Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Cette page explique comment utiliser KubernetesPodOperator pour déployer des pods Kubernetes à partir de Cloud Composer dans le cluster Google Kubernetes Engine appartenant à votre environnement Cloud Composer.
KubernetesPodOperator lance les pods Kubernetes dans le cluster de votre environnement. Les opérateurs Google Kubernetes Engine, quant à eux, exécutent des pods Kubernetes dans un cluster spécifié, qui peut être un cluster distinct et non lié à votre environnement. Vous pouvez également créer et supprimer des clusters à l'aide d'opérateurs Google Kubernetes Engine.
KubernetesPodOperator est une bonne option si vous avez besoin:
- de dépendances Python personnalisées qui ne sont pas disponibles via le dépôt PyPI public ;
- de dépendances binaires qui ne sont pas disponibles dans l'image de nœud de calcul Cloud Composer issue de la banque d'images.
Avant de commencer
- Nous vous recommandons d'utiliser la dernière version de Cloud Composer. Cette version doit être au minimum compatible avec le règlement sur les abandons de versions et la compatibilité.
- Assurez-vous que votre environnement dispose de suffisamment de ressources. Le lancement de pods dans un environnement où les ressources sont insuffisantes peut entraîner des erreurs au niveau des nœuds de calcul et des programmeurs Airflow.
Configurer les ressources de votre environnement Cloud Composer
Lorsque vous créez un environnement Cloud Composer, vous spécifiez ses paramètres de performance, y compris les paramètres de performance du cluster de l'environnement. Le lancement de pods Kubernetes dans le cluster de l'environnement peut entraîner une concurrence pour les ressources de cluster, telles que le processeur ou la mémoire. Dans la mesure où le programmeur et les nœuds de calcul Airflow appartiennent au même cluster GKE, ils ne fonctionneront pas correctement si cette concurrence entraîne un épuisement des ressources.
Pour éviter une pénurie de ressources, prenez l'une ou plusieurs des mesures suivantes :
- (Recommandé) Créez un pool de nœuds
- Augmentez le nombre de nœuds dans votre environnement.
- Spécifiez le type de machine approprié.
Créer un pool de nœuds
La méthode privilégiée pour éviter l'épuisement des ressources dans l'environnement Cloud Composer est de créer un pool de nœuds et de configurer les pods Kubernetes pour qu'ils s'exécutent en exploitant exclusivement les ressources de ce pool.
Console
Dans la console Google Cloud, accédez à la page Environnements.
Cliquez sur le nom de votre environnement.
Sur la page Détails de l'environnement, accédez à l'onglet Configuration de l'environnement.
Dans la section Ressources > Cluster GKE, suivez le lien Afficher les détails du cluster.
Créez un pool de nœuds comme décrit dans la section Ajouter un pool de nœuds.
gcloud
Déterminez le nom du cluster de votre environnement:
gcloud composer environments describe ENVIRONMENT_NAME \ --location LOCATION \ --format="value(config.gkeCluster)"Remplacez :
ENVIRONMENT_NAMEpar le nom de l'environnement.LOCATIONpar la région où se trouve l'environnement.
La sortie contient le nom du cluster de votre environnement. Par exemple,
europe-west3-example-enviro-af810e25-gke.Créez un pool de nœuds comme décrit dans la section Ajouter un pool de nœuds.
Augmenter le nombre de nœuds dans votre environnement
L'augmentation du nombre de nœuds dans votre environnement Cloud Composer augmente la puissance de calcul disponible pour vos charges de travail. Cette augmentation ne fournit pas de ressources supplémentaires pour les tâches qui nécessitent plus de processeur ou de RAM que le type de machine spécifié.
Pour augmenter le nombre de nœuds, mettez à jour votre environnement.
Spécifier le type de machine approprié
Lors de la création de l'environnement Cloud Composer, vous pouvez spécifier un type de machine. Pour garantir la disponibilité des ressources, spécifiez un type de machine pour le type de calcul qui se produit dans votre environnement Cloud Composer.
Configuration minimale
Pour créer un KubernetesPodOperator, seuls les paramètres name, image à utiliser et task_id du pod sont obligatoires. /home/airflow/composer_kube_config contient les identifiants permettant de s'authentifier auprès de GKE.
Airflow 2
Airflow 1
Configuration de l'affinité de pod
Lorsque vous configurez le paramètre affinity dans KubernetesPodOperator, vous contrôlez les nœuds sur lesquels les pods sont programmés, par exemple les nœuds d'un pool de nœuds spécifique. Dans cet exemple, l'opérateur ne s'exécute que sur les pools de nœuds pool-0 et pool-1. Vos nœuds d'environnement Cloud Composer 1 se trouvant dans default-pool, vos pods ne s'exécutent pas sur les nœuds de votre environnement.
Airflow 2
Airflow 1
Tel que l'exemple est configuré, la tâche échoue. Si vous consultez les journaux, la tâche échoue car les pools de nœuds pool-0 et pool-1 n'existent pas.
Pour vérifier que les pools de nœuds existent dans values, effectuez l'une des modifications de configuration suivantes :
Si vous avez créé un pool de nœuds précédemment, remplacez
pool-0etpool-1par les noms de vos pools de nœuds, puis importez à nouveau votre DAG.Créez un pool de nœuds nommé
pool-0oupool-1. Vous pouvez créer les deux, mais la tâche n'a besoin que d'un pool pour réussir.Remplacez
pool-0etpool-1pardefault-pool, qui est le pool par défaut utilisé par Airflow. Ensuite, importez à nouveau votre DAG.
Une fois les modifications effectuées, attendez quelques minutes que votre environnement soit mis à jour.
Exécutez ensuite à nouveau la tâche ex-pod-affinity et vérifiez que la tâche ex-pod-affinity réussit.
Configuration supplémentaire
Cet exemple présente des paramètres supplémentaires que vous pouvez configurer dans KubernetesPodOperator.
Pour en savoir plus, consultez les ressources suivantes:
Pour en savoir plus sur l'utilisation des secrets et des ConfigMaps Kubernetes, consultez Utiliser des secrets et des ConfigMaps Kubernetes.
Pour en savoir plus sur l'utilisation des modèles Jinja avec KubernetesPodOperator, consultez la section Utiliser des modèles Jinja.
Pour en savoir plus sur les paramètres KubernetesPodOperator, consultez la documentation de référence de l'opérateur dans la documentation Airflow.
Airflow 2
Airflow 1
Utiliser des modèles Jinja
Airflow est compatible avec les modèles Jinja dans les DAG.
Vous devez déclarer les paramètres Airflow requis (task_id, name et image) avec l'opérateur. Comme le montre l'exemple suivant, vous pouvez modéliser tous les autres paramètres avec Jinja, y compris cmds, arguments, env_vars et config_file.
Le paramètre env_vars de l'exemple est défini à partir d'une variable Airflow nommée my_value. L'exemple de DAG obtient sa valeur à partir de la variable de modèle vars dans Airflow. Airflow dispose de plus de variables qui permettent d'accéder à différents types d'informations. Par exemple, vous pouvez utiliser la variable de modèle conf pour accéder aux valeurs des options de configuration d'Airflow. Pour en savoir plus et obtenir la liste des variables disponibles dans Airflow, consultez la documentation de référence sur les modèles dans la documentation Airflow.
Sans modifier le DAG ni créer la variable env_vars, la tâche ex-kube-templates de l'exemple échoue, car la variable n'existe pas. Créez cette variable dans l'interface utilisateur d'Airflow ou avec Google Cloud CLI:
Interface utilisateur d'Airflow
Accédez à l'interface utilisateur d'Airflow.
Dans la barre d'outils, sélectionnez Administration > Variables.
Sur la page List Variable (Variable de liste), cliquez sur Add a new record (Ajouter un enregistrement).
Sur la page Add Variable (Ajouter une variable), saisissez les informations suivantes :
- Key (Clé) :
my_value - Val (Valeur) :
example_value
- Key (Clé) :
Cliquez sur Enregistrer.
Si votre environnement utilise Airflow 1, exécutez plutôt la commande suivante:
Accédez à l'interface utilisateur d'Airflow.
Dans la barre d'outils, sélectionnez Admin > Variables (Administration > Variables).
Sur la page Variables, cliquez sur l'onglet Create (Créer).
Sur la page Variable, saisissez les informations suivantes :
- Key (Clé) :
my_value - Val (Valeur) :
example_value
- Key (Clé) :
Cliquez sur Enregistrer.
gcloud
Saisissez la commande suivante :
gcloud composer environments run ENVIRONMENT \
--location LOCATION \
variables set -- \
my_value example_value
Si votre environnement utilise Airflow 1, exécutez plutôt la commande suivante:
gcloud composer environments run ENVIRONMENT \
--location LOCATION \
variables -- \
--set my_value example_value
Remplacez :
ENVIRONMENTpar le nom de l'environnement.LOCATIONpar la région où se trouve l'environnement.
L'exemple suivant montre comment utiliser des modèles Jinja avec KubernetesPodOperator:
Airflow 2
Airflow 1
Utiliser les secrets et les ConfigMaps Kubernetes
Un secret Kubernetes est un objet qui contient des données sensibles. Un ConfigMap Kubernetes est un objet qui contient des données non confidentielles sous forme de paires clé-valeur.
Dans Cloud Composer 2, vous pouvez créer des secrets et des ConfigMaps à l'aide de la Google Cloud CLI, de l'API ou de Terraform, puis y accéder depuis KubernetesPodOperator.
À propos des fichiers de configuration YAML
Lorsque vous créez un secret Kubernetes ou un ConfigMap à l'aide de la Google Cloud CLI et de l'API, vous fournissez un fichier au format YAML. Ce fichier doit respecter le même format que celui utilisé par les secrets et les ConfigMaps Kubernetes. La documentation Kubernetes fournit de nombreux exemples de code de ConfigMaps et de secrets. Pour commencer, consultez les pages Distribuer des identifiants de manière sécurisée à l'aide de secrets et ConfigMaps.
Comme dans les secrets Kubernetes, utilisez la représentation base64 lorsque vous définissez des valeurs dans Secrets.
Pour encoder une valeur, vous pouvez utiliser la commande suivante (il s'agit de l'une des nombreuses façons d'obtenir une valeur encodée en base64):
echo "postgresql+psycopg2://root:example-password@127.0.0.1:3306/example-db" -n | base64
Sortie :
cG9zdGdyZXNxbCtwc3ljb3BnMjovL3Jvb3Q6ZXhhbXBsZS1wYXNzd29yZEAxMjcuMC4wLjE6MzMwNi9leGFtcGxlLWRiIC1uCg==
Les deux exemples de fichiers YAML suivants sont utilisés dans des exemples plus loin dans ce guide. Exemple de fichier de configuration YAML pour un secret Kubernetes:
apiVersion: v1
kind: Secret
metadata:
name: airflow-secrets
data:
sql_alchemy_conn: cG9zdGdyZXNxbCtwc3ljb3BnMjovL3Jvb3Q6ZXhhbXBsZS1wYXNzd29yZEAxMjcuMC4wLjE6MzMwNi9leGFtcGxlLWRiIC1uCg==
Autre exemple montrant comment inclure des fichiers. Comme dans l'exemple précédent, commencez par encoder le contenu d'un fichier (cat ./key.json | base64), puis fournissez cette valeur dans le fichier YAML:
apiVersion: v1
kind: Secret
metadata:
name: service-account
data:
service-account.json: |
ewogICJ0eXBl...mdzZXJ2aWNlYWNjb3VudC5jb20iCn0K
Exemple de fichier de configuration YAML pour un ConfigMap. Vous n'avez pas besoin d'utiliser la représentation base64 dans les ConfigMaps:
apiVersion: v1
kind: ConfigMap
metadata:
name: example-configmap
data:
example_key: example_value
Gérer les secrets Kubernetes
Dans Cloud Composer 2, vous créez des secrets à l'aide de Google Cloud CLI et de kubectl:
Obtenez des informations sur le cluster de votre environnement:
Exécutez la commande suivante :
gcloud composer environments describe ENVIRONMENT \ --location LOCATION \ --format="value(config.gkeCluster)"Remplacez :
ENVIRONMENTpar le nom de votre environnement.LOCATIONpar la région où se trouve l'environnement Cloud Composer.
Le résultat de cette commande utilise le format suivant :
projects/<your-project-id>/zones/<zone-of-composer-env>/clusters/<your-cluster-id>.Pour obtenir l'ID du cluster GKE, copiez le résultat après
/clusters/(se termine par-gke).Pour obtenir la zone, copiez le résultat après
/zones/.
Connectez-vous à votre cluster GKE avec la commande suivante:
gcloud container clusters get-credentials CLUSTER_ID \ --project PROJECT \ --zone ZONERemplacez :
CLUSTER_ID: ID de cluster de l'environnement.PROJECT_ID: ID du projet.ZONEpar la zone dans laquelle se trouve le cluster de l'environnement.
Créez des secrets Kubernetes:
Les commandes suivantes illustrent deux approches différentes pour créer des secrets Kubernetes. L'approche
--from-literalutilise des paires clé/valeur. L'approche--from-fileutilise le contenu des fichiers.Pour créer un secret Kubernetes en fournissant des paires clé-valeur, exécutez la commande suivante. Cet exemple crée un secret nommé
airflow-secretsqui comporte un champsql_alchemy_connavec la valeurtest_value.kubectl create secret generic airflow-secrets \ --from-literal sql_alchemy_conn=test_valuePour créer un secret Kubernetes en fournissant le contenu du fichier, exécutez la commande suivante. Cet exemple crée un secret nommé
service-accountqui comporte le champservice-account.jsonavec la valeur extraite du contenu d'un fichier./key.jsonlocal.kubectl create secret generic service-account \ --from-file service-account.json=./key.json
Utiliser des secrets Kubernetes dans vos DAG
Cet exemple présente deux façons d'utiliser les secrets Kubernetes: en tant que variable d'environnement et en tant que volume installé par le pod.
Le premier secret, airflow-secrets, est défini sur une variable d'environnement Kubernetes nommée SQL_CONN (par opposition à une variable d'environnement Airflow ou Cloud Composer).
Le second secret, service-account, installe service-account.json, un fichier contenant un jeton de compte de service, dans /var/secrets/google.
Voici à quoi ressemblent les objets Secret:
Airflow 2
Airflow 1
Le nom du premier secret Kubernetes est défini dans la variable secret_env.
Ce secret est nommé airflow-secrets. Le paramètre deploy_type spécifie qu'il doit être exposé en tant que variable d'environnement. Le nom de la variable d'environnement est SQL_CONN, comme spécifié dans le paramètre deploy_target. Enfin, la valeur de la variable d'environnement SQL_CONN est définie sur la valeur de la clé sql_alchemy_conn.
Le nom du second secret Kubernetes est défini dans la variable secret_volume. Ce secret est nommé service-account. Il est exposé en tant que volume, comme spécifié dans le paramètre deploy_type. Le chemin d'accès au fichier à installer, deploy_target, est /var/secrets/google. Enfin, la clé (key) du secret stocké dans deploy_target est service-account.json.
Voici à quoi ressemble la configuration de l'opérateur :
Airflow 2
Airflow 1
Informations sur le fournisseur Kubernetes CNCF
KubernetesPodOperator est implémenté dans le fournisseur apache-airflow-providers-cncf-kubernetes.
Pour obtenir des notes de version détaillées sur le fournisseur Kubernetes CNCF, consultez le site Web du fournisseur Kubernetes CNCF.
Version 6.0.0
Dans la version 6.0.0 du package du fournisseur Kubernetes CNCF, la connexion kubernetes_default est utilisée par défaut dans KubernetesPodOperator.
Si vous avez spécifié une connexion personnalisée dans la version 5.0.0, cette connexion personnalisée est toujours utilisée par l'opérateur. Pour revenir à la connexion kubernetes_default, vous pouvez ajuster vos DAG en conséquence.
Version 5.0.0
Cette version introduit quelques modifications non rétrocompatibles par rapport à la version 4.4.0. Les plus importantes concernent la connexion kubernetes_default, qui n'est pas utilisée dans la version 5.0.0.
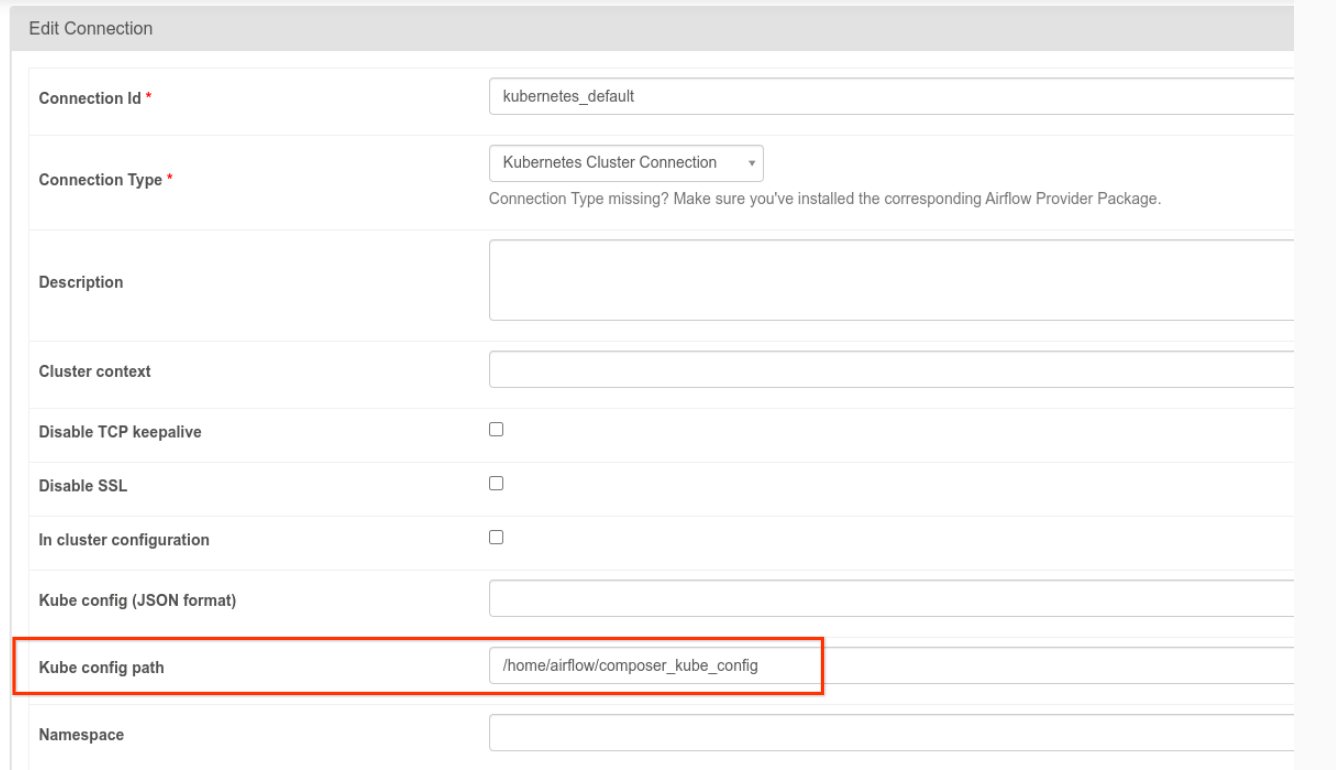
- La connexion
kubernetes_defaultdoit être modifiée. Le chemin d'accès à la configuration Kubernetes doit être défini sur/home/airflow/composer_kube_config(comme illustré dans la figure suivante). Vous pouvez également ajouterconfig_fileà la configuration KubernetesPodOperator (comme indiqué dans l'exemple de code suivant).
- Modifiez le code d'une tâche à l'aide de KubernetesPodOperator comme suit:
KubernetesPodOperator(
# config_file parameter - can be skipped if connection contains this setting
config_file="/home/airflow/composer_kube_config",
# definition of connection to be used by the operator
kubernetes_conn_id='kubernetes_default',
...
)
Pour en savoir plus sur la version 5.0.0, consultez les notes de version du fournisseur Kubernetes CNCF.
Dépannage
Cette section fournit des conseils pour résoudre les problèmes courants liés à KubernetesPodOperator:
Afficher les journaux
Pour résoudre les problèmes, vous pouvez consulter les journaux dans l'ordre suivant:
Journaux de tâches Airflow:
Dans la console Google Cloud, accédez à la page Environnements.
Dans la liste des environnements, cliquez sur le nom de votre environnement. La page Détails de l'environnement s'ouvre.
Accédez à l'onglet DAG.
Cliquez sur le nom du DAG, puis sur l'exécution du DAG pour afficher les détails et les journaux.
Journaux du programmeur Airflow:
Accédez à la page Détails de l'environnement.
Accédez à l'onglet Journaux.
Inspectez les journaux du planificateur Airflow.
Journaux des pods dans la console Google Cloud, sous les charges de travail GKE. Ces journaux incluent le fichier YAML de définition des pods, les événements des pods et les détails des pods.
Codes de retour non nuls
Lorsque vous utilisez KubernetesPodOperator (et GKEStartPodOperator), le code de retour du point d'entrée du conteneur détermine si la tâche est considérée comme réussie ou non. Les codes de retour non nuls indiquent un échec.
Un schéma courant consiste à exécuter un script shell comme point d'entrée du conteneur pour regrouper plusieurs opérations dans le conteneur.
Si vous écrivez un script de ce type, nous vous recommandons d'inclure la commande set -e en haut du script afin que les commandes ayant échoué dans le script arrêtent le script et propagent l'échec à l'instance de tâche Airflow.
Délais d'inactivité des pods
Le délai d'inactivité par défaut de KubernetesPodOperator est de 120 secondes, ce qui signifie que ce délai peut être dépassé avant que des images volumineuses ne puissent être téléchargées. Vous pouvez augmenter le délai d'inactivité en modifiant le paramètre startup_timeout_seconds lorsque vous créez KubernetesPodOperator.
Lorsqu'un pod expire, le journal spécifique à la tâche est disponible dans l'interface utilisateur d'Airflow. Exemple :
Executing <Task(KubernetesPodOperator): ex-all-configs> on 2018-07-23 19:06:58.133811
Running: ['bash', '-c', u'airflow run kubernetes-pod-example ex-all-configs 2018-07-23T19:06:58.133811 --job_id 726 --raw -sd DAGS_FOLDER/kubernetes_pod_operator_sample.py']
Event: pod-name-9a8e9d06 had an event of type Pending
...
...
Event: pod-name-9a8e9d06 had an event of type Pending
Traceback (most recent call last):
File "/usr/local/bin/airflow", line 27, in <module>
args.func(args)
File "/usr/local/lib/python2.7/site-packages/airflow/bin/cli.py", line 392, in run
pool=args.pool,
File "/usr/local/lib/python2.7/site-packages/airflow/utils/db.py", line 50, in wrapper
result = func(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/airflow/models.py", line 1492, in _run_raw_task
result = task_copy.execute(context=context)
File "/usr/local/lib/python2.7/site-packages/airflow/contrib/operators/kubernetes_pod_operator.py", line 123, in execute
raise AirflowException('Pod Launching failed: {error}'.format(error=ex))
airflow.exceptions.AirflowException: Pod Launching failed: Pod took too long to start
Un dépassement du délai d'inactivité d'un pod peut également se produire lorsque le compte de service Cloud Composer ne dispose pas des autorisations IAM nécessaires pour effectuer la tâche en question. Pour vérifier cela, examinez les erreurs au niveau du pod à l'aide des tableaux de bord GKE, afin de consulter les journaux de votre charge de travail en question, ou utilisez Cloud Logging.
Échec de l'établissement d'une nouvelle connexion
La mise à niveau automatique est activée par défaut dans les clusters GKE. Si un pool de nœuds se trouve dans un cluster en cours de mise à niveau, le message d'erreur suivant peut s'afficher :
<Task(KubernetesPodOperator): gke-upgrade> Failed to establish a new
connection: [Errno 111] Connection refused
Pour vérifier si votre cluster effectue une mise à niveau, accédez à la page Clusters Kubernetes dans la console Google Cloud, puis recherchez l'icône de chargement à côté du nom du cluster de votre environnement.