Integrazione con Salesforce Marketing Cloud
Questa pagina descrive le configurazioni necessarie per importare i dati da Salesforce Marketing Cloud (SFMC) come origine dati del carico di lavoro di marketing di Cortex Framework Data Foundation.
SFMC è una piattaforma di automazione del marketing digitale offerta da Salesforce. Fornisce alle aziende una suite completa di strumenti per gestire e automatizzare varie attività di marketing su più canali. Cortex Framework funge da motore di analisi dei dati e IA che ti aiuta a comprendere i risultati, identificare le aree di miglioramento e ottimizzare la tua strategia di marketing per ottenere risultati migliori.
Il seguente diagramma descrive come i dati SFMC sono disponibili tramite il carico di lavoro di marketing di Cortex Data Foundation:
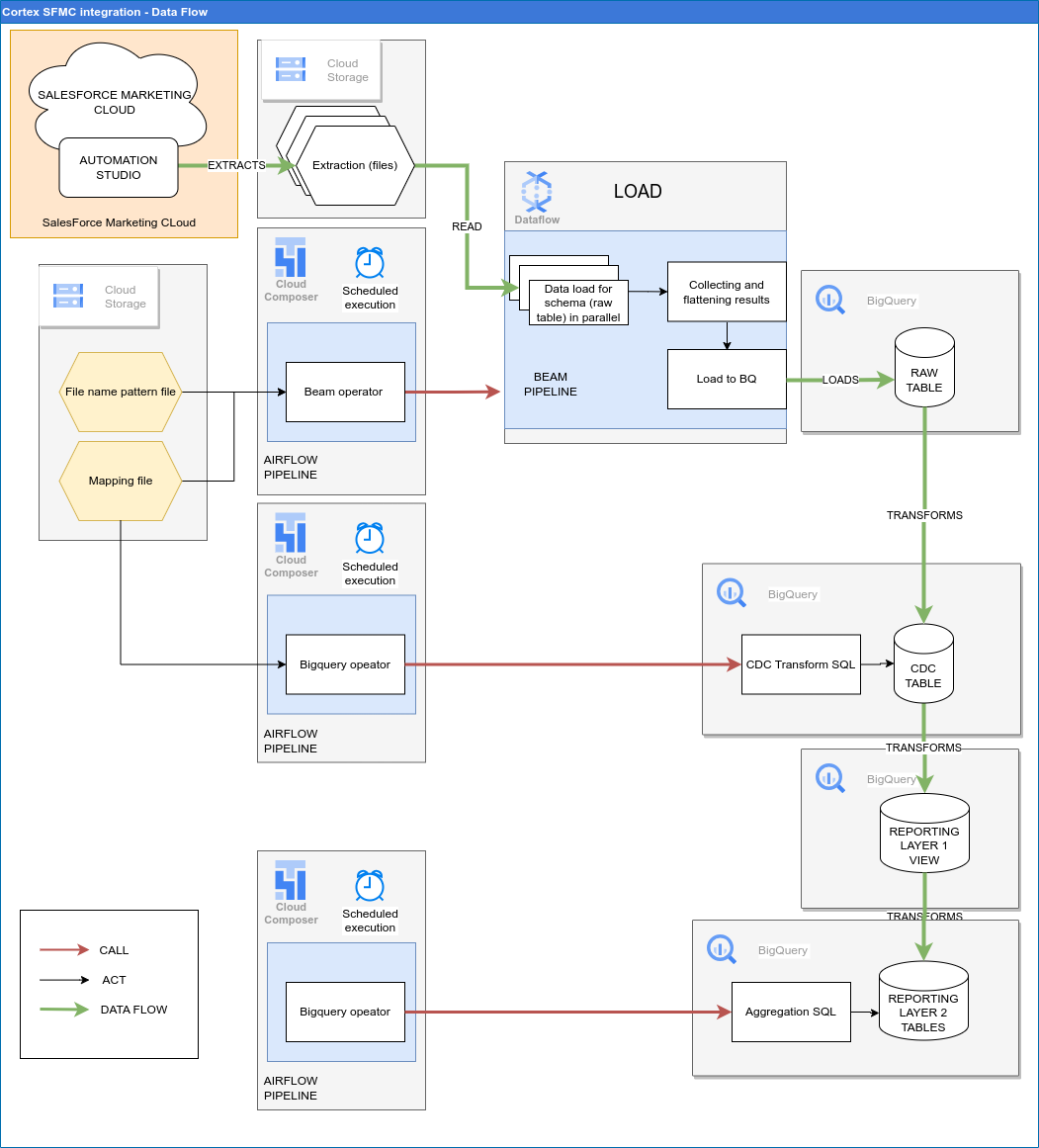
File di configurazione
Il file config.json configura le impostazioni necessarie per connettersi alle origini dati per il trasferimento
di dati da vari workload. Questo file contiene i seguenti parametri per SFMC:
"marketing": {
"deploySFMC": true,
"SFMC": {
"deployCDC": true,
"fileTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFMC"
}
}
}
La tabella seguente descrive il valore di ciascun parametro di marketing:
| Parametro | Significato | Valore predefinito | Descrizione |
marketing.deploySFMC
|
Esegui il deployment di SFMC | true
|
Esegui il deployment per l'origine dati SFMC. |
marketing.SFMC.deployCDC
|
Esegui il deployment degli script CDC per SFMC | true
|
Genera script di elaborazione CDC di Salesforce Marketing Cloud (SFMC) da eseguire come DAG in Cloud Composer. |
marketing.SFMC.fileTransferBucket
|
Bucket con i file di estrazione dati | - | Bucket in cui sono archiviati i file di estrazione dati di Automation Studio di Salesforce Marketing Cloud (SFMC). |
marketing.SFMC.datasets.cdc
|
Set di dati CDC per SFMC | Set di dati CDC per Salesforce Marketing Cloud (SFMC). | |
marketing.SFMC.datasets.raw
|
Set di dati non elaborati per SFMC | Set di dati non elaborati per Salesforce Marketing Cloud (SFMC). | |
marketing.SFMC.datasets.reporting
|
Set di dati dei report per SFMC | "REPORTING_SFMC"
|
Set di dati dei report per Salesforce Marketing Cloud (SFMC). |
Modello dati
Questa sezione descrive il modello di dati di Salesforce Marketing Cloud (SFMC) utilizzando il diagramma delle relazioni tra entità (ERD).
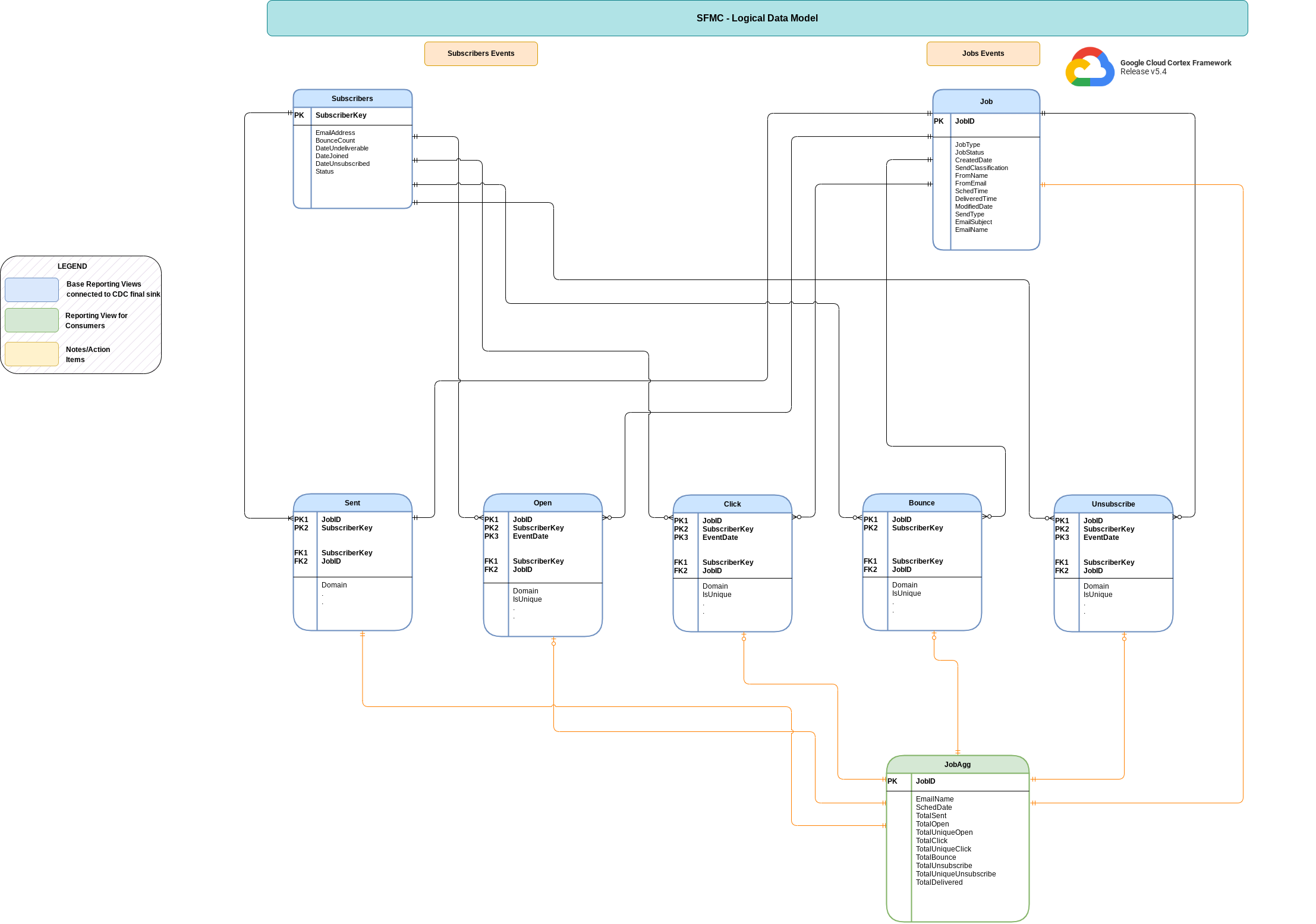
Visualizzazioni di base
Questi sono gli oggetti blu nell'ERD e sono viste sulle tabelle CDC senza
trasformazioni diverse da alcuni alias dei nomi delle colonne. Visualizza gli script in
src/marketing/src/SFMC/src/reporting/ddls.
Viste report
Si tratta degli oggetti verdi nell'ERD e sono visualizzazioni dei report che contengono
metriche aggregate. Visualizza gli script in
src/marketing/src/SFMC/src/reporting/ddls.
Estrazione dei dati utilizzando Automation Studio
SFMC Automation Studio consente ai consumatori di SFMC di esportare i dati di SFMC in vari sistemi di archiviazione. Cortex Framework Data Foundation cerca un insieme di file creati con Automation Studio in un bucket Cloud Storage. Inoltre, in questo processo devi utilizzare Email Studio di SFMC.
Per configurare le procedure di estrazione ed esportazione dei dati:
- Configura un bucket Cloud Storage. In questo bucket vengono archiviati i file
esportati da SFMC. Assegna un nome al parametro di configurazione
marketing.SFMC.fileTransferBucketdel bucket. Consulta le istruzioni riportate nella documentazione di Salesforce. Crea estensioni di dati. Per ogni entità per la quale vuoi estrarre i dati, crea un'estensione dati in Email Studio. Questo è necessario per identificare le origini dati dal database interno di SFMC.
- Elenca tutti i campi definiti in
src/SFMC/config/table_schemaper l'entità. Se devi personalizzare questa operazione per estrarre più o meno campi, assicurati che l'elenco dei campi sia allineato in questi passaggi e nei file dello schema della tabella. Ad esempio:
Entity: unsubscribe Fields: AccountID OYBAccountID JobID ListID BatchID SubscriberID SubscriberKey EventDate IsUnique Domain- Elenca tutti i campi definiti in
Crea attività di query SQL. Per ogni entità, crea un'attività di query SQL. Questa attività è collegata all'estensione di dati corrispondente creata in precedenza. Per questo passaggio, consulta la documentazione di Salesforce :
- Definisci la query SQL con tutti i campi pertinenti. La query deve selezionare tutti i campi pertinenti all'entità definiti nell'estensione dati nel passaggio precedente.
- Seleziona l'estensione dati corretta come target.
- Seleziona Sovrisci come azione sui dati.
- Vedi la seguente query di esempio:
SELECT AccountID, OYBAccountID, JobID, ListID, BatchID, SubscriberID, SubscriberKey, EventDate, IsUnique, Domain FROM _UnsubscribeCrea attività di estrazione dei dati. Consulta la documentazione di Salesforce per creare un'attività di estrazione dati per ogni entità. Questa attività recupera i dati dall'estensione dati Salesforce e li estrae in un file CSV. Per questo passaggio:
- Utilizza il pattern di denominazione corretto. Deve corrispondere al pattern definito nelle
impostazioni.
Ad esempio, per l'entità
Unsubscribe, il nome file può essereunsubscribe_%%Year%%_%%Month%%_%%Day%% %%Hour%%.csv. - Imposta Tipo di estrazione su
Data Extension Extract. - Seleziona le opzioni Ha intestazioni di colonna e Testo qualificato.
- Utilizza il pattern di denominazione corretto. Deve corrispondere al pattern definito nelle
impostazioni.
Ad esempio, per l'entità
Crea attività di conversione dei file per convertire il formato da UTF-16 a UTF-8. Per impostazione predefinita, Salesforce esporta i file CSV in UTF-16. In questo passaggio lo converti in formato UTF-8. Per ogni entità, crea un'altra attività di estrazione dati per la conversione dei file. Per questo passaggio:
- Utilizza lo stesso pattern di nome file utilizzato nel passaggio precedente dell'attività di estrazione dati.
- Imposta Tipo di estrazione su
File Convert - Seleziona
UTF8dal menu a discesa inConvert To.
Crea attività di trasferimento file. Crea un'attività di trasferimento file per ogni entità. Queste attività spostano i file CSV estratti da la casa sicura Salesforce ai bucket Cloud Storage. Per questo passaggio:
- Utilizza lo stesso pattern di nome file utilizzato nei passaggi precedenti.
- Seleziona come destinazione un bucket Cloud Storage configurato in precedenza nel processo.
Pianifica l'esecuzione. Al termine di tutte le attività, configura pianificazioni automatiche per eseguirle.
Aggiornamento e ritardo dei dati
Come regola generale, l'aggiornamento dei dati per le origini dati di Cortex Framework è limitato da ciò che consente la connessione a monte, nonché dalla frequenza di esecuzione del DAG. Modifica la frequenza di esecuzione del DAG in modo che sia in linea con la frequenza a monte, le limitazioni delle risorse e le esigenze della tua attività.
Con SFMC Automation Studio, il ritardo nell'aggiornamento dei dati dipende dal ritardo nella programmazione quando viene configurata l'esportazione dei dati.
Autorizzazioni per le connessioni di Cloud Composer
Crea le seguenti connessioni in Cloud Composer. Per ulteriori dettagli, consulta la documentazione sulla gestione delle connessioni Airflow.
| Nome connessione | Purpose |
sfmc_raw_dataflow
|
Per i file estratti da SFMC > set di dati BigQueryRaw. |
sfmc_cdc_bq
|
Per il trasferimento del set di dati non elaborato > set di dati CDC. |
sfmc_reporting_bq
|
Per il set di dati CDC > Trasferimento del set di dati dei report. |
Autorizzazioni del service account di Cloud Composer
L'account di servizio utilizzato in Cloud Composer (come configurato nella connessionesfmc_raw_dataflow) ha bisogno di autorizzazioni relative a Dataflow.
Consulta le istruzioni nella documentazione di Dataflow
Impostazioni di importazione
Controlla le pipeline di dati Source to Raw e Raw to CDC tramite le impostazioni nel file src/SFMC/config/ingestion_settings.yaml .
Questa sezione descrive i parametri di ogni pipeline di dati.
Origine alle tabelle non elaborate
Questa sezione contiene voci che controllano l'utilizzo dei file estratti da Automation Studio. Ogni voce corrisponde a un'entità SFMC. In base a questa configurazione, Cortex Framework crea DAG di Airflow che eseguono pipeline Dataflow per caricare i dati dai file esportati nelle tabelle BigQuery nel set di dati non elaborato.
La directory src/SFMC/config/table_schema contiene un file di schema per ogni entità
estratta da SFMC. In ogni file viene spiegato come leggere i file CSV
esportati da Automaton Studio per caricarli correttamente nel set di dati BigQueryraw.
Ogni file dello schema contiene tre colonne:
SourceField: nome del campo del file CSV.TargetField: il nome della colonna nella tabella non elaborata per questa entità.DataType: il tipo di dati di ogni campo della tabella non elaborata.
I seguenti parametri controllano le impostazioni di Source to Raw
per ogni voce:
| Parametro | Descrizione |
base_table
|
Nome della tabella non elaborata in cui vengono caricati i dati estratti di un'entità SFMC. |
load_frequency
|
La frequenza con cui viene eseguito un DAG per questa entità per caricare i dati dai file estratti. Per saperne di più sui possibili valori, consulta la documentazione di Airflow. |
file_pattern
|
Pattern per il file di questa tabella esportato da Automation Studio nel bucket Cloud Storage. Modificalo solo se hai scelto un nome diverso da quelli suggeriti per i file estratti. |
partition_details
|
La modalità di partizione della tabella non elaborata per motivi di rendimento. Per ulteriori informazioni, consulta Partizione della tabella. |
cluster_details
|
(Facoltativo) Se vuoi che la tabella non elaborata sia raggruppata per motivi di rendimento. Per ulteriori informazioni, consulta Impostazioni cluster. |
Tabelle non elaborate a CDC
Questa sezione descrive le voci che controllano il trasferimento dei dati dalle tabelle non elaborate alle tabelle CDC. Ogni voce corrisponde a una tabella non elaborata.
I seguenti parametri controllano le impostazioni di Raw to CDC per ogni voce:
| Parametro | Descrizione |
base_table
|
Tabella nel set di dati CDC in cui vengono archiviati i dati non elaborati dopo la trasformazione CDC. |
load_frequency
|
La frequenza con cui viene eseguito un DAG per questa entità per compilare la tabella CDC. Per ulteriori informazioni sui possibili valori, consulta la documentazione di Airflow. |
raw_table
|
Tabella di origine del set di dati non elaborato. |
row_identifiers
|
Colonne (separate da virgola) che formano un record univoco per questa tabella. |
partition_details
|
Come viene partizionata la tabella CDC per motivi di prestazioni. Per ulteriori informazioni, consulta Partizione della tabella. |
cluster_details
|
(Facoltativo) Se vuoi che questa tabella sia raggruppata per motivi di rendimento. Per ulteriori informazioni, consulta Impostazioni cluster. |
Impostazioni report
Puoi configurare e controllare la modalità di generazione dei dati da parte di Cortex Framework per il livello di generazione dei report finali di SFMC utilizzando il file di impostazioni dei report (src/SFMC/config/reporting_settings.yaml). Questo file controlla la modalità di generazione degli oggetti BigQuery del livello di generazione dei report (tabelle, visualizzazioni,funzioni o procedure archiviate).
Per ulteriori informazioni, vedi Personalizzare il file delle impostazioni dei report.
Passaggi successivi
- Per ulteriori informazioni su altre origini dati e carichi di lavoro, consulta Origini dati e carichi di lavoro.
- Per ulteriori informazioni sulla procedura di implementazione negli ambienti di produzione, consulta Prerequisiti per l'implementazione di Data Foundation di Cortex Framework.