Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
이 페이지에서는 복원력이 우수한 환경을 위해 데이터베이스 및 클러스터 장애 조치 테스트를 수행하는 방법을 설명합니다.
환경 장애 조치 테스트는 데이터 센터의 특정 영역의 완전한 서비스 중단을 시뮬레이션합니다. 이러한 시나리오에서 클러스터의 영역 서비스 중단과 데이터베이스의 영역 서비스 중단이 동시에 발생할 수 있습니다. 두 가지 장애 조치 테스트를 실행하면 복원력이 우수한 환경에서 장애 조치를 실행하는 방식을 모니터링하고 이로 인해 DAG 및 태스크에 미치는 영향을 확인할 수 있습니다.
시작하기 전에
장애 조치 테스트를 실행하려면 Google 계정에 다음 역할 및 권한이 있어야 합니다.
composer.environments.update권한 이 권한이 있는 역할 목록은 IAM으로 액세스 제어를 참조하세요.환경의 클러스터에서
kubectl명령어를 실행하기 위한 Kubernetes Engine 클러스터 관리자(roles/container.clusterAdmin) 역할 또는 GKE에서 직접 Kubernetes RBAC 역할을 프로비저닝할 수 있습니다.
승인된 네트워크를 사용하는 경우 GKE 클러스터의 제어 영역 엔드포인트에 액세스할 수 있는 머신에서
kubectl명령어를 실행해야 합니다. 환경의 제어 영역 엔드포인트에 대한 액세스를 설정하는 방법에 따라 몇 가지 옵션을 사용할 수 있습니다. 자세한 내용은 비공개 IP 환경에서 명령어 실행을 참조하세요.
환경이 정상인지 확인
장애 조치 테스트는 정상적인 환경에서만 테스트해야 합니다. 환경이 정상인지 확인하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 환경 페이지로 이동합니다.
환경 목록에서 환경 이름을 클릭합니다. 환경 세부정보 페이지가 열립니다.
Monitoring 탭으로 이동합니다.
모든 상태 측정항목이 녹색인지 확인합니다.
데이터베이스 장애 조치 테스트 수행
Google Cloud CLI 명령어로 트리거하여 영역 서비스 중단을 시뮬레이션하는 데이터베이스 장애 조치 테스트를 수행할 수 있습니다. 예를 들어 환경의 데이터베이스가 다른 영역으로 전환하는 데 걸리는 시간을 측정하기 위해 이를 수행할 수 있습니다.
환경에 대해 데이터베이스 장애 조치 테스트를 실행하려면 다음 단계를 따르세요.
환경이 정상인지 확인합니다.
환경 데이터베이스의 기본 영역을 가져옵니다.
gcloud composer environments fetch-database-properties \ ENVIRONMENT_NAME \ --location LOCATION다음을 바꿉니다.
ENVIRONMENT_NAME: Cloud Composer 환경의 이름입니다.LOCATION: 환경이 위치한 리전입니다.
예를 들면 다음과 같습니다.
gcloud composer environments fetch-database-properties \ example-environment \ --location us-central1데이터베이스 장애 조치 테스트를 시작합니다.
gcloud composer environments database-failover \ ENVIRONMENT_NAME \ --location LOCATION다음을 바꿉니다.
ENVIRONMENT_NAME: Cloud Composer 환경의 이름입니다.LOCATION: 환경이 위치한 리전입니다.
예를 들면 다음과 같습니다.
gcloud composer environments database-failover \ example-environment \ --location us-central1데이터베이스 장애 조치 테스트가 완료될 때까지 기다립니다. 이 과정은 최대 3분 정도 걸릴 수 있습니다.
환경 데이터베이스의 기본 영역이 변경되었는지 확인합니다.
gcloud composer environments fetch-database-properties \ ENVIRONMENT_NAME \ --location LOCATION환경의 상태 측정항목을 확인하여 환경이 정상인지 확인합니다.
장애 조치에 사용할 수 있는 데이터베이스(
composer.googleapis.com/environment/database/available_for_failover) 환경 측정항목이True가 되면 환경의 데이터베이스가 다른 장애 조치에 사용할 준비가 됩니다. Cloud Monitoring에서 환경의 측정항목을 보는 방법에 관한 자세한 내용은 환경 모니터링을 참조하세요.
환경의 클러스터 장애 조치 테스트 수행
영역 서비스 중단을 시뮬레이션하는 환경 클러스터에 대해 장애 조치 테스트를 수행할 수 있습니다. 예를 들어 환경이 다른 영역으로 전환하는 데 걸리는 시간을 측정하기 위해 이를 수행할 수 있습니다.
환경이 정상인지 확인
테스트를 시작하기 전에 환경이 정상인지 확인합니다.
환경 클러스터의 사용자 인증 정보 구성
클러스터 사용자 인증 정보를 가져오려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 환경 페이지로 이동합니다.
환경 목록에서 환경 이름을 클릭합니다. 환경 세부정보 페이지가 열립니다.
환경 구성 탭으로 이동합니다.
클러스터 세부정보 보기를 클릭합니다.
연결을 클릭합니다.
표시된 Google Cloud CLI 명령어를 복사하여 실행합니다.
예를 들면 다음과 같습니다.
gcloud container clusters get-credentials \ us-central1-exam-db23ee12-gke \ --region us-central1 \ --project example-project
환경의 클러스터 검사
환경 클러스터에서 워크로드가 실행되는 영역과 노드를 확인합니다. 이 정보를 사용하여 나중에 영역 서비스 중단을 시뮬레이션합니다. 또한 장애 조치 테스트를 수행하는 동안 이러한 명령어를 다시 실행하여 환경 클러스터의 장애 조치 수행 방법을 확인할 수도 있습니다.
노드 및 영역을 확인합니다.
kubectl get nodes \ -o=custom-columns=NAME:.metadata.name,NODE:.metadata.labels.topology\\.gke\\.io/zone포드를 확인합니다.
kubectl get pods --all-namespaces \ -o=custom-columns=NAME:.metadata.name,STATUS:.status.phase,NODE:.spec.nodeName \ --field-selector metadata.namespace!=kube-system포드에 관한 자세한 정보를 확인합니다.
kubectl get pods --all-namespaces -o wide \ --field-selector metadata.namespace!=kube-system
노드 드레이닝
서비스 중단을 시뮬레이션하려는 영역을 선택합니다. 클러스터 장애 조치 테스트를 데이터베이스 장애 조치 테스트와 함께 수행하는 경우 환경의 고가용성 Cloud SQL 인스턴스의 기본 영역을 선택할 수 있습니다.
예를 들어 기본 Cloud SQL 인스턴스가 us-central1-a에서 실행되는 경우 먼저 데이터베이스 장애 조치 테스트를 수행한 다음 클러스터의 장애 조치 테스트를 us-central1-a에서 수행하여 전체 us-central1-a 영역에서 서비스 중단을 시뮬레이션할 수 있습니다.
다음 명령어는 특정 영역에서 사용할 수 없는 노드 집합을 시뮬레이션합니다. 지정된 영역의 노드에서 포드를 강제로 제거하고 이러한 노드에서 포드 재예약을 방지합니다. 새 포드는 예약할 수 없으므로 새 노드가 클러스터에 추가됩니다.
이 명령어는 composer-system 네임스페이스에서 실행되는 워크로드에는 영향을 미치지 않습니다. 명령어 출력에 관련 오류 메시지가 표시될 수 있습니다. 이는 장애 조치 테스트에는 영향을 미치지 않습니다. 선택한 영역에 있는 노드는 예약 불가능으로 계속 표시됩니다.
선택한 영역에서 클러스터 영역 장애를 시뮬레이션하려면 다음 단계를 따르세요.
kubectl get nodes -o name -l "topology.gke.io/zone=ZONE" | \
xargs kubectl drain \
--ignore-daemonsets --delete-emptydir-data --force --disable-eviction
다음을 바꿉니다.
ZONE: 클러스터 영역 오류를 시뮬레이션하려는 영역입니다.
환경 측정항목 확인
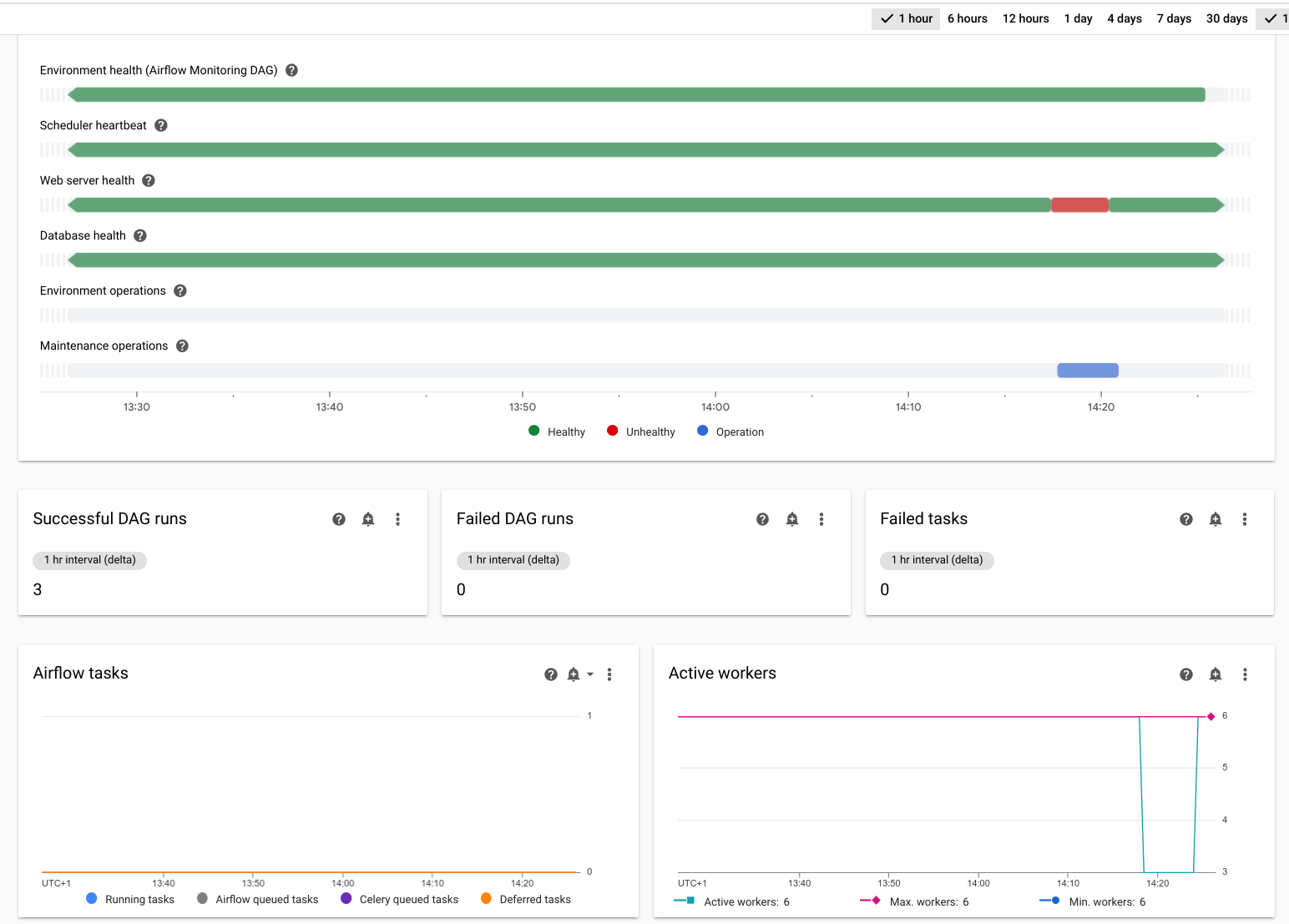
Google Cloud 콘솔에서 환경 페이지로 이동합니다.
환경 목록에서 환경 이름을 클릭합니다. 환경 세부정보 페이지가 열립니다.
Monitoring 탭으로 이동합니다.
장애 조치 작업 중에 다음 측정항목이 '녹색'이거나 최대 몇 분 동안 '빨간색' 상태로 유지되는지 확인합니다.
- 환경 상태
- 스케줄러 하트비트
- 웹 서버 상태
- 데이터베이스 상태
- 활성 작업자
- 활성 스케줄러
- 활성 웹 서버
- 활성 트리거
시뮬레이션된 서비스 중단은 '클러스터 유지보수 작업'으로 표시됩니다.
테스트 후 환경의 클러스터를 장애 조치 준비 상태로 되돌리기 위해 추가 작업을 수행할 필요는 없습니다. 테스트 중 환경 클러스터는 시뮬레이션된 서비스 중단의 영향을 받는 노드를 대체하는 새 노드를 자동으로 추가합니다.