Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Questa pagina descrive come monitorare l'integrità e le prestazioni complessive dell'ambiente Cloud Composer con le metriche chiave nella dashboard di monitoraggio.
Introduzione
Questo tutorial si concentra sulle metriche di monitoraggio chiave di Cloud Composer che possono fornire una buona panoramica dell'integrità e delle prestazioni a livello di ambiente.
Cloud Composer offre più metriche che descrivono lo stato generale dell'ambiente. Le linee guida per il monitoraggio in questo tutorial si basano sulle metriche esposte nella dashboard di monitoraggio del tuo ambiente Cloud Composer.
In questo tutorial, imparerai a conoscere le metriche chiave che fungono da indicatori principali dei problemi relativi al rendimento e all'integrità del tuo ambiente, nonché le linee guida per interpretare ogni metrica in azioni correttive per mantenere l'ambiente integro. Configurerai anche regole di avviso per ogni metrica, eseguirai il DAG di esempio e utilizzerai queste metriche e questi avvisi per ottimizzare il rendimento del tuo ambiente.
Obiettivi
Costi
Questo tutorial utilizza i seguenti componenti fatturabili di Google Cloud:
Al termine di questo tutorial, puoi evitare l'addebito di ulteriori costi eliminando le risorse create. Per maggiori dettagli, vedi Pulizia.
Prima di iniziare
Questa sezione descrive le azioni necessarie prima di iniziare il tutorial.
Creare e configurare un progetto
Per questo tutorial, è necessario un Google Cloud progetto. Configura il progetto nel seguente modo:
Nella console Google Cloud , seleziona o crea un progetto:
Verifica che la fatturazione sia attivata per il tuo progetto. Scopri come verificare se la fatturazione è abilitata per un progetto.
Assicurati che l'utente del progetto Google Cloud disponga dei seguenti ruoli per creare le risorse necessarie:
- Amministratore ambienti e oggetti Storage
(
roles/composer.environmentAndStorageObjectAdmin) - Compute Admin (
roles/compute.admin) - Editor Monitoring (
roles/monitoring.editor)
- Amministratore ambienti e oggetti Storage
(
Abilitare le API per il progetto
Enable the Cloud Composer API.
Crea l'ambiente Cloud Composer
Crea un ambiente Cloud Composer 2.
Nell'ambito di questa procedura,
concedi il ruolo Cloud Composer v2 API Service Agent Extension
(roles/composer.ServiceAgentV2Ext) al service account
dell'agente di servizio Composer. Cloud Composer utilizza questo account per eseguire operazioni
nel tuo progetto Google Cloud .
Esplora le metriche chiave per l'integrità e le prestazioni a livello di ambiente
Questo tutorial si concentra sulle metriche chiave che possono fornire una buona panoramica dell'integrità e delle prestazioni complessive del tuo ambiente.
La dashboard di monitoraggio nella consoleGoogle Cloud contiene una serie di metriche e grafici che consentono di monitorare le tendenze nel tuo ambiente e identificare i problemi relativi ai componenti Airflow e alle risorse Cloud Composer.
Ogni ambiente Cloud Composer ha il proprio dashboard Monitoring.
Familiarizza con le metriche chiave riportate di seguito e individua ciascuna metrica nella dashboard Monitoring:
Nella console Google Cloud , vai alla pagina Ambienti.
Nell'elenco degli ambienti, fai clic sul nome del tuo ambiente. Viene visualizzata la pagina Dettagli ambiente.
Vai alla scheda Monitoraggio.
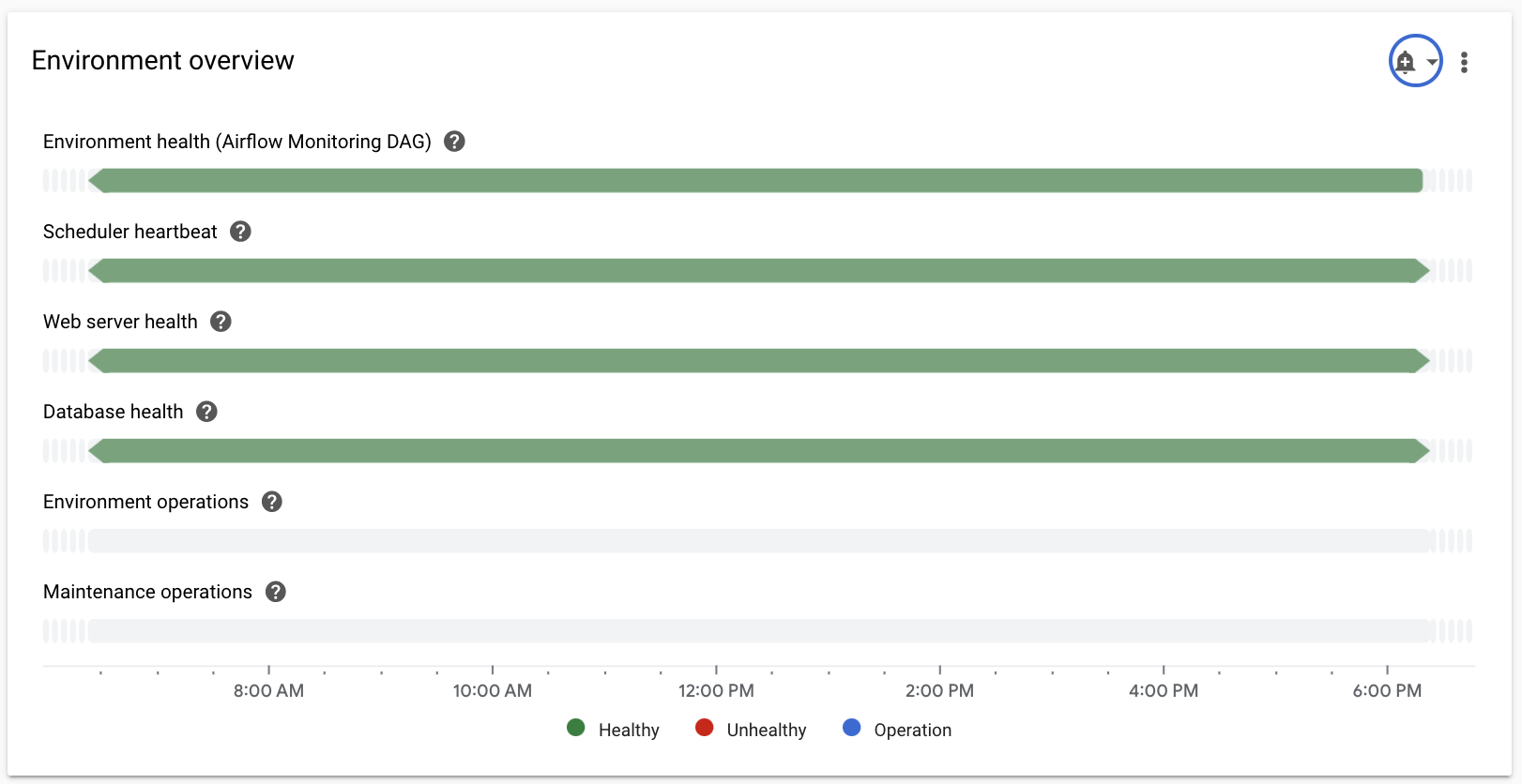
Seleziona la sezione Panoramica, individua l'elemento Panoramica ambiente nella dashboard e osserva la metrica Integrità ambiente (DAG di monitoraggio di Airflow).
Questa cronologia mostra lo stato di integrità dell'ambiente Cloud Composer. Il colore verde della barra di integrità dell'ambiente indica che l'ambiente è integro, mentre lo stato di ambiente non integro è indicato con il colore rosso.
Ogni pochi minuti, Cloud Composer esegue un DAG di liveness denominato
airflow_monitoring. Se l'esecuzione del DAG di attività termina correttamente, lo stato di integrità èTrue. Se l'esecuzione del DAG di attività non va a buon fine (ad esempio, a causa dell'espulsione del pod, della terminazione del processo esterno o della manutenzione), lo stato di integrità èFalse.
Seleziona la sezione Database SQL, individua l'elemento Integrità del database nel dashboard e osserva la metrica Integrità del database.
Questa sequenza temporale mostra lo stato della connessione all'istanza Cloud SQL del tuo ambiente. La barra verde di integrità del database indica la connettività, mentre gli errori di connessione sono indicati con il colore rosso.
Il pod di monitoraggio di Airflow esegue il ping del database periodicamente e segnala lo stato di integrità come
Truese è possibile stabilire una connessione o comeFalsein caso contrario.
Nell'elemento Integrità del database, osserva le metriche Utilizzo CPU database e Utilizzo memoria database.
Il grafico Utilizzo CPU database indica l'utilizzo dei core CPU da parte delle istanze del database Cloud SQL del tuo ambiente rispetto al limite totale di CPU del database disponibile.
Il grafico Utilizzo della memoria del database indica l'utilizzo della memoria da parte delle istanze del database Cloud SQL del tuo ambiente rispetto al limite totale di memoria del database disponibile.
Seleziona la sezione Schedulers, individua l'elemento Scheduler heartbeat nel dashboard e osserva la metrica Scheduler heartbeat.
Questa cronologia mostra lo stato dello scheduler di Airflow. Controlla le aree rosse per identificare i problemi dello scheduler Airflow. Se il tuo ambiente ha più di uno scheduler, lo stato di heartbeat è integro finché almeno uno degli scheduler risponde.
Lo scheduler è considerato non integro se l'ultimo heartbeat è stato ricevuto più di 30 secondi (valore predefinito) prima dell'ora attuale.
Seleziona la sezione Statistiche DAG, individua l'elemento Attività zombie interrotte nella dashboard e osserva la metrica Attività zombie interrotte.
Questo grafico indica il numero di attività zombie interrotte in una piccola finestra temporale. Le attività zombie sono spesso causate dalla terminazione esterna dei processi Airflow (ad esempio quando il processo di un'attività viene interrotto).
Lo scheduler di Airflow interrompe periodicamente le attività zombie, il che si riflette in questo grafico.
Seleziona la sezione Worker, individua l'elemento Riavvii dei container worker nella dashboard e osserva la metrica Riavvii dei container worker.
- Un grafico indica il numero totale di riavvii per i singoli container worker. Un numero eccessivo di riavvii del contenitore può influire sulla disponibilità del tuo servizio o di altri servizi downstream che lo utilizzano come dipendenza.
Scopri i benchmark e le possibili azioni correttive per le metriche chiave
Il seguente elenco descrive i valori di riferimento che possono indicare problemi e fornisce azioni correttive che puoi intraprendere per risolvere questi problemi.
Integrità ambiente (DAG di monitoraggio di Airflow)
Tasso di successo inferiore al 90% in un periodo di 4 ore
Gli errori possono comportare l'eliminazione dei pod o la chiusura dei worker perché l'ambiente è sovraccarico o non funziona correttamente. Le aree rosse nella cronologia dello stato dell'ambiente di solito corrispondono alle aree rosse nelle altre barre di stato dei singoli componenti dell'ambiente. Identifica la causa principale esaminando altre metriche nel dashboard di Monitoring.
Integrità del database
Tasso di successo inferiore al 95% in un periodo di 4 ore
Gli errori indicano che ci sono problemi di connettività al database Airflow, che potrebbero essere il risultato di un arresto anomalo o di un tempo di inattività del database perché è sovraccarico (ad esempio, a causa di un elevato utilizzo di CPU o memoria o di una latenza maggiore durante la connessione al database). Questi sintomi sono più spesso causati da DAG non ottimali, ad esempio quando i DAG utilizzano molte variabili di ambiente o Airflow definite a livello globale. Identifica la causa principale esaminando le metriche di utilizzo delle risorse del database SQL. Puoi anche esaminare i log dello scheduler per errori relativi alla connettività del database.
Utilizzo di CPU e memoria del database
Più dell'80% di utilizzo medio di CPU o memoria in un periodo di 12 ore
Il database potrebbe essere sovraccarico. Analizza la correlazione tra le esecuzioni del DAG e i picchi nell'utilizzo di CPU o memoria del database.
Puoi ridurre il carico del database tramite DAG più efficienti con query e connessioni in esecuzione ottimizzate o distribuendo il carico in modo più uniforme nel tempo.
In alternativa, puoi allocare più CPU o memoria al database. Le risorse del database sono controllate dalla proprietà Dimensioni ambiente del tuo ambiente e l'ambiente deve essere scalato a dimensioni maggiori.
Heartbeat dello scheduler
Tasso di successo inferiore al 90% in un periodo di 4 ore
Assegna più risorse allo scheduler o aumenta il numero di scheduler da 1 a 2 (opzione consigliata).
Attività zombie interrotte
Più di un'attività zombie ogni 24 ore
Il motivo più comune per le attività zombie è la carenza di risorse di CPU o memoria nel cluster del tuo ambiente. Esamina i grafici sull'utilizzo delle risorse dei worker e assegna più risorse ai worker oppure aumenta il timeout delle attività zombie in modo che lo scheduler attenda più a lungo prima di considerare un'attività come zombie.
Riavvii dei container worker
Più di un riavvio ogni 24 ore
Il motivo più comune è la mancanza di memoria o spazio di archiviazione del worker. Esamina il consumo di risorse dei worker e assegna più memoria o spazio di archiviazione ai worker. Se la mancanza di risorse non è il motivo, esamina la risoluzione dei problemi relativi ai riavvii dei worker e utilizza le query di logging per scoprire i motivi dei riavvii dei worker.
Creare canali di notifica
Segui le istruzioni riportate in Creare un canale di notifica per creare un canale di notifica via email.
Per saperne di più sui canali di notifica, consulta Gestire i canali di notifica.
Crea criteri di avviso
Crea policy di avviso basate sui benchmark forniti nelle sezioni precedenti di questo tutorial per monitorare continuamente i valori delle metriche e ricevere notifiche quando queste violano una condizione.
Console
Puoi configurare avvisi per ogni metrica presentata nella dashboard Monitoraggio facendo clic sull'icona a forma di campana nell'angolo dell'elemento corrispondente:
Trova ogni metrica che vuoi monitorare nella dashboard di Monitoring e fai clic sull'icona a forma di campana nell'angolo dell'elemento della metrica. Viene visualizzata la pagina Crea policy di avviso.
Nella sezione Trasforma i dati:
Configura la sezione All'interno di ogni serie temporale come descritto nella configurazione dei criteri di avviso per la metrica.
Fai clic su Avanti, poi configura la sezione Configura attivatore di avviso come descritto nella configurazione dei criteri di avviso per la metrica.
Fai clic su Avanti.
Configura le notifiche. Espandi il menu Canali di notifica e seleziona i canali di notifica che hai creato nel passaggio precedente.
Fai clic su OK.
Nella sezione Assegna un nome alla policy di avviso, compila il campo Nome policy di avviso. Utilizza un nome descrittivo per ciascuna metrica. Utilizza il valore "Assegna un nome al criterio di avviso" come descritto nella configurazione dei criteri di avviso per la metrica.
Fai clic su Avanti.
Rivedi il criterio di avviso e fai clic su Crea criterio.
Metrica Integrità ambiente (DAG di monitoraggio di Airflow) - configurazioni criterio di avviso
- Nome metrica: Ambiente Cloud Composer - Integro
- API: composer.googleapis.com/environment/healthy
Filtri:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Trasforma i dati > All'interno di ogni serie temporale:
- Finestra temporale continua: personalizzata
- Valore personalizzato: 4
- Unità personalizzate: ora/e
- Funzione finestra temporale continua: frazione (true)
Configura trigger di avviso:
- Tipi di condizione: soglia
- Attivatore di avvisi: una serie temporale è in violazione
- Posizione soglia: sotto la soglia
- Valore soglia: 90
- Nome condizione: condizione di integrità dell'ambiente
Configura le notifiche e finalizza l'avviso:
- Assegna alla policy di avviso il nome Integrità ambiente Airflow
Configurazioni criterio di avviso per la metrica di integrità del database
- Nome metrica: Cloud Composer Environment - Database Healthy
- API: composer.googleapis.com/environment/database_health
Filtri:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Trasforma i dati > All'interno di ogni serie temporale:
- Finestra temporale continua: personalizzata
- Valore personalizzato: 4
- Unità personalizzate: ora/e
- Funzione finestra temporale continua: frazione (true)
Configura trigger di avviso:
- Tipi di condizione: soglia
- Attivatore di avvisi: una serie temporale è in violazione
- Posizione soglia: sotto la soglia
- Valore soglia: 95
- Nome condizione: condizione di integrità del database
Configura le notifiche e finalizza l'avviso:
- Assegna un nome alla policy di avviso: Airflow Database Health
Metrica di utilizzo della CPU del database - configurazioni dei criterio di avviso
- Nome metrica: Cloud Composer Environment - Database CPU Utilization
- API: composer.googleapis.com/environment/database/cpu/utilization
Filtri:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Trasforma i dati > All'interno di ogni serie temporale:
- Finestra temporale continua: personalizzata
- Valore personalizzato: 12
- Unità personalizzate: ora/e
- Funzione finestra temporale continua: media
Configura trigger di avviso:
- Tipi di condizione: soglia
- Attivatore di avvisi: una serie temporale è in violazione
- Posizione soglia: sopra la soglia
- Valore soglia: 80
- Nome condizione: condizione di utilizzo della CPU del database
Configura le notifiche e finalizza l'avviso:
- Assegna alla policy di avviso il nome: Utilizzo CPU database Airflow
Metrica di utilizzo della memoria del database - configurazioni dei criterio di avviso
- Nome metrica: Cloud Composer Environment - Database Memory Utilization
- API: composer.googleapis.com/environment/database/memory/utilization
Filtri:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Trasforma i dati > All'interno di ogni serie temporale:
- Finestra temporale continua: personalizzata
- Valore personalizzato: 12
- Unità personalizzate: ora/e
- Funzione finestra temporale continua: media
Configura trigger di avviso:
- Tipi di condizione: soglia
- Attivatore di avvisi: una serie temporale è in violazione
- Posizione soglia: sopra la soglia
- Valore soglia: 80
- Nome condizione: condizione di utilizzo della memoria del database
Configura le notifiche e finalizza l'avviso:
- Assegna alla policy di avviso il nome: Utilizzo memoria database Airflow
Metrica Heartbeat dello scheduler - configurazioni dei criterio di avviso
- Nome metrica: Cloud Composer Environment - Scheduler Heartbeats
- API: composer.googleapis.com/environment/scheduler_heartbeat_count
Filtri:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Trasforma i dati > All'interno di ogni serie temporale:
- Finestra temporale continua: personalizzata
- Valore personalizzato: 4
- Unità personalizzate: ora/e
- Funzione finestra temporale continua: conteggio
Configura trigger di avviso:
- Tipi di condizione: soglia
- Attivatore di avvisi: una serie temporale è in violazione
- Posizione soglia: sotto la soglia
Valore soglia: 216
- Puoi ottenere questo numero eseguendo una query che aggrega il valore
_scheduler_heartbeat_count_meannell'editor di query di Esplora metriche.
- Puoi ottenere questo numero eseguendo una query che aggrega il valore
Nome condizione: condizione heartbeat dello scheduler
Configura le notifiche e finalizza l'avviso:
- Assegna alla policy di avviso il nome: Heartbeat dello scheduler di Airflow
Metrica Attività zombie interrotte - configurazioni criterio di avviso
- Nome metrica: Cloud Composer Environment - Zombie Tasks Killed
- API: composer.googleapis.com/environment/zombie_task_killed_count
Filtri:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Trasforma i dati > All'interno di ogni serie temporale:
- Finestra temporale continua: 1 giorno
- Funzione finestra temporale continua: somma
Configura trigger di avviso:
- Tipi di condizione: soglia
- Attivatore di avvisi: una serie temporale è in violazione
- Posizione soglia: sopra la soglia
- Valore soglia: 1
- Nome condizione: condizione Attività zombie
Configura le notifiche e finalizza l'avviso:
- Assegna alla policy di avviso il nome: Airflow Zombie Tasks
Metrica Riavvii dei container worker - configurazioni criterio di avviso
- Nome metrica: Container Kubernetes - Conteggio riavvii
- API: kubernetes.io/container/restart_count
Filtri:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION] pod_name =~ airflow-worker-.*|airflow-k8s-worker-.* container_name =~ airflow-worker|base cluster_name = [CLUSTER_NAME]CLUSTER_NAMEè il nome del cluster del tuo ambiente che puoi trovare in Configurazione ambiente > Risorse > cluster GKE nella console Google Cloud .Trasforma i dati > All'interno di ogni serie temporale:
- Finestra temporale continua: 1 giorno
- Funzione finestra temporale continua: tasso
Configura trigger di avviso:
- Tipi di condizione: soglia
- Attivatore di avvisi: una serie temporale è in violazione
- Posizione soglia: sopra la soglia
- Valore soglia: 1
- Nome condizione: condizione di riavvio dei container worker
Configura le notifiche e finalizza l'avviso:
- Assegna alla policy di avviso il nome: Airflow Worker Restarts
Terraform
Esegui uno script Terraform che crea un canale di notifica via email e carica i criteri di avviso per le metriche chiave fornite in questo tutorial in base ai rispettivi benchmark:
- Salva il file Terraform di esempio sul computer locale.
Sostituisci quanto segue:
PROJECT_ID: l'ID progetto del tuo progetto. Ad esempio:example-project.EMAIL_ADDRESS: l'indirizzo email a cui inviare una notifica in caso di attivazione di un avviso.ENVIRONMENT_NAME: il nome del tuo ambiente Cloud Composer. Ad esempio,example-composer-environment.CLUSTER_NAME: il nome del cluster dell'ambiente che puoi trovare in Configurazione ambiente > Risorse > Cluster GKE nella console Google Cloud .
resource "google_monitoring_notification_channel" "basic" {
project = "PROJECT_ID"
display_name = "Test Notification Channel"
type = "email"
labels = {
email_address = "EMAIL_ADDRESS"
}
# force_delete = false
}
resource "google_monitoring_alert_policy" "environment_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Environment Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Environment health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/healthy\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.9
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "database_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Database Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database_health\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.95
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_cpu_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database CPU Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database CPU usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/cpu/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_memory_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database Memory Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database memory usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/memory/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_scheduler_heartbeat" {
project = "PROJECT_ID"
display_name = "Airflow Scheduler Heartbeat"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Scheduler heartbeat condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/scheduler_heartbeat_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 216 // Threshold is 90% of the average for composer.googleapis.com/environment/scheduler_heartbeat_count metric in an idle environment
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_COUNT"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_zombie_task" {
project = "PROJECT_ID"
display_name = "Airflow Zombie Tasks"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Zombie tasks condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/zombie_task_killed_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_SUM"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_worker_restarts" {
project = "PROJECT_ID"
display_name = "Airflow Worker Restarts"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Worker container restarts condition"
condition_threshold {
filter = "resource.type = \"k8s_container\" AND (resource.labels.cluster_name = \"CLUSTER_NAME\" AND resource.labels.container_name = monitoring.regex.full_match(\"airflow-worker|base\") AND resource.labels.pod_name = monitoring.regex.full_match(\"airflow-worker-.*|airflow-k8s-worker-.*\")) AND metric.type = \"kubernetes.io/container/restart_count\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_RATE"
}
}
}
}
Testa i criteri di avviso
Questa sezione descrive come testare le norme di avviso create e interpretare i risultati.
Carica un DAG di esempio
Il DAG di esempio memory_consumption_dag.py fornito in questo tutorial imita
l'utilizzo intensivo della memoria del worker. Il DAG contiene 4 attività, ognuna delle quali scrive dati in una stringa di esempio, consumando 380 MB di memoria. L'esempio
di DAG è pianificato per essere eseguito ogni 2 minuti e inizierà a essere eseguito automaticamente
una volta caricato nell'ambiente Composer.
Carica il seguente DAG di esempio nell'ambiente che hai creato nei passaggi precedenti:
from datetime import datetime
import sys
import time
from airflow import DAG
from airflow.operators.python import PythonOperator
def ram_function():
data = ""
start = time.time()
for i in range(38):
data += "a" * 10 * 1000**2
time.sleep(0.2)
print(f"{i}, {round(time.time() - start, 4)}, {sys.getsizeof(data) / (1000 ** 3)}")
print(f"Size={sys.getsizeof(data) / (1000 ** 3)}GB")
time.sleep(30 - (time.time() - start))
print(f"Complete in {round(time.time() - start, 2)} seconds!")
with DAG(
dag_id="memory_consumption_dag",
start_date=datetime(2023, 1, 1, 1, 1, 1),
schedule="1/2 * * * *",
catchup=False,
) as dag:
for i in range(4):
PythonOperator(
task_id=f"task_{i+1}",
python_callable=ram_function,
retries=0,
dag=dag,
)
Interpretare avvisi e metriche in Monitoring
Attendi circa 10 minuti dopo l'avvio dell'esecuzione del DAG di esempio e valuta i risultati del test:
Controlla la tua casella di posta per verificare di aver ricevuto una notifica da Google Cloud Alerting con la riga dell'oggetto che inizia con
[ALERT]. Il contenuto di questo messaggio contiene i dettagli dell'incidente relativo alla criterio di avviso.Fai clic sul pulsante Visualizza incidente nella notifica via email. Viene visualizzata laMetrics Explorere. Rivedi i dettagli dell'incidente di avviso:
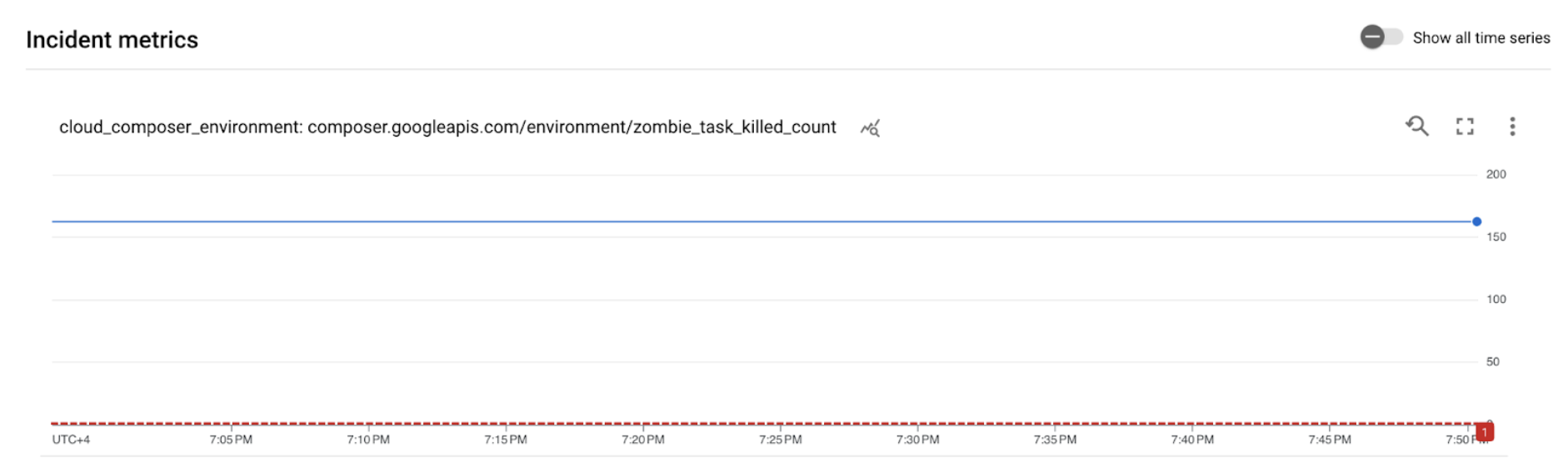
Figura 2. Dettagli dell'incidente di avviso (fai clic per ingrandire) Il grafico delle metriche dell'incidente indica che le metriche che hai creato hanno superato la soglia di 1, il che significa che Airflow ha rilevato e interrotto più di un'attività zombie.
Nel tuo ambiente Cloud Composer, vai alla scheda Monitoring, apri la sezione Statistiche DAG e trova il grafico Attività zombie terminate:
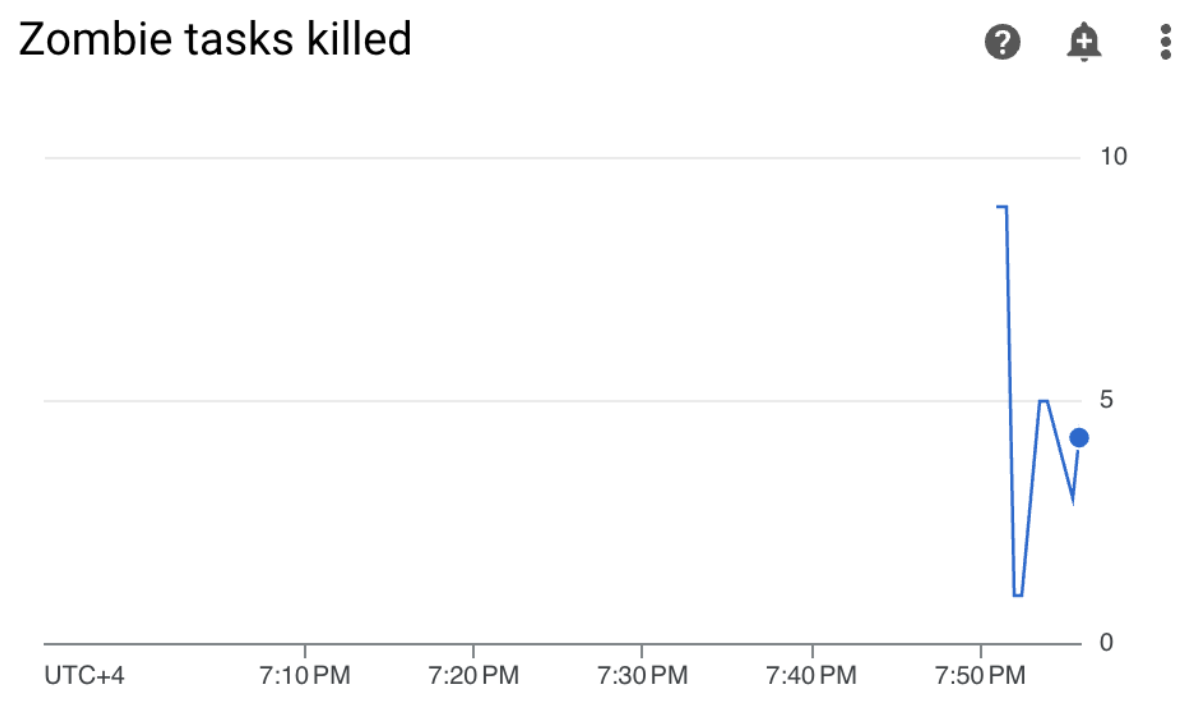
Figura 3. Grafico delle attività zombie (fai clic per ingrandire) Il grafico indica che Airflow ha interrotto circa 20 attività zombie nei primi 10 minuti di esecuzione del DAG di esempio.
Secondo i benchmark e le azioni correttive, il motivo più comune per le attività zombie è la mancanza di memoria o CPU del worker. Identifica la causa principale delle attività zombie analizzando l'utilizzo delle risorse dei worker.
Apri la sezione Worker nella dashboard di monitoraggio ed esamina le metriche sull'utilizzo di CPU e memoria dei worker:
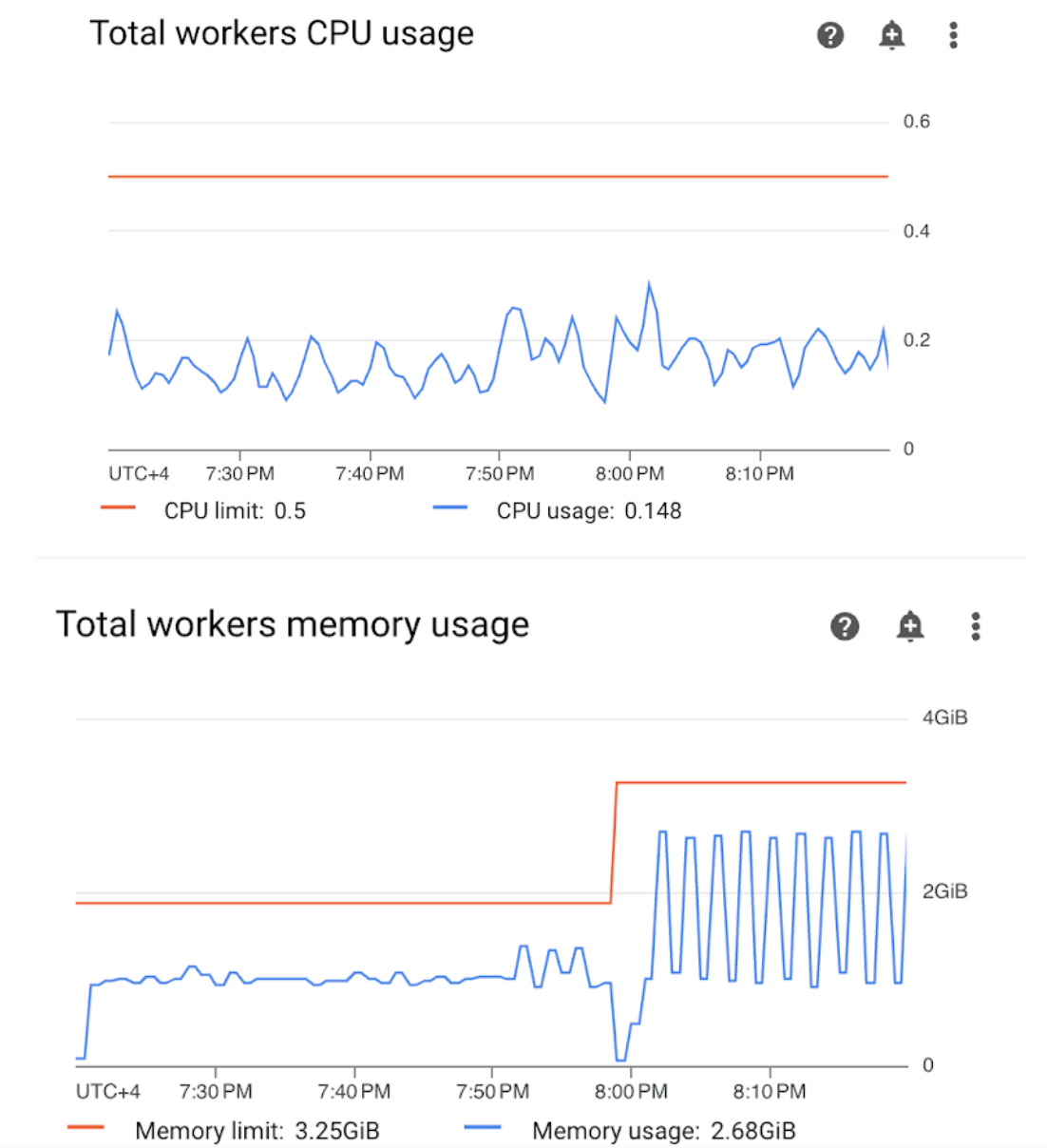
Figura 4.Metriche di utilizzo di CPU e memoria del worker (fai clic per ingrandire) Il grafico Utilizzo totale CPU worker indica che l'utilizzo della CPU worker è stato sempre inferiore al 50% del limite totale disponibile, pertanto la CPU disponibile è sufficiente. Il grafico Utilizzo totale della memoria dei worker mostra che l'esecuzione del DAG di esempio ha comportato il raggiungimento del limite di memoria allocabile, che equivale a quasi il 75% del limite di memoria totale mostrato nel grafico (GKE riserva il 25% dei primi 4 GiB di memoria e 100 MiB di memoria aggiuntivi su ogni nodo per gestire l'espulsione dei pod).
Puoi concludere che i worker non dispongono delle risorse di memoria per eseguire il DAG di esempio correttamente.
Ottimizzare l'ambiente e valutarne le prestazioni
In base all'analisi dell'utilizzo delle risorse dei worker, devi allocare più memoria ai worker per tutte le attività nel tuo DAG.
Nel tuo ambiente Composer, apri la scheda DAG, fai clic sul nome del DAG di esempio (
memory_consumption_dag), quindi fai clic su Metti in pausa il DAG.Alloca memoria worker aggiuntiva:
Nella scheda Configurazione ambiente, trova la configurazione Risorse > Workload e fai clic su Modifica.
Nell'elemento Worker, aumenta il limite di Memoria. In questo tutorial, utilizza 3,25 GB.
Salva le modifiche e attendi diversi minuti per il riavvio del worker.
Apri la scheda DAG, fai clic sul nome del DAG di esempio (
memory_consumption_dag) e poi su Riattiva DAG.
Vai a Monitoraggio e verifica che non siano visualizzate nuove attività zombie dopo aver aggiornato i limiti delle risorse worker:
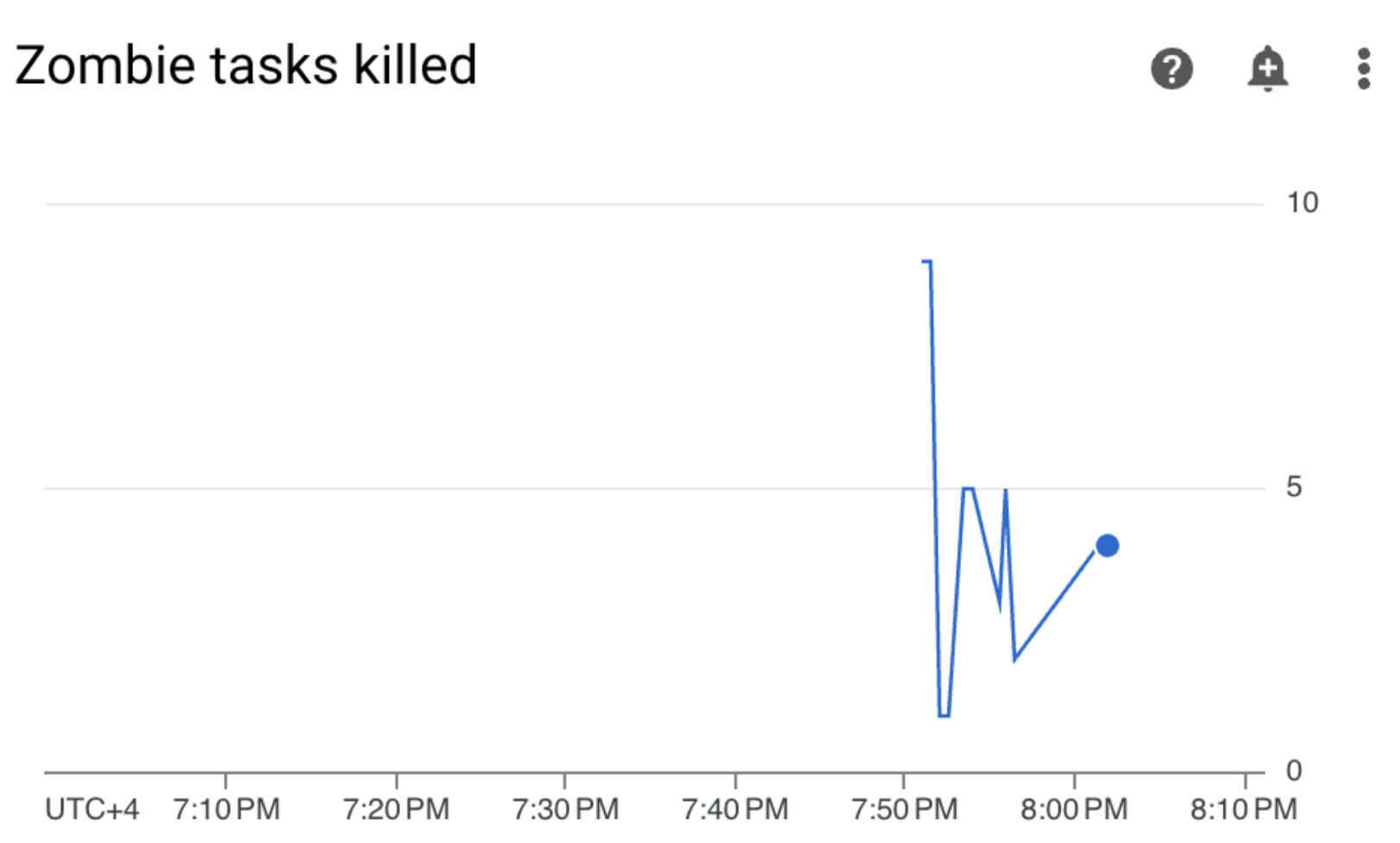
Riepilogo
In questo tutorial hai imparato a conoscere le metriche chiave di integrità e rendimento a livello di ambiente, come configurare i criteri di avviso per ogni metrica e come interpretare ogni metrica in azioni correttive. Successivamente, hai eseguito un DAG di esempio, hai identificato la causa principale dei problemi di integrità dell'ambiente con l'aiuto di avvisi e grafici di monitoraggio e hai ottimizzato l'ambiente allocando più memoria ai worker. Tuttavia, è consigliabile ottimizzare i DAG per ridurre il consumo di risorse dei worker in primo luogo, perché non è possibile aumentare le risorse oltre una determinata soglia.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il progetto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Elimina singole risorse
Se intendi esplorare più tutorial e guide rapide, il riuso dei progetti ti aiuta a non superare i limiti di quota.
Console
- Elimina l'ambiente Cloud Composer. Durante questa procedura, elimini anche il bucket dell'ambiente.
- Elimina ciascuno dei criteri di avviso che hai creato in Cloud Monitoring.
Terraform
- Assicurati che lo script Terraform non contenga voci per risorse ancora richieste dal tuo progetto. Ad esempio, potresti voler mantenere alcune API abilitate e le autorizzazioni IAM ancora assegnate (se hai aggiunto queste definizioni allo script Terraform).
- Esegui
terraform destroy. - Elimina manualmente il bucket dell'ambiente. Cloud Composer non lo elimina automaticamente. Puoi farlo dalla console Google Cloud o da Google Cloud CLI.