Integrazione con Campaign Manager 360
Questa pagina descrive le configurazioni necessarie per importare i dati da Campaign Manager 360 come origine dati del carico di lavoro di marketing di Cortex Framework Data Foundation.
Campaign Manager 360 (CM360) è una piattaforma di gestione della pubblicità basata sul web offerta da Google e progettata specificamente per inserzionisti e agenzie. Funge da hub centrale per gestire e ottimizzare tutte le campagne pubblicitarie digitali su vari canali. Cortex Framework fornisce gli strumenti e la piattaforma per analizzare i dati di CM360, combinarli con quelli di altri canali di marketing e utilizzare l'AI per ottenere informazioni più approfondite e ottimizzare la strategia di marketing complessiva.
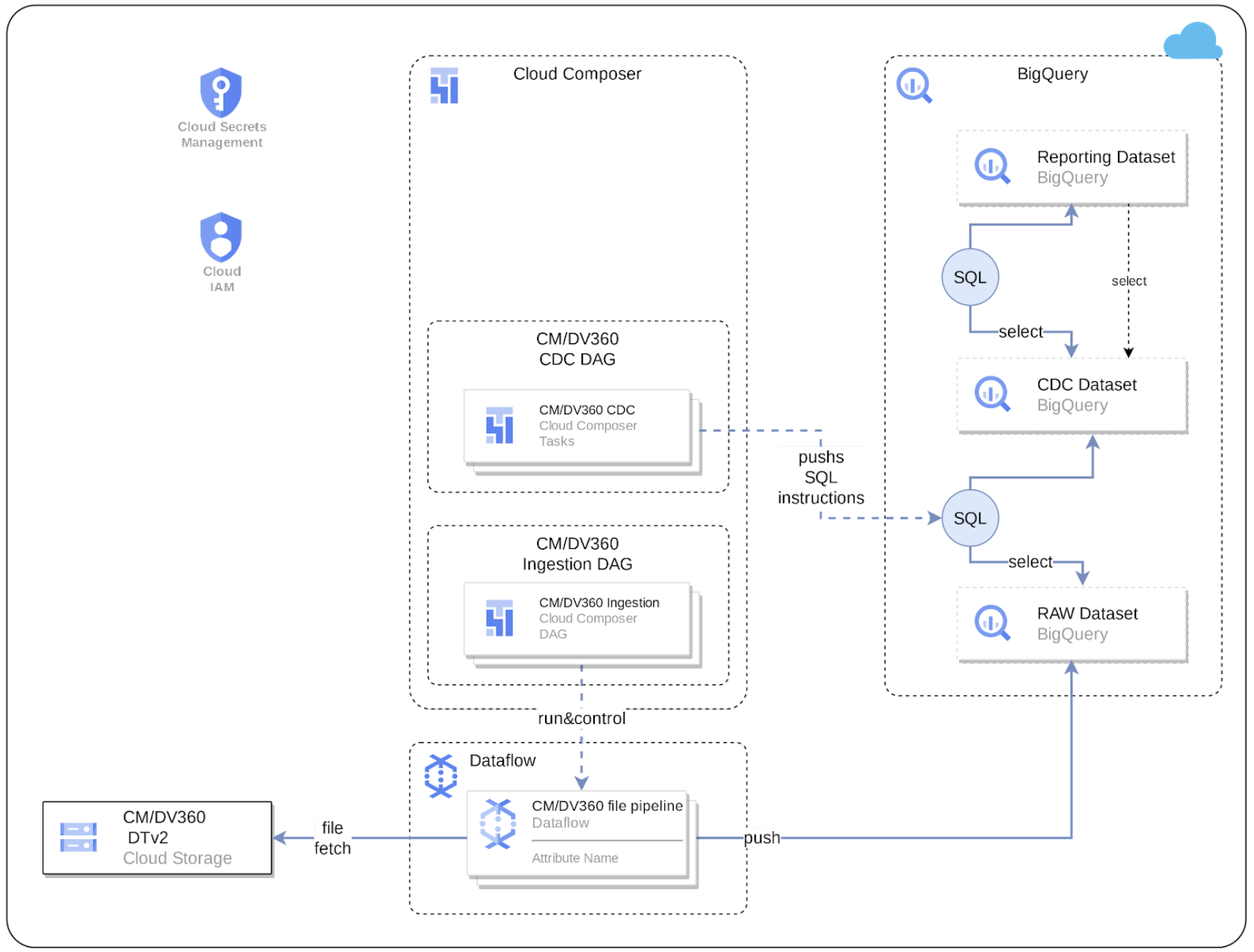
Il seguente diagramma descrive come i dati di CM360 sono disponibili tramite il carico di lavoro di marketing di Cortex Framework Data Foundation:
File di configurazione
Il file config.json
configura le impostazioni necessarie per connettersi alle origini dati per il trasferimento
di dati da vari workload. Questo file contiene i seguenti parametri per CM360:
"marketing": {
"deployCM360": true,
}
"CM360": {
"deployCDC": true,
"dataTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_CM360"
}
}
La tabella seguente descrive il valore di ciascun parametro di marketing:
| Parametro | Significato | Valore predefinito | Descrizione |
marketing.deployCM360
|
Esegui il deployment di CM360 | true
|
Esegui il deployment per l'origine dati CM360. |
marketing.CM360.deployCDC
|
Esegui il deployment degli script CDC per CM360 | true
|
Genera script di elaborazione CDC di CM360 da eseguire come DAG in Cloud Composer. |
marketing.CM360.dataTransferBucket
|
Bucket con i risultati di Data Transfer Service | - | Bucket in cui sono archiviati i file DTv2. |
marketing.CM360.datasets.cdc
|
Set di dati CDC per CM360 | Set di dati CDC per CM360. | |
marketing.CM360.datasets.raw
|
Set di dati non elaborati per CM360 | Set di dati non elaborato per CM360. | |
marketing.CM360.datasets.reporting
|
Set di dati dei report per CM360 | "REPORTING_CM360"
|
Set di dati dei report per CM360. |
Modello dati
Questa sezione descrive il modello di dati CM360 utilizzando il diagramma di relazione tra entità (ERD).
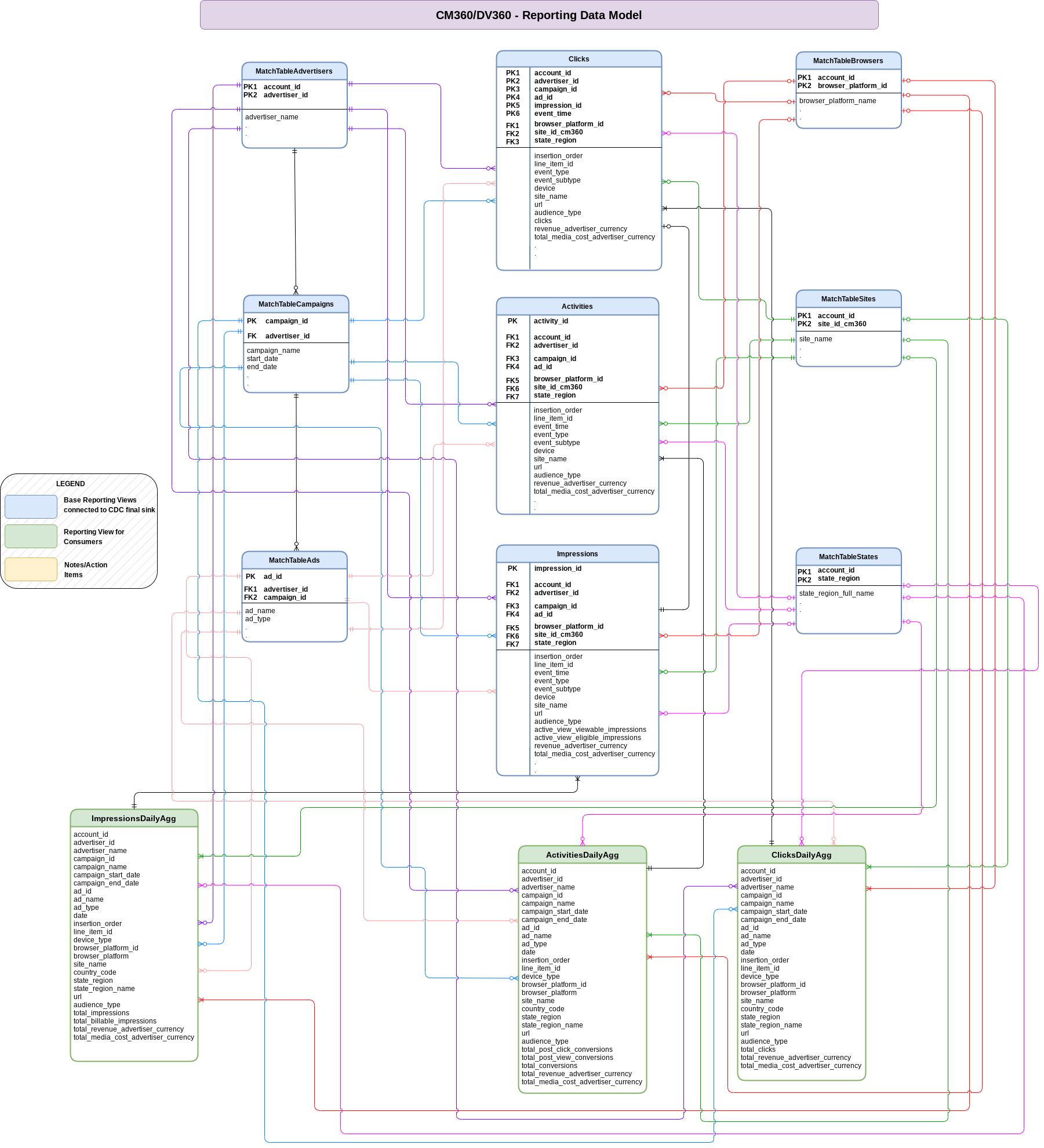
Visualizzazioni di base
Questi sono gli oggetti blu nell'ERD e sono viste sulle tabelle CDC senza
trasformazioni diverse da alcuni alias dei nomi delle colonne. Visualizza gli script in
src/marketing/src/CM360/src/reporting/ddls.
Viste report
Si tratta degli oggetti verdi nell'ERD e sono visualizzazioni dei report che contengono
metriche aggregate. Visualizza gli script in
src/marketing/src/CM360/src/reporting/ddls.
Archiviazione file di DTv2
I file DTv2 (Data Transfer Version 2) sono un formato specifico utilizzato da CM360 per fornire i dati sul rendimento delle campagne. Configura il processo di trasferimento dei dati seguendo la documentazione di Data Transfer V2.0 per utilizzare CM360 con Cortex Framework.
Crea o aggiungi un bucket Cloud Storage per archiviare i file DTv2 da CM360. Assicurati che i file nel bucket siano leggibili dall'account di servizio che esegue i DAG in Cloud Composer. Per ulteriori informazioni, consulta la sezione Creare bucket di archiviazione.
Aggiornamento e ritardo dei dati
Come regola generale, l'aggiornamento dei dati per le origini dati di Cortex Framework è limitato da ciò che consente la connessione a monte, nonché dalla frequenza di esecuzione del DAG. Modifica la frequenza di esecuzione del DAG in modo che sia in linea con la frequenza a monte, le limitazioni delle risorse e le esigenze della tua attività.
Con la versione 2 di Data Transfer di CM360, i dati su impressioni e clic vengono inviati 24 volte al giorno (ogni ora). Il tempo di elaborazione può variare in base al file, pertanto i file potrebbero non essere visualizzati in ordine. I file di attività vengono pubblicati ogni giorno.
Connessioni Cloud Composer
Crea le seguenti connessioni in Cloud Composer. Per ulteriori dettagli, consulta la documentazione sulla gestione delle connessioni Airflow.
| Nome connessione | Purpose |
cm360_raw_dataflow
|
Per i file DTv2 di CM360 > set di dati non elaborato BigQuery |
cm360_cdc_bq
|
Per il trasferimento del set di dati non elaborato > set di dati CDC |
cm360_reporting_bq
|
Per il trasferimento del set di dati CDC > set di dati report |
Autorizzazioni del service account di Cloud Composer
Concedi le autorizzazioni Dataflow all'account di servizio utilizzato in Cloud Composer (come configurato nella connessione cm360_raw_dataflow).
Consulta le istruzioni nella documentazione di Dataflow.
Impostazioni di importazione
Controlla le pipeline di dati Source to Raw e Raw to CDC tramite le impostazioni nel
file src/CM360/config/ingestion_settings.yaml. Questa sezione descrive i parametri di ogni pipeline di dati.
Origine alle tabelle non elaborate
Questa sezione descrive come vengono elaborate le voci che controllano i file di DTv2. Ogni voce corrisponde ai file associati a un'entità. In base a questa configurazione, Cortex Framework crea DAG di Airflow che eseguono pipeline di Dataflow per elaborare i dati dei file DTv2.
I seguenti parametri controllano le impostazioni di Source to Raw
per ogni voce:
| Parametro | Descrizione |
base_table
|
Tabella nel set di dati non elaborato in cui sono archiviati i dati di un'entità (ad es. i dati "Click"). |
load_frequency
|
La frequenza con cui viene eseguito un DAG per questa entità per compilare la tabella CDC. Per ulteriori informazioni sui possibili valori, consulta la documentazione di Airflow. |
file_pattern
|
Pattern di nomi di file basati su che corrispondono a un'entità. |
schema_file
|
File dello schema nella directory src/table_schema
che mappa i campi DTv2 ai nomi delle colonne e ai tipi di dati della tabella di destinazione.
|
partition_details
|
Facoltativo:se vuoi che questa tabella sia suddivisa per motivi di rendimento. Per ulteriori informazioni, consulta Partizione della tabella. |
cluster_details
|
(Facoltativo) Se vuoi che questa tabella sia raggruppata per motivi di rendimento. Per ulteriori informazioni, consulta Impostazioni cluster. |
Tabelle non elaborate a CDC
Questa sezione contiene voci che controllano il modo in cui i dati vengono spostati dalle tabelle non elaborate alle tabelle CDC. Ogni voce corrisponde a una tabella non elaborata (che a sua volta corrisponde all'entità DTv2 come indicato sopra).
I seguenti parametri controllano le impostazioni di Raw to CDC per ogni voce:
| Parametro | Descrizione |
base_table
|
Tabella nel set di dati CDC in cui vengono archiviati i dati non elaborati
dopo la trasformazione CDC (ad es. customer).
|
load_frequency
|
La frequenza con cui viene eseguito un DAG per questa entità per compilare la tabella CDC. Per ulteriori informazioni sui possibili valori, consulta la documentazione di Airflow. |
row_identifiers
|
Elenco di colonne (separate da virgola) che formano un record univoco per questa tabella. |
partition_details
|
Facoltativo:se vuoi che questa tabella sia suddivisa per motivi di rendimento. Per ulteriori informazioni, consulta Partizione della tabella. |
cluster_details
|
(Facoltativo) Se vuoi che questa tabella sia raggruppata per motivi di rendimento. Per ulteriori informazioni, consulta Impostazioni cluster. |
Impostazioni report
Puoi configurare e controllare la modalità di generazione dei dati da parte di Cortex Framework per il livello di generazione dei report finali di CM360 utilizzando il file di impostazioni dei report (src/CM360/config/reporting_settings.yaml). Questo file controlla la modalità di generazione degli oggetti BigQuery del livello di generazione dei report (tabelle, visualizzazioni, funzioni o procedure memorizzate).
Per ulteriori informazioni, vedi Personalizzare il file delle impostazioni dei report.
Passaggi successivi
- Per ulteriori informazioni su altre origini dati e carichi di lavoro, consulta Origini dati e carichi di lavoro.
- Per ulteriori informazioni sulla procedura di implementazione negli ambienti di produzione, consulta Prerequisiti per l'implementazione di Data Foundation di Cortex Framework.