Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Nesta página, descrevemos como realizar testes de failover de banco de dados e cluster para ambientes altamente resilientes.
Os testes de failover para seu ambiente simulam uma interrupção completa de uma zona em um data center. Nesse cenário, uma interrupção zonal de um cluster e uma interrupção zonal de um banco de dados podem acontecer ao mesmo tempo. Ao realizar os dois testes de failover, você pode monitorar como seu ambiente altamente resiliente executa um failover e verificar como isso afeta seus DAGs e tarefas.
Antes de começar
Para realizar testes de failover, sua Conta do Google precisa ter as seguintes funções e permissões:
A permissão
composer.environments.update. Consulte Controle de acesso com o IAM para uma lista de papéis com essa permissão.Papel Administrador de cluster do Kubernetes Engine (
roles/container.clusterAdmin) para executar comandoskubectlno cluster do ambiente. Como alternativa, é possível provisionar papéis de RBAC do Kubernetes diretamente no GKE.
Se você usar redes autorizadas, será necessário executar comandos
kubectlem uma máquina que possa acessar o endpoint do plano de controle do cluster do GKE. Dependendo de como você configura o acesso ao endpoint do plano de controle do ambiente, é possível usar várias opções. Para mais informações, consulte Como executar comandos em um ambiente de IP particular.
Verificar se o ambiente está íntegro
Faça testes de failover apenas em ambientes íntegros. Para verificar se o ambiente está íntegro:
No console Google Cloud , acesse a página Ambientes.
Na lista de ambientes, clique no nome do seu ambiente. A página Detalhes do ambiente é aberta.
Acesse a guia Monitoramento.
Verifique se todas as métricas de integridade estão verdes.
Realizar um teste de failover do banco de dados
É possível realizar um teste de failover do banco de dados, que simula uma interrupção zonal, acionando-o com um comando da Google Cloud CLI. Por exemplo, para medir o tempo necessário para que o banco de dados do seu ambiente mude para outra zona.
Para realizar um teste de failover de banco de dados no seu ambiente:
Verifique se o ambiente está íntegro.
Encontre a zona principal do banco de dados do seu ambiente:
gcloud composer environments fetch-database-properties \ ENVIRONMENT_NAME \ --location LOCATIONSubstitua:
ENVIRONMENT_NAME: o nome do seu ambiente do Cloud Composer.LOCATION: a região em que o ambiente está localizado.
Exemplo:
gcloud composer environments fetch-database-properties \ example-environment \ --location us-central1Inicie o teste de failover do banco de dados:
gcloud composer environments database-failover \ ENVIRONMENT_NAME \ --location LOCATIONSubstitua:
ENVIRONMENT_NAME: o nome do seu ambiente do Cloud Composer.LOCATION: a região em que o ambiente está localizado.
Exemplo:
gcloud composer environments database-failover \ example-environment \ --location us-central1Aguarde até que o teste de failover do banco de dados seja concluído. O processo pode levar até 3 minutos.
Verifique se a zona principal do banco de dados do seu ambiente foi alterada:
gcloud composer environments fetch-database-properties \ ENVIRONMENT_NAME \ --location LOCATIONVerifique as métricas de integridade do ambiente para garantir que ele esteja íntegro.
O banco de dados do seu ambiente fica pronto para outro failover quando a métrica de ambiente Banco de dados disponível para failover (
composer.googleapis.com/environment/database/available_for_failover) se tornaTrue. Para mais informações sobre como ver as métricas do seu ambiente no Cloud Monitoring, consulte Monitorar ambientes.
Realizar o teste de failover do cluster do ambiente
É possível realizar um teste de failover para o cluster do seu ambiente, que simula uma interrupção zonal. Por exemplo, para medir o tempo que leva para seu ambiente mudar para outra zona.
Verificar se o ambiente está íntegro
Antes de iniciar o teste, verifique se o ambiente está íntegro.
Configurar credenciais para o cluster do seu ambiente
Para receber as credenciais do cluster:
No console Google Cloud , acesse a página Ambientes.
Na lista de ambientes, clique no nome do seu ambiente. A página Detalhes do ambiente é aberta.
Acesse a guia Configuração do ambiente.
Clique em Ver detalhes do cluster.
Clique em Conectar.
Copie e execute o comando da Google Cloud CLI mostrado.
Exemplo:
gcloud container clusters get-credentials \ us-central1-exam-db23ee12-gke \ --region us-central1 \ --project example-project
Inspecionar o cluster do ambiente
Verifique as zonas e os nós em que as cargas de trabalho são executadas no cluster do seu ambiente. Você usará essas informações para simular uma interrupção zonal mais tarde. Você também pode executar esses comandos novamente durante o teste de failover para ver como o cluster do seu ambiente realiza o failover.
Verifique nós e zonas:
kubectl get nodes \ -o=custom-columns=NAME:.metadata.name,NODE:.metadata.labels.topology\\.gke\\.io/zoneVerifique os pods:
kubectl get pods --all-namespaces \ -o=custom-columns=NAME:.metadata.name,STATUS:.status.phase,NODE:.spec.nodeName \ --field-selector metadata.namespace!=kube-systemConfira informações mais detalhadas sobre os pods:
kubectl get pods --all-namespaces -o wide \ --field-selector metadata.namespace!=kube-system
Drenar nós
Escolha uma zona em que você quer simular uma interrupção. Se você realizar o teste de failover do cluster junto com o teste de failover do banco de dados, convém escolher a zona principal da instância do Cloud SQL de alta disponibilidade do seu ambiente.
Por exemplo, se a instância principal do Cloud SQL for executada em us-central1-a, será possível simular uma interrupção em toda a zona us-central1-a. Para isso, primeiro execute o teste de failover do banco de dados e, em seguida, o teste de failover do cluster em us-central1-a.
O comando a seguir simula um conjunto de nós que ficam indisponíveis em uma zona específica. Ele remove à força os pods dos nós na zona especificada e impede a reprogramação dos pods nesses nós. Como não é possível programar novos pods, novos nós são adicionados ao cluster.
Esse comando não afeta as cargas de trabalho executadas no namespace composer-system. Talvez você veja mensagens de erro relacionadas na resposta ao comando. Isso não afeta o teste de failover. Os nós que existem na zona selecionada ainda estão marcados como não programáveis.
Para simular uma falha de zona de cluster na zona selecionada:
kubectl get nodes -o name -l "topology.gke.io/zone=ZONE" | \
xargs kubectl drain \
--ignore-daemonsets --delete-emptydir-data --force --disable-eviction
Substitua:
ZONE: a zona em que você quer simular uma falha de zona do cluster.
Verificar métricas de ambiente
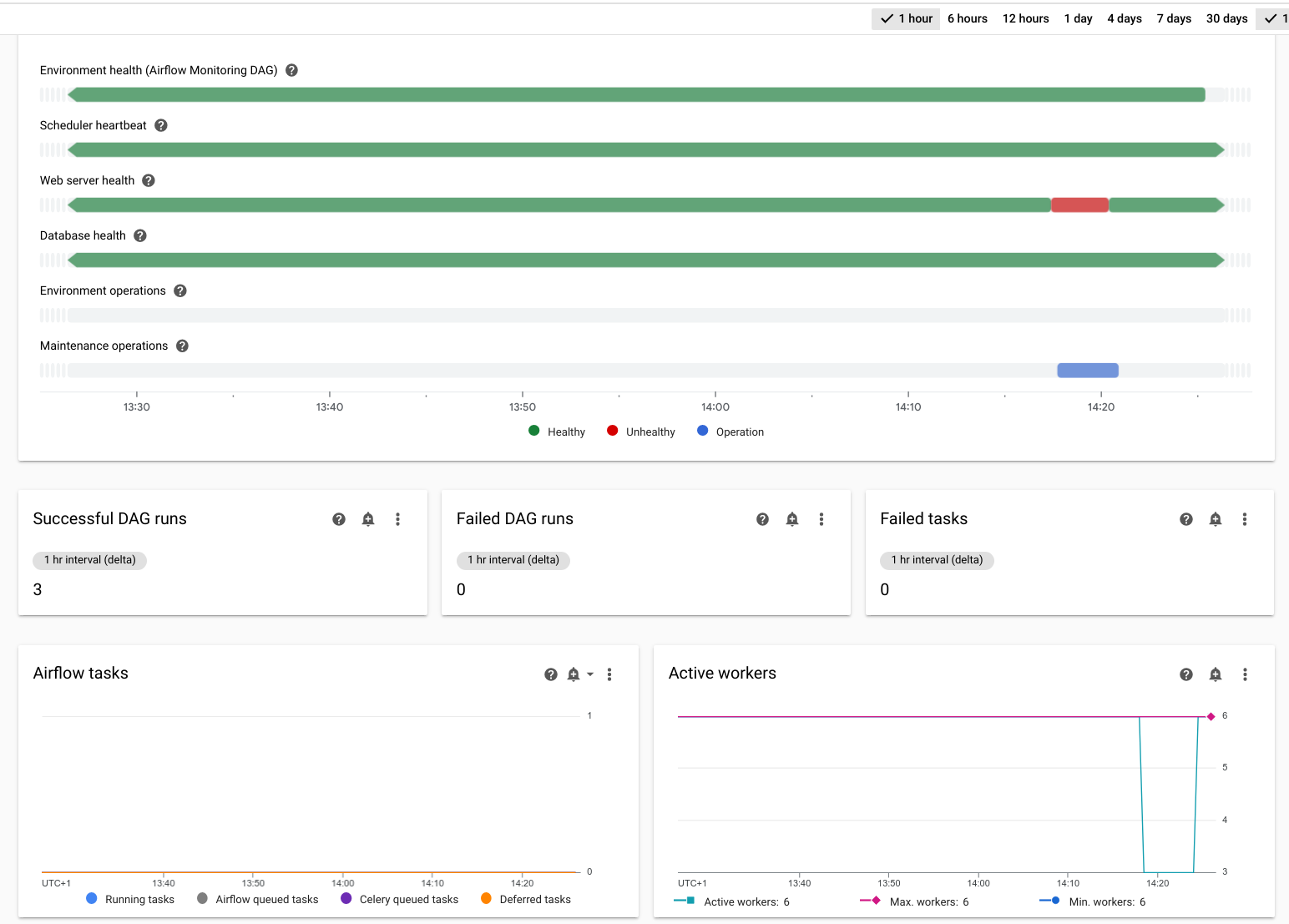
No console Google Cloud , acesse a página Ambientes.
Na lista de ambientes, clique no nome do seu ambiente. A página Detalhes do ambiente é aberta.
Acesse a guia Monitoramento.
Verifique se as seguintes métricas estão "verdes" durante a operação de failover ou permanecem no status "vermelho" por no máximo alguns minutos.
- Integridade do ambiente
- Sinal de funcionamento do programador
- Integridade do servidor da Web
- Integridade do banco de dados
- Workers ativos
- Programadores ativos
- Servidores da Web ativos
- Acionadores ativos
A interrupção simulada é marcada como uma "operação de manutenção do cluster".
Não é necessário fazer mais nada para retornar o cluster do seu ambiente à prontidão para failover após o teste. Durante o teste, o cluster do ambiente adiciona automaticamente novos nós que substituem os afetados pela interrupção simulada.