Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Tutorial ini menunjukkan cara menggunakan Cloud Composer untuk membuat DAG (Directed Acyclic Graph) Apache Airflow yang menjalankan tugas wordcount Apache Hadoop di cluster Dataproc.
Tujuan
- Akses lingkungan Cloud Composer Anda dan gunakan UI Airflow.
- Buat dan lihat variabel lingkungan Airflow.
- Buat dan jalankan DAG yang mencakup tugas berikut:
- Membuat cluster Dataproc.
- Menjalankan tugas jumlah kata Apache Hadoop di cluster.
- Menampilkan hasil jumlah kata ke bucket Cloud Storage.
- Menghapus cluster.
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
- Cloud Composer
- Dataproc
- Cloud Storage
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Sebelum memulai
Pastikan API berikut diaktifkan di project Anda:
Konsol
Enable the Dataproc, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud
Enable the Dataproc, Cloud Storage APIs:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable dataproc.googleapis.com
storage-component.googleapis.com Di project Anda, buat bucket Cloud Storage dengan class penyimpanan dan region apa pun untuk menyimpan hasil tugas penghitungan kata Hadoop.
Catat jalur bucket yang Anda buat, misalnya
gs://example-bucket. Anda akan menentukan variabel Airflow untuk jalur ini dan menggunakan variabel tersebut dalam contoh DAG nanti dalam tutorial ini.Buat lingkungan Cloud Composer dengan parameter default. Tunggu hingga pembuatan lingkungan selesai. Setelah selesai, tanda centang hijau akan muncul di sebelah kiri nama lingkungan.
Catat region tempat Anda membuat lingkungan, misalnya
us-central. Anda akan menentukan variabel Airflow untuk region ini dan menggunakannya dalam DAG contoh untuk menjalankan cluster Dataproc di region yang sama.
Menyetel variable Airflow
Tetapkan variabel Airflow untuk digunakan nanti dalam contoh DAG. Misalnya, Anda dapat menyetel variabel Airflow di UI Airflow.
| Variabel Airflow | Nilai |
|---|---|
gcp_project
|
Project ID project yang Anda gunakan untuk tutorial ini, seperti example-project. |
gcs_bucket
|
Bucket Cloud Storage URI yang Anda buat untuk tutorial ini, seperti gs://example-bucket |
gce_region
|
Region tempat Anda membuat lingkungan, seperti us-central1.
Ini adalah region tempat cluster Dataproc Anda akan dibuat. |
Melihat contoh alur kerja
DAG Airflow adalah kumpulan tugas terorganisir yang ingin Anda jadwalkan
dan jalankan. DAG ditentukan dalam file Python standar. Kode yang ditampilkan di
hadoop_tutorial.py adalah kode alur kerja.
Operator
Untuk mengorkestrasi tiga tugas dalam contoh alur kerja, DAG mengimpor tiga operator Airflow berikut:
DataprocClusterCreateOperator: Membuat cluster Dataproc.DataProcHadoopOperator: Mengirimkan tugas wordcount Hadoop dan menulis hasil ke bucket Cloud Storage.DataprocClusterDeleteOperator: Menghapus cluster untuk menghindari biaya Compute Engine berkelanjutan.
Dependensi
Anda mengatur tugas yang ingin dijalankan dengan cara yang mencerminkan hubungan dan dependensinya. Tugas dalam DAG ini berjalan secara berurutan.
Penjadwalan
Nama DAG adalah composer_hadoop_tutorial, dan DAG berjalan sekali setiap hari. Karena start_date yang diteruskan ke default_dag_args ditetapkan ke yesterday, Cloud Composer menjadwalkan alur kerja untuk segera dimulai setelah DAG diupload ke bucket lingkungan.
Mengupload DAG ke bucket lingkungan
Cloud Composer menyimpan DAG di folder /dags di bucket lingkungan Anda.
Untuk mengupload DAG:
Di komputer lokal Anda, simpan
hadoop_tutorial.py.Di konsol Google Cloud , buka halaman Environments.
Dalam daftar lingkungan, di kolom DAGs folder untuk lingkungan Anda, klik link DAGs.
Klik Upload file.
Pilih
hadoop_tutorial.pydi komputer lokal Anda, lalu klik Open.
Cloud Composer menambahkan DAG ke Airflow dan menjadwalkan DAG secara otomatis. Perubahan DAG terjadi dalam 3-5 menit.
Menjelajahi operasi DAG
Melihat status tugas
Saat Anda mengupload file DAG ke folder dags/ di Cloud Storage, Cloud Composer akan menguraikan file tersebut. Jika berhasil diselesaikan, nama alur kerja akan muncul di daftar DAG, dan alur kerja dimasukkan dalam antrean untuk segera dijalankan.
Untuk melihat status tugas, buka antarmuka web Airflow dan klik DAGs di toolbar.
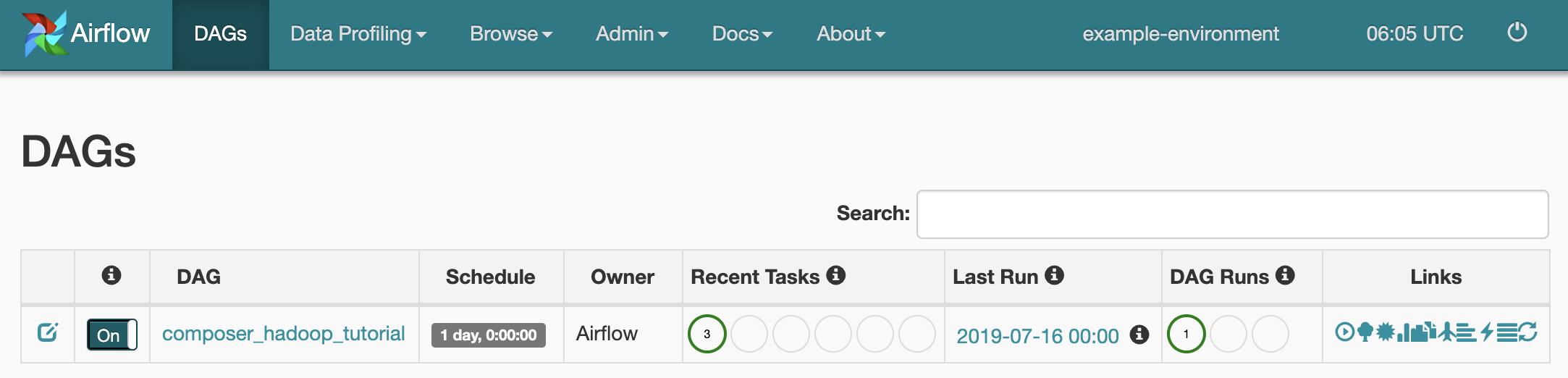
Untuk membuka halaman detail DAG, klik
composer_hadoop_tutorial. Halaman ini menyertakan representasi grafis dari tugas dan dependensi alur kerja.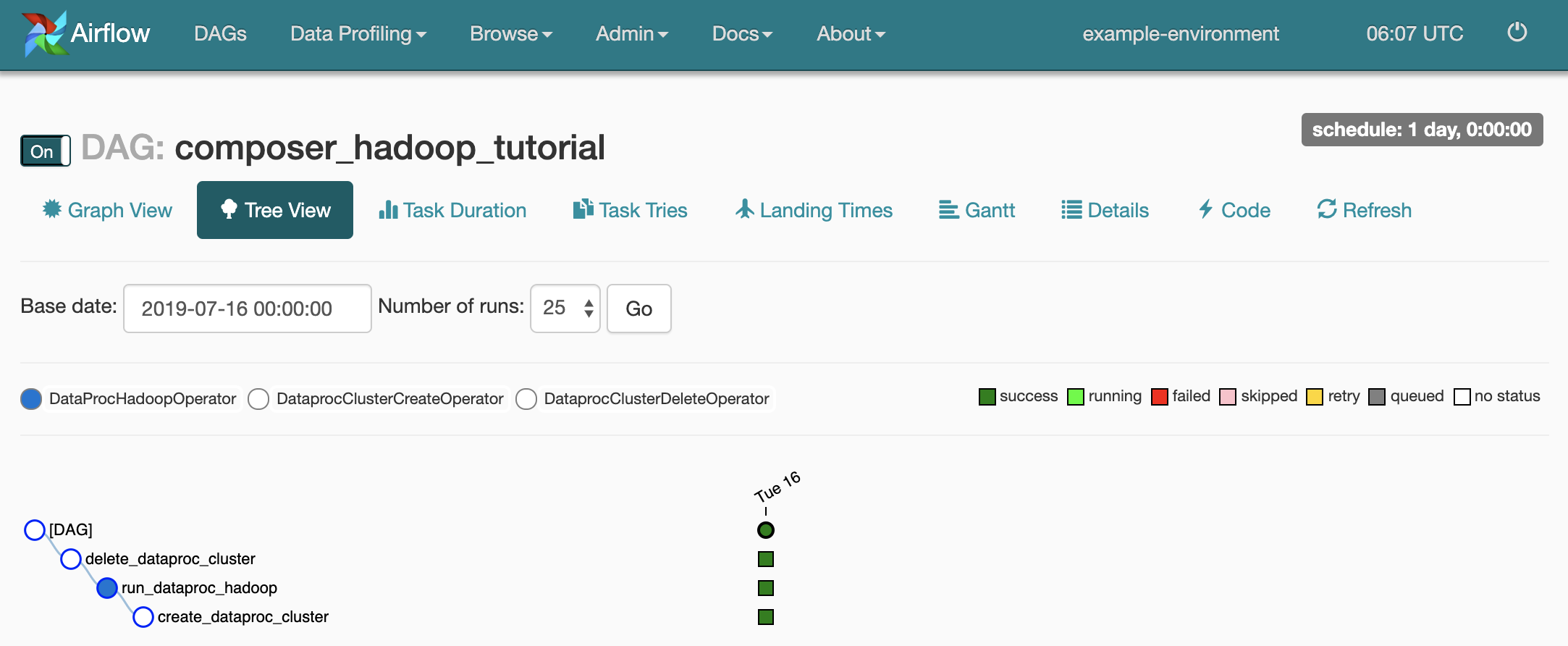
Untuk melihat status setiap tugas, klik Tampilan Grafik, lalu arahkan mouse ke gambar setiap tugas.
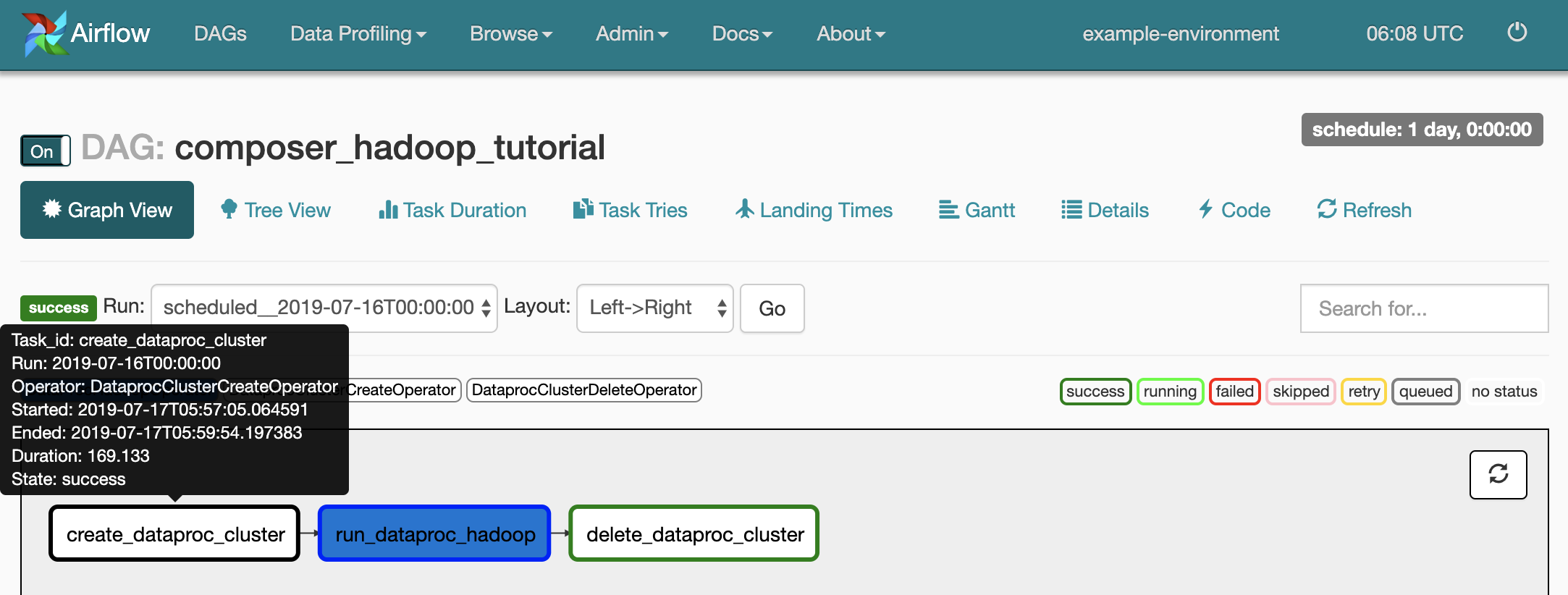
Mengantrekan alur kerja lagi
Untuk menjalankan alur kerja lagi dari Tampilan Grafik:
- Dalam Tampilan Grafik UI Airflow, klik grafik
create_dataproc_cluster. - Untuk mereset ketiga tugas, klik Hapus, lalu klik Oke untuk mengonfirmasi.
- Klik
create_dataproc_clusterlagi di Tampilan Grafik. - Untuk mengantrekan alur kerja lagi, klik Jalankan.
Melihat hasil tugas
Anda juga dapat memeriksa status dan hasil alur kerja composer_hadoop_tutorial
dengan membuka halaman konsol Google Cloud berikut:
Cluster Dataproc: untuk memantau pembuatan dan penghapusan cluster. Perhatikan bahwa cluster yang dibuat oleh alur kerja bersifat sementara: cluster tersebut hanya ada selama durasi alur kerja dan dihapus sebagai bagian dari tugas alur kerja terakhir.
Tugas Dataproc: untuk melihat atau memantau tugas wordcount Apache Hadoop. Klik ID Tugas untuk melihat output log tugas.
Cloud Storage Browser: untuk melihat hasil wordcount di folder
wordcountdi bucket Cloud Storage yang Anda buat untuk tutorial ini.
Pembersihan
Hapus resource yang digunakan dalam tutorial ini:
Hapus lingkungan Cloud Composer, termasuk menghapus bucket lingkungan secara manual.
Hapus bucket Cloud Storage yang menyimpan hasil tugas penghitungan kata Hadoop.