Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
このページでは、環境の規模とパフォーマンスのパラメータをプロジェクトのニーズに合わせて調整し、環境で活用されていないリソースのパフォーマンスを向上させ、コストを削減する方法について説明します。
スケーリングと最適化に関するその他のページ:
- 環境のスケーリングの詳細については、環境をスケーリングするをご覧ください。
- 環境をスケールする仕組みについては、環境のスケーリングをご覧ください。
- 主要な環境指標のモニタリングに関するチュートリアルについては、主要な指標で環境の健全性とパフォーマンスをモニタリングするをご覧ください。
最適化プロセスの概要
環境のパラメータを変更すると、環境のパフォーマンスのさまざまな側面に影響する可能性があります。環境を反復処理で最適化することをおすすめします。
- 環境のプリセットで開始します。
- DAG を実行します。
- 環境のパフォーマンスをモニタリングします。
- 環境の規模とパフォーマンス パラメータを調整して、前の手順を繰り返します。
環境のプリセットで開始する
Google Cloud コンソールで環境を作成するときは、3 つの環境プリセットのいずれかを選択できます。これらのプリセットでは、環境の初期スケールとパフォーマンス構成が設定されます。環境を作成した後に、プリセットで指定されたすべてのスケールとパフォーマンスのパラメータを変更できます。
次の見積もりに基づいて、いずれかのプリセットを使用して始めることをおすすめします。
- 環境にデプロイする予定の DAG の合計数
- 同時実行 DAG 実行の最大数
- 同時実行タスクの最大数
環境のパフォーマンスは、環境で実行する特定の DAG の実装によって異なります。次の表に、平均リソース使用量に基づく推定値を示します。DAG でより多くのリソースを使用すると予想される場合は、それに応じて推定値を調整します。
| 推奨のプリセット | DAG の合計 | 同時実行 DAG 実行の最大数 | Max concurrent tasks |
|---|---|---|---|
| 小 | 50 | 15 | 18 |
| 中 | 250 | 60 | 100 |
| 大 | 1000 | 250 | 400 |
たとえば、環境で 40 個の DAG を実行する必要があります。すべての DAG を 1 つのアクティブなタスクそれぞれに同時に実行する必要があります。この環境では、同時に実行する DAG の実行とタスクの最大数が Small プリセットの推奨推定値を超えるため、Medium プリセットが使用されます。
DAG を実行します
環境が作成されたら、そこに DAG をアップロードします。DAG を実行し、環境のパフォーマンスをモニタリングします。
DAG の実際のアプリケーションを反映したスケジュールで DAG を実行することをおすすめします。たとえば、複数の DAG を同時に実行する場合は、これらの DAG がすべて同時に実行されているときに環境のパフォーマンスを確認してください。
環境のパフォーマンスをモニタリングする
このセクションでは、Cloud Composer 2 の最も一般的な容量とパフォーマンスのチューニングについて説明します。パフォーマンスに関する最も一般的な考慮事項を最初に説明します。そのため、このガイドの詳細な手順に従うことをおすすめします。
Monitoring ダッシュボードに移動する
環境のモニタリング ダッシュボードで、環境のパフォーマンス指標をモニタリングできます。
環境の Monitoring ダッシュボードに移動するには:
Google Cloud Console で [環境] ページに移動します。
環境の名前をクリックします。
[Monitoring] タブに移動します。
スケジューラの CPU とメモリの指標をモニタリングする
Airflow スケジューラの CPU とメモリの指標は、スケジューラのパフォーマンスが Airflow の全体的なパフォーマンスのボトルネックになっているかどうかを確認するのに役立ちます。
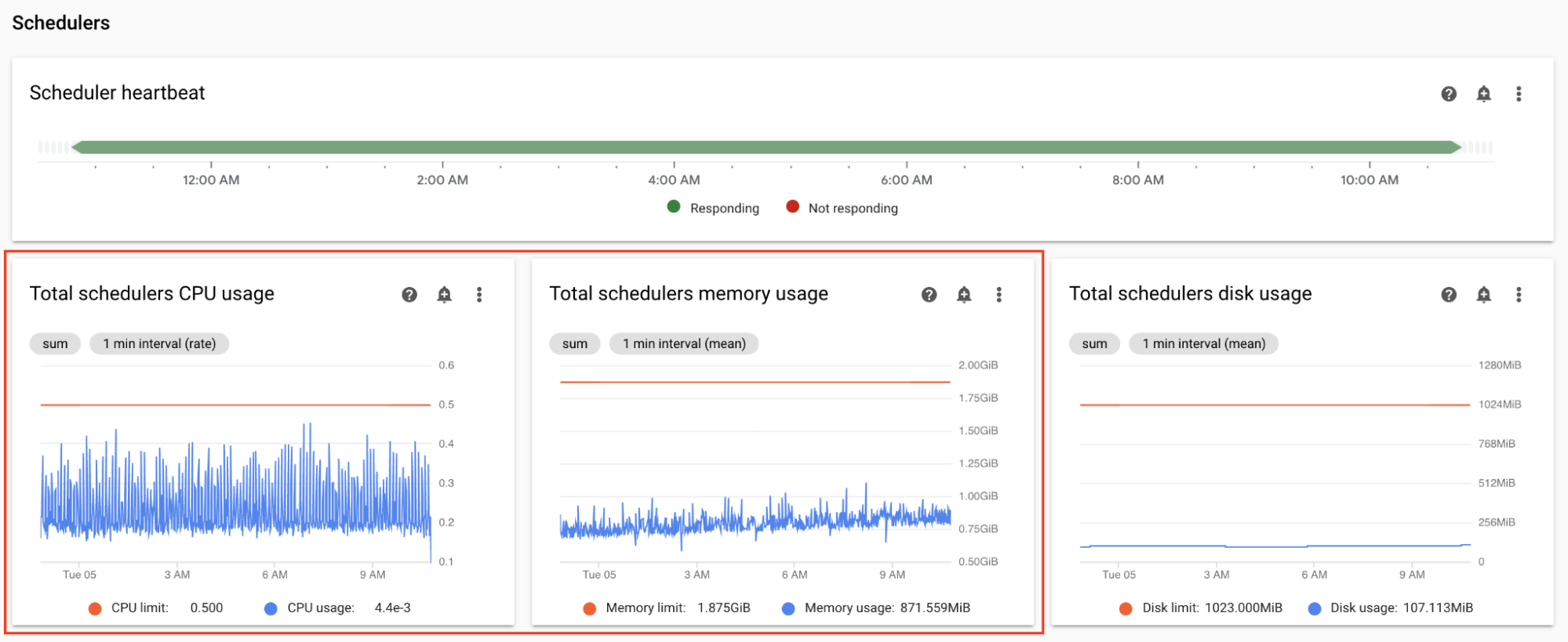
Monitoring ダッシュボードの [スケジューラ] セクションで、環境の Airflow スケジューラのグラフを確認します。
- スケジューラの CPU 使用率の合計
- スケジューラのメモリ使用量の合計
モニタリングに基づいて調整します。
スケジューラの CPU 使用率が常に 30%~35% を下回る場合は、次のことをおすすめします。
スケジューラの CPU 使用率が合計時間の数分以上にわたって 80% を超える場合は、次のことをおすすめします。
すべての DAG ファイルの合計解析時間をモニタリングする
スケジューラは、DAG 実行のスケジュールを設定する前に DAG を解析します。DAG の解析に時間がかかる場合、スケジューラの容量を消費して、DAG 実行のパフォーマンスが低下する可能性があります。
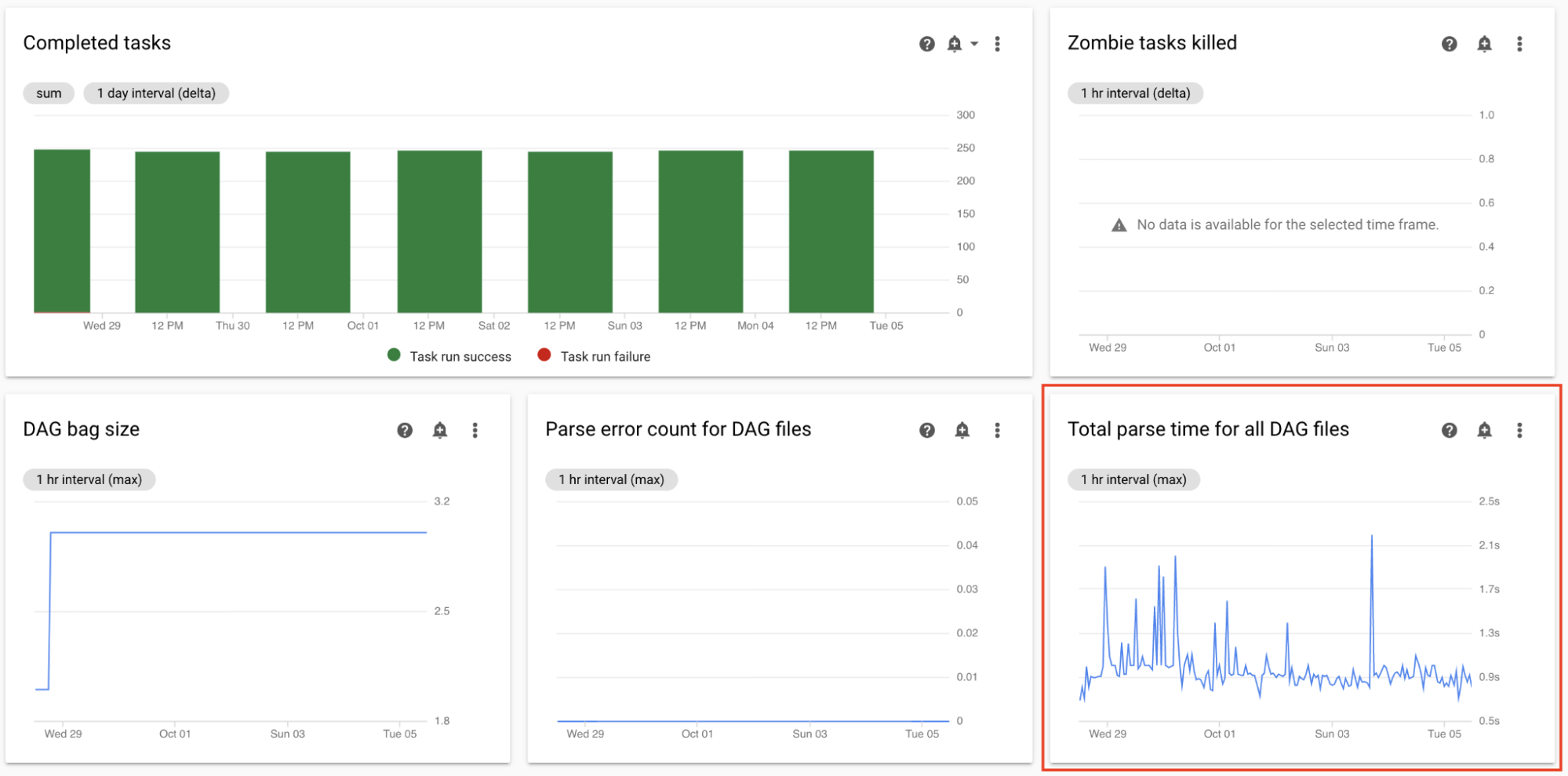
Monitoring ダッシュボードの [DAG 統計] セクションで、合計 DAG 解析時間のグラフを確認します。
数値が約 10 秒を超える場合、スケジューラが DAG 解析により過負荷となり、DAG を効果的に実行できない可能性があります。Airflow のデフォルトの DAG 解析頻度は 30 秒です。DAG の解析時間がこのしきい値を超えると、解析サイクルが重複し始め、その後スケジューラの容量を使い切ります。
モニタリング結果により、次のように対応してください。
- DAG(Python の依存関係を含む)を簡素化します。
- DAG ファイルの解析間隔を増やします。DAG ディレクトリのリスト間隔を長くします。
- スケジューラの数を増やします。
- スケジューラの CPU を増やします。
ワーカー Pod の強制排除のモニタリング
Pod のエビクションは、環境内のクラスタ内の特定の Pod がリソース上限に達すると発生します。
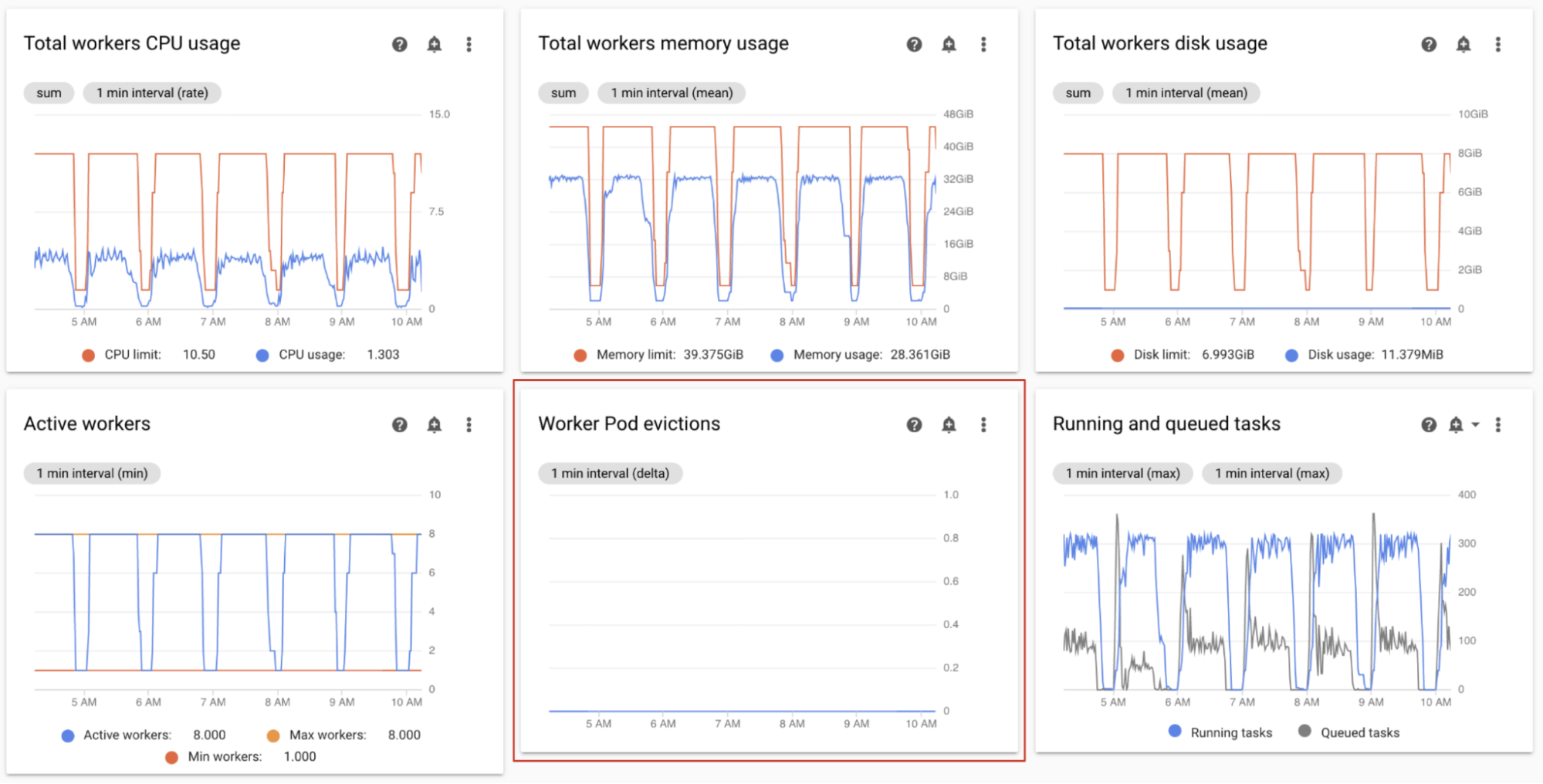
Airflow ワーカー Pod が強制排除されると、その Pod で実行されているすべてのタスク インスタンスは中断され、後で Airflow によって失敗としてマークされます。
ワーカー Pod 強制排除の問題の多くは、ワーカーのメモリ不足が原因で発生します。
Monitoring ダッシュボードの [ワーカー] セクションで、環境のワーカー Pod 強制排除のグラフを確認します。
[ワーカーの合計メモリ使用量] グラフには、環境の全体的な視点が表示されます。環境レベルでメモリ使用率が正常な場合でも、単一のワーカーはメモリ制限を超えることがあります。
モニタリング結果により、次のように対応してください。
- ワーカーで使用可能なメモリを増やします。
- ワーカーの同時実行を減らします。これにより、単一のワーカーが一度に処理するタスクが少なくなります。これにより、より多くのメモリまたはストレージが個々のタスクに提供されます。ワーカーの同時実行を変更する場合は、ワーカーの最大数を増やすこともできます。 このように、環境で一度に処理できるタスクの数は同じままです。たとえば、ワーカーの同時実行数を 12 から 6 に減らす場合は、ワーカーの最大数を 2 倍にします。
アクティブなワーカーをモニタリングする
環境内のワーカーの数は、キューに入れられたタスクに応じて自動的にスケーリングします。
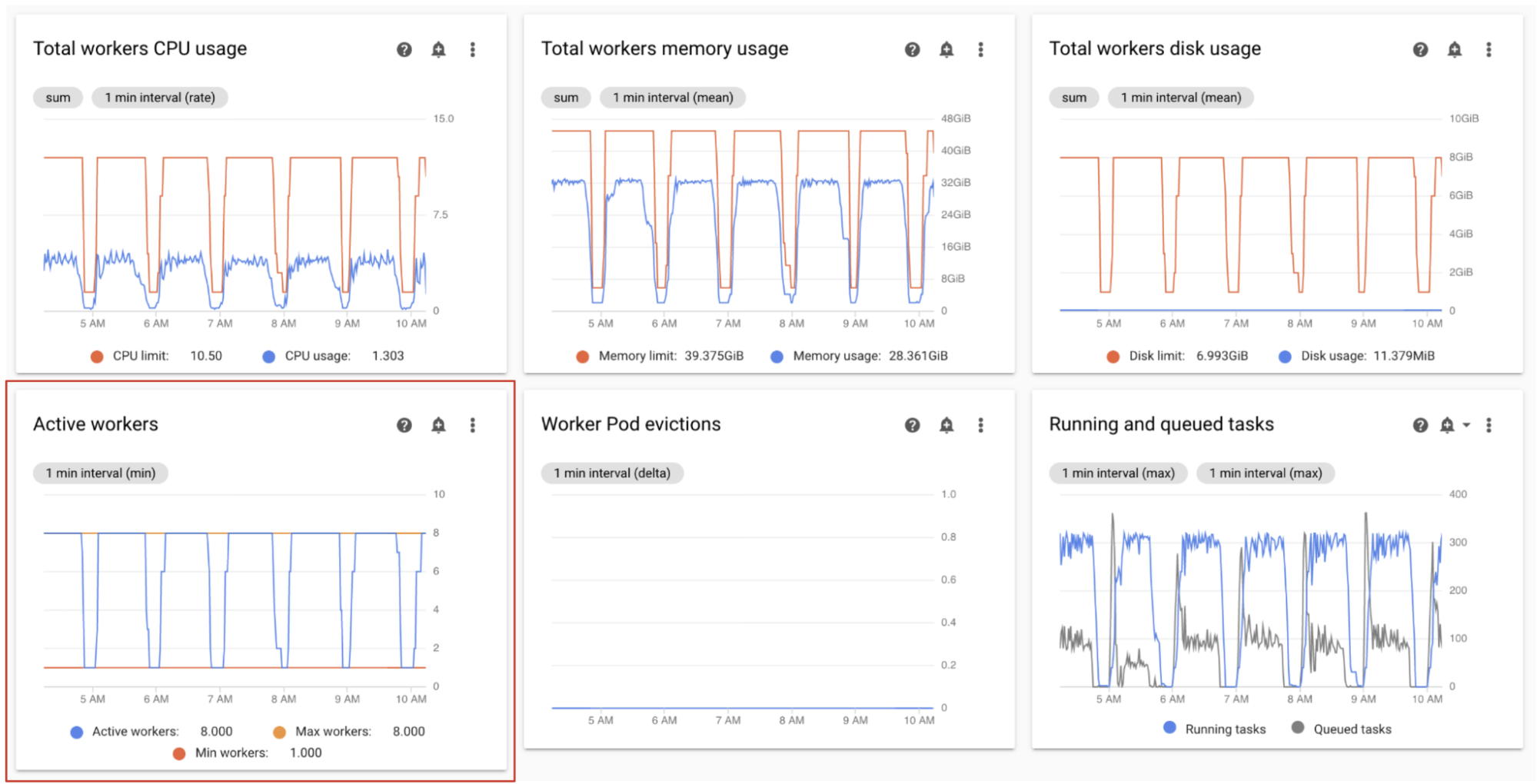
Monitoring ダッシュボードの [ワーカー] セクションで、アクティブなワーカーの数とキュー内のタスク数のグラフを確認します。
- アクティブ ワーカー数
- Airflow タスク
モニタリングに基づいて調整します。
- 環境がワーカーの上限に頻繁に到達すると同時に、Celery キュー内のタスクの数が継続的に多い場合は、ワーカーの最大数を増やすことをおすすめします。
タスク間のスケジューリングの遅延が長いにもかかわらず、環境がワーカーの最大数にスケールアップされない場合、Airflow の設定によってスロットルが抑制され、Cloud Composer メカニズムが環境をスケーリングできないようにしている可能性があります。Cloud Composer 2 環境は Celery キュー内のタスク数に基づいてスケーリングするため、キューへの移動中にタスクがスロットルされないように Airflow を構成します。
- ワーカーの同時実行を増やします。ワーカーの同時実行数は、予想される同時実行タスクの最大数より大きい、環境内のワーカーの最大数で割った値に設定する必要があります。
- 1 つの DAG で多数のタスクを同時に実行している場合、DAG の同時実行を増やします。これにより、DAG ごとの実行中のタスク インスタンスの最大数に達する可能性があります。
- DAG あたりの最大アクティブ実行数を増やします。同じ DAG を複数回並行して実行した場合、DAG ごとの最大アクティブ実行回数制限に達したため、Airflow が実行をスロットリングする可能性があります。
ワーカーの CPU とメモリ使用量をモニタリングする
環境内のすべてのワーカーで集計された CPU とメモリの合計使用量をモニタリングして、Airflow ワーカーが環境のリソースを適切に使用しているかどうかを確認します。
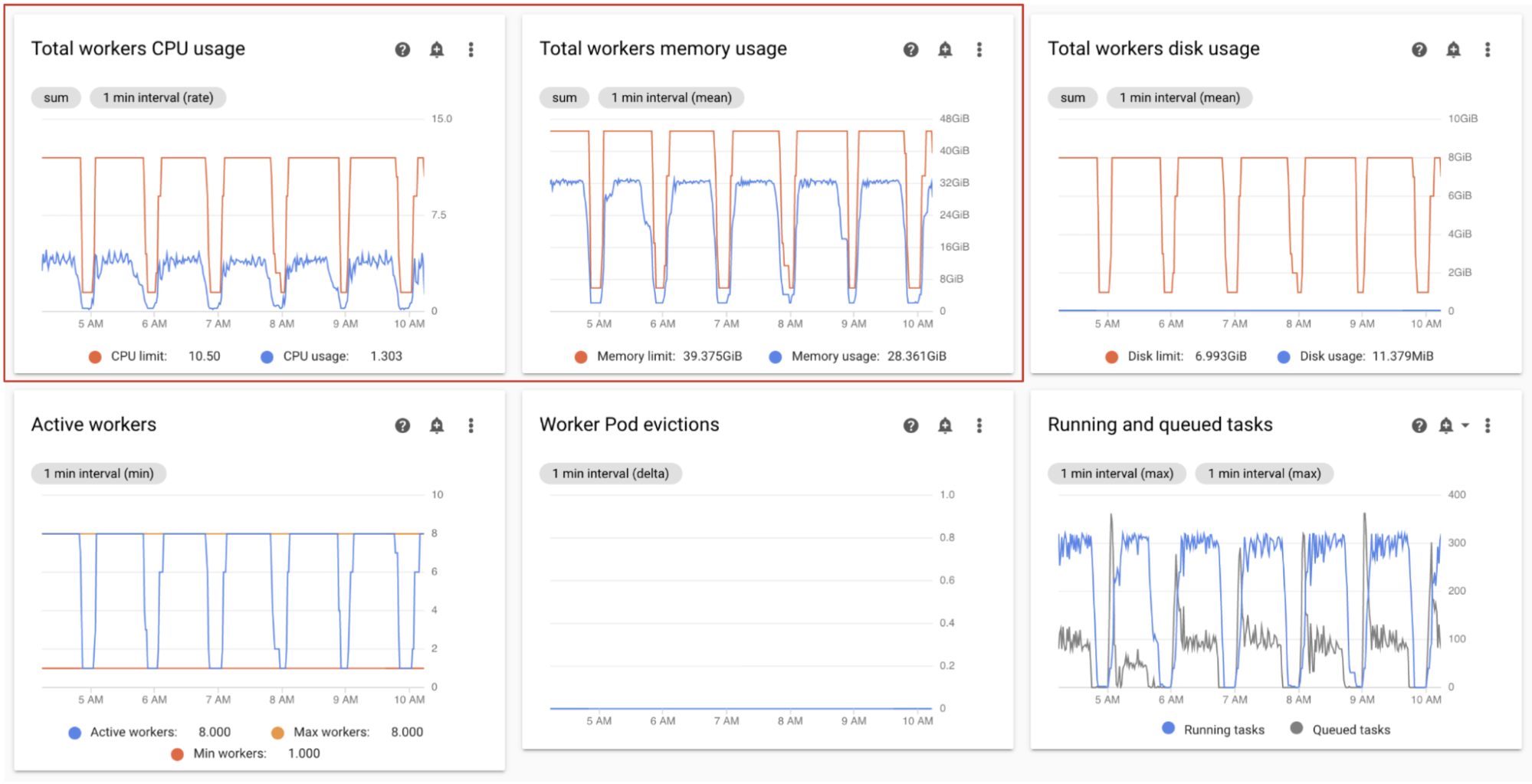
Monitoring ダッシュボードの [ワーカー] セクションで、Airflow ワーカーによる CPU とメモリ使用量のグラフを確認します。
- ワーカーの合計 CPU 使用率
- ワーカーの合計メモリ使用量
これらのグラフはリソースの合計使用量を表します。集計ビューに予備容量が示されていても、個々のワーカーは容量上限に達している可能性があります。
モニタリングに基づいて調整します。
- ワーカーのメモリ使用量が上限に近づくと、ワーカー Pod の強制排除が発生する可能性があります。この問題を解決するには、ワーカーメモリを増やします。
- メモリ使用量が上限と比較して最小で、ワーカー Pod の強制排除がない場合は、ワーカーメモリを減少させることをおすすめします。
ワーカーの CPU 使用率が上限に近づいている(合計時間の数パーセントで 80% を超えている)場合は、次のような処理を行います。
- ワーカーの数を増やします。これにより、特定のワークロードにプロビジョニングされた容量を環境でより細かく制御できます。
- 個々のタスクでより高い CPU 割り当てが必要な場合、ワーカーの CPU を増やすかワーカーの同時実行を減らします。それ以外の場合は、ワーカー数を増やすことをおすすめします。
実行中のタスクとキューに入れられたタスクをモニタリングする
キューに入れられたタスクと実行中のタスクの数をモニタリングして、スケジューリング プロセスの効率を確認できます。
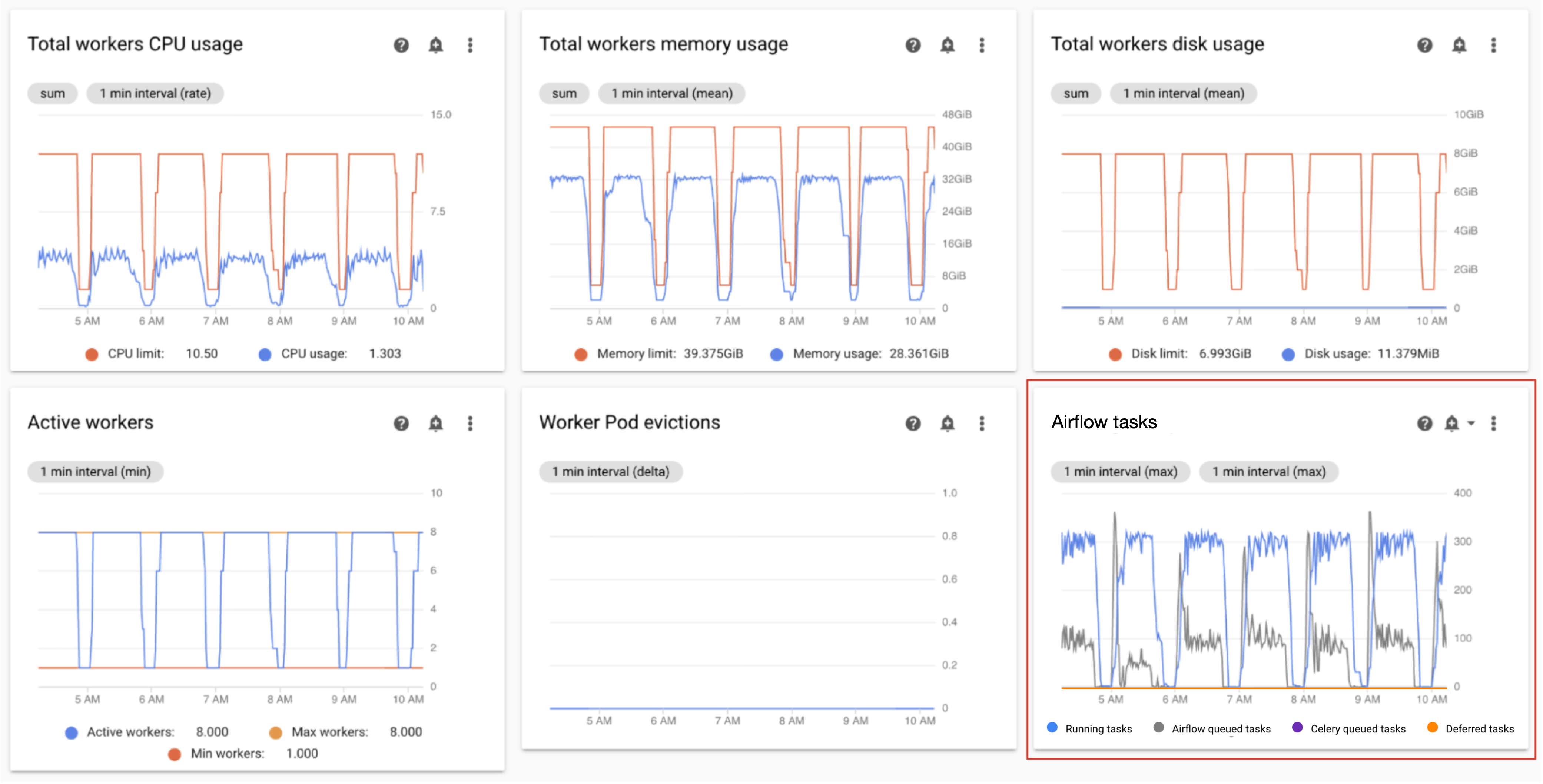
Monitoring ダッシュボードの [ワーカー] セクションで、環境の Airflow タスクのグラフを確認します。
キュー内のタスクは、ワーカーによって実行されるのを待機しています。環境にキューに入ったタスクがある場合、環境内のワーカーが他のタスクの実行中であることを意味する場合があります。
一部のキューイングは、特に処理のピーク時の環境に存在します。ただし、キューに入れられたタスクが多い場合や、グラフの傾向が増大している場合は、ワーカーがタスクを処理するのに十分な容量がないか、Airflow がタスクの実行をスロットリングしている可能性があります。
キューに入れられたタスクの数は通常、実行中のタスクの数が最大レベルに達するとモニタリングされます。
両方の問題に対処するには:
データベースの CPU とメモリ使用量をモニタリングする
Airflow データベースのパフォーマンスの問題は、DAG の全体的な実行の問題の原因になる場合があります。 通常、ストレージは必要に応じて自動的に拡張されるため、データベース ディスクの使用は問題になりません。
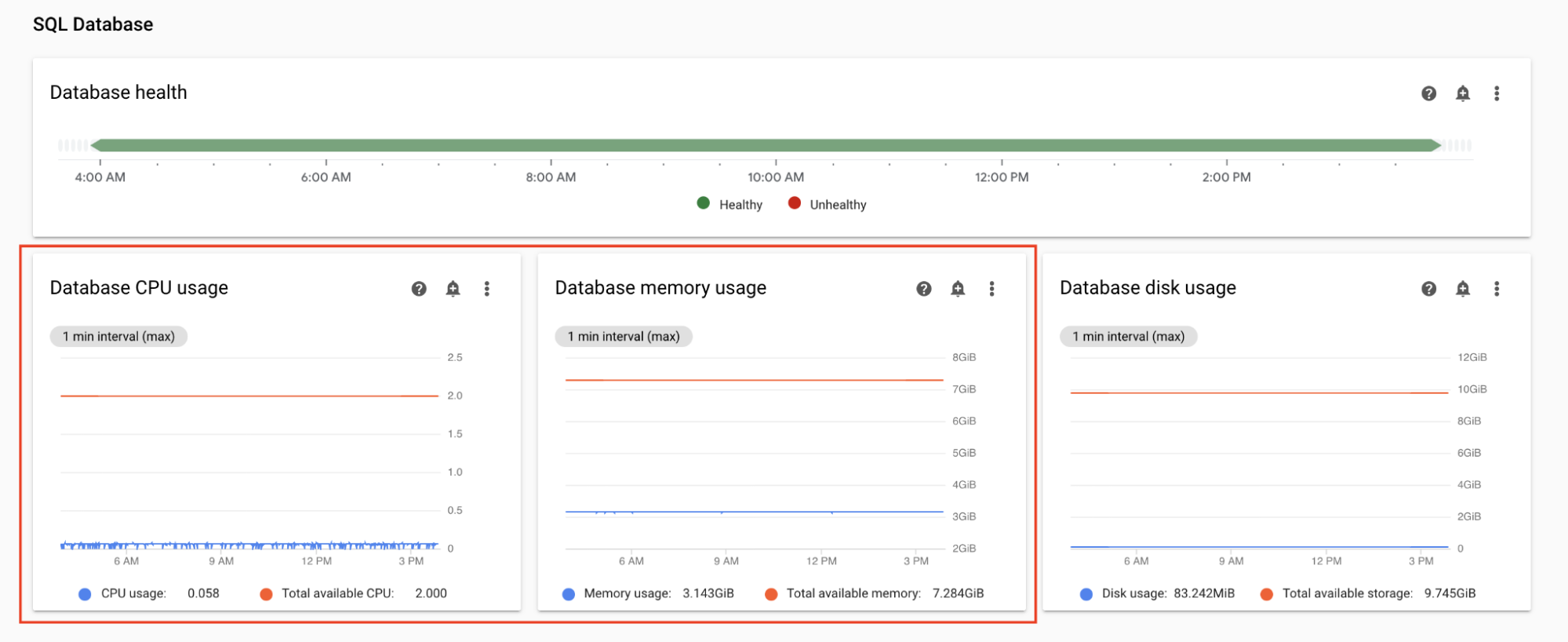
Monitoring ダッシュボードの [SQL データベース] セクションで、Airflow データベースによる CPU とメモリ使用量のグラフを確認します。
- データベースの CPU 使用率
- データベースのメモリ使用量
合計時間の数パーセントでデータベースの CPU 使用率が 80% を超えると、データベースが過負荷状態になり、スケーリングが必要になります。
データベース サイズの設定は、ご使用の環境の環境サイズ プロパティで制御されます。データベースをスケールアップまたはスケールダウンするには、別の階層(Small、Medium、Large)に環境サイズを変更します。環境のサイズを増やすと、環境の費用が増加します。
タスクのスケジュール設定のレイテンシをモニタリングする
タスク間のレイテンシが想定レベルを超えている場合(20 秒以上など)、DAG の実行によって生成されたタスクの負荷を環境が処理できないことを示している可能性があります。

タスクのスケジュール設定のレイテンシ グラフは、環境の Airflow UI で確認できます。
この例では、遅延(2.5 秒と 3.5 秒)が許容範囲内に収まりますが、レイテンシが大幅に高くなる場合、以下の可能性があります。
- スケジューラは過負荷状態です。潜在的な問題の兆候がないか、スケジューラの CPU とメモリをモニタリングします。
- Airflow 構成オプションでは実行がスロットリングされます。ワーカーの同時実行を増やす、DAG の同時実行を増やす、DAG ごとの最大実行数を増やすことを検討してください。
- タスクを実行するための十分なワーカーがありません。ワーカーの最大数を増やすことを検討してください。
ウェブサーバーの CPU とメモリをモニタリングする
Airflow ウェブサーバーのパフォーマンスは Airflow UI に影響します。ウェブサーバーが過負荷になるのは一般的ではありません。過負荷が発生する場合、Airflow UI のパフォーマンスは低下する可能性がありますが、DAG 実行のパフォーマンスには影響しません。
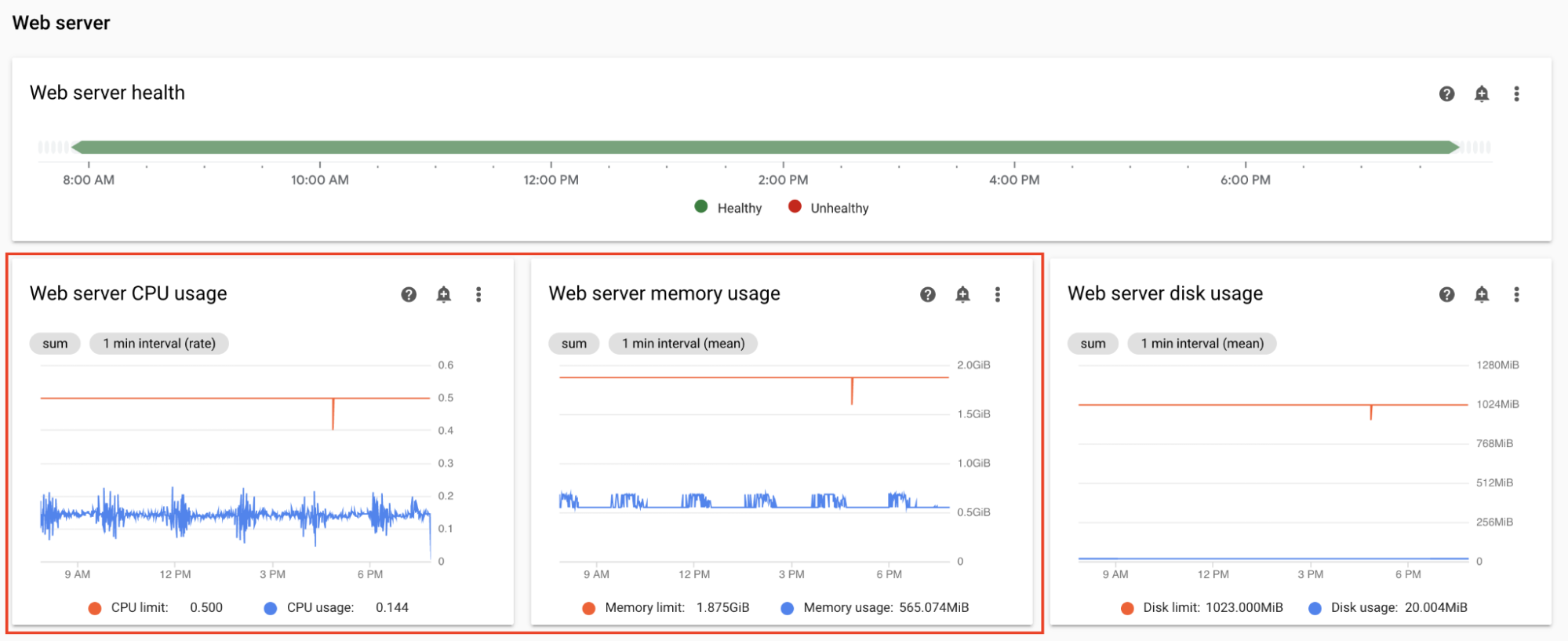
Monitoring ダッシュボードの [ウェブサーバー] セクションで、Airflow ウェブサーバーのグラフをモニタリングします。
- ウェブサーバーの CPU 使用率
- ウェブサーバーのメモリ使用量
モニタリングに基づく:
- 時間の数パーセントでウェブサーバーの CPU 使用率が、80% を超えている場合、ウェブサーバーの CPU を増やすことを検討してください。
- ウェブサーバーのメモリ使用量が多いことに気付いた場合は、ウェブサーバーにメモリを追加することを検討してください。
環境のスケールとパフォーマンス パラメータを調整する
スケジューラの数を変更する
スケジューラの数を調整すると、スケジューラの容量と Airflow スケジューリングの復元力が改善されます。
スケジューラの数を増やすと、Airflow データベースとの間のトラフィックが増加します。ほとんどのシナリオでは、Airflow スケジューラを 2 つ使用することをおすすめします。3 つのスケジューラを使用する必要があるのは、特別な考慮事項がある、まれなケースのみです。3 つを超えるスケジューラを頻繁に構成すると、環境のパフォーマンスが低下することがあります。
スケジューリングの高速化が必要な場合:
- 2 つの Airflow スケジューラを構成する。
- Airflow スケジューラに、より多くの CPU とメモリのリソースを割り当てる。
- dag-dir-list-interval を増やす
- min-file-process-interval を増やす
- job-heartbeat-sec を増やす
例:
コンソール
スケジューラの数を調整するの手順に沿って、環境に必要なスケジューラの数を設定します。
gcloud
スケジューラの数を調整するの手順に沿って、環境に必要なスケジューラの数を設定します。
次の例では、スケジューラの数を 2 に設定しています。
gcloud composer environments update example-environment \
--scheduler-count=2
Terraform
スケジューラの数を調整するの手順に沿って、環境に必要なスケジューラの数を設定します。
次の例では、スケジューラの数を 2 に設定しています。
resource "google_composer_environment" "example-environment" {
# Other environment parameters
config {
workloads_config {
scheduler {
count = 2
}
}
}
}
スケジューラの CPU とメモリの変更
CPU パラメータとメモリ パラメータは、環境内の各スケジューラ用です。たとえば、環境に 2 つのスケジューラがある場合、合計容量は指定された CPU 数とメモリ数の 2 倍になります。
コンソール
ワーカー、スケジューラ、ウェブサーバーのスケール、パフォーマンス パラメータを調整するの手順に従って、スケジューラの CPU とメモリを設定します。
gcloud
ワーカー、スケジューラ、ウェブサーバーのスケール、パフォーマンス パラメータを調整するの手順に従って、スケジューラの CPU とメモリを設定します。
次の例では、スケジューラの CPU とメモリを変更します。必要に応じて、CPU 属性またはメモリ属性のみを指定できます。
gcloud composer environments update example-environment \
--scheduler-cpu=0.5 \
--scheduler-memory=3.75
Terraform
ワーカー、スケジューラ、ウェブサーバーのスケール、パフォーマンス パラメータを調整するの手順に従って、スケジューラの CPU とメモリを設定します。
次の例では、スケジューラの CPU とメモリを変更します。必要に応じて、CPU 属性またはメモリ属性を省略できます。
resource "google_composer_environment" "example-environment" {
# Other environment parameters
config {
workloads_config {
scheduler {
cpu = "0.5"
memory_gb = "3.75"
}
}
}
}
ワーカーの最大数を変更する
ワーカーの最大数を増やすと、必要に応じて環境をより多くのワーカーに自動的にスケーリングできます。
ワーカーの最大数を減らすと、環境の最大容量は減りますが、環境の費用を削減するのにも役立ちます。
例:
コンソール
ワーカーの最小数と最大数を調整するの手順に従って、環境に必要なワーカーの最大数を設定します。
gcloud
ワーカーの最小数と最大数を調整するの手順に従って、環境に必要なワーカーの最大数を設定します。
次の例では、ワーカーの最大数を 6 に設定しています。
gcloud composer environments update example-environment \
--max-workers=6
Terraform
ワーカーの最小数と最大数を調整するの手順に従って、環境に必要なワーカーの最大数を設定します。
次の例では、ワーカーの最大数を 6 に設定しています。
resource "google_composer_environment" "example-environment" {
# Other environment parameters
config {
workloads_config {
worker {
max_count = "6"
}
}
}
}
ワーカーの CPU とメモリを変更する
ワーカー使用状況のグラフがメモリ使用率が非常に低い場合は、ワーカーメモリを減らすと役立ちます。
ワーカーメモリを増やすと、ワーカーがより多くのタスクを同時に処理したり、メモリ使用量の多いタスクを処理したりできます。ワーカー Pod の強制排除の問題に対処できる可能性があります。
ワーカー CPU を減らすと、ワーカー CPU リソースグラフでワーカーの CPU リソースが極めて過剰に割り当てられている場合に役立ちます。
ワーカー CPU を増やすと、ワーカーが同時により多くのタスクを処理でき、場合によってはこれらのタスクの処理時間を短縮できます。
ワーカーの CPU またはメモリを変更すると、ワーカーが再起動されます。これは、実行中のタスクに影響を与える可能性があります。DAG が実行されていない場合に実行することをおすすめします。
CPU パラメータとメモリ パラメータは、環境内の各ワーカー用です。たとえば、環境に 4 つのワーカーがある場合、合計容量は指定された CPU 数とメモリ数の 4 倍になります。
コンソール
ワーカー、スケジューラ、ウェブサーバーのスケール、パフォーマンス パラメータを調整するの手順に従って、ワーカーの CPU とメモリを設定します。
gcloud
ワーカー、スケジューラ、ウェブサーバーのスケール、パフォーマンス パラメータを調整するの手順に従って、ワーカーの CPU とメモリを設定します。
次の例では、ワーカーの CPU とメモリを変更します。必要に応じて、CPU 属性またはメモリ属性を省略できます。
gcloud composer environments update example-environment \
--worker-memory=3.75 \
--worker-cpu=2
Terraform
ワーカー、スケジューラ、ウェブサーバーのスケール、パフォーマンス パラメータを調整するの手順に従って、ワーカーの CPU とメモリを設定します。
次の例では、ワーカーの CPU とメモリを変更します。必要に応じて、CPU またはメモリ パラメータを省略できます。
resource "google_composer_environment" "example-environment" {
# Other environment parameters
config {
workloads_config {
worker {
cpu = "2"
memory_gb = "3.75"
}
}
}
}
ウェブサーバーの CPU とメモリを変更する
ウェブサーバーの使用状況グラフが示す使用率が連続して低い場合、ウェブサーバーの CPU かメモリの数を減らすと役立つ可能性があります。
ウェブサーバーのパラメータを変更すると、ウェブサーバーが再起動されます。これにより、ウェブサーバーのダウンタイムが一時的に発生します。通常の使用時間外に変更することをおすすめします。
コンソール
ワーカー、スケジューラ、ウェブサーバーのスケール、パフォーマンス パラメータを調整するの手順に従って、ウェブサーバーの CPU とメモリを設定します。
gcloud
ワーカー、スケジューラ、ウェブサーバーのスケール、パフォーマンス パラメータを調整するの手順に従って、ウェブサーバーの CPU とメモリを設定します。
次の例では、ウェブサーバーの CPU とメモリを変更します。必要に応じて、CPU 属性またはメモリ属性を省略できます。
gcloud composer environments update example-environment \
--web-server-cpu=2 \
--web-server-memory=3.75
Terraform
ワーカー、スケジューラ、ウェブサーバーのスケール、パフォーマンス パラメータを調整するの手順に従って、ウェブサーバーの CPU とメモリを設定します。
次の例では、ウェブサーバーの CPU とメモリを変更します。必要に応じて、CPU 属性またはメモリ属性を省略できます。
resource "google_composer_environment" "example-environment" {
# Other environment parameters
config {
workloads_config {
web_server {
cpu = "2"
memory_gb = "3.75"
}
}
}
}
環境サイズを変更する
環境サイズを変更すると、Airflow データベースや Airflow キューなどの Cloud Composer バックエンド コンポーネントの容量が変更されます。
- データベースの使用状況の指標が十分に活用されていない場合は、環境のサイズをより小さなサイズ(大から中、中から小など)に変更することを検討してください。
Airflow データベースの使用率が高い場合は、環境のサイズを大きくすることを検討してください。
コンソール
環境のサイズを調整するの手順に沿って、環境のサイズを設定します。
gcloud
環境のサイズを調整するの手順に沿って、環境のサイズを設定します。
次の例では、環境のサイズを Medium に変更しています。
gcloud composer environments update example-environment \
--environment-size=medium
Terraform
環境のサイズを調整するの手順に沿って、環境のサイズを設定します。
次の例では、環境のサイズを Medium に変更しています。
resource "google_composer_environment" "example-environment" {
# Other environment parameters
config {
environment_size = "medium"
}
}
DAG ディレクトリの一覧表示の間隔の変更
DAG ディレクトリの一覧表示間隔を増やすと、環境バケット内での新しい DAG の検出に関連するスケジューラの負荷が軽減されます。
- 新しい DAG をあまりデプロイしない場合、この間隔を長くすることを検討してください。
- 新しくデプロイされた DAG ファイルへの Airflow の反応を速くしたい場合、この間隔を短くすることを検討してください。
このパラメータを変更するには、次の Airflow 構成オプションをオーバーライドします。
| セクション | キー | 値 | 備考 |
|---|---|---|---|
scheduler |
dag_dir_list_interval |
リスティング間隔の新しい値 | デフォルト値は秒単位で 120 です。 |
DAG ファイルの解析間隔の変更
DAG ファイルの解析間隔を長くすると、DAG バッグ内の DAG の継続的な解析に関連するスケジューラの負荷が軽減されます。
変更の頻度が低い DAG が多数存在する場合や、スケジューラの負荷が高い場合は、この間隔を長くすることを検討してください。
このパラメータを変更するには、次の Airflow 構成オプションをオーバーライドします。
| セクション | キー | 値 | 備考 |
|---|---|---|---|
scheduler |
min_file_process_interval |
DAG 解析間隔の新しい値 | デフォルト値は秒単位で 30 です。 |
ワーカーの同時実行
同時実行のパフォーマンスと環境の自動スケーリング機能は、次の 2 つの設定に関連づけられています。
- Airflow ワーカーの最小数
[celery]worker_concurrencyパラメータ
Cloud Composer によって提供されるデフォルト値はほとんどのユースケースに最適ですが、環境によってはカスタム調整が役立つ場合があります。
ワーカーの同時実行のパフォーマンスに関する考慮事項
[celery]worker_concurrency パラメータは、1 つのワーカーがタスクキューから受け取ることができるタスクの数を定義します。タスクの実行速度は、ワーカーの CPU、メモリ、作業自体の種類など、複数の要因によって決まります。
ワーカーの自動スケーリング
Cloud Composer はタスクキューをモニタリングして、待機しているタスクを請け負う追加のワーカーを生成します。[celery]worker_concurrency を高い値に設定すると、すべてのワーカーが大量のタスクを選択できるようになるため、特定の状況では、キューがいっぱいにならないことがあり、自動スケーリングがトリガーされません。
たとえば、2 つの Airflow ワーカーがあり、[celery]worker_concurrency が 100 に設定され、キューにタスクが 200 個ある Cloud Composer 環境では、各ワーカーは 100 個のタスクを選択します。この場合、キューは空のままになり、自動スケーリングがトリガーされません。これらのタスクの完了に時間がかかると、パフォーマンスの問題が発生する可能性があります。
ただし、タスクが小さく、迅速に実行される場合、[celery]worker_concurrency の設定に高い値を指定すると、スケーリングが過剰になる可能性があります。たとえば、この環境で 300 個のタスクがキューにある場合、Cloud Composer は新しいワーカーの作成を開始します。ただし、新しいワーカーの準備ができるまでに最初の 200 個のタスクが完了した場合は、既存のワーカーが残りのタスクを選択できます。最終的には、自動スケーリングによって新しいワーカーが作成されますが、それらが選択するタスクはありません。
特殊なケースでは、[celery]worker_concurrency をピーク時のタスク実行時間とキュー内のタスク数に基づいて調整する必要があります。
- 完了に時間のかかるタスクの場合、ワーカーがキューを完全に空にできないようにする必要があります。
- 迅速に実行される小さなタスクの場合、Airflow ワーカーの最小数を増やして過剰なスケーリングを防ぎます。
タスクログの同期
Airflow ワーカーには、タスク実行ログを Cloud Storage バケットに同期するコンポーネントを備えています。1 つのワーカーで多数の同時タスクが実行されると、多数の同期リクエストが発生します。これにより、ワーカーが過負荷になり、パフォーマンスの問題が発生する可能性があります。
ログ同期トラフィック数が多いことが原因でパフォーマンスの問題が発生した場合は、[celery]worker_concurrency の値を小さくして、代わりに Airflow ワーカーの最小数を調整します。
ワーカーの同時実行を変更する
このパラメータを変更すると、1 つのワーカーが同時に実行できるタスクの数を調整できます。
たとえば、CPU が 0.5 のワーカーは、一般的に 6 つの同時タスクを処理できます。1 つの環境に 3 つのワーカーがある場合、最大 18 個の同時タスクを処理できます。
キューで待機しているタスクがあり、同時に、ワーカーの CPU とメモリ使用率が低い場合は、このパラメータを大きくします。
Pod の強制排除が発生する場合は、このパラメータを小さくします。これにより、1 つのワーカーが処理しようとするタスクの数を減らすことができます。代わりに、ワーカーのメモリを増やすこともできます。
ワーカーの同時実行のデフォルト値は次のようになります。
- Airflow 2.6.3 以降のバージョンでは、
32、12 * worker_CPU、6 * worker_memoryのうちの最小値。 - 2.6.3 より前の Airflow バージョン では、
32、12 * worker_CPU、8 * worker_memoryのうちの最小値。 - 2.3.3 より前の Airflow バージョンでは、
12 * worker_CPU。
worker_CPU 値は、1 つのワーカーに割り当てられる CPU の数です。worker_memory 値は、1 つのワーカーに割り当てられるメモリの量です。たとえば、環境内のワーカーがそれぞれ 0.5 CPU と 4 GB のメモリを使用する場合、ワーカーの同時実行は 6 に設定されます。ワーカーの同時実行の値は、環境内のワーカー数に依存しません。
このパラメータを変更するには、次の Airflow 構成オプションをオーバーライドします。
| セクション | キー | 値 |
|---|---|---|
celery |
worker_concurrency |
ワーカーの同時実行の新しい値 |
DAG の同時実行を変更する
DAG の同時実行は、各 DAG で同時に実行できるタスク インスタンスの最大数を定義します。DAG で多数の同時実行タスクを実行する場合は、同時実行数を増やします。この設定が低いと、スケジューラはキューへのタスクの追加を遅らせます。これにより、環境の自動スケーリングの効率も低下します。
このパラメータを変更するには、次の Airflow 構成オプションをオーバーライドします。
| セクション | キー | 値 | 備考 |
|---|---|---|---|
core |
max_active_tasks_per_dag |
DAG の同時実行の新しい値 | デフォルト値は 16 です。 |
DAG ごとの最大アクティブ実行数を増やす
この属性は、DAG あたりのアクティブな DAG 実行の最大数を定義します。同じ DAG を複数回(たとえば、異なる入力引数を使用して)同時実行する必要がある場合、この属性を使用すると、スケジューラはそのような実行を並行して開始できます。
このパラメータを変更するには、次の Airflow 構成オプションをオーバーライドします。
| セクション | キー | 値 | 備考 |
|---|---|---|---|
core |
max_active_runs_per_dag |
DAG ごとの最大アクティブ実行数の新しい値 | デフォルト値は 25 です。 |