Questo tutorial descrive come attivare la replica asincrona di Hyperdisk Balanced in due regioni Google Cloud come soluzione di ripristino di emergenza (RE) e come avviare le istanzeRER in caso di disastro.
Un'istanza del cluster di failover (FCI) di Microsoft SQL Server è una singola istanza SQL Server ad alta disponibilità di cui viene eseguito il deployment su più nodi del cluster di failover di Windows Server (WSFC). In qualsiasi momento, uno dei nodi del cluster ospita attivamente l'istanza SQL. In caso di interruzione di zona o problema della VM, WSFC trasferisce automaticamente la proprietà delle risorse dell'istanza a un altro nodo all'interno del cluster, consentendo ai client di riconnettersi. La FCI di SQL Server richiede che i dati si trovino su dischi condivisi in modo che sia possibile accedervi da tutti i nodi WSFC.
Per garantire che il deployment di SQL Server possa resistere a un'interruzione a livello di regione, replica i dati del disco della regione primaria in una regione secondaria attivando la replica asincrona. Questo tutorial utilizza dischi multi-writer Hyperdisk bilanciato ad alta affidabilità per abilitare la replica asincrona in due regioni Google Cloud come soluzione di ripristino di emergenza (RE) per l'infrastruttura cluster di failover (FCI) di SQL Server e come avviare le istanze RE in caso di disastro. In questo documento, un disastro è un evento in cui un cluster di database principale non funziona o non è disponibile perché la regione del cluster non è disponibile, ad esempio a causa di una calamità naturale.
Questo tutorial è rivolto ad architetti, amministratori e database engineer.
Disaster recovery in Google Cloud
RE in Google Cloud comporta il mantenimento dell'accesso continuo ai dati quando una regione non funziona o diventa inaccessibile. Esistono diverse opzioni di implementazione per il sito di DR e queste saranno determinate dai requisiti del Recovery Point Objective (RPO) e del Recovery Time Objective (RTO). Questo tutorial illustra una delle opzioni in cui i dischi collegati alla macchina virtuale vengono replicati dalla regione principale a quella dREDR.
Disaster recovery utilizzando la replica asincrona di Hyperdisk
La replica asincrona di Hyperdisk è un'opzione di archiviazione che fornisce la copia asincrona dell'archiviazione per la replica dei dischi tra due regioni. Nell'improbabile caso di un'interruzione in una regione, la replica asincrona di Hyperdisk consente di eseguire il failover dei dati in una regione secondaria e di riavviare i workload in quella regione.
La replica asincrona di Hyperdisk replica i dati da un disco collegato a un workload in esecuzione, noto come disco principale, a un disco distinto situato in un'altra regione. Il disco che riceve la replica è definito come disco secondario. La regione in cui è in esecuzione il disco primario è denominata regione principale, mentre la regione in cui è in esecuzione il disco secondario è la regione secondaria. Per garantire che le repliche di tutti i dischi collegati a ogni nodo SQL Server contengano i dati dello stesso istante, i dischi vengono aggiunti a un gruppo di coerenza. I gruppi di coerenza ti consentono di eseguire test di RE e RE su più dischi.
Architettura del disaster recovery
Per la replica asincrona di Hyperdisk, il seguente diagramma mostra un'architettura minima che supporta l'alta affidabilità del database in una regione principale, R1, e la replica del disco dalla regione principale alla regione secondaria, R2.
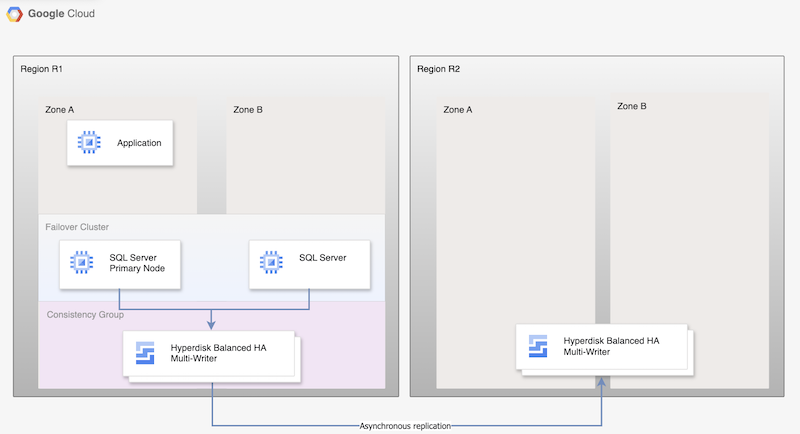
Figura 1. Architettura di disaster recovery con Microsoft SQL Server e replica asincrona di Hyperdisk
Questa architettura funziona nel seguente modo:
- Due istanze di Microsoft SQL Server, un'istanza principale e un'istanza di standby, fanno parte di un cluster FCI e si trovano nella regione principale (R1), ma in zone diverse (zone A e B). Entrambe le istanze condividono un disco Hyperdisk bilanciato ad alta affidabilità, consentendo l'accesso ai dati da entrambe le VM. Per istruzioni, consulta Configurazione di un cluster FCI SQL Server con la modalità multi-writer Hyperdisk bilanciato ad alta affidabilità.
- I dischi di entrambi i nodi SQL vengono aggiunti ai gruppi di coerenza e replicati nella regione diRER R2. Compute Engine replica in modo asincrono i dati da R1 a R2.
- La replica asincrona replica solo i dati sui dischi in R2 e non replica i metadati della VM. Durante il DR, vengono create nuove VM e i dischi replicati esistenti vengono collegati alle VM per mettere online i nodi.
Procedura di disaster recovery
Il processo di DR definisce i passaggi operativi da seguire dopo che una regione non è più disponibile per riprendere il workload in un'altra regione.
Un processo di base di DR del database prevede i seguenti passaggi:
- La prima regione (R1), in cui è in esecuzione l'istanza del database primaria, diventa non disponibile.
- Il team operativo riconosce e conferma formalmente l'emergenza e decide se è necessario eseguire un failover.
- Se è necessario un failover, devi terminare la replica tra i dischi primario e secondario. Viene creata una nuova VM dalle repliche del disco e messa online.
- Il database nella regione di RE, R2, viene convalidato e messo online. Il database in R2 diventa il nuovo database principale, abilitando la connettività.
- Gli utenti riprendono l'elaborazione nel nuovo database primario e accedono all'istanza primaria in R2.
Sebbene questo processo di base ristabilisca un database principale funzionante, non consente di creare un'architettura ad alta affidabilità completa, perché il nuovo database principale non viene replicato.
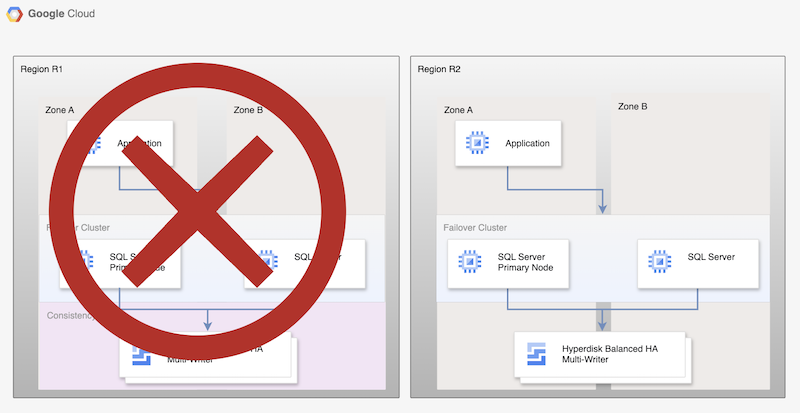
Figura 2. Deployment di SQL Server dopo il disaster recovery con la replica asincrona dei dischi permanenti
Ripristino di una regione recuperata
Quando la regione principale (R1) viene ripristinata online, puoi pianificare ed eseguire il processo di failback. La procedura di failback è composta da tutti i passaggi descritti in questo tutorial, ma in questo caso R2 è la regione di origine e R1 è la regione di recupero.
Scegli una versione di SQL Server
Questo tutorial supporta le seguenti versioni di Microsoft SQL Server:
- SQL Server 2016 Enterprise e Standard Edition
- SQL Server 2017 Enterprise e Standard Edition
- SQL Server 2019 Enterprise e Standard Edition
- SQL Server 2022 Enterprise e Standard Edition
Il tutorial utilizza l'istanza del cluster di failover SQL Server con il disco Hyperdisk bilanciato ad alta affidabilità.
Se non hai bisogno delle funzionalità di SQL Server Enterprise, puoi utilizzare la versione Standard di SQL Server:
Le versioni 2016, 2017, 2019 e 2022 di SQL Server sono dotate di Microsoft SQL Server Management Studio installato nell'immagine; non devi quindi installare il programma separatamente. Tuttavia, in un ambiente di produzione, ti consigliamo di installare un'istanza di Microsoft SQL Server Management Studio su una VM separata in ogni regione. Se configuri un ambiente ad alta affidabilità, devi installare Microsoft SQL Server Management Studio una volta per ciascuna zona per assicurarti che rimanga disponibile laddove una zona non fosse più accessibile.
Configura il disaster recovery per Microsoft SQL Server
Questo tutorial utilizza l'immagine sql-ent-2022-win-2022 per Microsoft SQL Server
Enterprise.
Per un elenco completo delle immagini, consulta Immagini sistema operativo.
Configura un cluster ad alta affidabilità con due istanze
Per configurare la replica dei dischi per SQL Server tra due regioni, innanzitutto
crea un cluster ad alta affidabilità a due istanze in una regione.
Un'istanza
fungerà da istanza principale e l'altra da istanza in standby. Per completare questo passaggio, segui le istruzioni riportate in
Configurazione di un cluster FCI SQL Server con la modalità multi-writer Hyperdisk bilanciato ad alta affidabilità.
Questo tutorial utilizza us-central1 per la regione primaria R1.
Se hai seguito i passaggi descritti in
Configurazione di un cluster FCI SQL Server con modalità multi-writer Hyperdisk bilanciato ad alta affidabilità,
avrai creato due istanze SQL Server nella stessa regione (us-central1) e avrai eseguito il deployment di un'istanza SQL Server primaria (node-1) in
us-central1-a e di un'istanza in standby (node-2) in us-central1-b.
Attiva la replica asincrona dei dischi
Dopo aver creato e configurato tutte le VM, attiva la replica dei dischi tra le due regioni completando i seguenti passaggi:
Crea un gruppo di coerenza sia per i nodi SQL Server sia per il nodo che ospita i ruoli di controllo del witness e del dominio. Uno dei limiti per i gruppi di coerenza è che non possono estendersi a più zone, quindi devi aggiungere ogni nodo a un gruppo di coerenza separato.
gcloud compute resource-policies create disk-consistency-group node-1-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group node-2-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group witness-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group multiwriter-disk-const-grp \ --region=$REGION
Aggiungi i dischi delle VM principali e di standby ai gruppi di coerenza corrispondenti.
gcloud compute disks add-resource-policies node-1 \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-2 \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies mw-datadisk-1 \ --region=$REGION \ --resource-policies=multiwriter-disk-const-grp gcloud compute disks add-resource-policies witness \ --zone=$REGION-c \ --resource-policies=witness-disk-const-grp
Crea dischi secondari vuoti nella regione secondaria.
DR_REGION="us-west1" gcloud compute disks create node-1-replica \ --zone=$DR_REGION-a \ --size=50 \ --primary-disk=node-1 \ --primary-disk-zone=$REGION-a gcloud compute disks create node-2-replica \ --zone=$DR_REGION-b \ --size=50 \ --primary-disk=node-2 \ --primary-disk-zone=$REGION-b gcloud compute disks create multiwriter-datadisk-1-replica \ --replica-zones=$DR_REGION-a,$DR_REGION-b \ --size=$PD_SIZE \ --type=hyperdisk-balanced-high-availability \ --access-mode READ_WRITE_MANY \ --primary-disk=multiwriter-datadisk-1 \ --primary-disk-region=$REGION gcloud compute disks create witness-replica \ --zone=$DR_REGION-c \ --size=50 \ --primary-disk=witness \ --primary-disk-zone=$REGION-c
Avvia la replica del disco. I dati vengono replicati dal disco principale al disco vuoto appena creato nella regione di DR.
gcloud compute disks start-async-replication node-1 \ --zone=$REGION-a \ --secondary-disk=node-1-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-2 \ --zone=$REGION-b \ --secondary-disk=node-2-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication multiwriter-datadisk-1 \ --region=$REGION \ --secondary-disk=multiwriter-datadisk-1-replica \ --secondary-disk-region=$DR_REGION gcloud compute disks start-async-replication witness \ --zone=$REGION-c \ --secondary-disk=witness-replica \ --secondary-disk-zone=$DR_REGION-c
A questo punto, i dati dovrebbero essere in fase di replica tra le regioni.
Lo stato della replica per ogni disco dovrebbe essere Active.
Simula un disaster recovery
In questa sezione, testerai l'architettura di disaster recovery configurata in questo tutorial.
Simula un'interruzione del servizio ed esegui un failover di disaster recovery
Durante un failover, crei nuove VM nella regione di RE e colleghi i dischi replicati. Per semplificare il failover, puoi utilizzare un altro Virtual Private Cloud (VPC) nella regione di RE per il recupero, in modo da utilizzare lo stesso indirizzo IP.
Prima di avviare il failover, assicurati che node-1 sia il nodo principale per il
gruppo di disponibilità AlwaysOn che hai creato. Avvia il domain controller e il
nodo SQL Server principale per evitare problemi di sincronizzazione dei dati, poiché
i due nodi sono protetti da due gruppi di coerenza distinti.
Per simulare un'interruzione, segui questi passaggi:
Crea una VPC di recupero.
DRVPC_NAME="default-dr" DRSUBNET_NAME="default-recovery" gcloud compute networks create $DRVPC_NAME \ --subnet-mode=custom CIDR=$(gcloud compute networks subnets describe default \ --region=$REGION --format=value\(ipCidrRange\)) gcloud compute networks subnets create $DRSUBNET_NAME \ --network=$DRVPC_NAME --range=$CIDR --region=$DR_REGION
Termina o interrompi la replica dei dati.
PROJECT=$(gcloud config get-value project) gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-1-disk-const-grp \ --zone=$REGION-a gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-2-disk-const-grp \ --zone=$REGION-b gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/multiwriter-disk-const-grp \ --zone=$REGION-c gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/witness-disk-const-grp \ --zone=$REGION-c
Arresta le VM di origine nella regione principale.
gcloud compute instances stop node-1 \ --zone=$REGION-a gcloud compute instances stop node-2 \ --zone=$REGION-b gcloud compute instances stop witness \ --zone=$REGION-c
Rinomina le VM esistenti per evitare nomi duplicati nel progetto.
gcloud compute instances set-name witness \ --new-name=witness-old \ --zone=$REGION-c gcloud compute instances set-name node-1 \ --new-name=node-1-old \ --zone=$REGION-a gcloud compute instances set-name node-2 \ --new-name=node-2-old \ --zone=$REGION-b
Crea le VM nella regione di RE utilizzando i dischi secondari. Queste VM avranno l'indirizzo IP della VM di origine.
NODE1IP=$(gcloud compute instances describe node-1-old --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) NODE2IP=$(gcloud compute instances describe node-2-old --zone $REGION-b --format=value\(networkInterfaces[0].networkIP\)) WITNESSIP=$(gcloud compute instances describe witness-old --zone $REGION-c --format=value\(networkInterfaces[0].networkIP\)) gcloud compute instances create node-1 \ --zone=$DR_REGION-a \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE1IP\ --disk=boot=yes,device-name=node-1-replica,mode=rw,name=node-1-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional gcloud compute instances create witness \ --zone=$DR_REGION-c \ --machine-type=n2-standard-2 \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $WITNESSIP \ --disk=boot=yes,device-name=witness-replica,mode=rw,name=witness-replica gcloud compute instances create node-2 \ --zone=$DR_REGION-b \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE2IP\ --disk=boot=yes,device-name=node-2-replica,mode=rw,name=node-2-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional
Hai simulato un'interruzione e hai eseguito il failover nella regione di RE. Ora puoi verificare se l'istanza secondaria funziona correttamente.
Verifica la connettività di SQL Server
Dopo aver creato le VM, verifica che i database siano stati recuperati correttamente e che il server funzioni come previsto. Per testare il database, esegui una query dal database recuperato.
- Connettiti alla VM SQL Server utilizzando Remote Desktop.
- Apri SQL Server Management Studio.
- Nella finestra di dialogo Connettiti al server, verifica che il nome del server sia impostato su
node-1e seleziona Connetti. Nel menu File, seleziona File > Nuovo > Query con la connessione attuale.
USE [bookshelf]; SELECT * FROM Books;