Movie Score Prediction with BigQuery, Vertex AI and MongoDB Atlas
Abirami Sukumaran
Developer Advocate, Google
Stanimira Vlaeva
MongoDB
Hey there! It’s been a minute since we last wrote about Google Cloud and MongoDB Atlas together. We had an idea for this new genre of experiment that involves BigQuery, BQML, Vertex AI, Cloud Functions, MongoDB Atlas, and Cloud Run and we thought of putting it together in this blog. You will get to learn how we brought these services together in delivering a full stack application and other independent functions and services the application uses. Have you read our last blog about Serverless MEAN stack applications with Cloud Run and MongoDB Atlas? If not, this would be a good time to take a look at that, because some topics we cover in this discussion are designed to reference some steps from that blog. In this experiment, we are going to bring BigQuery, Vertex AI, and MongoDB Atlas to predict a categorical variable using a Supervised Machine Learning Model created with AutoML.
The experiment
We all love movies, right? Well, most of us do. Irrespective of language, geography, or culture, we enjoy not only watching movies but also talking about the nuances and qualities that go into making a movie successful. I have often wondered, “If only I could alter a few aspects and create an impactful difference in the outcome in terms of the movie’s rating or success factor.” That would involve predicting the success score of the movie so I can play around with the variables, dialing values up and down to impact the result. That is exactly what we have done in this experiment.
Summary of architecture
Today we'll predict a Movie Score using Vertex AI AutoML and have transactionally stored it in MongoDB Atlas. The model is trained with data stored in BigQuery and registered in Vertex AI. The list of services can be composed into three sections:
1. ML Model Creation2. User Interface / Client Application
3. Trigger to predict using the ML API
ML Model Creation
1. Data sourced from CSV to BigQuery2. BigQuery data integrated into Vertex AI for AutoML model creation
3. Model deployed in Vertex AI Model Registry for generating endpoint API
User Interface Application
4. MongoDB Atlas for storing transactional data and powering the client application5. Angular client application interacting with MongoDB Atlas
6. Client container deployed in Cloud Run
Trigger to predict using the ML API
7. Java Cloud Functions to trigger invocation of the deployed AutoML model’s endpoint that takes in movie details as request from the UI, returns the predicted movie SCORE, and writes the response back to MongoDB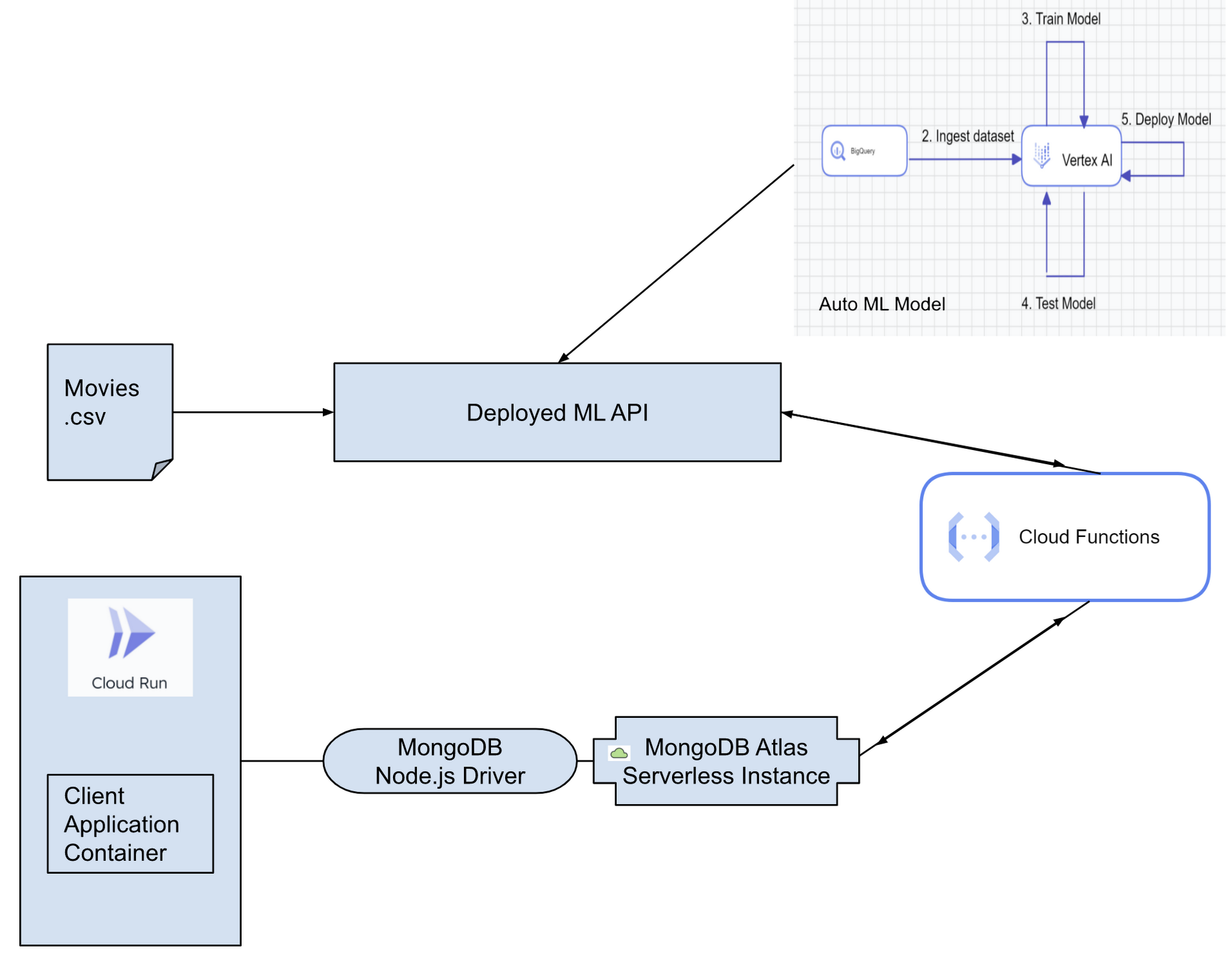
Preparing training data
You can use any publicly available dataset, create your own, or use the dataset from CSV in git. I have done basic processing steps for this experiment in the dataset in the link. Feel free to do an elaborate cleansing and preprocessing for your implementation. Below are the independent variables in the dataset:
Name (String)
Rating (String)
Genre (String, Categorical)
Year (Number)
Released (Date)
Director (String)
Writer (String)
Star (String)
Country (String, Categorical)
Budget (Number)
Company (String)
Runtime (Number)
BigQuery dataset using Cloud Shell
BigQuery is a serverless, multi-cloud data warehouse that can scale from bytes to petabytes with zero operational overhead. This makes it a great choice for storing ML training data. But there’s more — the built-in machine learning (ML) and analytics capabilities allow you to create no-code predictions using just SQL queries. And you can access data from external sources with federated queries, eliminating the need for complicated ETL pipelines. You can read more about everything BigQuery has to offer in the BigQuery product page.
BigQuery allows you to focus on analyzing data to find meaningful insights. In this blog, you'll use the bq command-line tool to load a local CSV file into a new BigQuery table. Follow the below steps to enable BigQuery:
Activate Cloud Shell and create your project
You will use Cloud Shell, a command-line environment running in Google Cloud. Cloud Shell comes pre-loaded with bq.
- In the Google Cloud Console, on the project selector page, select or create a Google Cloud project.
- Make sure that billing is enabled for your Cloud project. Learn how to check if billing is enabled on a project.
- Navigate to BigQuery to enable the API. You can also open the BigQuery web UI directly by entering the following URL in your browser:
- https://console.cloud.google.com/bigquery.
- From the Cloud Console, click Activate Cloud Shell. Make sure you navigate to the project and that it’s authenticated. Refer to gcloud config commands.
Creating and loading the dataset
A BigQuery dataset is a collection of tables. All tables in a dataset are stored in the same data location. You can also attach custom access controls to limit access to a dataset and its tables.
1. In Cloud Shell, use the bq mk command to create a dataset called "movies."2.
Use –location=LOCATION to set the location to a region you can remember to set as the region for the VERTEX AI step as well (both instances should be on the same region).
You may also use a public dataset of your choice. To open and query the public dataset, follow the documentation.
--source_format=CSV - uses CSV data format when parsing data file.
--skip_leading_rows=1 - skips the first line in the CSV file because it is a header row.
Movies.movies_score - defines the table the data should be loaded into.
./movies_bq_src.csv - defines the file to load. bq load command can load files from Cloud. Storage with gs://my_bucket/path/to/file URIs.
A schema, which can be defined in a JSON schema file or as a comma-separated list. (I’ve used a comma-separated list.)
Hurray! Our CSV data is now loaded in the table movies.movies. Remember, you can create a view to keep only essential columns that contribute to the model training and ignore the rest.
We can interact with BigQuery in three ways:
The bq command
API
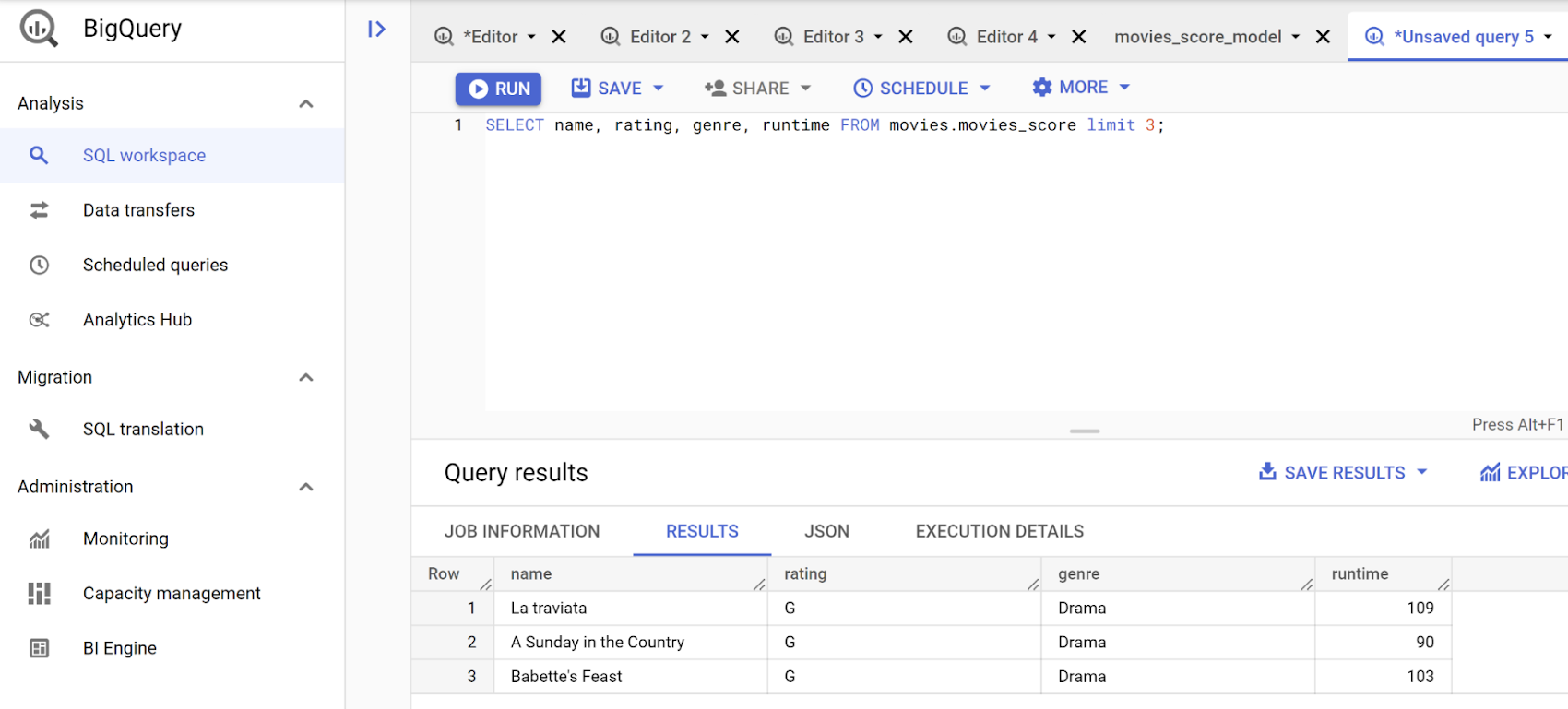
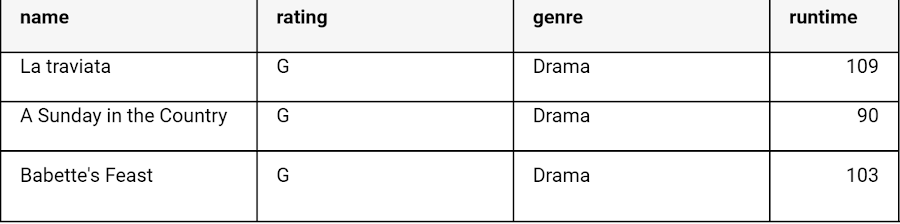
Your queries can also join your data against any dataset (or datasets, so long as they're in the same location) that you have permission to read. Find a snippet of the sample data below:
I have used the BigQuery Web SQL Workspace to run queries. The SQL Workspace looks like this:
Predicting movie success score (user score on a scale of 1-10)
In this experiment, I am predicting the success score (user score/rating) for the movie as a multi-class classification model on the movie dataset.
A quick note about the choice of model
This is an experimental choice of model chosen here, based on the evaluation of results I ran across a few models initially and finally went ahead with LOGISTIC REG to keep it simple and to get results closer to the actual movie rating from several databases. Please note that this should be considered just as a sample for implementing the model and is definitely not the recommended model for this use case. One other way of implementing this is to predict the outcome of the movie as GOOD/BAD using the Logistic Regression model instead of predicting the score.
Using BigQuery data in Vertex AI AutoML integration
Use your data from BigQuery to directly create an AutoML model with Vertex AI. Remember, we can also perform AutoML from BigQuery itself and register the model with VertexAI and expose the endpoint. Refer to the documentation for BigQuery AutoML. In this example, however, we will use Vertex AI AutoML to create our model.
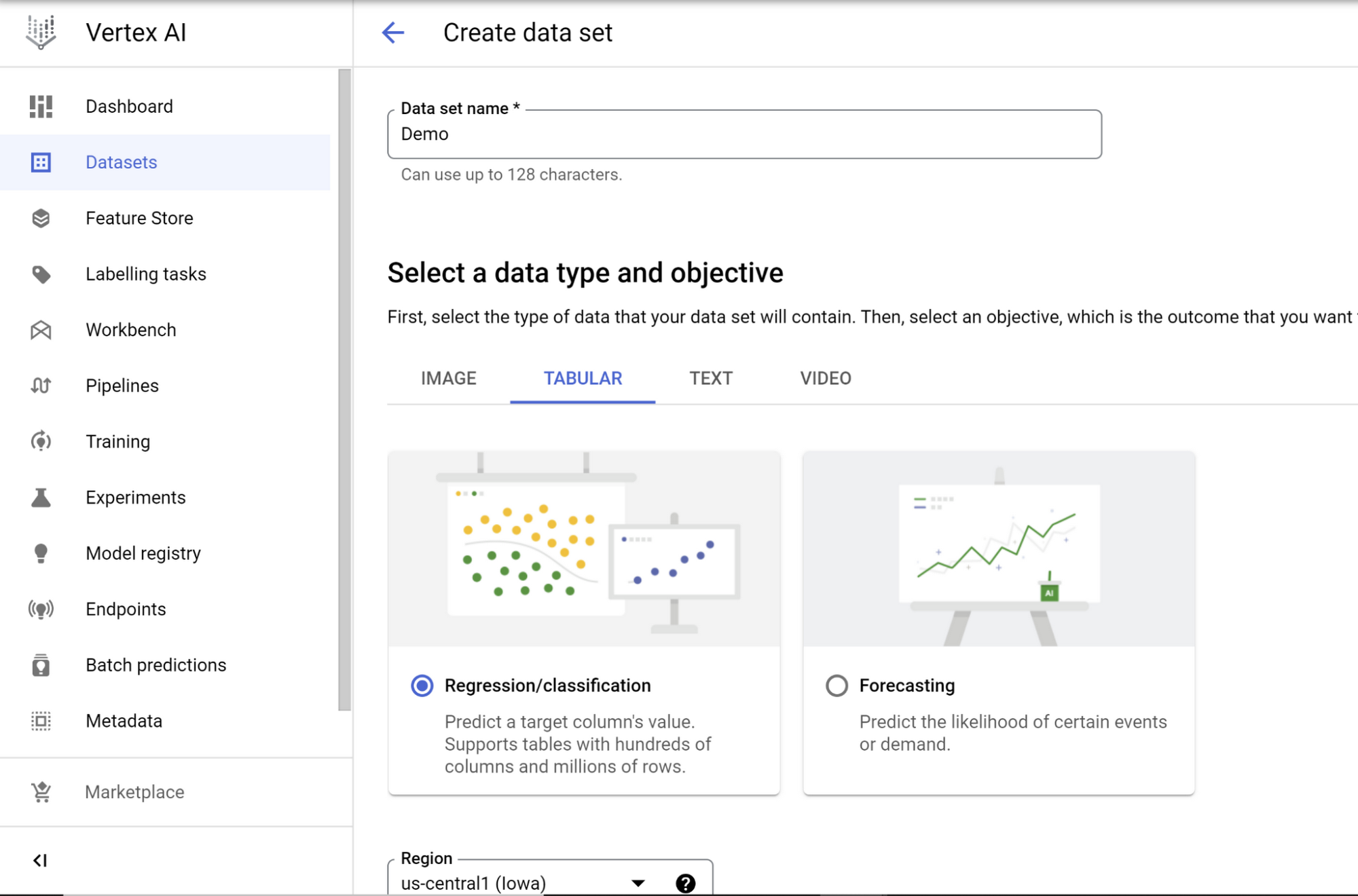
Creating a Vertex AI data set
Go to Vertex AI from Google Cloud Console, enable Vertex AI API if not already done, expand data and select Datasets, click on Create data set, select TABULAR data type and the “Regression / classification” option, and click Create:
Select data source
On the next page, select a data source:
Choose the “Select a table or view from BigQuery” option and select the table from BigQuery in the BigQuery path BROWSE field. Click Continue.
A Note to remember
The BigQuery instance and Vertex AI data sets should have the same region in order for the BigQuery table to show up in Vertex AI.
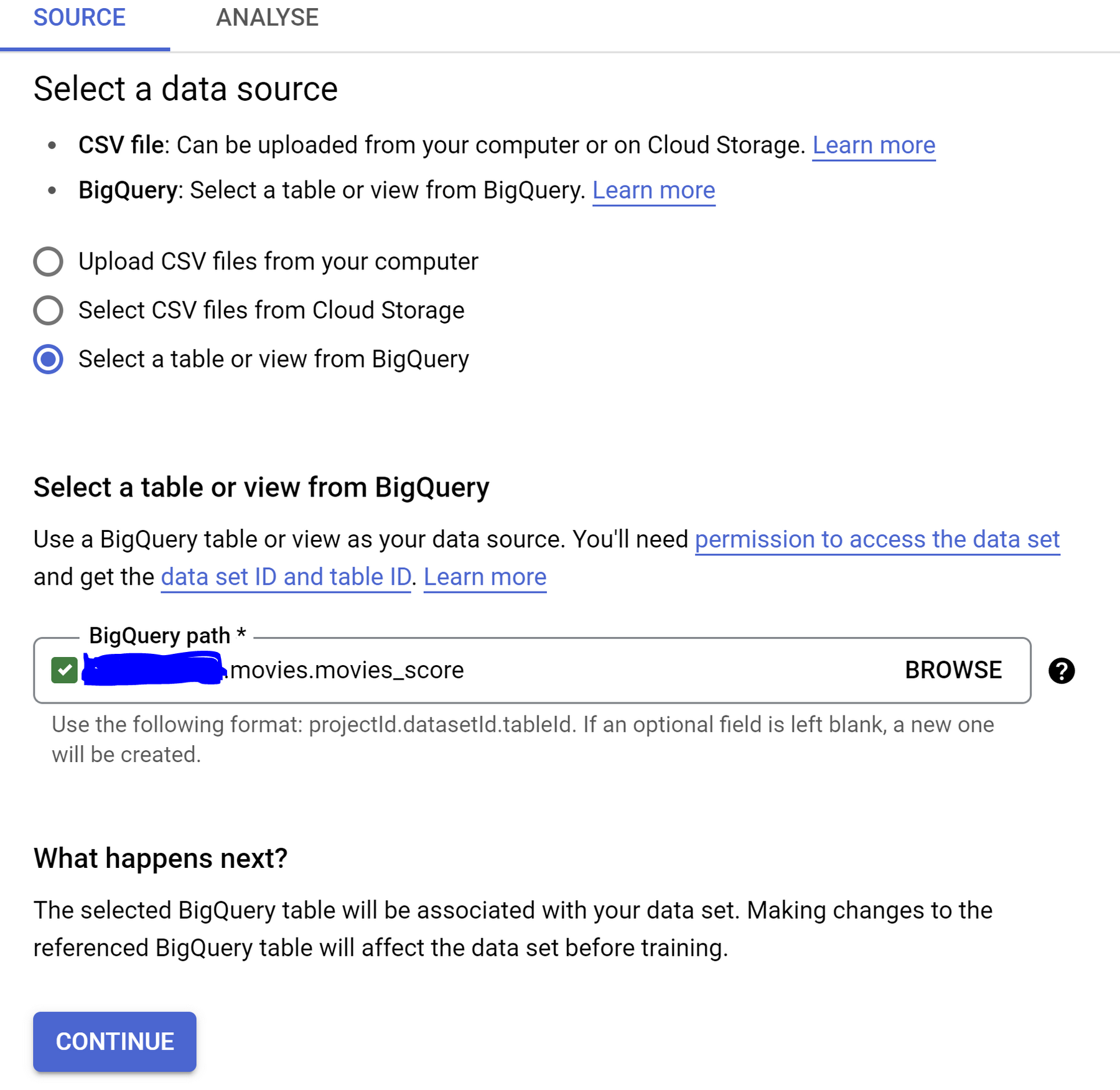
When you are selecting your source table/view, from the browse list, remember to click on the radio button to continue with the below steps. If you accidentally click on the name of the table/view, you will be taken to Dataplex. You just need to browse back to Vertex AI if this happens to you.
Train your model
Once the dataset is created, you should see the Analyze page with the option to train a new model. Click that:
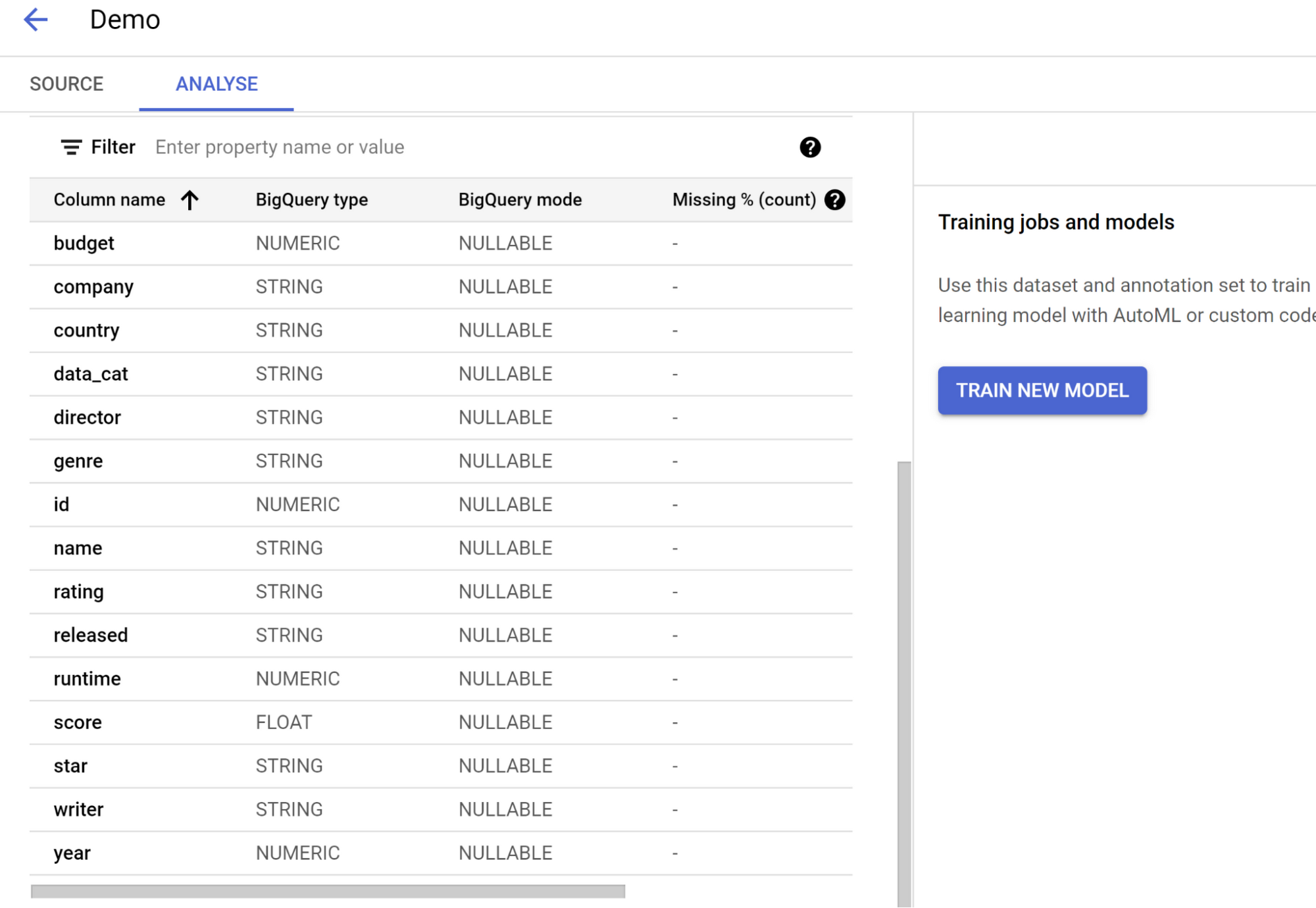
Configure training steps
Go through the steps in the Training Process.
Leave Objective as Classification.
Select AutoML option in first page and click continue:
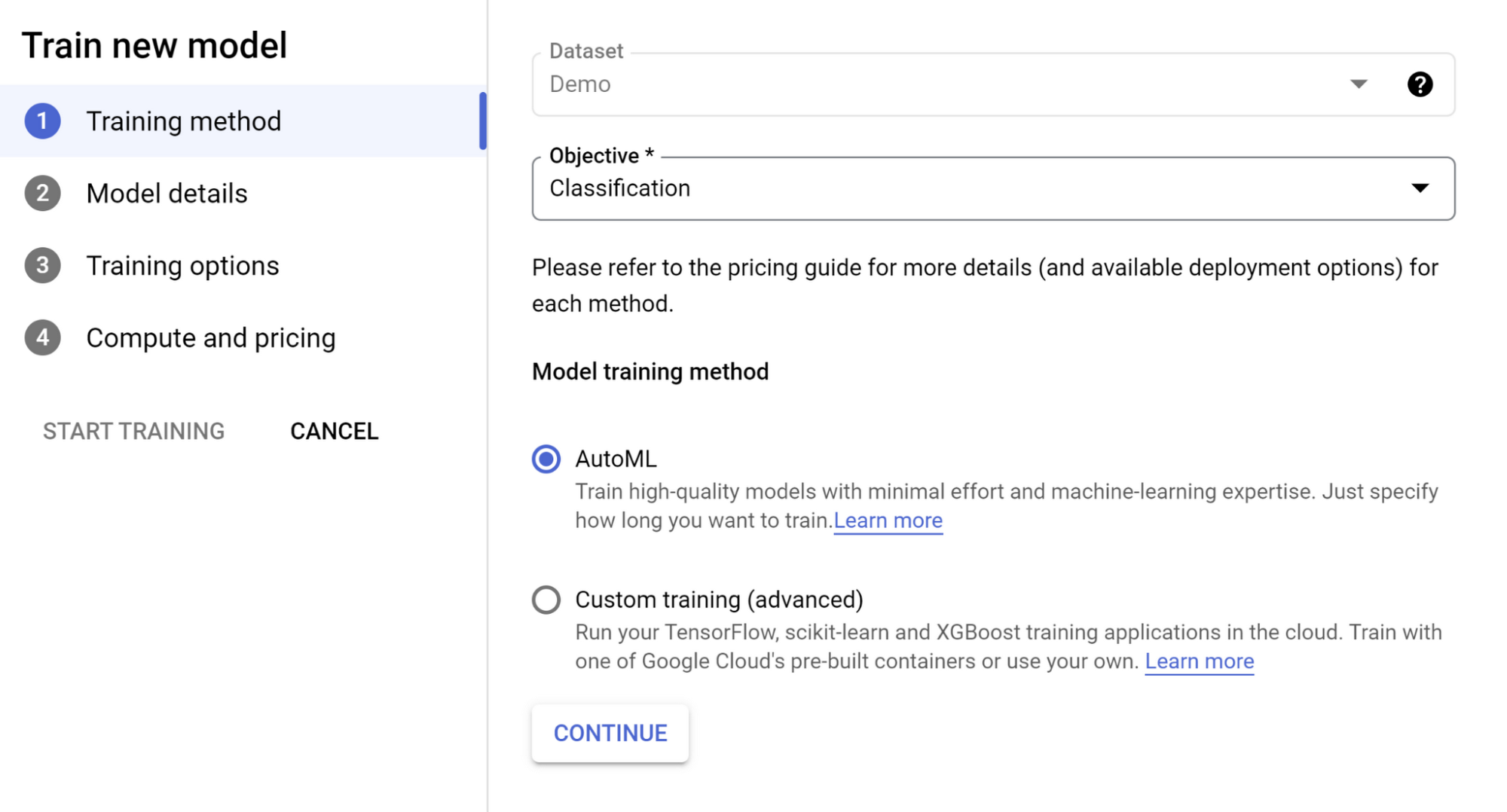
Give your model a name.
Select Target Column name as “Score” from the dropdown that shows and click Continue.
Also note that you can check the “Export test dataset to BigQuery” option, which makes it easy to see the test set with results in the database efficiently without an extra integration layer or having to move data between services.
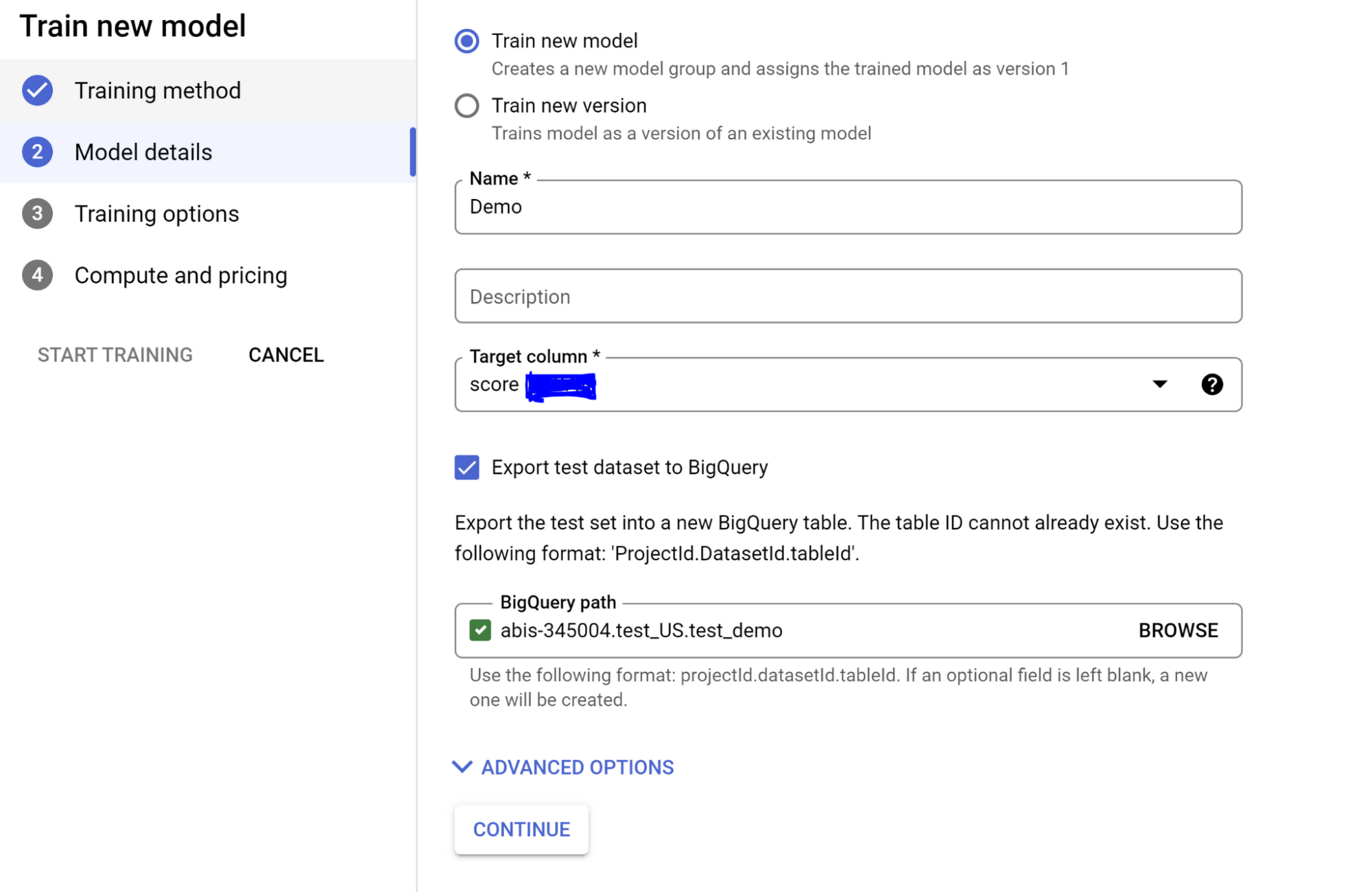
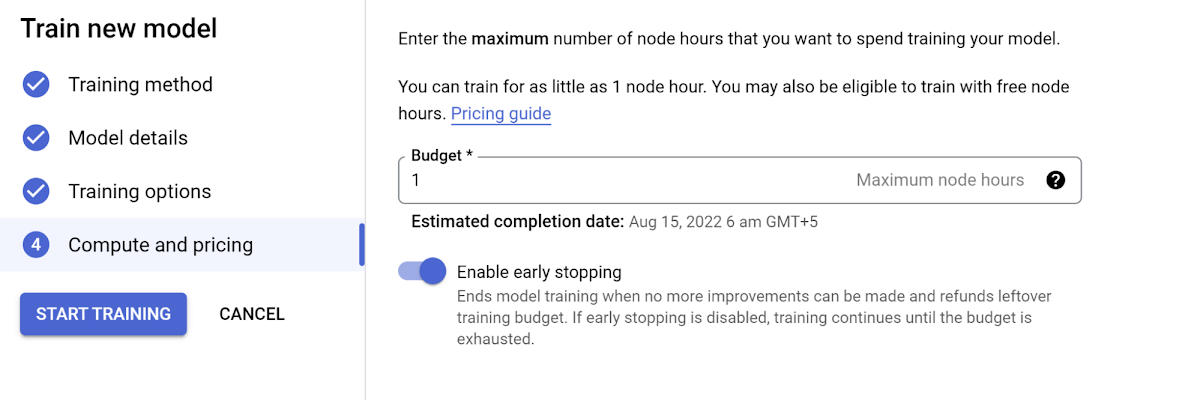
On the next pages, you have the option to select any advanced training options you need and the hours you want to set the model to train. Please note that you might want to be mindful of the pricing before you increase the number of node hours you want to use for training.
Click Start Training to begin training your new model.
Evaluate, deploy, and test your model
Once the training is completed, you should be able to click Training (under the Model Development heading in the left-side menu) and see your training listed in the Training Pipelines section. Click that to land on the Model Registry page. You should be able to:
1. View and evaluate the training results.
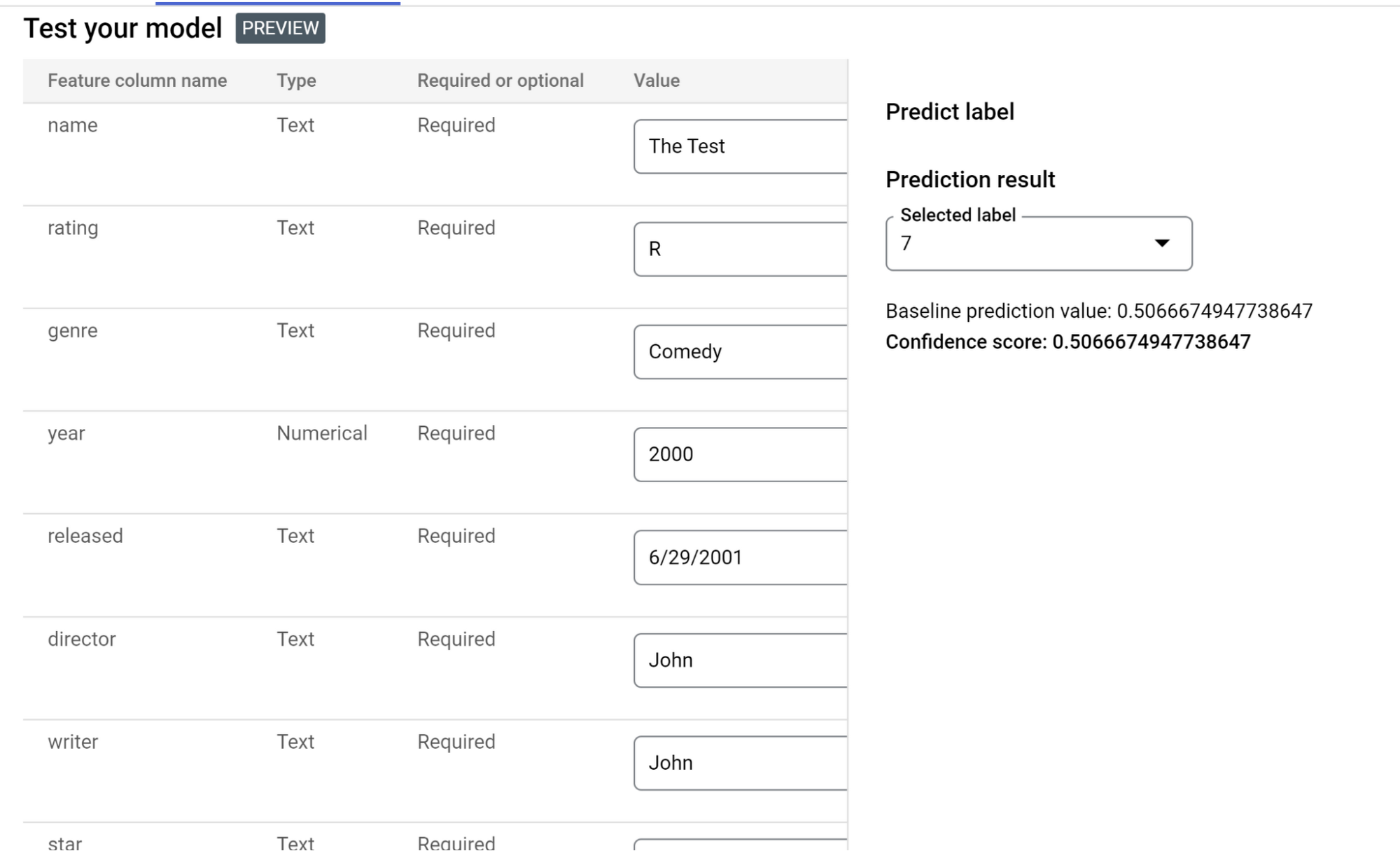
2. Deploy and test the model with your API endpoint.
Once you deploy your model, an API endpoint gets created which can be used in your application to send requests and get model prediction results in the response.
You can integrate batch predictions with BigQuery database objects as well. Read from the BigQuery object (in this case, I have created a view to batch predict movies score) and write into a new BigQuery table. Provide the respective BigQuery paths as shown in the image and click CREATE:
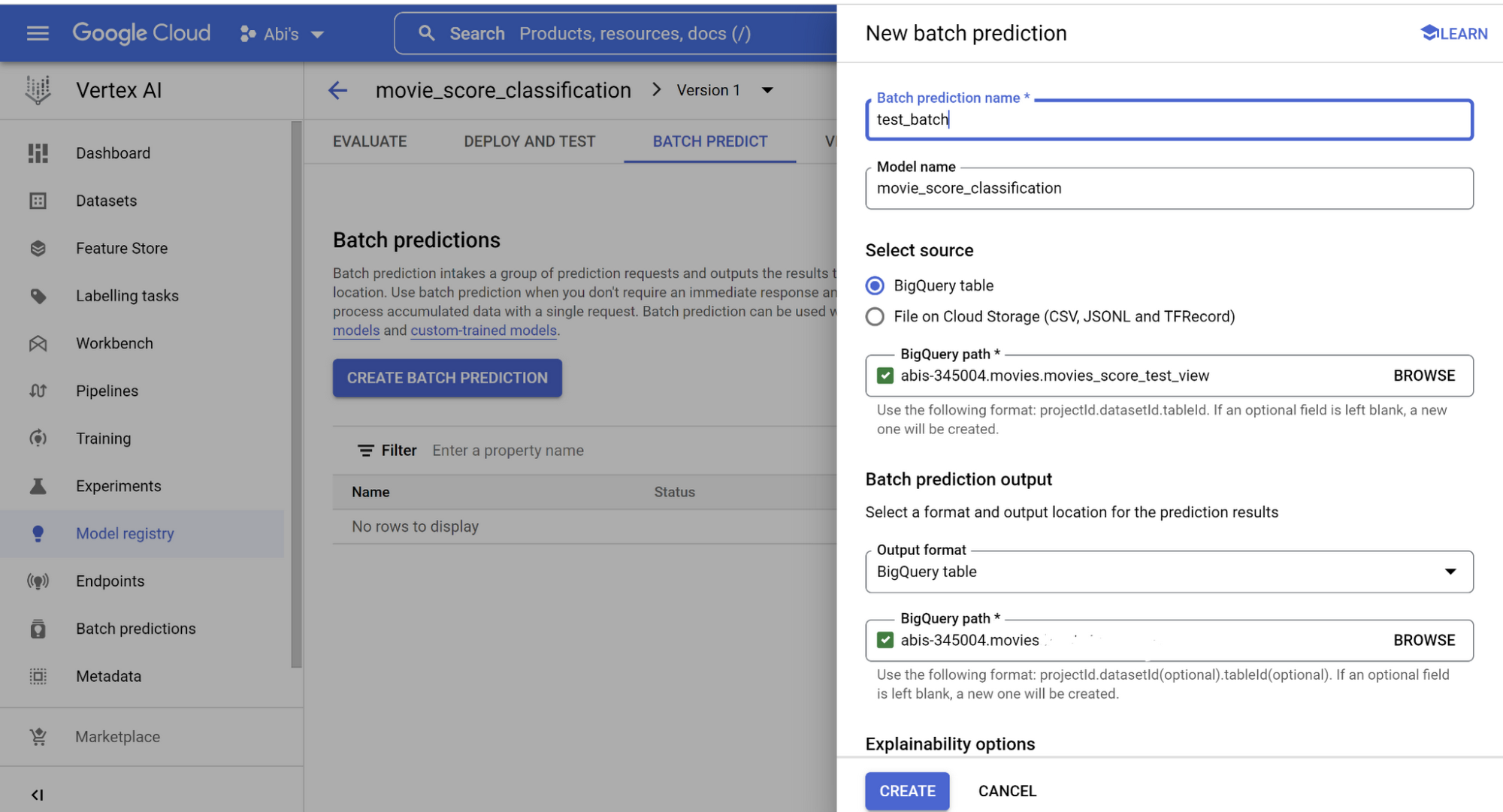
Once it is complete, you should be able to query your database for the batch prediction results. But before you move on from this section, make sure you take a note of the deployed model’s Endpoint id, location, and other details on your Vertex AI endpoint section.
We have created a custom ML model for the same use case using BigQuery ML with no code but only SQL, and it’s already detailed in another blog.
Serverless web application with MongoDB Atlas and Angular
The user interface for this experiment is using Angular and MongoDB Atlas and is deployed on Cloud Run. Check out the blog post describing how to set up a MongoDB serverless instance to use in a web app and deploy that on Cloud Run.
In the application, we’re also utilizing Atlas Search, a full-text search capability, integrated into MongoDB Atlas. Atlas Search enables autocomplete when entering information about our movies. For the data, we imported the same dataset we used earlier into Atlas.
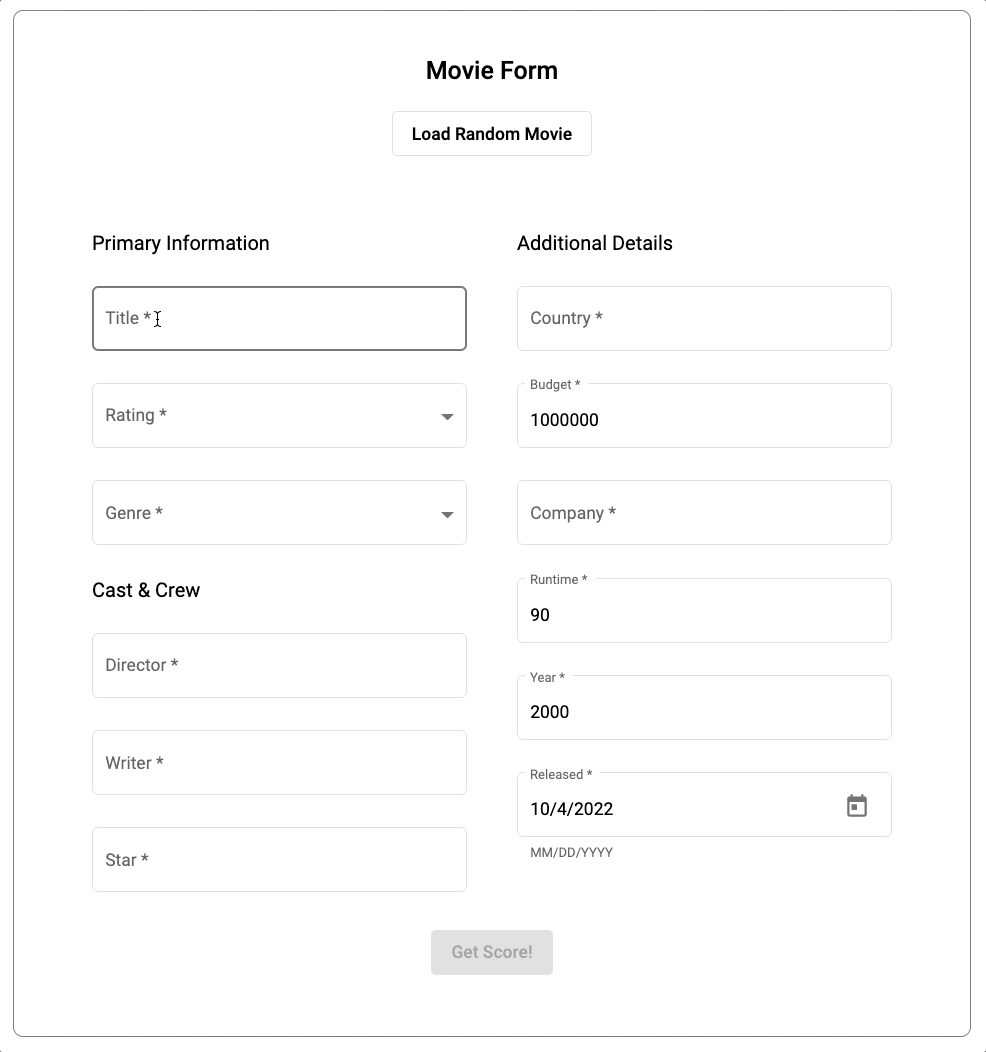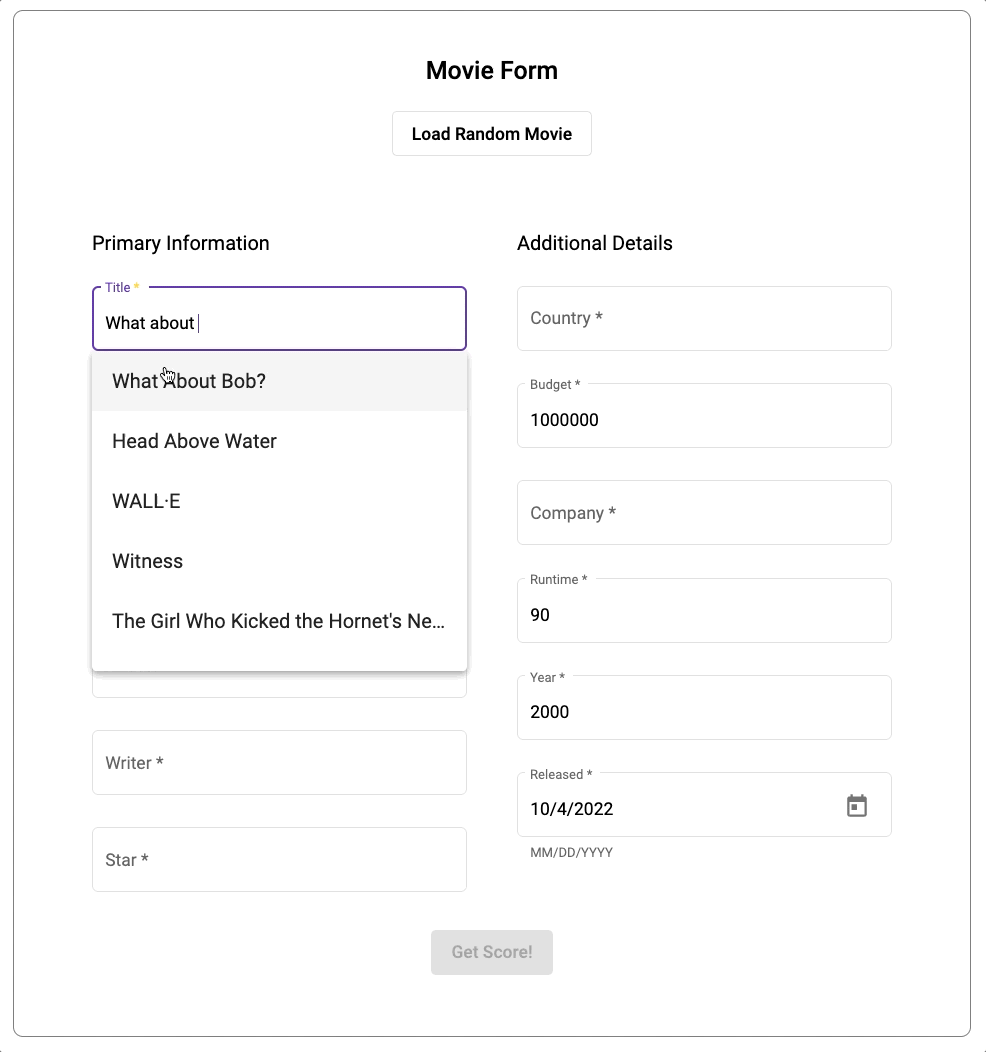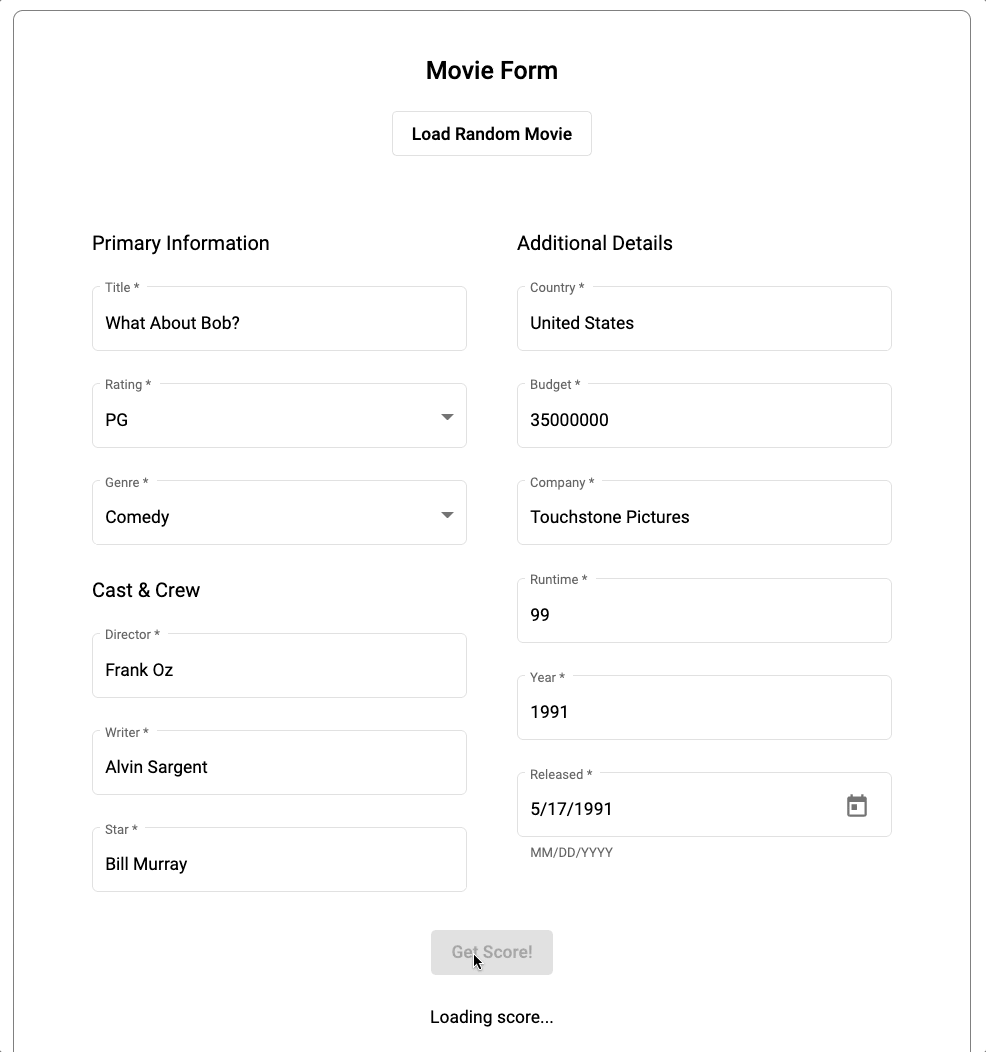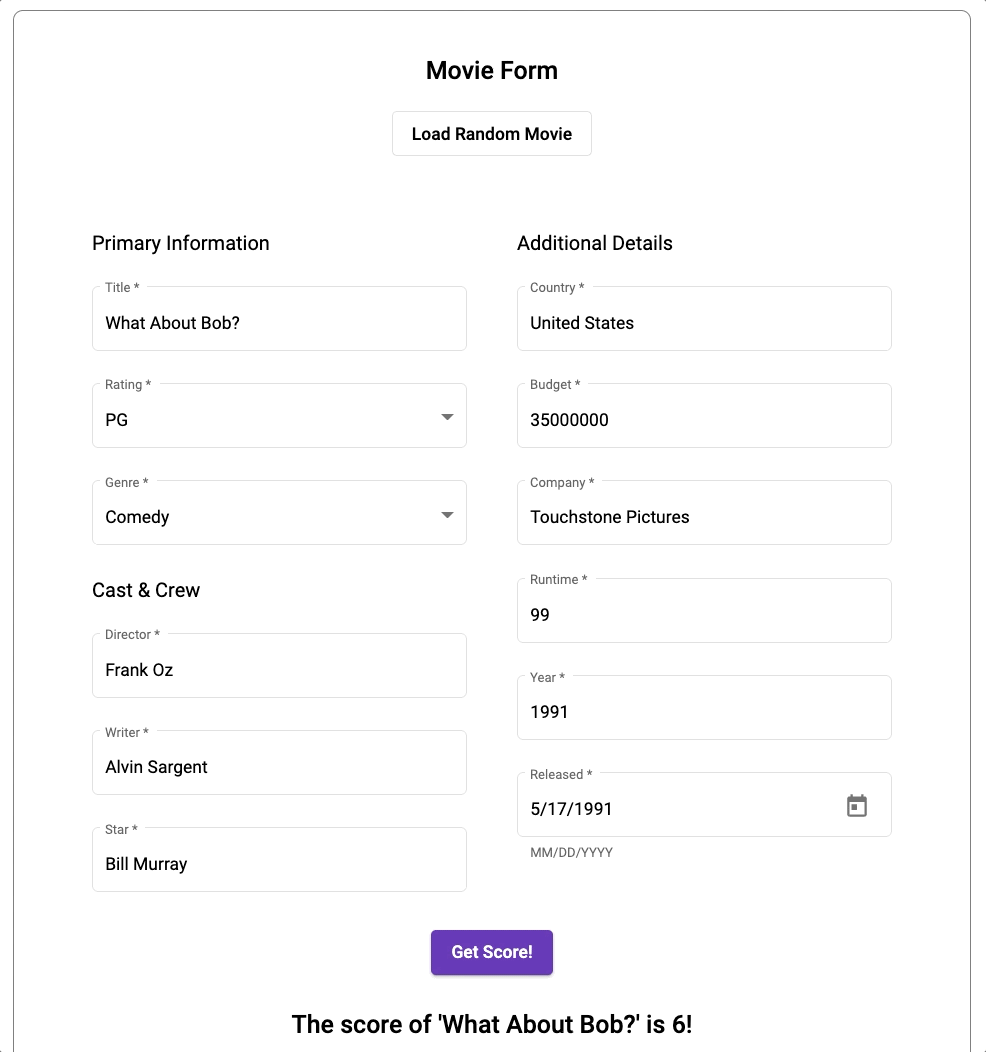
You can find the source code of the application in the dedicated Github repository.
MongoDB Atlas for transactional data
In this experiment, MongoDB Atlas is used to record transactions in the form of:
Real time user requests.
Prediction result response.
Historical data to facilitate UI fields autocompletion.
If instead, you want to configure a pipeline for streaming data from MongoDB to BigQuery and vice-versa, check out the dedicated Dataflow templates.
Once you provision your cluster and set up your database, make sure to note the below in preparation of our next step, creating the trigger:
Database Name
Collection Name
Please note that this client application uses the Cloud Function Endpoint (which is explained in the below section) that uses user input and predicts movie score and inserts in MongoDB.
Java Cloud Function to trigger ML invocation from the UI
Cloud Functions is a lightweight, serverless compute solution for developers to create single-purpose, stand-alone functions that respond to Cloud events without needing to manage a server or runtime environment. In this section, we will prepare the Java Cloud Functions code and dependencies and authorize for it to be executed on triggers.
Remember how we have the endpoint and other details from the ML deployment step? We are going to use that here, and since we are using Java Cloud Functions, we will use pom.xml for handling dependencies. We use google-cloud-aiplatform library to consume the Vertex AI AutoML endpoint API:
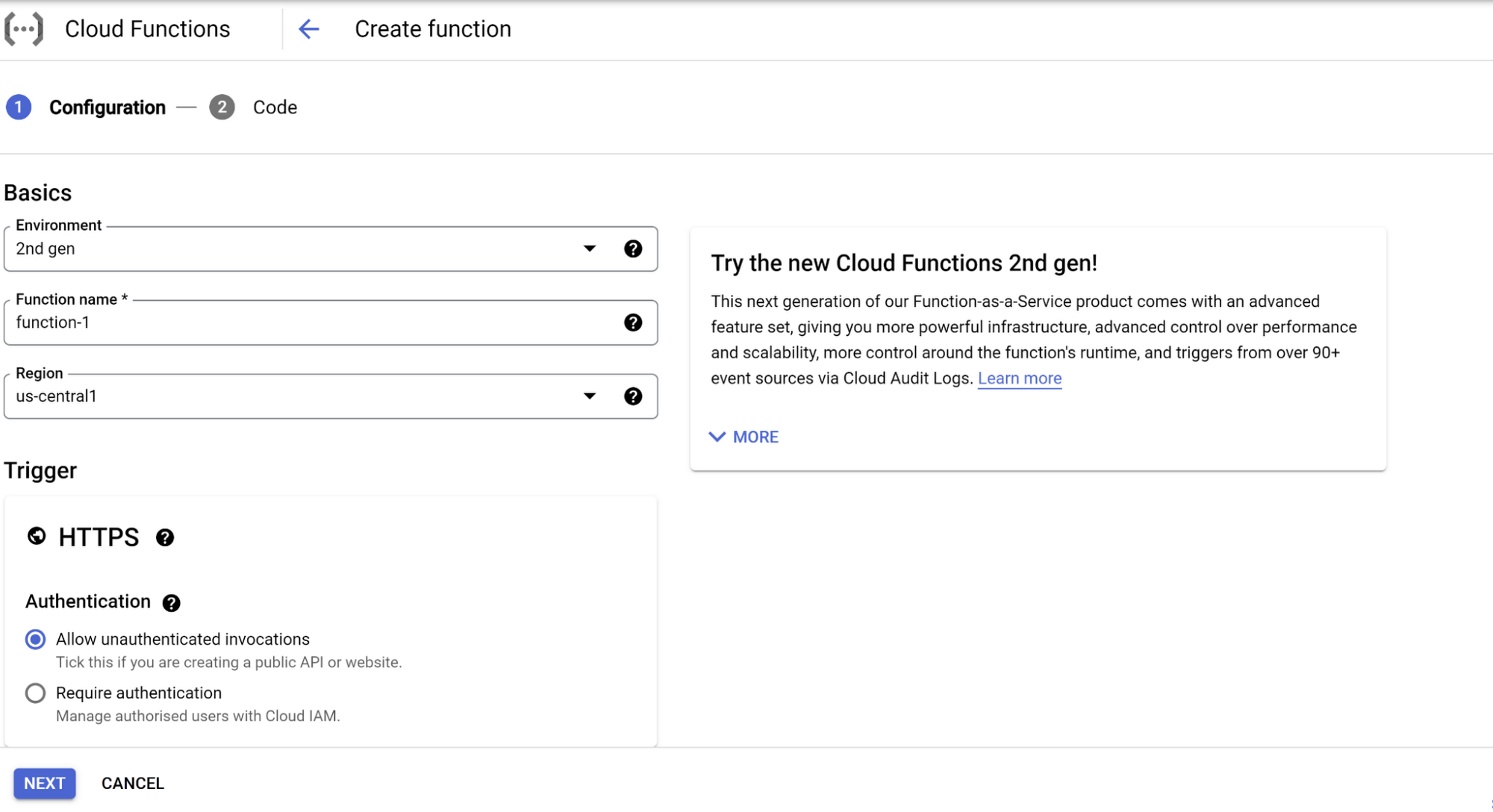
1. Search for Cloud Functions in Google Cloud console and click “Create Function.”
2. Enter the configuration details, like Environment, Function name, Region, Trigger (in this case, HTTPS), Authentication of your choice, enable “Require HTTPS,” and click next/save.
3. On the next page, select Runtime (Java 11), Source Code (Inline or upload), and start editing
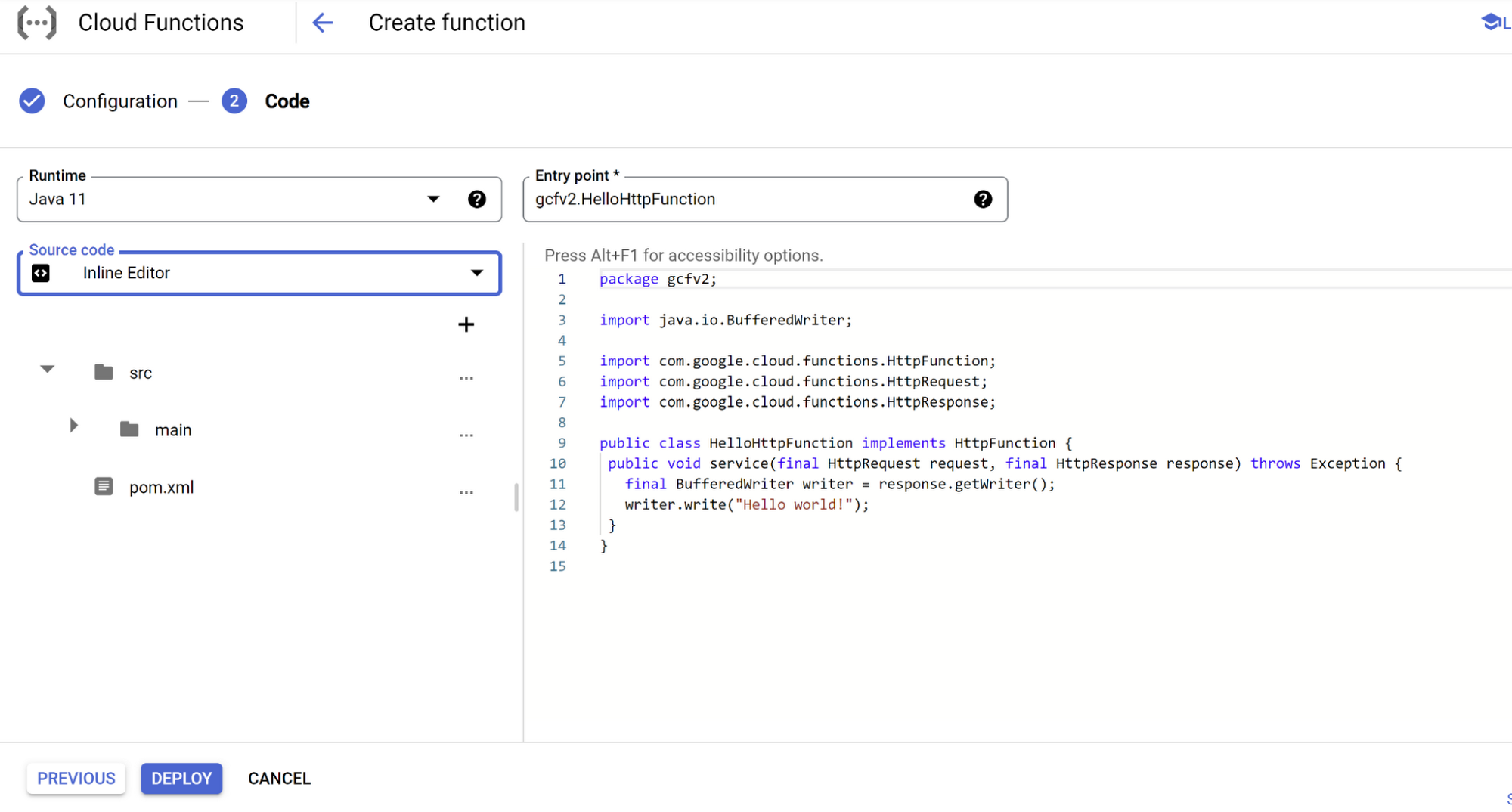
If you are using Gen2 (recommended), you can use the class name and package as-is. If you use Gen1 Cloud Functions, please change the package name and class name to “Example.”
5. In the .java file, you will notice the part where we connect to MongoDB instance to write data: (use your credentials)6. You should also notice the ML model invocation part in the java code (use your endpoint):
That’s it! Nothing else to do in this section. The endpoint is used in the client application for the user interface to send user parameters to Cloud Functions as a request and receive movie score as a response. The endpoint also writes the response and request to the MongoDB collection.
What’s next?
Thank you for following us on this journey! As a reward for your patience, you can check out the predicted score for your favorite movie.
Analyze and compare the accuracy and other evaluation parameters between the BigQuery ML manually using SQLs and Vertex AI Auto ML model.
Play around with the independent variables and try to increase the accuracy of the prediction result.
Take it one step further and try the same problem as a Linear Regression model by predicting the score as a float/decimal point value instead of rounded integers.
To learn more about some of the key concepts in this post you can dive in here:




