Cloud Run functions トリガーを使用して Shielded VM 完全性モニタリング イベントに自動的に対処する方法について説明します。
概要
整合性モニタリングは Shielded VM インスタンスから測定値を収集し、それらを Cloud Logging で明らかにします。整合性測定値が Shielded VM インスタンスのブート内で変わると、整合性検証は失敗します。この失敗は、ログに記録されたイベントとして取り込まれます。これは Cloud Monitoring でも発生します。
正当な理由で Shielded VM の整合性の測定値が変わることがあります。たとえば、システムの更新によって、オペレーティング システムのカーネルに予想される変化が生じた場合などです。この変化のため、完全性の検証が予想どおりに失敗した場合、完全性モニタリングによって Shielded VM インスタンスが新しい完全性ポリシーのベースラインを習得する必要があります。
このチュートリアルでは、まず、次の手順で、整合性検証で不合格だった Shielded VM インスタンスをシャットダウンする単純な自動システムを作成します。
- すべての完全性モニタリング イベントを Pub/Sub トピックにエクスポートします。
- 完全性検証で不合格だった Shielded VM インスタンスを識別してシャットダウンするため、そのトピックのイベントを使用する Cloud Run functions のトリガーを作成します。
次に、必要に応じてシステムを拡張し、完全性の検証で不合格だった Shielded VM インスタンスが既知の正常な測定値と一致する場合は新しいベースラインを習得するか、そうでない場合はシャットダウンするように指示します。
- Firestore データベースを作成して、既存の正常な完全性ベースラインの測定値を維持します。
- Cloud Run functions トリガーを更新して、完全性の検証で不合格だった Shielded VM インスタンスがデータベース内にある場合は、インスタンスに新しいベースラインを習得するように指示し、それ以外の場合はシャットダウンするように指示します。
拡張されたソリューションを実装する場合は、次の方法で行ってください。
- 正当な理由で検証が失敗すると予想される更新があるたびに、インスタンス グループ内の単一の Shielded VM インスタンスでその更新を実行します。
- 更新された VM インスタンスからの後期ブートイベントをソースとして使用し、known_good_measurements コレクションに新しいドキュメントを作成して、新しいポリシー ベースライン測定値をデータベースに追加します。詳しくは、既存の正常なベースライン測定値のデータベースの作成をご覧ください。
- 残りの Shielded VM インスタンスを更新します。トリガーによって、残りのインスタンスに新しいベースラインを習得することを求められます。既存の正常なベースラインとして検証される可能性があるためです。詳細は、Cloud Run functions のトリガーを更新して既知の適切なベースラインを習得するをご覧ください。
前提条件
- ネイティブ モードの Firestore をデータベース サービスとして選択しているプロジェクトを使用します。選択はプロジェクトを作成するときに実施します。これは変更できません。プロジェクトで Firestore をネイティブ モードで使用していない場合、Firestore コンソールを開くと「このプロジェクトは別のデータベース サービスを使用しています」というメッセージが表示されます。
- そのプロジェクトに Compute Engine Shielded VM インスタンスを配置して、整合性ベースライン測定値のソースとして機能させます。Shielded VM インスタンスは少なくとも 1 回は再起動される必要があります。
gcloudコマンドライン ツールがインストール済み。次の手順で、Stackdriver Logging API と Cloud Run functions の API を有効にします。
Google Cloud コンソールで、[API とサービス] ページに移動します。
Cloud Functions API と Stackdriver Logging API が [有効化された API とサービス] リストに表示されているか確認します。
どちらの API も表示されていない場合は、[API とサービスを追加] をクリックします。
必要に応じて API を検索して有効にします。
Pub/Sub トピックに整合性モニタリング エントリをエクスポートする
ログを使用して、Shielded VM インスタンスによって生成されたすべての完全性モニタリング ログエントリを Pub/Sub トピックにエクスポートします。このトピックを Cloud Run functions トリガーのデータソースとして使用して、完全性モニタリング イベントへのレスポンスを自動化します。
ログ エクスプローラ
Google Cloud コンソールで、[ログ エクスプローラ] ページに移動します。
クエリビルダーに、次の値を入力します。
resource.type="gce_instance" AND logName: "projects/YOUR_PROJECT_ID/logs/compute.googleapis.com/shielded_vm_integrity"
[Run Filter] をクリックします。
[その他の操作] をクリックし、[シンクを作成] を選択します。
[ログ ルーティング シンクの作成] ページで、次の操作を行います。
- [シンクの詳細] の [シンク名] に「
integrity-monitoring」と入力し、[次へ] をクリックします。 - [シンクの宛先] で [シンクサービス] を展開し、[Cloud Pub/Sub] を選択します。
- [Cloud Pub/Sub トピックを選択してください] を開いて、[トピックを作成する] をクリックします。
- [トピックの作成] ダイアログの [トピック ID] に「
integrity-monitoring」と入力し、[トピックを作成] をクリックします。 - [次へ] をクリックし、[シンクを作成] をクリックします。
- [シンクの詳細] の [シンク名] に「
ログ エクスプローラ
Google Cloud コンソールで、[ログ エクスプローラ] ページに移動します。
[オプション] をクリックしてから、[Go back to Legacy Logs Explorer] を選択します。
[ラベルまたはテキスト検索でフィルタ] を開き、[高度なフィルタに変換] をクリックします。
次の高度なフィルタを入力します。
resource.type="gce_instance" AND logName: "projects/YOUR_PROJECT_ID/logs/compute.googleapis.com/shielded_vm_integrity"
logName:の後にスペースが 2 つあることに注意してください。[フィルタを送信] をクリックします。
[エクスポートを作成] をクリックします。
[シンク名] に「
integrity-monitoring」と入力します。[シンクサービス] で [Cloud Pub/Sub] を選択します。
[シンクの宛先] を開き、[新しい Cloud Pub/Sub トピックを作成する] をクリックします。
[名前] に「
integrity-monitoring」と入力し、[作成] をクリックします。[シンクを作成] をクリックします。
完全性の失敗に対応するための Cloud Run functions トリガーを作成する
Pub/Sub トピックのデータを読み取り、完全性検証で不合格だった Shielded VM インスタンスを停止する Cloud Run functions トリガーを作成します。
次のコードは Cloud Run functions トリガーを定義します。このコードを
main.pyという名前のファイルにコピーします。import base64 import json import googleapiclient.discovery def shutdown_vm(data, context): """A Cloud Function that shuts down a VM on failed integrity check.""" log_entry = json.loads(base64.b64decode(data['data']).decode('utf-8')) payload = log_entry.get('jsonPayload', {}) entry_type = payload.get('@type') if entry_type != 'type.googleapis.com/cloud_integrity.IntegrityEvent': raise TypeError("Unexpected log entry type: %s" % entry_type) report_event = (payload.get('earlyBootReportEvent') or payload.get('lateBootReportEvent')) if report_event is None: # We received a different event type, ignore. return policy_passed = report_event['policyEvaluationPassed'] if not policy_passed: print('Integrity evaluation failed: %s' % report_event) print('Shutting down the VM') instance_id = log_entry['resource']['labels']['instance_id'] project_id = log_entry['resource']['labels']['project_id'] zone = log_entry['resource']['labels']['zone'] # Shut down the instance. compute = googleapiclient.discovery.build( 'compute', 'v1', cache_discovery=False) # Get the instance name from instance id. list_result = compute.instances().list( project=project_id, zone=zone, filter='id eq %s' % instance_id).execute() if len(list_result['items']) != 1: raise KeyError('unexpected number of items: %d' % len(list_result['items'])) instance_name = list_result['items'][0]['name'] result = compute.instances().stop(project=project_id, zone=zone, instance=instance_name).execute() print('Instance %s in project %s has been scheduled for shut down.' % (instance_name, project_id))
main.pyと同じ場所で、以下の依存関係において、requirements.txtという名前のファイルを作成してコピーします。google-api-python-client==1.6.6 google-auth==1.4.1 google-auth-httplib2==0.0.3
ターミナル ウィンドウを開き、
main.pyとrequirements.txtを含むディレクトリに移動します。gcloud beta functions deployコマンドを実行して次のトリガーをデプロイします。gcloud beta functions deploy shutdown_vm \ --project PROJECT_ID \ --runtime python37 \ --trigger-resource integrity-monitoring \ --trigger-event google.pubsub.topic.publish
既存の正常なベースライン測定値のデータベースを作成する
Firestore データベースを作成して、既存の正常な整合性ポリシーのベースライン測定値のソースを提供します。このデータベースを最新の状態に保つには、ベースライン測定値を手動で追加する必要があります。
Google Cloud コンソールで、[VM インスタンス] ページに移動します。
Shielded VM インスタンス ID をクリックして、[VM インスタンスの詳細] ページを開きます。
[ログ] で、[Stackdriver Logging] をクリックします。
最新の
lateBootReportEventログエントリを見つけます。ログエントリ >
jsonPayload>lateBootReportEvent>policyMeasurementsを展開します。lateBootReportEvent>policyMeasurementsに含まれる要素の値に注意してください。Google Cloud コンソールで、[Firestore] ページに移動します。
[コレクションを開始] を選択します。
[コレクション ID] に「known_good_measurements」と入力します。
[ドキュメント ID] に「baseline1」と入力します。
[フィールド名] に、
lateBootReportEvent>policyMeasurementsの要素0に含まれる [pcrNum] フィールドの値を入力します。[フィールド タイプ] で [マップ] を選択します。
hashAlgo、pcrNum、value という名前の 3 つの文字列フィールドを [マップ] フィールドに追加します。この値を
lateBootReportEvent>policyMeasurementsの要素0フィールドの値にします。さらにマップ フィールドを作成(
lateBootReportEvent>policyMeasurementsの要素ごとに 1 つ)します。作成したマップ フィールドに、最初のマップ フィールドと同じサブフィールドを指定します。このサブフィールドの値は、追加の要素ごとの値にマッピングされます。たとえば、Linux VM を使用している場合、作成が完了したコレクションは次のようになります。
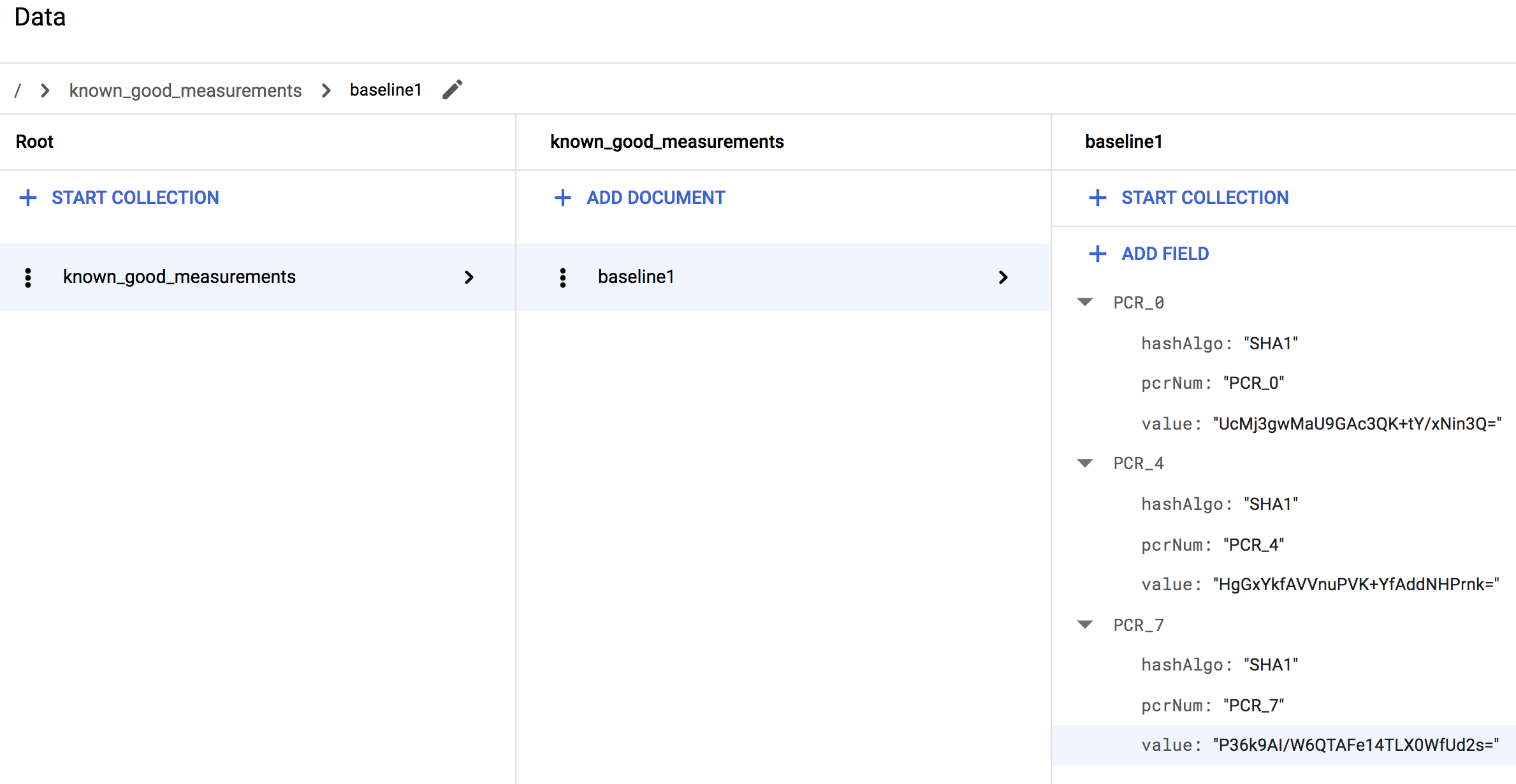
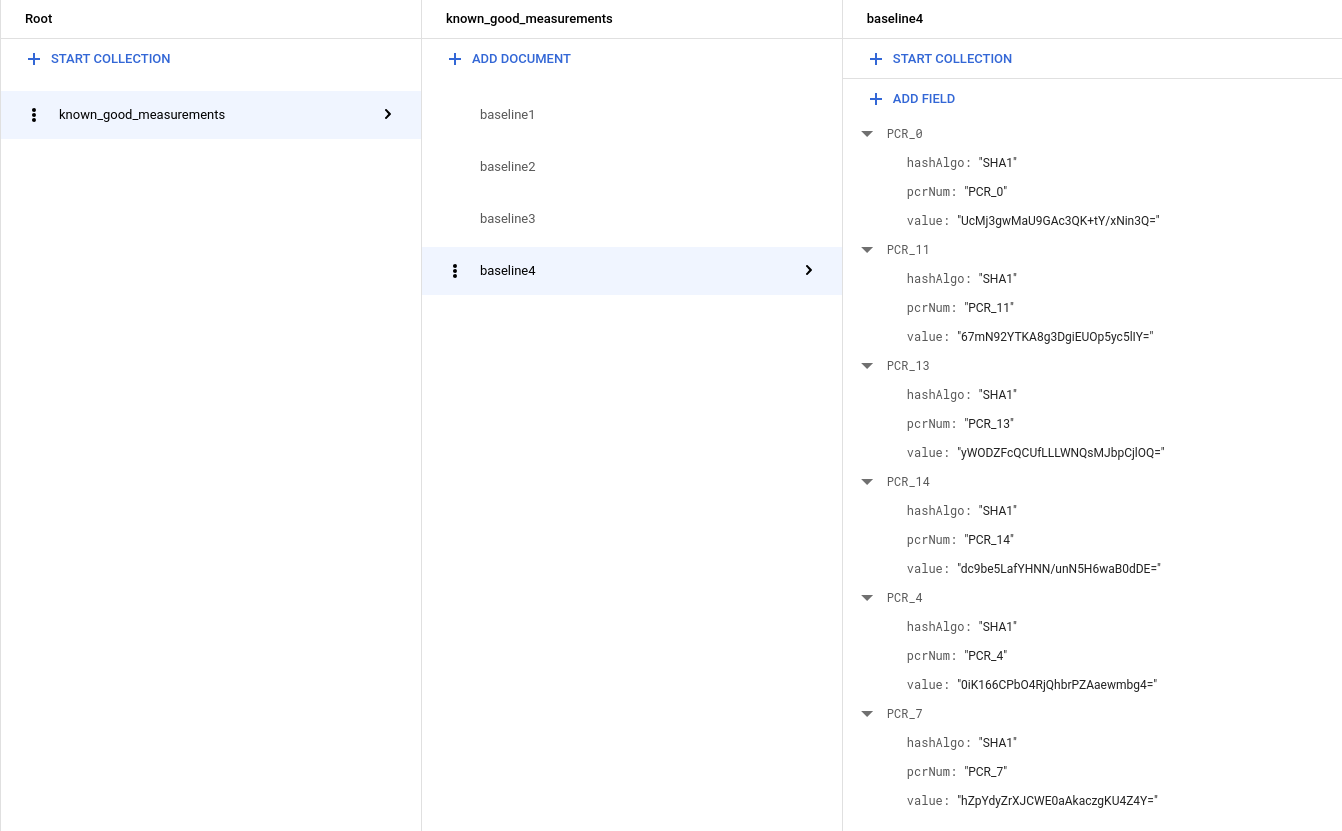
Windows VM を使用している場合は、より多くの測定値、すなわち次のようなコレクションが表示されます。
Cloud Run functions トリガーを更新して既知の適切な基準値を学習する
次のコードにより、既知の正常な測定結果のデータベースにある場合は、完全性検証で不合格だったすべての Shielded VM インスタンスに新しいベースラインを習得させ、それ以外の場合はシャットダウンする Cloud Run functions トリガーが作成されます。このコードをコピーして、
main.py内の既存コードを上書きします。import base64 import json import googleapiclient.discovery import firebase_admin from firebase_admin import credentials from firebase_admin import firestore PROJECT_ID = 'PROJECT_ID' firebase_admin.initialize_app(credentials.ApplicationDefault(), { 'projectId': PROJECT_ID, }) def pcr_values_to_dict(pcr_values): """Converts a list of PCR values to a dict, keyed by PCR num""" result = {} for value in pcr_values: result[value['pcrNum']] = value return result def instance_id_to_instance_name(compute, zone, project_id, instance_id): list_result = compute.instances().list( project=project_id, zone=zone, filter='id eq %s' % instance_id).execute() if len(list_result['items']) != 1: raise KeyError('unexpected number of items: %d' % len(list_result['items'])) return list_result['items'][0]['name'] def relearn_if_known_good(data, context): """A Cloud Function that shuts down a VM on failed integrity check. """ log_entry = json.loads(base64.b64decode(data['data']).decode('utf-8')) payload = log_entry.get('jsonPayload', {}) entry_type = payload.get('@type') if entry_type != 'type.googleapis.com/cloud_integrity.IntegrityEvent': raise TypeError("Unexpected log entry type: %s" % entry_type) # We only send relearn signal upon receiving late boot report event: if # early boot measurements are in a known good database, but late boot # measurements aren't, and we send relearn signal upon receiving early boot # report event, the VM will also relearn late boot policy baseline, which we # don't want, because they aren't known good. report_event = payload.get('lateBootReportEvent') if report_event is None: return evaluation_passed = report_event['policyEvaluationPassed'] if evaluation_passed: # Policy evaluation passed, nothing to do. return # See if the new measurement is known good, and if it is, relearn. measurements = pcr_values_to_dict(report_event['actualMeasurements']) db = firestore.Client() kg_ref = db.collection('known_good_measurements') # Check current measurements against known good database. relearn = False for kg in kg_ref.get(): kg_map = kg.to_dict() # Check PCR values for lateBootReportEvent measurements against the known good # measurements stored in the Firestore table if ('PCR_0' in kg_map and kg_map['PCR_0'] == measurements['PCR_0'] and 'PCR_4' in kg_map and kg_map['PCR_4'] == measurements['PCR_4'] and 'PCR_7' in kg_map and kg_map['PCR_7'] == measurements['PCR_7']): # Linux VM (3 measurements), only need to check above 3 measurements if len(kg_map) == 3: relearn = True # Windows VM (6 measurements), need to check 3 additional measurements elif len(kg_map) == 6: if ('PCR_11' in kg_map and kg_map['PCR_11'] == measurements['PCR_11'] and 'PCR_13' in kg_map and kg_map['PCR_13'] == measurements['PCR_13'] and 'PCR_14' in kg_map and kg_map['PCR_14'] == measurements['PCR_14']): relearn = True compute = googleapiclient.discovery.build('compute', 'beta', cache_discovery=False) instance_id = log_entry['resource']['labels']['instance_id'] project_id = log_entry['resource']['labels']['project_id'] zone = log_entry['resource']['labels']['zone'] instance_name = instance_id_to_instance_name(compute, zone, project_id, instance_id) if not relearn: # Issue shutdown API call. print('New measurement is not known good. Shutting down a VM.') result = compute.instances().stop(project=project_id, zone=zone, instance=instance_name).execute() print('Instance %s in project %s has been scheduled for shut down.' % (instance_name, project_id)) else: # Issue relearn API call. print('New measurement is known good. Relearning...') result = compute.instances().setShieldedInstanceIntegrityPolicy( project=project_id, zone=zone, instance=instance_name, body={'updateAutoLearnPolicy':True}).execute() print('Instance %s in project %s has been scheduled for relearning.' % (instance_name, project_id))
次の依存関係をコピーして、
requirements.txt内の既存のコードを上書きします。google-api-python-client==1.6.6 google-auth==1.4.1 google-auth-httplib2==0.0.3 google-cloud-firestore==0.29.0 firebase-admin==2.13.0
ターミナル ウィンドウを開き、
main.pyとrequirements.txtを含むディレクトリに移動します。gcloud beta functions deployコマンドを実行して次のトリガーをデプロイします。gcloud beta functions deploy relearn_if_known_good \ --project PROJECT_ID \ --runtime python37 \ --trigger-resource integrity-monitoring \ --trigger-event google.pubsub.topic.publishCloud 関数のコンソール上で、旧版の
shutdown_vm関数を手動で削除します。Google Cloud コンソールで、[Cloud Functions] ページに移動します。
shutdown_vm 関数を選択し、delete をクリックします。
整合性検証の失敗に対する自動応答を確認する
- まず、 が有効になっている実行中のインスタンスの Shielded VM オプションが有効になっているかどうかを確認します。有効になっていない場合は、Shielded VM イメージで新しいインスタンスを作成して(Ubuntu 18.04LTS)、セキュアブート オプションを有効にします。インスタンスに対して数セントが請求される場合があります。この処理は 1 時間以内に完了します。
- ここで、なんらかの理由により、手動でカーネルをアップグレードするとします。
インスタンスに SSH で接続し、次のコマンドを使用して現在のカーネルを確認します。
uname -srLinux 4.15.0-1028-gcpなどのコードが表示されます。https://kernel.ubuntu.com/~kernel-ppa/mainline/ から汎用カーネルをダウンロードします。
ダウンロードしたコマンドを使用してインストールします。
sudo dpkg -i *.debVM を再起動します。
マシンに SSH でログインできないため、VM が起動していないことがわかります。新しいカーネルの署名がセキュアブート ホワイトリストに含まれていないため、これは想定どおりの結果です。またこれによって、セキュアブートが承認されていない不正なカーネルによる変更を確かに防止することもわかります。
しかし、今回は悪意のある行為によるカーネルのアップグレードではないので、セキュアブートを無効にして新しいカーネルを起動します。
VM をシャットダウンし、セキュアブート オプションの選択を解除した後、VM を再起動します。
マシンの起動が再び失敗します。しかし今回は、セキュアブート オプションが変更されたのと、新しいカーネル イメージが追加されたため、Cloud 関数によって自動的にシャットダウンされ、基準値とは異なる測定結果となります。(上記の結果は、Cloud 関数の Stackdriver ログで確認できます。)
悪意ある変更ではなく根本原因もわかっているため、
lateBootReportEventの測定結果を既知の正常な測定値の Firebase テーブルに追加できます(2 つの変更点があることに注意してください: (1)セキュアブート オプション(2)カーネル イメージ)。前の手順に沿って実行します。既知の正常な測定値のデータベースを作成し、最新の
lateBootReportEventにある実測値を使用して、Firestore データベースに新しい基準値を追加します。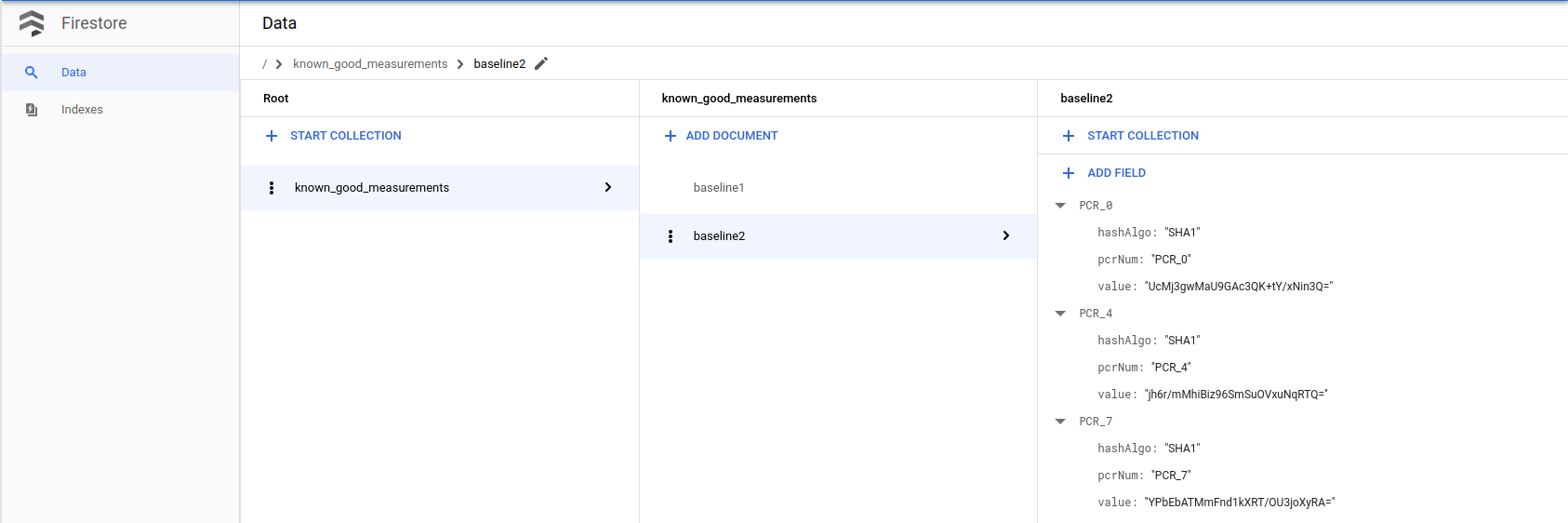
マシンを再起動します。[Stackdriver ログ] チェックボックスをオンにしても、
lateBootReportEventは false のままです。しかし、Cloud 関数が新しい測定値を信頼して再学習したため、マシンは正常に起動できるはずです。このことは、Cloud 関数の Stackdriver を確認することで確認できます。次に、セキュアブートを無効にすると、カーネルにブートできるようになります。マシンに SSH でログインし、カーネルをもう一度確認すると、新しいカーネル バージョンが表示されます。
uname -sr最後に、このステップで使用したリソースとデータをクリーンアップします。
このステップで作成をした場合は、追加の請求を回避するために、VM をシャットダウンします。
Google Cloud コンソールで、[VM インスタンス] ページに移動します。
このステップで追加した既知の正常な測定値を削除します。
Google Cloud コンソールで、[Firestore] ページに移動します。