Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
En esta página se describe cómo usar KubernetesPodOperator para desplegar pods de Kubernetes desde Cloud Composer en el clúster de Google Kubernetes Engine que forma parte de tu entorno de Cloud Composer.
KubernetesPodOperator inicia pods de Kubernetes en el clúster de tu entorno. En comparación, los operadores de Google Kubernetes Engine ejecutan pods de Kubernetes en un clúster específico, que puede ser un clúster independiente que no esté relacionado con tu entorno. También puedes crear y eliminar clústeres con los operadores de Google Kubernetes Engine.
KubernetesPodOperator es una buena opción si necesitas lo siguiente:
- Dependencias de Python personalizadas que no están disponibles en el repositorio público de PyPI.
- Dependencias binarias que no están disponibles en la imagen de trabajador de Cloud Composer.
Antes de empezar
Si se usa la versión 5.0.0 del proveedor de Kubernetes de CNCF, sigue las instrucciones documentadas en la sección del proveedor de Kubernetes de CNCF.
La configuración de afinidad de pods no está disponible en Cloud Composer 2. Si quieres usar la afinidad de pods, usa los operadores de GKE para iniciar pods en otro clúster.
Acerca de KubernetesPodOperator en Cloud Composer 2
En esta sección se describe cómo funciona KubernetesPodOperator en Cloud Composer 2.
Uso de recursos
En Cloud Composer 2, el clúster de tu entorno se escala automáticamente. Las cargas de trabajo adicionales que ejecutes con KubernetesPodOperator se escalan de forma independiente de tu entorno.
Tu entorno no se ve afectado por el aumento de la demanda de recursos, pero el clúster de tu entorno se amplía y se reduce en función de la demanda de recursos.
Los precios de las cargas de trabajo adicionales que ejecutes en el clúster de tu entorno se corresponden con el modelo de precios de Cloud Composer 2 y utilizan los SKUs de Compute de Cloud Composer.
Cloud Composer 2 usa clústeres de Autopilot, que introducen el concepto de clases de computación:
Cloud Composer solo admite la clase de computación
general-purpose.De forma predeterminada, si no se selecciona ninguna clase, se asume la clase
general-purposeal crear pods con KubernetesPodOperator.Cada clase está asociada a propiedades y límites de recursos específicos. Puedes consultar más información en la documentación de Autopilot. Por ejemplo, los pods que se ejecutan en la clase
general-purposepueden usar hasta 110 GiB de memoria.
Acceso a los recursos del proyecto
Cloud Composer 2 usa clústeres de GKE con Workload Identity Federation for GKE. Los pods que se ejecutan en el espacio de nombres composer-user-workloads
pueden acceder Google Cloud a los recursos de tu proyecto sin
configuración adicional. La cuenta de servicio de tu entorno se usa para acceder a estos recursos.
Si quieres usar un espacio de nombres personalizado, las cuentas de servicio de Kubernetes asociadas a este espacio de nombres deben asignarse a cuentas de servicio para habilitar la autorización de identidad de servicio para las solicitudes a las APIs de Google y otros servicios. Google Cloud Si ejecutas pods en un espacio de nombres personalizado en el clúster de tu entorno, no se crearán enlaces de IAM entre Kubernetes y las cuentas de servicio, y estos pods no podrán acceder a los recursos de tu proyecto.Google Cloud Google Cloud
Si usas un espacio de nombres personalizado y quieres que tus pods tengan acceso a los recursos deGoogle Cloud , sigue las instrucciones de Workload Identity Federation for GKE y configura las vinculaciones para un espacio de nombres personalizado:
- Crea un espacio de nombres independiente en el clúster de tu entorno.
- Crea un enlace entre la cuenta de servicio de Kubernetes del espacio de nombres personalizado y la cuenta de servicio de tu entorno.
- Añade la anotación de la cuenta de servicio de tu entorno a la cuenta de servicio de Kubernetes.
- Cuando uses KubernetesPodOperator, especifica el espacio de nombres y la cuenta de servicio de Kubernetes en los parámetros
namespaceyservice_account_name.
Configuración mínima
Para crear un KubernetesPodOperator, solo se necesitan los parámetros name, image y task_id del pod que se va a usar. El /home/airflow/composer_kube_config
contiene las credenciales para autenticarte en GKE.
Configuración adicional
En este ejemplo se muestran parámetros adicionales que puedes configurar en KubernetesPodOperator.
Consulta los siguientes recursos para obtener más información:
Para obtener información sobre cómo usar los secretos y los ConfigMaps de Kubernetes, consulta Usar secretos y ConfigMaps de Kubernetes.
Para obtener información sobre cómo usar plantillas Jinja con KubernetesPodOperator, consulta Usar plantillas Jinja.
Para obtener información sobre los parámetros de KubernetesPodOperator, consulta la referencia del operador en la documentación de Airflow.
Usar plantillas Jinja
Airflow admite plantillas Jinja en los DAGs.
Debe declarar los parámetros de Airflow obligatorios (task_id, name y image) con el operador. Como se muestra en el siguiente ejemplo, puedes usar Jinja para crear plantillas de todos los demás parámetros, incluidos cmds, arguments, env_vars y config_file.
El parámetro env_vars del ejemplo se define a partir de una variable de Airflow llamada my_value. El DAG de ejemplo obtiene su valor de la variable de plantilla vars de Airflow. Airflow tiene más variables que proporcionan acceso a diferentes tipos de información. Por ejemplo, puedes usar la variable de plantilla conf para acceder a los valores de las opciones de configuración de Airflow. Para obtener más información y la lista de variables disponibles en Airflow, consulta la referencia de plantillas en la documentación de Airflow.
Sin cambiar el DAG ni crear la variable env_vars, la tarea ex-kube-templates del ejemplo falla porque la variable no existe. Crea esta variable en la interfaz de usuario de Airflow o con Google Cloud CLI:
Interfaz de usuario de Airflow
Ve a la interfaz de Airflow.
En la barra de herramientas, seleccione Administrar > Variables.
En la página List Variable (Variable de lista), haz clic en Add a new record (Añadir un nuevo registro).
En la página Añadir variable, introduce la siguiente información:
- Tecla:
my_value - Valor:
example_value
- Tecla:
Haz clic en Guardar.
gcloud
Introduce el siguiente comando:
gcloud composer environments run ENVIRONMENT \
--location LOCATION \
variables set -- \
my_value example_value
Sustituye:
ENVIRONMENTcon el nombre del entorno.LOCATIONcon la región en la que se encuentra el entorno.
En el siguiente ejemplo se muestra cómo usar plantillas Jinja con KubernetesPodOperator:
Usar secretos y ConfigMaps de Kubernetes
Un secreto de Kubernetes es un objeto que contiene datos sensibles. Un ConfigMap de Kubernetes es un objeto que contiene datos no confidenciales en pares clave-valor.
En Cloud Composer 2, puedes crear secretos y ConfigMaps con la CLI de Google Cloud, la API o Terraform, y luego acceder a ellos desde KubernetesPodOperator.
Acerca de los archivos de configuración YAML
Cuando creas un Secret o un ConfigMap de Kubernetes con la CLI de Google Cloud y la API, proporcionas un archivo en formato YAML. Este archivo debe tener el mismo formato que los secretos y los ConfigMaps de Kubernetes. La documentación de Kubernetes proporciona muchos ejemplos de código de ConfigMaps y Secrets. Para empezar, puedes consultar la página Distribuir credenciales de forma segura mediante secretos y ConfigMaps.
Al igual que en los secretos de Kubernetes, usa la representación en base64 cuando definas valores en los secretos.
Para codificar un valor, puedes usar el siguiente comando (esta es una de las muchas formas de obtener un valor codificado en base64):
echo "postgresql+psycopg2://root:example-password@127.0.0.1:3306/example-db" -n | base64
Resultado:
cG9zdGdyZXNxbCtwc3ljb3BnMjovL3Jvb3Q6ZXhhbXBsZS1wYXNzd29yZEAxMjcuMC4wLjE6MzMwNi9leGFtcGxlLWRiIC1uCg==
En los ejemplos que se muestran más adelante en esta guía se utilizan los dos archivos YAML que se indican a continuación. Ejemplo de archivo de configuración YAML de un secreto de Kubernetes:
apiVersion: v1
kind: Secret
metadata:
name: airflow-secrets
data:
sql_alchemy_conn: cG9zdGdyZXNxbCtwc3ljb3BnMjovL3Jvb3Q6ZXhhbXBsZS1wYXNzd29yZEAxMjcuMC4wLjE6MzMwNi9leGFtcGxlLWRiIC1uCg==
Otro ejemplo que muestra cómo incluir archivos. Al igual que en el ejemplo anterior, primero codifica el contenido de un archivo (cat ./key.json | base64) y, a continuación, proporciona este valor en el archivo YAML:
apiVersion: v1
kind: Secret
metadata:
name: service-account
data:
service-account.json: |
ewogICJ0eXBl...mdzZXJ2aWNlYWNjb3VudC5jb20iCn0K
Ejemplo de archivo de configuración YAML de un ConfigMap. No es necesario que utilices la representación base64 en ConfigMaps:
apiVersion: v1
kind: ConfigMap
metadata:
name: example-configmap
data:
example_key: example_value
Gestionar secretos de Kubernetes
En Cloud Composer 2, puedes crear secretos con Google Cloud CLI y kubectl:
Obtén información sobre el clúster de tu entorno:
Ejecuta el siguiente comando:
gcloud composer environments describe ENVIRONMENT \ --location LOCATION \ --format="value(config.gkeCluster)"Sustituye:
ENVIRONMENTcon el nombre de tu entorno.LOCATIONcon la región en la que se encuentra el entorno de Cloud Composer.
El resultado de este comando tiene el siguiente formato:
projects/<your-project-id>/locations/<location-of-composer-env>/clusters/<your-cluster-id>.Para obtener el ID del clúster de GKE, copia el resultado después de
/clusters/(termina en-gke).
Conéctate a tu clúster de GKE con el siguiente comando:
gcloud container clusters get-credentials CLUSTER_ID \ --project PROJECT \ --region LOCATIONHaz los cambios siguientes:
CLUSTER_ID: el ID del clúster del entorno.PROJECT_ID: el ID de proyecto.LOCATION: la región en la que se encuentra el entorno.
Crea secretos de Kubernetes:
En los siguientes comandos se muestran dos enfoques diferentes para crear secretos de Kubernetes. El enfoque
--from-literalusa pares clave-valor. El enfoque--from-fileusa el contenido de los archivos.Para crear un secreto de Kubernetes proporcionando pares clave-valor, ejecuta el siguiente comando. En este ejemplo, se crea un secreto llamado
airflow-secretsque tiene un camposql_alchemy_conncon el valortest_value.kubectl create secret generic airflow-secrets \ --from-literal sql_alchemy_conn=test_value -n composer-user-workloadsPara crear un secreto de Kubernetes proporcionando el contenido de un archivo, ejecuta el siguiente comando. En este ejemplo se crea un secreto llamado
service-accountque tiene el camposervice-account.jsoncon el valor tomado del contenido de un archivo./key.jsonlocal.kubectl create secret generic service-account \ --from-file service-account.json=./key.json -n composer-user-workloads
Usar secretos de Kubernetes en tus DAGs
En este ejemplo se muestran dos formas de usar los secretos de Kubernetes: como variable de entorno y como volumen montado por el pod.
El primer secreto, airflow-secrets, se asigna a una variable de entorno de Kubernetes llamada SQL_CONN (en lugar de a una variable de entorno de Airflow o Cloud Composer).
El segundo secreto, service-account, monta service-account.json, un archivo
con un token de cuenta de servicio, en /var/secrets/google.
Este es el aspecto de los objetos secretos:
El nombre del primer secreto de Kubernetes se define en la variable secret_env.
Este secreto se llama airflow-secrets. El parámetro deploy_type especifica que debe exponerse como una variable de entorno. El nombre de la variable de entorno es SQL_CONN, tal como se especifica en el parámetro deploy_target. Por último, el valor de la variable de entorno SQL_CONN se asigna al valor de la clave sql_alchemy_conn.
El nombre del segundo secreto de Kubernetes se define en la variable secret_volume. Este secreto se llama service-account. Se expone como un volumen, tal como se especifica en el parámetro deploy_type. La ruta del archivo que se va a montar, deploy_target, es /var/secrets/google. Por último, el key del secreto almacenado en deploy_target es service-account.json.
Este es el aspecto de la configuración del operador:
Información sobre el proveedor de Kubernetes de la CNCF
KubernetesPodOperator se implementa en el proveedor apache-airflow-providers-cncf-kubernetes.
Para consultar las notas de la versión detalladas del proveedor de Kubernetes de CNCF, visita el sitio web del proveedor de Kubernetes de CNCF.
Versión 6.0.0
En la versión 6.0.0 del paquete del proveedor de Kubernetes de CNCF, KubernetesPodOperator usa la conexión kubernetes_default de forma predeterminada.
Si has especificado una conexión personalizada en la versión 5.0.0, el operador seguirá usando esa conexión. Para volver a usar la kubernetes_default
conexión, puede que tengas que ajustar tus DAGs en consecuencia.
Versión 5.0.0
Esta versión introduce algunos cambios incompatibles con versiones anteriores
en comparación con la versión 4.4.0. Las más importantes están relacionadas con la kubernetes_defaultconexión, que no se usa en la versión 5.0.0.
- Es necesario modificar la conexión
kubernetes_default. La ruta de configuración de Kubernetes debe ser/home/airflow/composer_kube_config(como se muestra en la siguiente figura). Como alternativa, se debe añadirconfig_filea la configuración de KubernetesPodOperator (como se muestra en el siguiente ejemplo de código).
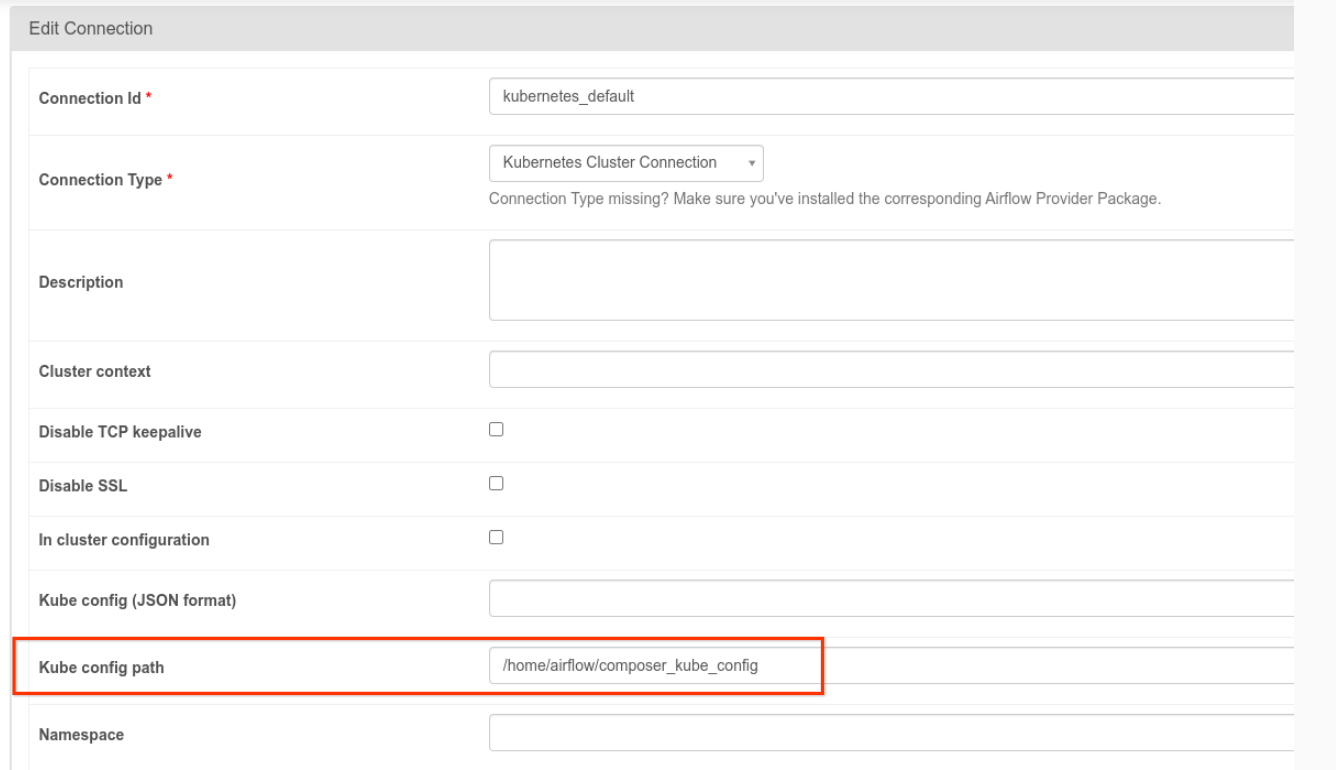
- Modifica el código de una tarea con KubernetesPodOperator de la siguiente manera:
KubernetesPodOperator(
# config_file parameter - can be skipped if connection contains this setting
config_file="/home/airflow/composer_kube_config",
# definition of connection to be used by the operator
kubernetes_conn_id='kubernetes_default',
...
)
Para obtener más información sobre la versión 5.0.0, consulta las notas de la versión del proveedor de Kubernetes de CNCF.
Solución de problemas
En esta sección se ofrecen consejos para solucionar problemas habituales de KubernetesPodOperator:
Ver registros
Cuando intentes solucionar problemas, puedes consultar los registros en el siguiente orden:
Registros de tareas de Airflow:
En la Google Cloud consola, ve a la página Entornos.
En la lista de entornos, haz clic en el nombre del entorno. Se abrirá la página Detalles del entorno.
Ve a la pestaña DAGs.
Haga clic en el nombre del DAG y, a continuación, en la ejecución del DAG para ver los detalles y los registros.
Registros del programador de Airflow:
Ve a la página Detalles del entorno.
Ve a la pestaña Registros.
Inspecciona los registros del programador de Airflow.
Registros de pods en la consola, en cargas de trabajo de GKE. Google Cloud Estos registros incluyen el archivo YAML de definición de pod, los eventos de pod y los detalles del pod.
Códigos de retorno distintos de cero
Cuando se usa KubernetesPodOperator (y GKEStartPodOperator), el código de retorno del punto de entrada del contenedor determina si la tarea se considera completada correctamente o no. Los códigos de retorno distintos de cero indican un error.
Un patrón habitual es ejecutar un script de shell como punto de entrada del contenedor para agrupar varias operaciones en el contenedor.
Si vas a escribir una secuencia de comandos de este tipo, te recomendamos que incluyas el comando set -e en la parte superior para que, si se produce un error en un comando de la secuencia, esta se detenga y el error se propague a la instancia de tarea de Airflow.
Tiempos de espera de pods
El tiempo de espera predeterminado de KubernetesPodOperator es de 120 segundos, lo que puede provocar que se agote el tiempo de espera antes de que se descarguen imágenes más grandes. Puedes aumentar el tiempo de espera modificando el parámetro startup_timeout_seconds al crear el KubernetesPodOperator.
Cuando se agota el tiempo de espera de un pod, el registro específico de la tarea está disponible en la interfaz de usuario de Airflow. Por ejemplo:
Executing <Task(KubernetesPodOperator): ex-all-configs> on 2018-07-23 19:06:58.133811
Running: ['bash', '-c', u'airflow run kubernetes-pod-example ex-all-configs 2018-07-23T19:06:58.133811 --job_id 726 --raw -sd DAGS_FOLDER/kubernetes_pod_operator_sample.py']
Event: pod-name-9a8e9d06 had an event of type Pending
...
...
Event: pod-name-9a8e9d06 had an event of type Pending
Traceback (most recent call last):
File "/usr/local/bin/airflow", line 27, in <module>
args.func(args)
File "/usr/local/lib/python2.7/site-packages/airflow/bin/cli.py", line 392, in run
pool=args.pool,
File "/usr/local/lib/python2.7/site-packages/airflow/utils/db.py", line 50, in wrapper
result = func(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/airflow/models.py", line 1492, in _run_raw_task
result = task_copy.execute(context=context)
File "/usr/local/lib/python2.7/site-packages/airflow/contrib/operators/kubernetes_pod_operator.py", line 123, in execute
raise AirflowException('Pod Launching failed: {error}'.format(error=ex))
airflow.exceptions.AirflowException: Pod Launching failed: Pod took too long to start
Los tiempos de espera de los pods también pueden producirse cuando la cuenta de servicio de Cloud Composer no tiene los permisos de gestión de identidades y accesos necesarios para realizar la tarea en cuestión. Para verificarlo, consulta los errores a nivel de pod en los paneles de control de GKE para ver los registros de tu carga de trabajo específica o usa Cloud Logging.
No se ha podido establecer una nueva conexión
La actualización automática está habilitada de forma predeterminada en los clústeres de GKE. Si un grupo de nodos está en un clúster que se está actualizando, es posible que vea el siguiente error:
<Task(KubernetesPodOperator): gke-upgrade> Failed to establish a new
connection: [Errno 111] Connection refused
Para comprobar si tu clúster se está actualizando, en la consola de Google Cloud , ve a la página Clústeres de Kubernetes y busca el icono de carga junto al nombre del clúster de tu entorno.