetro | Significado | Valor predeterminado | Descripción |
k9.deployMeridian
|
Implementar Meridian o no. | false
|
Elige si se debe implementar Cortex para Meridian como parte de una implementación de Data Foundation. |
k9.Meridian.salesDataSourceType
|
La fuente de los datos de ventas. | - | Elige entre BYOD, SAP o OracleEBS.
|
k9.Meridian.salesDatasetID
|
El ID de su conjunto de datos de ventas. | - | El ID de su conjunto de datos de ventas. Varía en función de la configuración relacionada de Cortex Data Foundation. |
k9.Meridian.deploymentType
|
Define si la implementación es completa o incremental. | - | Elige entre initial y incremental.
|
k9.Meridian.defaultNotebookFile
|
Archivo de cuaderno de Jupyter. | meridian_cortex_marketing.ipynb
|
Nombre del archivo de cuaderno situado en la carpeta notebooks de Cloud Storage.
|
k9.Meridian.defaultConfigFile
|
El archivo de configuración para ejecutar el cuaderno. | cortex_meridian_config.json
|
Contiene Cortex para la configuración de Meridian que se usa al ejecutar el cuaderno.
Debe estar en la carpeta configuration de Cloud Storage.
|
k9.Meridian.gcsBucketNameSuffix
|
Sufijo del segmento de Cloud Storage de Cortex para Meridian. | cortex-meridian
|
El nombre completo del segmento será {PROJECT_ID}-cortex-meridian de forma predeterminada. |
k9.Meridian.workflow.template
|
Plantilla del flujo de trabajo. | create_notebook_execution_run.yaml
|
Plantilla para crear el flujo de trabajo. El flujo de trabajo se usa para iniciar la ejecución de un cuaderno. |
k9.Meridian.workflow.name
|
Nombre del flujo de trabajo. | cortex-meridian-execute-notebook
|
El nombre que se muestra en el portal de Google Cloud del flujo de trabajo. |
k9.Meridian.workflow.region
|
La región de implementación del flujo de trabajo. | us-central1
|
La región de implementación del flujo de trabajo. Normalmente, se elige la misma que el resto de la implementación. |
k9.Meridian.runnerServiceAccount
|
El nombre de la cuenta de servicio de Cortex para Meridian. | cortex-meridian-colab-runner
|
Nombre de la cuenta de servicio utilizada para ejecutar el flujo de trabajo y las ejecuciones de Colab Enterprise. |
k9.Meridian.colabEnterprise.region
|
Región de implementación de las ejecuciones de Colab Enterprise. | us-central1
|
Región de implementación de las ejecuciones de Colab Enterprise. Normalmente, se elige la misma que el resto de la implementación. |
k9.Meridian.colabEnterprise.runtimeTemplateName
|
Nombre de la plantilla de tiempo de ejecución de Colab Enterprise. | cortex-meridian-template
|
Nombre de la plantilla de tiempo de ejecución de Colab Enterprise. |
k9.Meridian.colabEnterprise.runtimeMachine_type
|
Tipo de máquina del tiempo de ejecución del cuaderno de Colab Enterprise. | n1-highmem-32
|
Tipo de máquina del tiempo de ejecución del cuaderno de Colab Enterprise. |
k9.Meridian.colabEnterprise.runtimeAcceleratorCoreCount
|
Número de núcleos. | 1
|
Número de núcleos del acelerador de GPU del entorno de ejecución del cuaderno de Colab Enterprise. |
k9.Meridian.colabEnterprise.runtimeAcceleratorType
|
Tipo de acelerador del tiempo de ejecución del cuaderno de Colab Enterprise. | NVIDIA_TESLA_T4
|
El tipo de GPU. |
k9.Meridian.colabEnterprise.executionName
|
Nombre de la ejecución del tiempo de ejecución del cuaderno de Colab Enterprise. | cortex-meridian-execution
|
Nombre que se mostrará en la interfaz web de Colab Enterprise - Ejecuciones. |
k9.Meridian.colabEnterprise.notebookRunLogsFolder
|
Nombre de la carpeta de las ejecuciones del tiempo de ejecución. | notebook-run-logs
|
Las ejecuciones del cuaderno de Colab almacenarán los registros y las copias de ejecución del cuaderno aquí. |
Flujo de trabajo
Los flujos de trabajo son la interfaz principal para iniciar las ejecuciones de Cortex para Meridian. Se implementa un flujo de trabajo predeterminado llamado cortex-meridian-execute-notebook
como parte de Cortex para Meridian.
Ejecución de cuadernos
Para iniciar una nueva ejecución de Cortex para Meridian, sigue estos pasos:
- Ve al cuaderno
cortex-meridian-execute-notebookde Workflows. - Haz clic en Ejecutar para iniciar una nueva ejecución.
- En las ejecuciones iniciales, deje el campo de entrada vacío para usar la configuración predeterminada almacenada en el archivo de configuración
cortex_meridian_config.jsonde Cloud Storage. - Vuelve a hacer clic en Ejecutar para continuar.
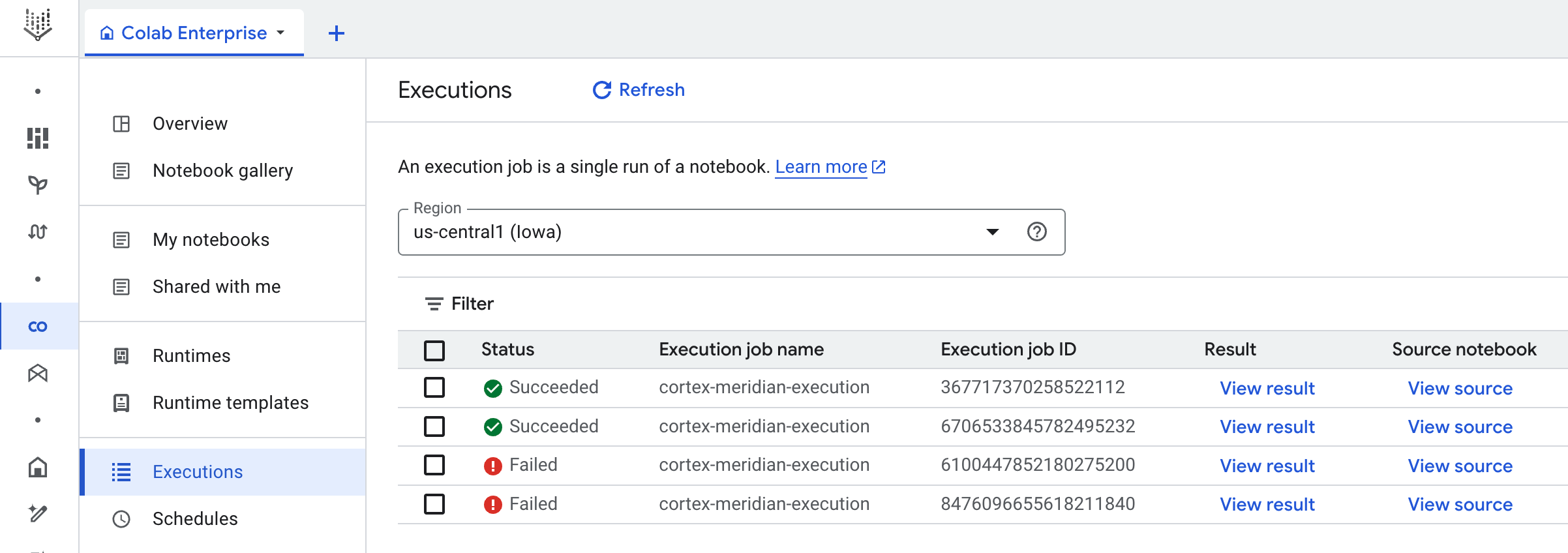
Después de un breve retraso, se mostrará el estado de ejecución del flujo de trabajo:
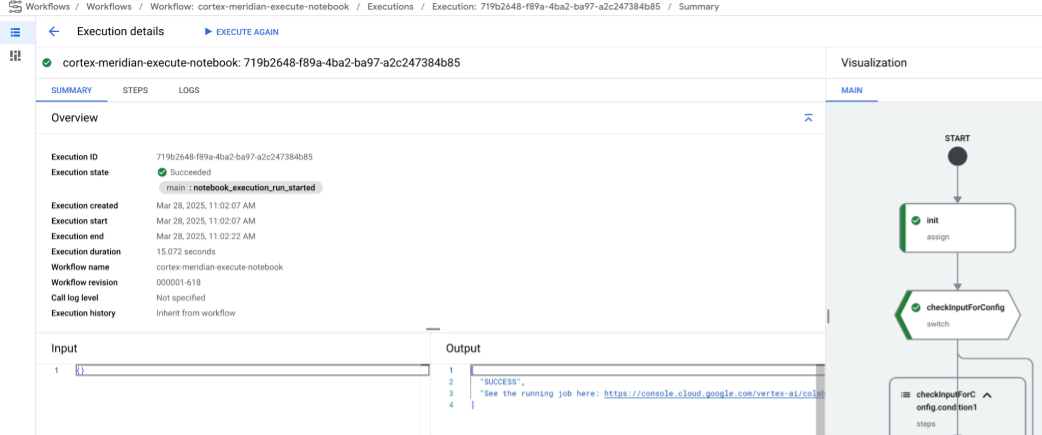
Imagen 10. Ejemplo de detalles de ejecución. Monitoriza el progreso de la ejecución del cuaderno en Colab Enterprise.
Pasos del flujo de trabajo
El flujo de trabajo de cortex-meridian-execute-notebook contiene los siguientes pasos:
| Step | Sub-step | Descripción |
init
|
-
|
Inicializa los parámetros. |
checkInputForConfig
|
-
|
Comprueba si se ha proporcionado un nuevo archivo JSON de configuración como entrada del flujo de trabajo. |
logBackupConfigFileName
|
Registra el nombre del archivo de configuración de la copia de seguridad. | |
backupConfigFile
|
Crea una copia de seguridad del archivo de configuración en Cloud Storage. | |
logBackupResult
|
Registra el resultado de la llamada a la API de Cloud Storage. | |
updateGCSConfigFile
|
Actualiza el archivo de configuración en Cloud Storage con los nuevos valores. | |
pre_notebook_execution
|
-
|
Este paso está vacío de forma predeterminada. Puedes personalizarla. Por ejemplo, la carga de datos u otros pasos relevantes antes de ejecutar el cuaderno. Para obtener más información, consulta los artículos Información general de Workflows y Conectores de Workflows. |
create_notebook_execution_run
|
-
|
Crea la ejecución del cuaderno de Colab Enterprise (mediante una secuencia de comandos shell en Cloud Build). |
notebook_execution_run_started
|
-
|
Muestra el resultado de la finalización. |
Personalizar el flujo de trabajo de ejecución de Meridian
Puedes personalizar la ejecución de Meridian proporcionando tu propio archivo JSON de configuración en el campo de entrada Workflows:
- Introduce el JSON completo de la configuración modificada en el campo de entrada.
- El flujo de trabajo hará lo siguiente:
- Sustituye el archivo
cortex_meridian_config.jsonde Cloud Storage por el JSON proporcionado. - Crea una copia de seguridad del archivo de configuración original en el directorio
Cloud Storage/configuration. - El nombre del archivo de copia de seguridad tendrá el formato
cortex_meridian_config_workflow_backup_workflow_execution_id.json, donde workflow_execution_id es un identificador único de la ejecución del flujo de trabajo actual (por ejemplo,cortex_meridian_config_workflow_backup_3e3a5290-fac0-4d51-be5a-19b55b2545de.json).
- Sustituye el archivo
Información general sobre los cuadernos de Jupyter
La función principal de cargar datos de entrada para ejecutar el modelo de Meridian se gestiona mediante el cuaderno de Python meridian_cortex_marketing.ipynb, ubicado en la carpeta notebooks de tu segmento de Cloud Storage.
El flujo de ejecución del cuaderno consta de los siguientes pasos:
- Instala los paquetes necesarios (incluido Meridian) e importa las bibliotecas obligatorias.
- Carga funciones auxiliares para interactuar con Cloud Storage y BigQuery.
- Obtiene la configuración de ejecución del archivo
configuration/cortex_meridian_config.jsonen Cloud Storage. - Carga los datos de Cortex Framework desde la vista Infraestructura de datos de Cortex Framework en BigQuery.
- Configura la especificación del modelo de Meridian y asigna los modelos de datos de Cortex Framework Data Foundation para marketing y ventas al esquema de entrada del modelo de Meridian.
- Ejecuta el muestreo de Meridian y genera un informe de resumen, que se guarda en Cloud Storage (
/reporting). - Ejecuta el optimizador de presupuesto para el escenario predeterminado y genera un informe de resumen en Cloud Storage (
/reporting). - Guarda el modelo en Cloud Storage (
/models). - Guarda los resultados de CSV en Cloud Storage (
/csv). - Genera un informe general y guárdalo en Cloud Storage (
/reporting).
Importar un cuaderno para ejecutarlo y editarlo manualmente
Para personalizar o ejecutar manualmente el cuaderno, impórtalo desde Cloud Storage:
- Ve a Colab Enterprise.
- Haz clic en Mis cuadernos.
- Haz clic en Importar.
- Selecciona Cloud Storage como fuente de importación y selecciona el cuaderno de Cloud Storage.
- Haz clic en Importar.
El cuaderno se cargará y se abrirá.
Resultados de las ejecuciones de cuadernos
Para revisar los resultados de la ejecución de un cuaderno, abre una copia completa del cuaderno con todos los resultados de las celdas:
- Ve a Ejecuciones en Colab Enterprise.
- En el menú desplegable, selecciona la región correspondiente.
- Junto al cuaderno que quieras consultar, haz clic en Ver resultado.
- Colab Enterprise abrirá el resultado de la ejecución del cuaderno en una pestaña nueva.
- Para ver el resultado, haz clic en la pestaña nueva.
Plantilla de entorno de ejecución
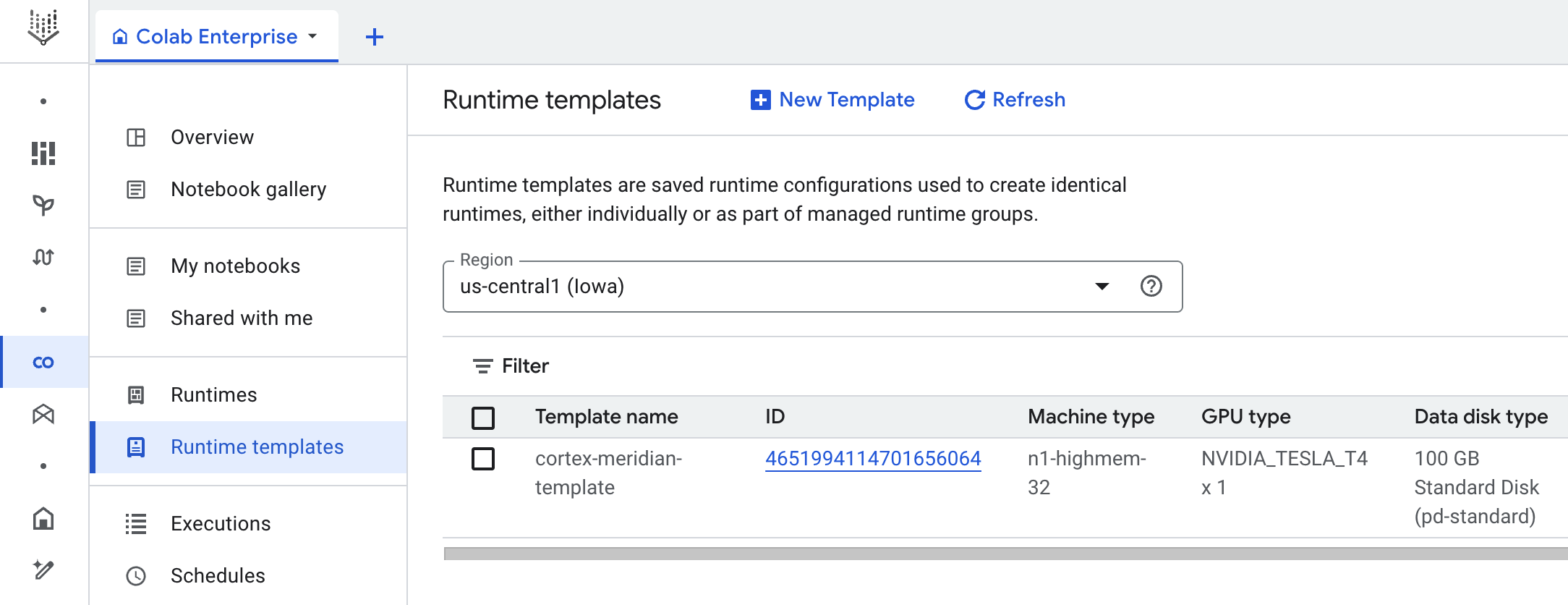
Google Cloud Colab Enterprise usa plantillas de entorno de ejecución para definir entornos de ejecución preconfigurados. Se incluye una plantilla de tiempo de ejecución predefinida, adecuada para ejecutar el cuaderno de Meridian, con la implementación de Cortex para Meridian. Esta plantilla se usa automáticamente para crear entornos de ejecución para las ejecuciones de cuadernos.
Si es necesario, puedes crear manualmente plantillas de tiempo de ejecución adicionales.