Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
En esta página se describe cómo usar el DataflowTemplateOperator para lanzar flujos de procesamiento de Dataflow desde Cloud Composer.
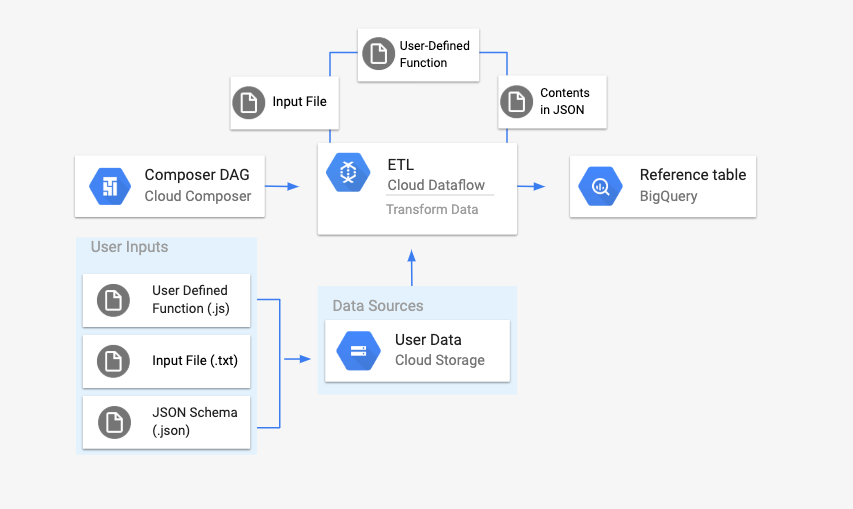
El flujo de procesamiento de archivos de texto de Cloud Storage a BigQuery
es un flujo de procesamiento por lotes que te permite subir archivos de texto almacenados en Cloud Storage, transformarlos mediante una función de JavaScript definida por el usuario (UDF) que proporciones y, por último, mostrar los resultados en BigQuery.
Información general
Antes de iniciar el flujo de trabajo, crearás las siguientes entidades:
Una tabla de BigQuery vacía de un conjunto de datos vacío que contendrá las siguientes columnas de información:
location,average_temperature,monthy, opcionalmente,inches_of_rain,is_currentylatest_measurement.Un archivo JSON que normalizará los datos del archivo
.txtal formato correcto para el esquema de la tabla de BigQuery. El objeto JSON tendrá una matriz deBigQuery Schema, donde cada objeto contendrá un nombre de columna, un tipo de entrada y si es un campo obligatorio o no.Un archivo
.txtde entrada que contendrá los datos que se subirán en lote a la tabla de BigQuery.Una función definida por el usuario escrita en JavaScript que transformará cada línea del archivo
.txten las variables pertinentes de nuestra tabla.Un archivo DAG de Airflow que apuntará a la ubicación de estos archivos.
A continuación, sube el archivo
.txt, el archivo.jsUDF y el archivo de esquema.jsona un segmento de Cloud Storage. También subirás el DAG a tu entorno de Cloud Composer.Una vez que se haya subido el DAG, Airflow ejecutará una tarea a partir de él. Esta tarea iniciará una canalización de Dataflow que aplicará la función definida por el usuario al archivo
.txty le dará formato según el esquema JSON.Por último, los datos se subirán a la tabla de BigQuery que has creado anteriormente.
Antes de empezar
- Para escribir la función definida por el usuario, debes tener conocimientos de JavaScript.
- En esta guía se da por hecho que ya tienes un entorno de Cloud Composer. Consulta Crear un entorno para crear uno. Puedes usar cualquier versión de Cloud Composer con esta guía.
Enable the Cloud Composer, Dataflow, Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.Asegúrate de que tienes los siguientes permisos:
- Roles de Cloud Composer: crea un entorno (si no tienes ninguno), gestiona objetos en el segmento del entorno, ejecuta DAGs y accede a la interfaz de usuario de Airflow.
- Roles de Cloud Storage: crea un segmento y gestiona los objetos que contiene.
- Roles de BigQuery: crear un conjunto de datos y una tabla, modificar los datos de la tabla, modificar el esquema y los metadatos de la tabla.
- Roles de Dataflow: consulta las tareas de Dataflow.
Asegúrate de que la cuenta de servicio de tu entorno tenga permisos para crear trabajos de Dataflow, acceder al segmento de Cloud Storage y leer y actualizar datos de la tabla en BigQuery.
Crear una tabla de BigQuery vacía con una definición de esquema
Crea una tabla de BigQuery con una definición de esquema. Usarás esta definición de esquema más adelante en esta guía. Esta tabla de BigQuery contendrá los resultados de la subida por lotes.
Para crear una tabla vacía con una definición de esquema, sigue estos pasos:
Consola
En la Google Cloud consola, ve a la página BigQuery:
En el panel de navegación, en la sección Recursos, despliega tu proyecto.
En el panel de detalles, haz clic en Crear conjunto de datos.
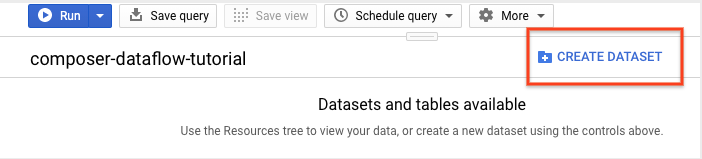
En la página Crear conjunto de datos, en la sección ID del conjunto de datos, asigna un nombre al conjunto de datos
average_weather. Deja el resto de los campos con su valor predeterminado.
Haz clic en Crear conjunto de datos.
Vuelve al panel de navegación y, en la sección Recursos, despliega tu proyecto. A continuación, haga clic en el conjunto de datos
average_weather.En el panel de detalles, haz clic en Crear tabla.

En la página Crear tabla, ve a la sección Fuente y selecciona Tabla vacía.
En la página Crear tabla, ve a la sección Destino:
En Nombre del conjunto de datos, elige el conjunto de datos
average_weather.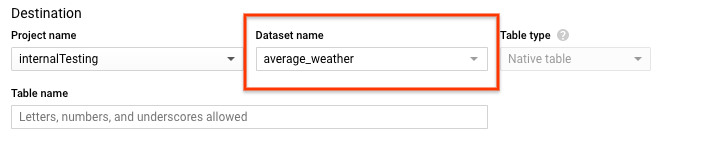
En el campo Nombre de la tabla, introduce el nombre
average_weather.Verifica que el Tipo de tabla sea Tabla nativa.
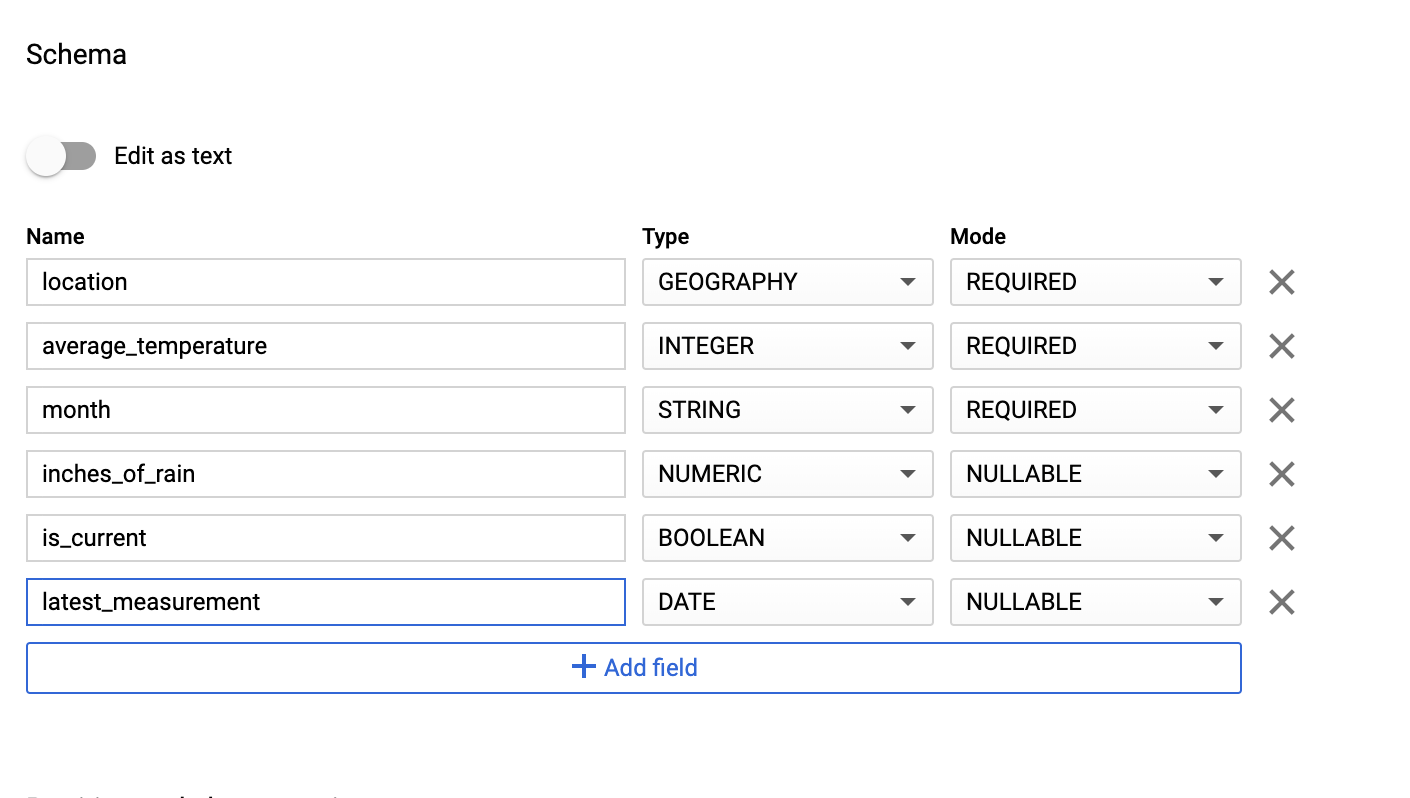
En la sección Schema (Esquema), introduce la definición de schema. Puedes usar uno de los siguientes métodos:
Introduce la información del esquema manualmente. Para ello, habilita la opción Editar como texto e introduce el esquema de la tabla como una matriz JSON. Escribe lo siguiente en los campos:
[ { "name": "location", "type": "GEOGRAPHY", "mode": "REQUIRED" }, { "name": "average_temperature", "type": "INTEGER", "mode": "REQUIRED" }, { "name": "month", "type": "STRING", "mode": "REQUIRED" }, { "name": "inches_of_rain", "type": "NUMERIC" }, { "name": "is_current", "type": "BOOLEAN" }, { "name": "latest_measurement", "type": "DATE" } ]Usa Añadir campo para introducir el esquema manualmente:
En Configuración de partición y clústeres, deja el valor predeterminado,
No partitioning.En la sección Opciones avanzadas, en Cifrado, deje el valor predeterminado,
Google-owned and managed key.Haz clic en Crear tabla.
bq
Usa el comando bq mk para crear un conjunto de datos vacío y una tabla en este conjunto de datos.
Ejecuta el siguiente comando para crear un conjunto de datos con la media del tiempo global:
bq --location=LOCATION mk \
--dataset PROJECT_ID:average_weather
Haz los cambios siguientes:
LOCATION: la región en la que se encuentra el entorno.PROJECT_ID: el ID de proyecto.
Ejecuta el siguiente comando para crear una tabla vacía en este conjunto de datos con la definición de esquema:
bq mk --table \
PROJECT_ID:average_weather.average_weather \
location:GEOGRAPHY,average_temperature:INTEGER,month:STRING,inches_of_rain:NUMERIC,is_current:BOOLEAN,latest_measurement:DATE
Una vez creada la tabla, puede actualizar su fecha de vencimiento, su descripción y sus etiquetas. También puedes modificar la definición del esquema.
Python
Guarda este código como
dataflowtemplateoperator_create_dataset_and_table_helper.py
y actualiza las variables para que reflejen tu proyecto y tu ubicación. A continuación, ejecuta el código con el siguiente comando:
python dataflowtemplateoperator_create_dataset_and_table_helper.py
Python
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Crea un segmento de Cloud Storage
Crea un segmento para almacenar todos los archivos necesarios para el flujo de trabajo. El DAG que crees más adelante en esta guía hará referencia a los archivos que subas a este segmento de almacenamiento. Para crear un nuevo segmento de almacenamiento, sigue estos pasos:
Consola
Abre Cloud Storage en la Google Cloud consola.
Haz clic en Crear segmento para abrir el formulario de creación de segmentos.
Introduce la información del contenedor y haz clic en Continuar para completar cada paso:
Especifique un nombre único a nivel global para el segmento. En esta guía se usa
bucketNamecomo ejemplo.Seleccione Región como tipo de ubicación. A continuación, selecciona una ubicación donde se almacenarán los datos del segmento.
Selecciona Estándar como clase de almacenamiento predeterminada para tus datos.
Selecciona el control de acceso Uniforme para acceder a tus objetos.
Haz clic en Listo.
gcloud
Usa el comando gcloud storage buckets create:
gcloud storage buckets create gs://bucketName/
Haz los cambios siguientes:
bucketName: el nombre del segmento que has creado anteriormente en esta guía.
Códigos de ejemplo
C#
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Go
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Java
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Python
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Ruby
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Crear un esquema de BigQuery en formato JSON para la tabla de salida
Crea un archivo de esquema de BigQuery con formato JSON que coincida con la tabla de salida que has creado anteriormente. Ten en cuenta que los nombres, los tipos y los modos de los campos deben coincidir con los definidos anteriormente en el esquema de tu tabla de BigQuery. Este archivo normalizará los datos de tu archivo .txt en un formato compatible con tu esquema de BigQuery. Dale el nombre jsonSchema.json a este archivo.
{
"BigQuery Schema": [
{
"name": "location",
"type": "GEOGRAPHY",
"mode": "REQUIRED"
},
{
"name": "average_temperature",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "month",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "inches_of_rain",
"type": "NUMERIC"
},
{
"name": "is_current",
"type": "BOOLEAN"
},
{
"name": "latest_measurement",
"type": "DATE"
}]
}
Crear un archivo JavaScript para dar formato a los datos
En este archivo, definirás la función definida por el usuario (UDF) que ofrece la lógica necesaria para transformar las líneas de texto del archivo de entrada. Ten en cuenta que esta función toma cada línea de texto de tu archivo de entrada como un argumento independiente, por lo que la función se ejecutará una vez por cada línea del archivo de entrada. Dale el nombre transformCSVtoJSON.js a este archivo.
Crear un archivo de entrada
Este archivo contendrá la información que quieras subir a tu tabla de BigQuery. Copia este archivo localmente y llámalo
inputFile.txt.
POINT(40.7128 74.006),45,'July',null,true,2020-02-16
POINT(41.8781 87.6298),23,'October',13,false,2015-02-13
POINT(48.8566 2.3522),80,'December',null,true,null
POINT(6.5244 3.3792),15,'March',14,true,null
Subir archivos a un segmento
Sube los siguientes archivos al segmento de Cloud Storage que has creado anteriormente:
- Esquema de BigQuery en formato JSON (
.json) - Función definida por el usuario de JavaScript (
transformCSVtoJSON.js) El archivo de entrada del texto que quieras procesar (
.txt)
Consola
- En la Google Cloud consola, ve a la página Segmentos de Cloud Storage.
En la lista de contenedores, haga clic en el suyo.
En la pestaña Objetos del cubo, haga una de las siguientes acciones:
Arrastra los archivos que quieras desde el escritorio o el gestor de archivos hasta el panel principal de la Google Cloud consola.
Haz clic en el botón Subir archivos, selecciona los archivos que quieras subir en el cuadro de diálogo que aparece y haz clic en Abrir.
gcloud
Ejecuta el comando gcloud storage cp:
gcloud storage cp OBJECT_LOCATION gs://bucketName
Haz los cambios siguientes:
bucketName: el nombre del segmento que has creado anteriormente en esta guía.OBJECT_LOCATION: la ruta local a tu objeto. Por ejemplo,Desktop/transformCSVtoJSON.js.
Códigos de ejemplo
Python
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Ruby
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Configurar DataflowTemplateOperator
Antes de ejecutar el DAG, define las siguientes variables de Airflow.
| Variable de Airflow | Valor |
|---|---|
project_id
|
El ID del proyecto. Ejemplo: example-project. |
gce_zone
|
Zona de Compute Engine en la que se debe crear el clúster de Dataflow. Ejemplo: us-central1-a Para obtener más información sobre las zonas válidas, consulta Regiones y zonas. |
bucket_path
|
Ubicación del segmento de Cloud Storage que has creado anteriormente. Ejemplo: gs://example-bucket |
Ahora harás referencia a los archivos que has creado anteriormente para crear un DAG que inicie el flujo de trabajo de Dataflow. Copia este DAG y guárdalo localmente
como composer-dataflow-dag.py.
Airflow 2
Airflow 1
Sube el DAG a Cloud Storage
Sube tu DAG a la carpeta /dags del bucket de tu entorno. Una vez que se haya completado la subida correctamente, podrá verlo haciendo clic en el enlace Carpeta DAGs de la página Entornos de Cloud Composer.
Ver el estado de la tarea
- Ve a la interfaz web de Airflow.
- En la página de los DAGs, haz clic en el nombre del DAG (por ejemplo,
composerDataflowDAG). - En la página Detalles de los DAGs, haz clic en Vista de gráfico.
Comprobar el estado:
Failed: La tarea tiene un recuadro rojo alrededor. También puedes mantener el puntero sobre la tarea y buscar Estado: Fallido.Success: La tarea tiene un recuadro verde. También puedes mantener el puntero sobre la tarea y comprobar si aparece el mensaje Estado: Éxito.
Después de unos minutos, puedes consultar los resultados en Dataflow y BigQuery.
Ver tu trabajo en Dataflow
En la Google Cloud consola, ve a la página Dataflow.
Tu tarea se llama
dataflow_operator_transform_csv_to_bqy tiene un ID único que se añade al final del nombre con un guion, de esta forma:
Haz clic en el nombre para ver los detalles del trabajo.
Ver los resultados en BigQuery
En la Google Cloud consola, ve a la página BigQuery.
Puedes enviar consultas con SQL estándar. Usa la siguiente consulta para ver las filas que se han añadido a tu tabla:
SELECT * FROM projectId.average_weather.average_weather