PyTorch on Google Cloud: How To train and tune PyTorch models on Vertex AI
Rajesh Thallam
Machine Learning Specialist, Cloud Customer Engineer
Vaibhav Singh
Group Product Manager
Since the publishing of the inaugural post of PyTorch on Google Cloud blog series, we announced Vertex AI: Google Cloud’s end-to-end ML platform at Google I/O 2021. Vertex AI unifies Google Cloud’s existing ML offerings into a single platform for efficiently building and managing the lifecycle of ML projects. It provides tools for every step of the machine learning workflow across various model types, for varying levels of machine learning expertise.
We will continue the blog series with Vertex AI to share how to build, train and deploy PyTorch models at scale and how to create reproducible machine learning pipelines on Google Cloud.
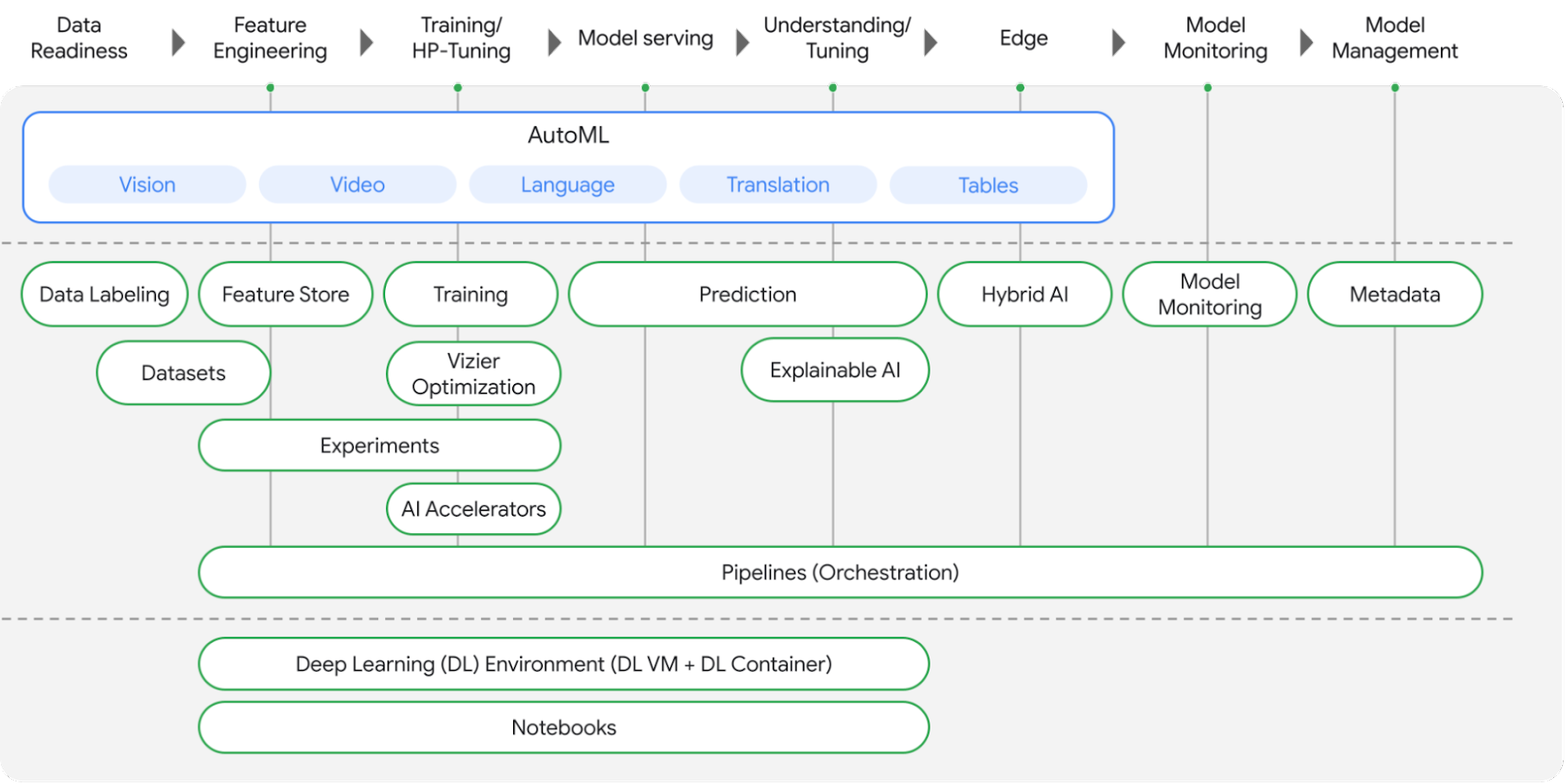
Figure 1. What’s included in Vertex AI?
In this post, we will show how to use:
- Vertex AI Training to build and train a sentiment text classification model using PyTorch
- Vertex AI Hyperparameter Tuning to tune hyperparameters of PyTorch models
You can find the accompanying code for this blog post on the GitHub repository and the Jupyter Notebook.
Let’s get started!
Use case and dataset
In this article we will fine tune a transformer model (BERT-base) from Hugging Face Transformers Library for a sentiment analysis task using PyTorch. BERT (Bidirectional Encoder Representations from Transformers) is a Transformer model pre-trained on a large corpus of unlabeled text in a self-supervised fashion. We will begin experimentation with the IMDB sentiment classification dataset on Notebooks.
We recommend using a Notebook instance with limited compute for development and experimentation purposes. Once we are satisfied with the local experiment on the notebook, we show how you can submit a training job from the same Jupyter notebook to the Vertex Training service to scale the training with bigger GPU shapes. Vertex Training service optimizes the training pipeline by spinning up infrastructure for the training job and spinning it down after the training is complete, without you having to manage the infrastructure.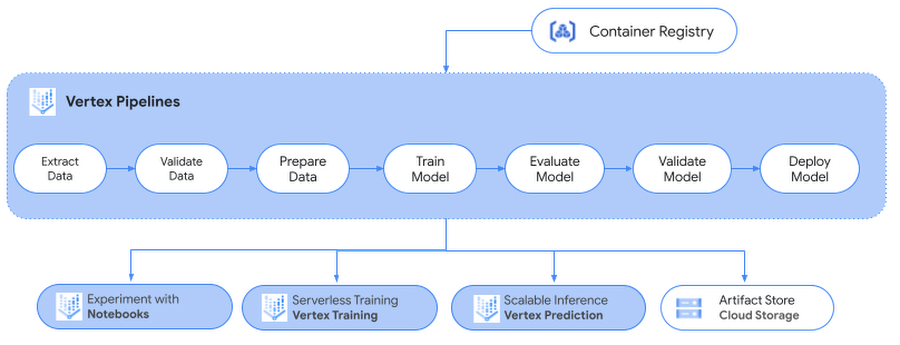
Figure 2. ML workflow on Vertex AI
In the upcoming posts, we will show how you can deploy and serve these PyTorch models on Vertex Prediction service followed by Vertex Pipelines to automate, monitor and govern your ML systems by orchestrating a ML workflow in a serverless manner, and storing workflow's artifacts using Vertex ML Metadata.
Creating a development environment on Notebooks
To set up a PyTorch development environment on JupyterLab notebooks with Notebooks, follow the setup section in the earlier post here.
To interact with the new notebook instance, go to the Notebooks page in the Google Cloud Console and click the “OPEN JUPYTERLAB” link next to the new instance, which becomes active when the instance is ready to use.
Training a PyTorch model on VertexTraining
After creating a Notebooks instance, you can start with your experiments. Let’s look into the model specifics for the use case.
The model specifics
For analyzing sentiments of the movie reviews in the IMDB dataset, we will fine-tune a pre-trained BERT model from Hugging Face. The pre-trained BERT model already encodes a lot of information about the language as the model was trained on a large corpus of English data in a self-supervised fashion. Now we only need to slightly tune them using their outputs as features for the sentiment classification task. This means quicker development iteration on a much smaller dataset, instead of training a specific Natural Language Processing (NLP) model with a larger training dataset.
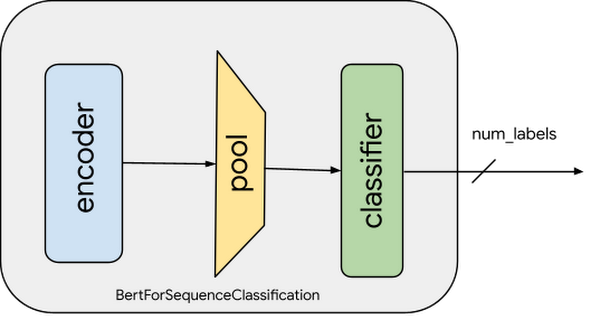
Figure 4. Pretrained Model with classification layer: The blue-box indicates the pre-trained BERT Encoder module. Output of the encoder is pooled into a linear layer with the number of outputs same as the number of target labels (classes).
For training the sentiment classification model, we will:
- Preprocess and transform (tokenize) the reviews data
- Load the pre-trained BERT model and add the sequence classification head for sentiment analysis
- Fine-tune the BERT model for sentence classification
The following code snippet shows how to preprocess the data and fine-tune a pre-trained BERT model. Please refer to the Jupyter Notebook for complete code and detailed explanation.
In the snippet above, notice that the encoder (also referred to as the base model) weights are not frozen. This is why a very small learning rate (2e-5) is chosen to avoid loss of pre-trained representations. Learning rate and other hyperparameters are captured under the TrainingArguments object. During the training, we are only capturing accuracy metrics. You can modify the compute_metrics function to capture and report other metrics.
Training the model on Vertex AI
While you can do local experimentation on your Notebooks instance, for larger datasets or large models often a vertically scaled compute resource or horizontally distributed training is required. The most effective way to perform this task is Vertex Training service for following reasons:
- Automatically provision and deprovision resources: Training job on Vertex AI will automatically provision computing resources, perform the training task and ensure deletion of compute resources once the training job is finished.
- Reusability and portability: You can package training code with its parameters and dependencies into a container and create a portable component. This container can then be run with different scenarios such as hyperparameter tuning, various data sources and more.
- Training at scale: You can run a distributed training job on Vertex Training to train models in a cluster across multiple nodes in parallel and resulting in faster training time.
- Logging and Monitoring: The training service logs messages from the job to Cloud Logging and can be monitored while the job is running.
In this post, we show how to scale a training job with Vertex Training by packaging the code and creating a training pipeline to orchestrate a training job.
There are three steps to run a training job using Vertex AI custom training service:
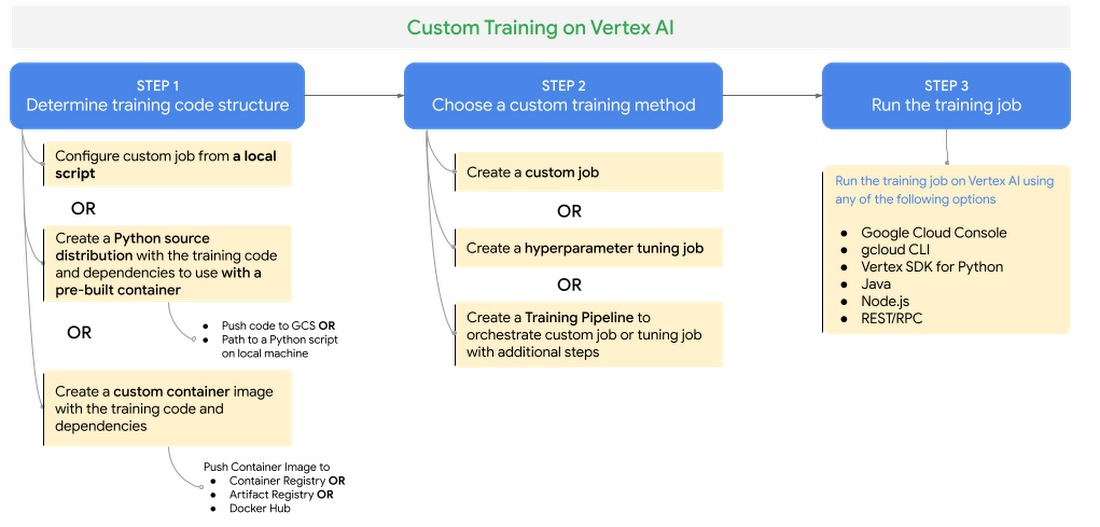
Figure 5. Custom training on Vertex AI
STEP 1 - Determine training code structure: Package training application code as a Python source distribution or as a custom container image (Docker)
STEP 2 - Choose a custom training method: You can run a training job on Vertex Training as a custom job or a hyperparameter training job or a training pipeline.
Custom jobs: With a custom job you configure the settings to run your training code on Vertex AI such as worker pool specs - machine types, accelerators, Python training spec or custom container spec.
Hyperparameter tuning jobs: Hyperparameter tuning jobs automate tuning of hyperparameters of your model based on the criteria you configure such as goal or metric to optimize, hyperparameters values and number of trials to run.
Training pipelines: Orchestrates custom training jobs or hyperparameter tuning jobs with additional steps after the training job is successfully completed.
STEP 3 - Run the training job: You can submit the training job to run on Vertex Training using
gcloudCLI or any of Client SDK libraries such as Vertex SDK for Python.
Refer to the documentation for further details on custom training methods.
Packaging the training application
Before running the training application on Vertex Training, the training application code with required dependencies must be packaged and uploaded to a Cloud Storage bucket that your Google Cloud project can access. There are two ways to package the application and run on Vertex Training:
- Create a Python source distribution with the training code and dependencies to use with a pre-built containers on Vertex AI
- Use custom containers to package dependencies using Docker containers
You can structure your training code in any way you prefer. Refer to the GitHub repository or Jupyter Notebook for our recommended approach on structuring training code.
Run Custom Job on Vertex Training with a pre-built container
Vertex AI provides Docker container images that can be run as pre-built containers for custom training. These containers include common dependencies used in training code based on the Machine Learning framework and framework version.
For the sentiment analysis task, we are using Hugging Face Datasets and fine-tune a transformer model from Hugging Face Transformers Library using PyTorch. We use the pre-built container for PyTorch and package the training application code as a Python Source Distribution by adding standard Python dependencies required by the training algorithm - transformers, datasets and tqdm - in the setup.py file.
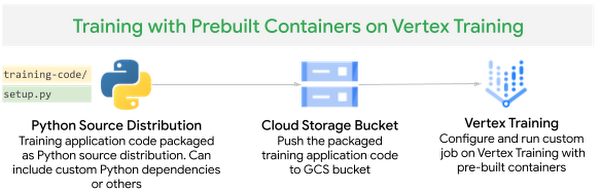
Figure 6. Custom training with pre-built containers on Vertex Training
The find_packages() function inside setup.py includes the training code in the package as dependencies.
We use Vertex SDK for Python to create and submit the training job to the Vertex training service by configuring a Custom Job resource with the pre-built container image for PyTorch and specifying the training code packaged as Python source distribution. We are attaching a NVIDIA Tesla T4 GPU to the training job for accelerating the training.
Alternatively, you can also submit the training job to Vertex AI training service using gcloud beta ai custom-jobs create command. gcloud command stages your training application on GCS bucket and submits the training job.
worker-pool-spec parameter in the command defines the worker pool configuration used by the custom job. Following are the fields within worker-pool-spec:
- Set the
executor-image-uritous-docker.pkg.dev/vertex-ai/training/pytorch-gpu.1-7:latestfor training on pre-built PyTorch v1.7 image for GPU - Set the
local-package-pathto the path to the training code - Set the
python-moduleto thetrainer.taskwhich is the main module to start the training application - Set the accelerator-type and machine-type to set the compute type to run the application
Refer to documentation for the gcloud beta ai custom-jobs create command for details.
Run Custom Job on Vertex Training with custom container
To create a training job with a custom container, you define a Dockerfile to install or add the dependencies required for the training job. Then, you build and test your Docker image locally to verify, push the image to Container Registry and submit a Custom Job to Vertex Training service.
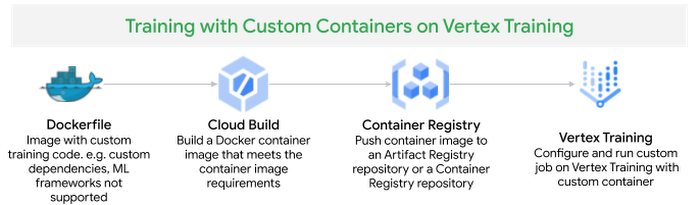
We create a Dockerfile with a pre-built PyTorch container image provided by Vertex AI as the base image, install the dependencies - transformers, datasets , tqdm and cloudml-hypertune and copy the training application code.
Now, build and push the image to Google Cloud Container Registry.
Submit the custom training job to Vertex Training using Vertex SDK for Python.
Alternatively, you can also submit the training job to Vertex AI training service using gcloud beta ai custom-jobs create command with custom container spec. gcloud command submits the training job and launches worker pool with the custom container image specified.
worker-pool-spec parameter defines the worker pool configuration used by the custom job. Following are the fields within worker-pool-spec:
Set the c
ontainer-image-urito the custom container image pushed to Google Cloud Container Registry for trainingSet the
accelerator-typeandmachine-typeto set the compute type to run the application
Once the job is submitted, you can monitor the status and progress of training job either in Google Cloud Console or use gcloud CLI command gcloud beta ai custom-jobs stream-logs as shown below:
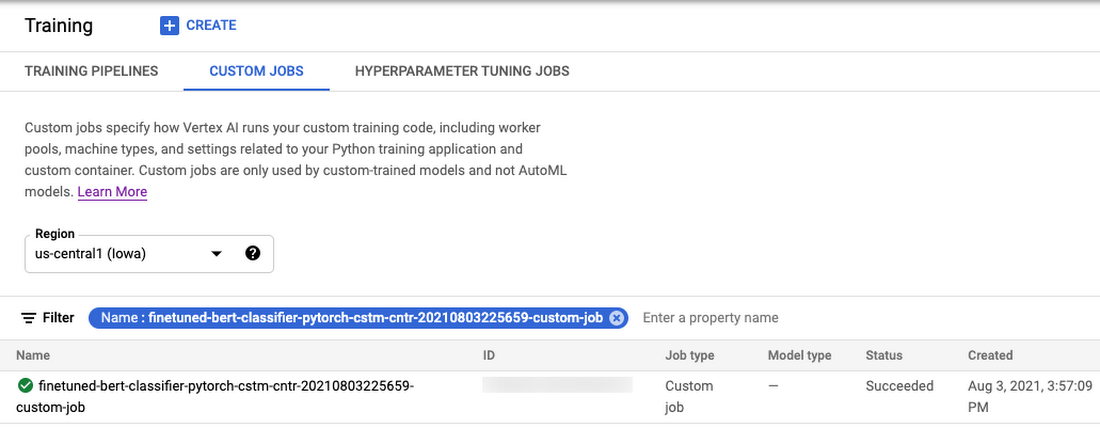
Hyperparameter tuning on Vertex AI
The training application code for fine-tuning a transformer model uses hyperparameters such as learning rate and weight decay. These hyperparameters control the behavior of the training algorithm and can have a substantial effect on the performance of the resulting model. In this section, we show how you can automate tuning these hyperparameters with Vertex Training.
We submit a Hyperparameter Tuning job to Vertex Training service by packaging the training application code and dependencies in a Docker container and push the container to Google Container Registry, similar to running a CustomJob on Vertex AI with Custom Container shown in the earlier section.
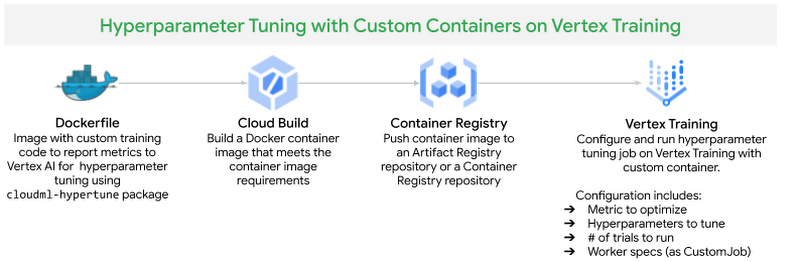
Figure 9. Hyperparameter Tuning on Vertex Training
How does hyperparameter tuning work in Vertex AI?
Following are the high level steps involved in running a Hyperparameter Tuning job on Vertex Training service:
- Define the hyperparameters to tune the model along with the metric to optimize
- Vertex Training service runs multiple trials of the training application with the hyperparameters and limits you specify - maximum number of trials to run and number of parallel trials.
- Vertex AI keeps track of the results from each trial and makes adjustments for subsequent trials. This requires your training application to report the metrics to Vertex AI using the Python package
cloudml-hypertune. - When the job is finished, get the summary of all the trials with the most effective configuration of values based on the criteria you configured
Refer to the Vertex AI documentation to understand how to configure and select hyperparameters for tuning, configure tuning strategy and how Vertex AI optimizes the hyperparameter tuning jobs. The default tuning strategy uses results from previous trials to inform the assignment of values in subsequent trials.
Changes to training application code for hyperparameter tuning
There are few requirements to follow that are specific to hyperparameter tuning in Vertex AI:
- To pass the hyperparameter values to training code, you must define a command-line argument in the main training module for each tuned hyperparameter. Use the value passed in those arguments to set the corresponding hyperparameter in the training application's code.
- You must pass metrics from the training application to Vertex AI to evaluate the efficacy of a trial. You can use
cloudml-hypertunePython package to report metrics.
Previously, in the training application code, we instantiated Trainer with hyperparameters passed as training arguments (training_args). These hyperparameters are passed as command line arguments to the training module trainer.task which are then passed to the training_args. Refer to ./python_package/trainer module for training application code.
To report metrics to Vertex AI when hyperparameter tuning is enabled, we call cloudml-hypertune Python package after the evaluation phase as a callback to the trainer object. The trainer object passes the metrics computed in the last evaluation phase to the callback that will be reported by the hypertune library to Vertex AI for evaluating trials.
Run Hyperparameter Tuning Job on Vertex AI
Before submitting the Hyperparameter Tuning job to Vertex AI, push the custom container image with the training application to Cloud Container Registry repository and then submit the job to Vertex AI using Vertex SDK for Python. We use the same image as before when running the Custom Job on Vertex Training service.
Define the training arguments with hp-tune argument set to y so that training application code can report metrics to Vertex Training service.
Create a CustomJob with worker pool specs to define machine types, accelerators and customer container spec with the training application code.
Next, define the parameter and metric specifications:
parameter_specdefines the search space i.e. parameters to search and optimize. The spec requires to specify the hyperparameter data type as an instance of a parameter value specification. Refer to the documentation on selecting the hyperparameter to tune and how to define them.metric_specdefines the goal of the metric to optimize. The goal specifies whether you want to tune your model to maximize or minimize the value of this metric.
Configure and submit a HyperparameterTuningJob with the CustomJob, metric_spec, parameter_spec and trial limits. Trial limits define how many trials to allow the service to run:
max_trial_count: Maximum # of Trials run by the service. Start with a smaller value to understand the impact of the hyperparameters chosen before scaling up.parallel_trial_count: Number of Trials to run in parallel. Start with a smaller value as Vertex AI uses results from the previous trials to inform the assignment of values in subsequent trials. Higher number of parallel trials mean these trials start without having the benefit of the results of any trials still running.search_algorithm: Search algorithm specified for the study. When not specified, Vertex AI by default applies Bayesian optimization to arrive at the optimal solution to search over the parameter space.
Refer to the documentation to understand the hyperparameter training job configuration.
Alternatively, you can submit a hyperparameter tuning job to Vertex AI training service using gcloud beta ai hp-tuning-jobs create. The gcloud command submits the hyperparameter tuning job and launches multiple trials with a worker pool based on custom container image specified, number of trials and the criteria set. The command requires hyperparameter tuning job configuration provided as configuration file in YAML format with job name. Refer to the Jupyter notebook on creating the YAML configuration and submitting the job via gcloud command.
You can monitor the hyperparameter tuning job launched from Cloud Console following the link here or use gcloud CLI command gcloud beta ai custom-jobs stream-logs.
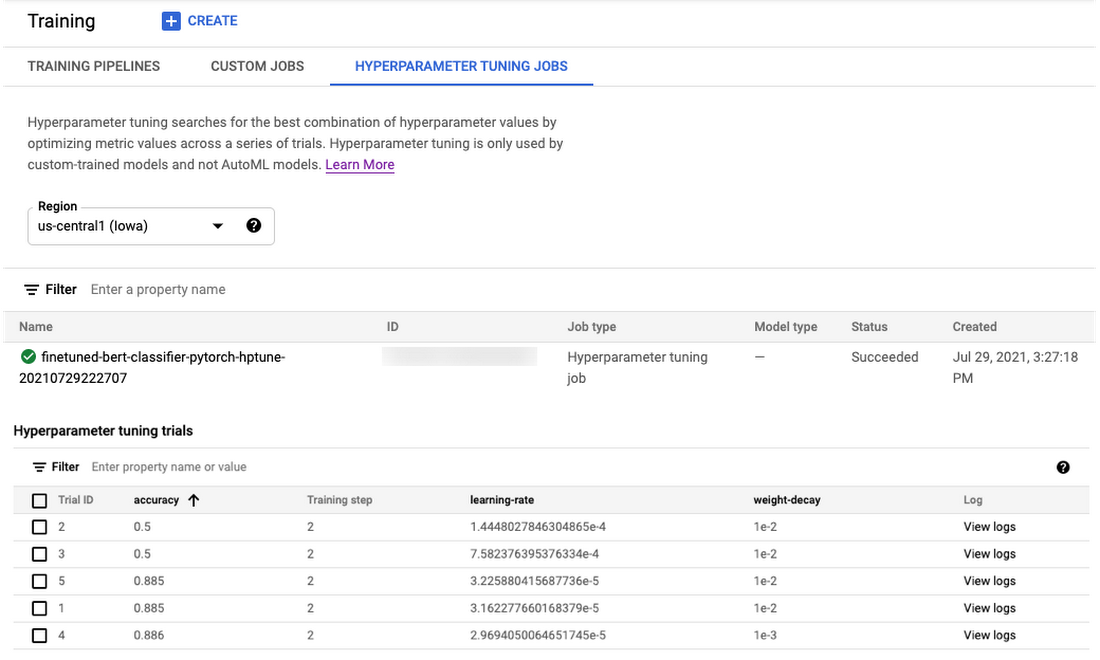
Figure 10. Monitor progress and logs of hyperparameter tuning jobs from Google Cloud Console
After the job is finished, you can view and format the results of the hyperparameter tuning Trials (run by Vertex Training service) and pick the best performing Trial to deploy to Vertex Prediction service.
Run predictions locally
Let’s run prediction calls on the trained model locally with a few examples (refer to the notebook for the complete code). The next post in this series will show you how to deploy this model on Vertex Prediction service.
Cleaning up the Notebook environment
After you are done experimenting, you can either stop or delete the Notebooks instance. Delete the Notebooks instance to prevent any further charges. If you want to save your work, you can choose to stop the instance instead.
What’s next?
In this article, we explored Notebooks for PyTorch model development. We then trained and tuned the model on Vertex Training service, a fully managed service for training machine learning models at scale. We looked at how you can submit training jobs as Custom Job and Hyperparameter Tuning Job to Vertex Training using Vertex SDK for Python and gcloud CLI commands with both pre-built and custom containers for PyTorch.
In the next installments of this series, we will show how to deploy PyTorch models on Vertex Prediction service and orchestrate a machine learning workflow using Vertex Pipelines. We encourage you to explore the Vertex AI features and read the reference guide on best practices for implementing machine learning on Google Cloud.
References
- Introduction to Notebooks
- Custom training on Vertex Training
- Configuring distributed training on Vertex Training
- GitHub repository with code and accompanying notebook
Stay tuned. Thank you for reading! Have a question or want to chat? Find authors here - Rajesh [Twitter | LinkedIn] and Vaibhav [LinkedIn].
Thanks to Karl Weinmeister and Jordan Totten for helping and reviewing the post.