Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
本頁面說明如何透過監控資訊主頁中的重點指標,監控 Cloud Composer 整體環境的健康狀態和效能。
簡介
本教學課程著重於重要的 Cloud Composer 監控指標,可提供環境層級健康狀態和效能的良好總覽。
Cloud Composer 提供多項指標,可說明環境的整體狀態。本教學課程中的監控指南是以 Cloud Composer 環境的監控資訊主頁顯示的指標為依據。
在本教學課程中,您將瞭解可做為環境效能和健康狀態主要指標的關鍵指標,以及如何根據各項指標解讀結果並採取修正措施,確保環境健康無虞。您也會為每個指標設定快訊規則、執行範例 DAG,並使用這些指標和快訊來提升環境效能。
目標
費用
本教學課程使用下列 Google Cloud的計費元件:
完成本教學課程後,您可以刪除建立的資源以避免繼續計費。詳情請參閱「清除」。
事前準備
本節說明開始教學課程前必須執行的動作。
建立及設定專案
本教學課程需要 Google Cloud 專案。請按以下方式設定專案:
在 Google Cloud 控制台中,選取或建立專案:
請確認您已為專案啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
請確認 Google Cloud 專案使用者具有下列角色,可建立必要資源:
- 環境與 Storage 物件管理員
(
roles/composer.environmentAndStorageObjectAdmin) - 運算管理員 (
roles/compute.admin) - 「監控編輯者」 (
roles/monitoring.editor)
- 環境與 Storage 物件管理員
(
為專案啟用 API
Enable the Cloud Composer API.
建立 Cloud Composer 環境
這個程序會將 Cloud Composer v2 API 服務代理人擴充角色 (roles/composer.ServiceAgentV2Ext) 授予 Composer 服務代理人帳戶。Cloud Composer 會使用這個帳戶在專案中執行作業。 Google Cloud
探索環境層級的健康狀態和效能重點指標
本教學課程著重於重要指標,可協助您掌握環境的整體健康狀態和效能。
Google Cloud 控制台中的監控資訊主頁包含各種指標和圖表,可監控環境中的趨勢,並找出 Airflow 元件和 Cloud Composer 資源的問題。
每個 Cloud Composer 環境都有自己的監控資訊主頁。
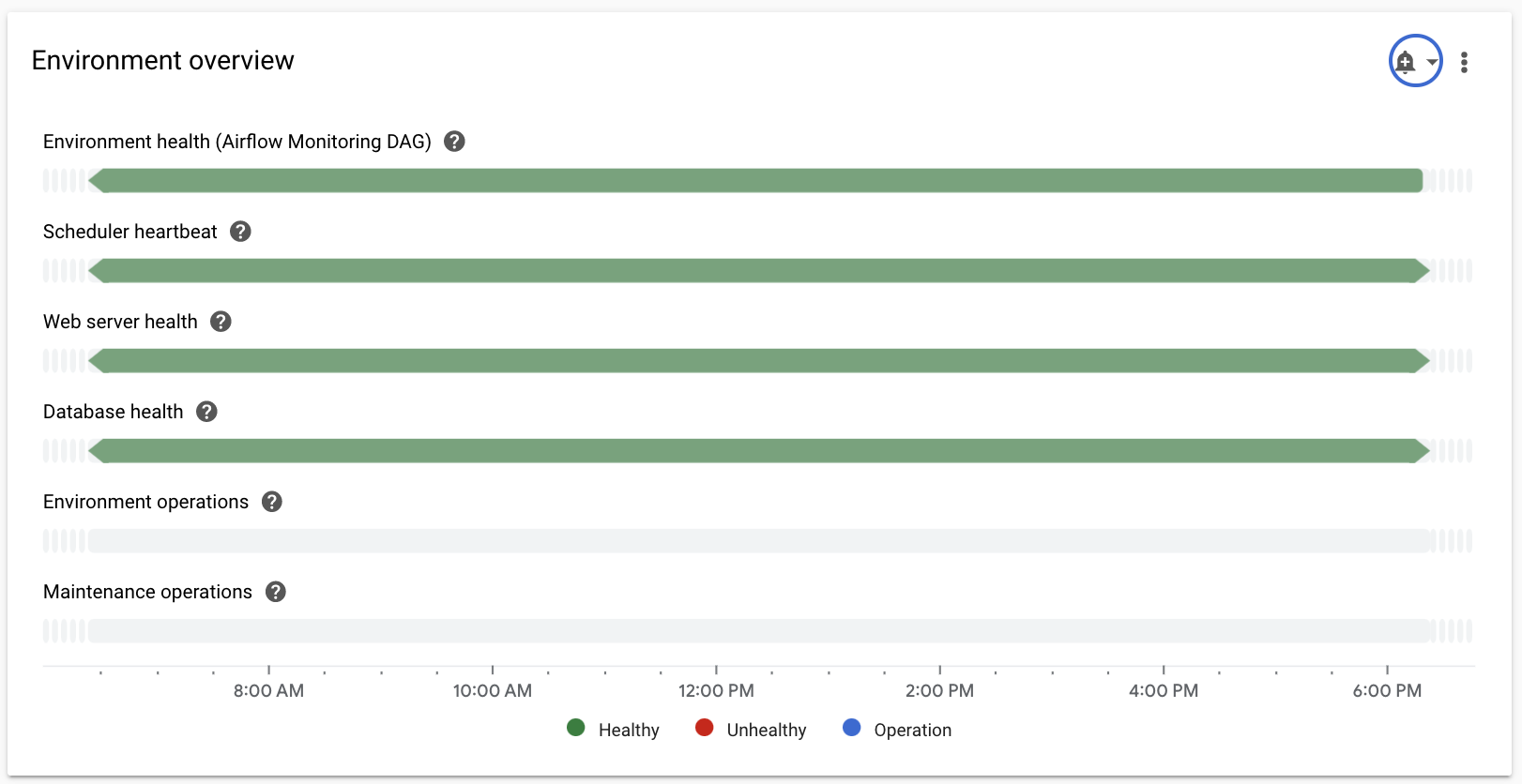
請先熟悉下列重要指標,然後在「監控」資訊主頁中找出各項指標:
前往 Google Cloud 控制台的「Environments」頁面。
在環境清單中,按一下環境名稱。 「環境詳細資料」頁面隨即開啟。
前往「監控」分頁。
選取「總覽」部分,在資訊主頁上找出「環境總覽」項目,然後觀察「環境健康狀態 (Airflow 監控 DAG)」指標。
這條時間軸會顯示 Cloud Composer 環境的健康狀態。環境健康狀態列為綠色,表示環境健康狀態良好;如果環境健康狀態不佳,則會顯示為紅色。
Cloud Composer 每隔幾分鐘就會執行名為
airflow_monitoring的存活 DAG。如果存活 DAG 執行作業順利完成,健康狀態會顯示True。如果執行中的 DAG 失敗 (例如因 Pod 遭移除、外部程序終止或維護作業),健康狀態會顯示為False。
選取「SQL database」(SQL 資料庫) 部分,在資訊主頁上找出「Database health」(資料庫健康狀態) 項目,然後觀察「Database health」(資料庫健康狀態) 指標。
這條時間軸會顯示環境與 Cloud SQL 執行個體的連線狀態。綠色的「資料庫健康狀態」長條表示連線正常,紅色則表示連線失敗。
Airflow 監控 Pod 會定期 ping 資料庫,並在可以建立連線時回報
True健康狀態,否則回報False。
在「資料庫健康狀態」項目中,觀察「資料庫 CPU 使用率」和「資料庫記憶體使用率」指標。
「資料庫 CPU 使用率」圖表會顯示環境中 Cloud SQL 資料庫執行個體的 CPU 核心使用率,以及可用的資料庫 CPU 總限制。
「資料庫記憶體用量」圖表會顯示環境中 Cloud SQL 資料庫執行個體的記憶體用量,以及可用的資料庫記憶體總量上限。
選取「排程器」部分,在資訊主頁上找到「排程器心跳」項目,然後觀察「排程器心跳」指標。
這個時間軸會顯示 Airflow 排程器的健康狀態。檢查紅色區域,找出 Airflow 排程器問題。如果環境有多個排程器,只要至少有一個排程器回應,心跳狀態就會正常。
如果系統在目前時間前 30 秒 (預設值) 內未收到最後一次心跳訊號,就會判定排程器健康狀態不良。
選取「DAG statistics」部分,在資訊主頁上找出「Zombie tasks killed」項目,然後觀察「Zombie tasks killed」指標。
這張圖表顯示在短時間範圍內停止的無效工作數量。無效工作通常是由於 Airflow 程序外部終止 (例如工作程序遭到終止)。
Airflow 排程器會定期停止無效工作,這會反映在這張圖表中。
選取「工作站」部分,在資訊主頁上找出「工作站容器重新啟動」項目,然後觀察「工作站容器重新啟動」指標。
- 圖表會顯示個別工作站容器的重新啟動總次數。容器重新啟動次數過多可能會影響服務可用性,或影響以該服務為依附元件的其他下游服務。
瞭解主要指標的基準和可能的修正措施
以下清單說明可能指出問題的基準值,並提供您可採取的修正措施來解決這些問題。
環境健康狀態 (Airflow 監控 DAG)
4 小時內成功率低於 90%
如果環境過度負載或發生故障,可能會導致 Pod 遭到剔除或工作站終止,進而造成失敗。環境健康時間軸上的紅色區域,通常與個別環境元件其他健康狀態長條圖中的紅色區域相關。查看監控資訊主頁中的其他指標,找出根本原因。
資料庫健康狀態
4 小時內成功率低於 95%
如果發生失敗情形,表示 Airflow 資料庫的連線有問題,可能是因為資料庫當機或停機,或是資料庫過載 (例如 CPU 或記憶體使用率過高,或連線至資料庫時延遲時間較長)。這些症狀最常是由次佳 DAG 造成,例如 DAG 使用許多全域定義的 Airflow 或環境變數。查看 SQL 資料庫資源用量指標,找出根本原因。您也可以檢查排程器記錄,找出與資料庫連線相關的錯誤。
資料庫 CPU 和記憶體用量
在 12 小時的時間範圍內,平均 CPU 或記憶體使用率超過 80%
資料庫可能超載。分析 DAG 執行作業與資料庫 CPU 或記憶體用量尖峰之間的關聯性。
您可以透過效率更高的 DAG,以及最佳化的執行查詢和連線,降低資料庫負載,也可以在一段時間內更平均地分散負載。
或者,您也可以為資料庫分配更多 CPU 或記憶體。資料庫資源由環境的環境大小屬性控管,且環境必須擴大。
排程器活動訊號
4 小時內成功率低於 90%
為排程器指派更多資源,或將排程器數量從 1 增加至 2 (建議做法)。
已停止的無效工作
每 24 小時內出現多個殭屍工作
僵屍工作最常見的原因是環境叢集中的 CPU 或記憶體資源不足。查看工作站資源用量圖表,並為工作站指派更多資源,或延長閒置工作逾時時間,讓排程器等待更久,才將工作視為閒置工作。
工作站容器重新啟動
24 小時內重新啟動超過一次
最常見的原因是工作站記憶體或儲存空間不足。請調查工作站的資源消耗量,並為工作站分配更多記憶體或儲存空間。如果資源不足不是原因,請參閱疑難排解工作站重新啟動事件,並使用記錄查詢找出工作站重新啟動的原因。
建立通知管道
按照「建立通知管道」一文中的操作說明,建立電子郵件通知管道。
如要進一步瞭解通知管道,請參閱「管理通知管道」。
建立快訊政策
根據本教學課程先前章節提供的基準建立警告政策,持續監控指標值,並在這些指標違反條件時收到通知。
主控台
如要為 Monitoring 資訊主頁中顯示的每個指標設定快訊,請按一下對應項目角落的鈴鐺圖示:
在 Monitoring 資訊主頁中找出要監控的指標,然後按一下指標項目角落的鈴鐺圖示。「建立快訊政策」頁面隨即開啟。
在「轉換資料」部分:
按照指標的警報政策設定,設定「每個時間序列內」部分。
按一下「下一步」,然後按照指標的快訊政策設定說明,設定「設定快訊觸發條件」部分。
點選「下一步」。
設定通知。展開「Notification channels」(通知管道) 選單,然後選取您在上一步中建立的通知管道。
按一下 [確定]。
在「為快訊政策命名」部分,填寫「快訊政策名稱」欄位。為每個指標使用描述性名稱。請使用「Name the alert policy」(為快訊政策命名) 值,如指標的快訊政策設定所述。
點選「下一步」。
檢查快訊政策,然後按一下「建立政策」。
環境健康狀態 (Airflow 監控 DAG) 指標 - 快訊政策設定
- 指標名稱:Cloud Composer 環境 - 正常
- API:composer.googleapis.com/environment/healthy
篩選器:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]轉換資料 > 每個時間序列內:
- 滾動週期:自訂
- 自訂值:4
- 自訂單位:小時
- 滾動週期函式:true 比例
設定快訊觸發條件:
- 條件類型:門檻
- 快訊觸發條件:任何時間序列違反條件時
- 門檻位置:低於門檻
- 門檻值:90
- 條件名稱:環境健康狀態條件
設定通知並完成快訊:
- 將警告政策命名為:Airflow Environment Health
資料庫健康指標 - 快訊政策設定
- 指標名稱:Cloud Composer 環境 - 資料庫運作正常
- API:composer.googleapis.com/environment/database_health
篩選器:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]轉換資料 > 每個時間序列內:
- 滾動週期:自訂
- 自訂值:4
- 自訂單位:小時
- 滾動週期函式:true 比例
設定快訊觸發條件:
- 條件類型:門檻
- 快訊觸發條件:任何時間序列違反條件時
- 門檻位置:低於門檻
- 門檻值:95
- 條件名稱:資料庫健康狀態條件
設定通知並完成快訊:
- 將警告政策命名為:Airflow Database Health
資料庫 CPU 使用率指標 - 快訊政策設定
- 指標名稱:Cloud Composer 環境 - 資料庫 CPU 使用率
- API:composer.googleapis.com/environment/database/cpu/utilization
篩選器:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]轉換資料 > 每個時間序列內:
- 滾動週期:自訂
- 自訂值:12
- 自訂單位:小時
- 滾動週期函式:平均值
設定快訊觸發條件:
- 條件類型:門檻
- 快訊觸發條件:任何時間序列違反條件時
- 門檻位置:高於門檻
- 門檻值:80
- 條件名稱:資料庫 CPU 使用率條件
設定通知並完成快訊:
- 將警告政策命名為「Airflow Database CPU Usage」
資料庫記憶體用量指標 - 快訊政策設定
- 指標名稱:Cloud Composer 環境 - 資料庫記憶體使用率
- API:composer.googleapis.com/environment/database/memory/utilization
篩選器:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]轉換資料 > 每個時間序列內:
- 滾動週期:自訂
- 自訂值:12
- 自訂單位:小時
- 滾動週期函式:平均值
設定快訊觸發條件:
- 條件類型:門檻
- 快訊觸發條件:任何時間序列違反條件時
- 門檻位置:高於門檻
- 門檻值:80
- 條件名稱:資料庫記憶體用量條件
設定通知並完成快訊:
- 將警告政策命名為:Airflow Database Memory Usage
排程器活動訊號指標 - 快訊政策設定
- 指標名稱:Cloud Composer 環境 - 排程器心跳
- API:composer.googleapis.com/environment/scheduler_heartbeat_count
篩選器:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]轉換資料 > 每個時間序列內:
- 滾動週期:自訂
- 自訂值:4
- 自訂單位:小時
- 滾動週期函式:count
設定快訊觸發條件:
- 條件類型:門檻
- 快訊觸發條件:任何時間序列違反條件時
- 門檻位置:低於門檻
門檻值:216
- 如要取得這個數字,請在指標探索器查詢編輯器中,執行會匯總
_scheduler_heartbeat_count_mean值的查詢。
- 如要取得這個數字,請在指標探索器查詢編輯器中,執行會匯總
條件名稱:排程器活動訊號條件
設定通知並完成快訊:
- 將警告政策命名為:Airflow 排程器活動訊號
已停止的無效工作指標 - 快訊政策設定
- 指標名稱:Cloud Composer 環境 - 已停止的無效工作
- API:composer.googleapis.com/environment/zombie_task_killed_count
篩選器:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]轉換資料 > 每個時間序列內:
- 滾動週期:1 天
- 滾動週期函式:總和
設定快訊觸發條件:
- 條件類型:門檻
- 快訊觸發條件:任何時間序列違反條件時
- 門檻位置:高於門檻
- 門檻值:1
- 條件名稱:無效工作條件
設定通知並完成快訊:
- 將警告政策命名為:Airflow Zombie Tasks
工作站容器重新啟動指標 - 快訊政策設定
- 指標名稱:Kubernetes 容器 - 重新啟動次數
- API:kubernetes.io/container/restart_count
篩選器:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION] pod_name =~ airflow-worker-.*|airflow-k8s-worker-.* container_name =~ airflow-worker|base cluster_name = [CLUSTER_NAME]CLUSTER_NAME是您環境的叢集名稱,可在 Google Cloud 主控台的「環境設定」>「資源」>「GKE 叢集」下方找到。轉換資料 > 每個時間序列內:
- 滾動週期:1 天
- 滾動週期函式:速率
設定快訊觸發條件:
- 條件類型:門檻
- 快訊觸發條件:任何時間序列違反條件時
- 門檻位置:高於門檻
- 門檻值:1
- 條件名稱:工作站容器重新啟動條件
設定通知並完成快訊:
- 將警告政策命名為「Airflow Worker Restarts」
Terraform
執行 Terraform 指令碼,建立電子郵件通知管道,並根據本教學課程中提供的各項重要指標及其基準,上傳對應的快訊政策:
- 將範例 Terraform 檔案儲存到本機電腦。
更改下列內容:
PROJECT_ID:專案的專案 ID。例如:example-project。EMAIL_ADDRESS:觸發快訊時必須通知的電子郵件地址。ENVIRONMENT_NAME:Cloud Composer 環境的名稱。 例如:example-composer-environment。CLUSTER_NAME:您的環境叢集名稱,可在「環境設定」>「資源」>「GKE 叢集」 Google Cloud 控制台中找到。
resource "google_monitoring_notification_channel" "basic" {
project = "PROJECT_ID"
display_name = "Test Notification Channel"
type = "email"
labels = {
email_address = "EMAIL_ADDRESS"
}
# force_delete = false
}
resource "google_monitoring_alert_policy" "environment_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Environment Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Environment health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/healthy\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.9
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "database_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Database Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database_health\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.95
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_cpu_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database CPU Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database CPU usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/cpu/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_memory_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database Memory Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database memory usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/memory/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_scheduler_heartbeat" {
project = "PROJECT_ID"
display_name = "Airflow Scheduler Heartbeat"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Scheduler heartbeat condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/scheduler_heartbeat_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 216 // Threshold is 90% of the average for composer.googleapis.com/environment/scheduler_heartbeat_count metric in an idle environment
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_COUNT"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_zombie_task" {
project = "PROJECT_ID"
display_name = "Airflow Zombie Tasks"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Zombie tasks condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/zombie_task_killed_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_SUM"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_worker_restarts" {
project = "PROJECT_ID"
display_name = "Airflow Worker Restarts"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Worker container restarts condition"
condition_threshold {
filter = "resource.type = \"k8s_container\" AND (resource.labels.cluster_name = \"CLUSTER_NAME\" AND resource.labels.container_name = monitoring.regex.full_match(\"airflow-worker|base\") AND resource.labels.pod_name = monitoring.regex.full_match(\"airflow-worker-.*|airflow-k8s-worker-.*\")) AND metric.type = \"kubernetes.io/container/restart_count\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_RATE"
}
}
}
}
測試快訊政策
本節說明如何測試建立的快訊政策,以及解讀結果。
上傳範例 DAG
本教學課程提供的範例 DAG memory_consumption_dag.py 會模擬大量使用工作站記憶體的情況。DAG 包含 4 項工作,每項工作都會將資料寫入範例字串,耗用 380 MB 的記憶體。範例 DAG 排定每 2 分鐘執行一次,上傳至 Composer 環境後就會自動開始執行。
上傳下列範例 DAG 至您在上一個步驟中建立的環境:
from datetime import datetime
import sys
import time
from airflow import DAG
from airflow.operators.python import PythonOperator
def ram_function():
data = ""
start = time.time()
for i in range(38):
data += "a" * 10 * 1000**2
time.sleep(0.2)
print(f"{i}, {round(time.time() - start, 4)}, {sys.getsizeof(data) / (1000 ** 3)}")
print(f"Size={sys.getsizeof(data) / (1000 ** 3)}GB")
time.sleep(30 - (time.time() - start))
print(f"Complete in {round(time.time() - start, 2)} seconds!")
with DAG(
dag_id="memory_consumption_dag",
start_date=datetime(2023, 1, 1, 1, 1, 1),
schedule="1/2 * * * *",
catchup=False,
) as dag:
for i in range(4):
PythonOperator(
task_id=f"task_{i+1}",
python_callable=ram_function,
retries=0,
dag=dag,
)
解讀 Monitoring 中的快訊和指標
範例 DAG 開始執行後,請等待約 10 分鐘,然後評估測試結果:
檢查電子郵件信箱,確認您收到來自「Alerting」Google Cloud 的通知,且主旨開頭為「
[ALERT]」。這封郵件的內容包含快訊政策事件詳細資料。按一下電子郵件通知中的「查看事件」按鈕。系統會將您重新導向至 Metrics Explorer。查看警報事件的詳細資料:
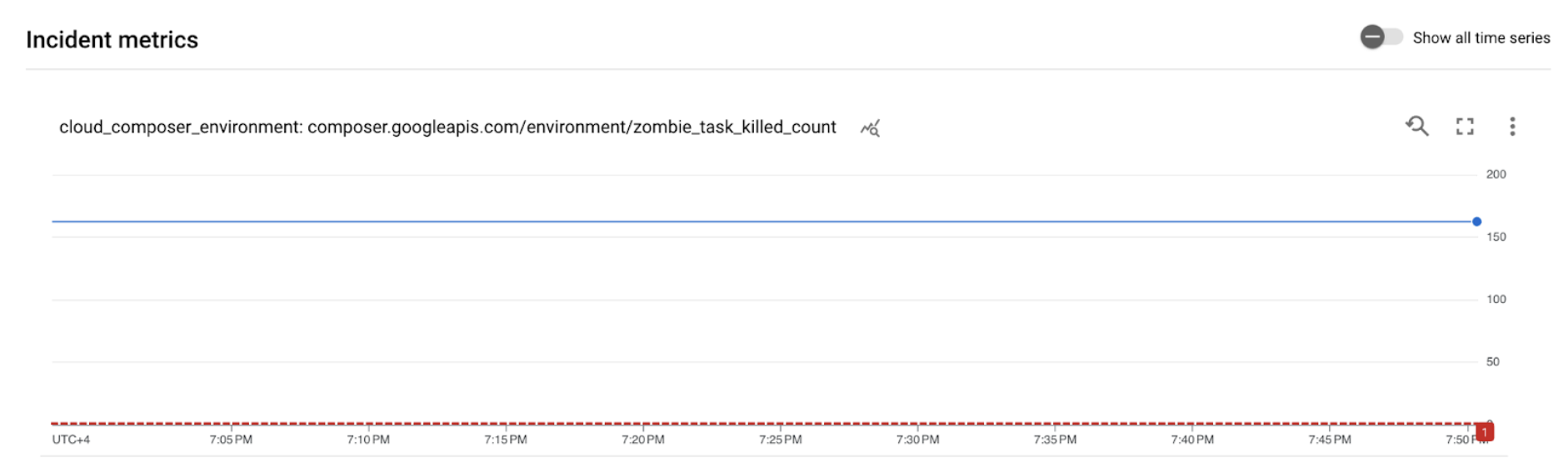
圖 2. 快訊事件的詳細資料 (按一下即可放大) 事件指標圖表顯示您建立的指標超過門檻 1,表示 Airflow 偵測到並終止了 1 個以上的殭屍工作。
在 Cloud Composer 環境中,前往「監控」分頁,開啟「DAG 統計資料」部分,然後找出「已終止的殭屍工作」圖表:
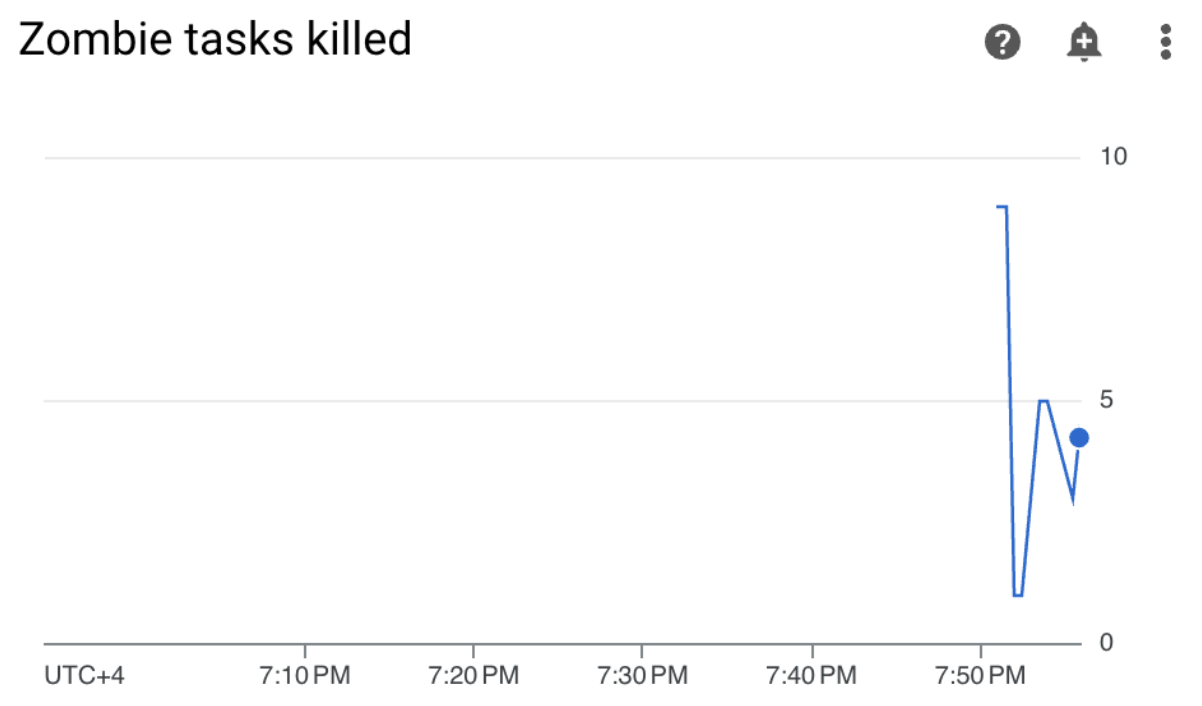
圖 3. 殭屍工作圖表 (按一下即可放大) 圖表顯示,在執行範例 DAG 的前 10 分鐘內,Airflow 廢止了約 20 個無效工作。
根據基準和修正措施,殭屍工作最常見的原因是工作站記憶體或 CPU 不足。分析工作站資源用量,找出閒置工作任務的根本原因。
開啟監控資訊主頁的「工作人員」部分,然後查看工作人員的 CPU 和記憶體用量指標:
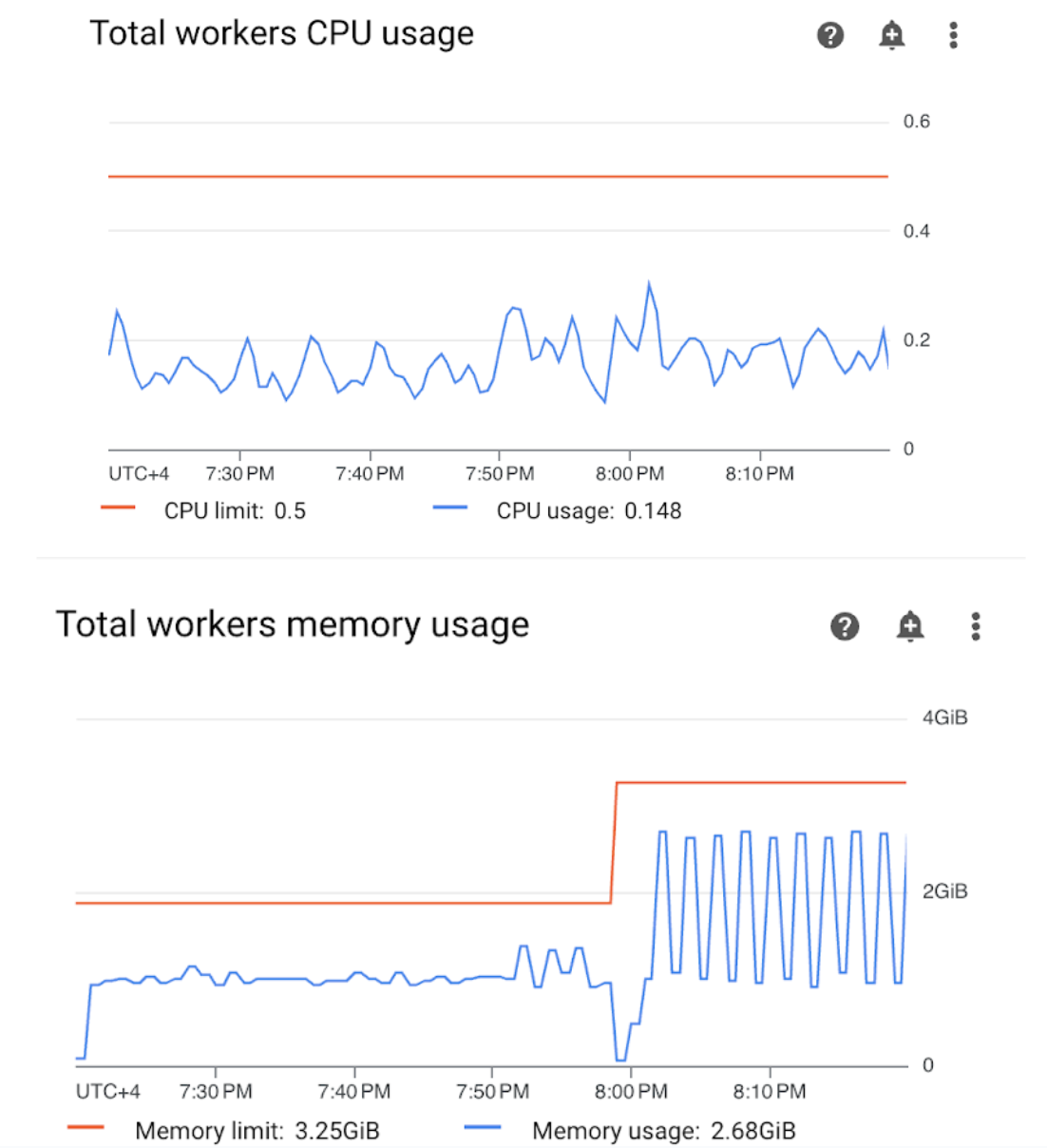
圖 4. 工作人員 CPU 和記憶體用量指標 (按一下即可放大) 「工作站 CPU 使用率總計」圖表顯示,工作站 CPU 使用率一律低於可用總限制的 50%,因此可用 CPU 充足。「工作站記憶體總用量」圖表顯示,執行範例 DAG 會達到可分配的記憶體上限,這幾乎等於圖表上顯示的記憶體總上限的 75% (GKE 會保留每個節點前 4 GiB 記憶體的 25%,以及額外 100 MiB 的記憶體,以處理 Pod 逐出作業)。
由此可見,工作站缺乏記憶體資源,無法順利執行範例 DAG。
最佳化環境並評估效能
根據工作站資源使用率分析結果,您需要為 DAG 中的所有工作分配更多記憶體,才能順利完成工作。
在 Composer 環境中,開啟「DAG」分頁,按一下範例 DAG (
memory_consumption_dag) 的名稱,然後按一下「暫停 DAG」。分配額外工作站記憶體:
在「Environment configuration」(環境設定) 分頁中,找到「Resources」(資源) >「Workloads」(工作負載) 設定,然後按一下「Edit」(編輯)。
在「Worker」項目中,提高「Memory」限制。在本教學課程中,請使用 3.25 GB。
儲存變更,並等待工作站重新啟動 (可能需要幾分鐘)。
開啟「DAG」分頁,按一下範例 DAG 的名稱 (
memory_consumption_dag),然後按一下「取消暫停 DAG」。
前往「監控」,確認更新工作站資源限制後,沒有出現新的殭屍工作:
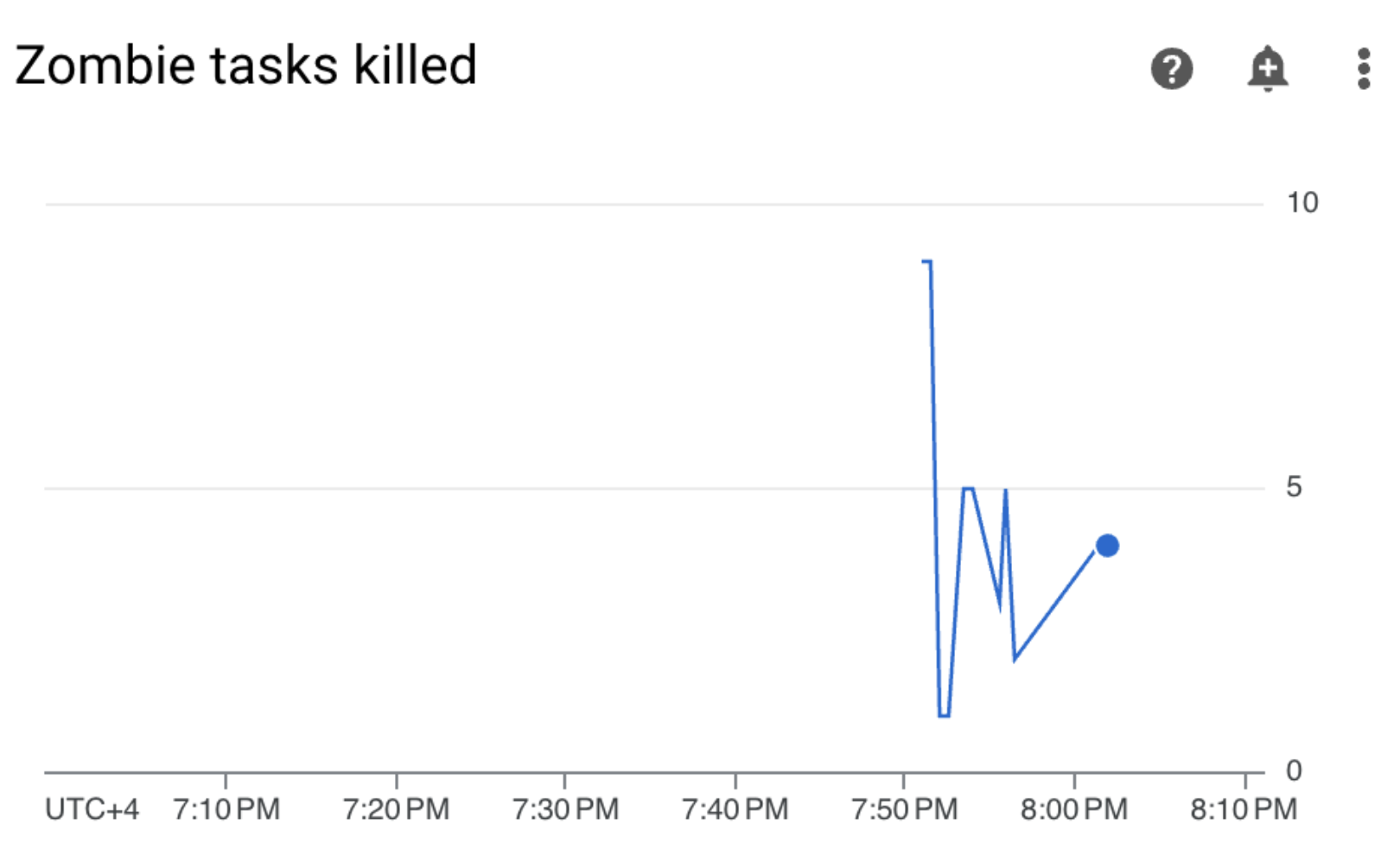
摘要
在本教學課程中,您已瞭解環境層級的重要健康狀態和效能指標、如何為每個指標設定快訊政策,以及如何根據每個指標採取修正措施。接著執行範例 DAG,並透過快訊和監控圖表找出環境健康狀態問題的根本原因,然後為工作人員分配更多記憶體,藉此改善環境。不過,建議您先最佳化 DAG,減少工作站資源耗用量,因為資源無法超過特定門檻。
清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取本教學課程所用資源的費用,請刪除含有相關資源的專案,或者保留專案但刪除個別資源。
刪除專案
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
刪除個別資源
如果打算進行多個教學課程及快速入門導覽課程,重複使用專案有助於避免超出專案配額限制。
主控台
- 刪除 Cloud Composer 環境。您也可以在執行這項程序時刪除環境的 bucket。
- 刪除您在 Cloud Monitoring 中建立的每項警告政策。
Terraform
- 請確認 Terraform 指令碼未包含專案仍需的資源項目。舉例來說,您可能想保留部分已啟用的 API,並繼續指派 IAM 權限 (如果您已在 Terraform 腳本中新增這類定義)。
- 執行
terraform destroy。 - 手動刪除環境的值區。Cloud Composer 不會自動刪除。您可以透過 Google Cloud 控制台或 Google Cloud CLI 執行這項操作。