A data pipeline for MongoDB Atlas and BigQuery using Dataflow
Venkatesh Shanbhag
Senior Partner Solution Architect, MongoDB
Sachin Agarwal
Group Product Manager, Google Cloud
Data is critical for any organization to build and operationalize a comprehensive analytics strategy. For example, each transaction in the BFSI (Banking, Finance, Services, and Insurance) sector produces data. In Manufacturing, sensor data can be vast and heterogeneous. Most organizations maintain many different systems, and each organization has unique rules and processes for handling the data contained within those systems.
Google Cloud provides end-to-end data cloud solutions to store, manage, process, and activate data starting with BigQuery. BigQuery is a fully managed data warehouse that is designed for running analytical processing (OLAP) at any scale. BigQuery has built-in features like machine learning, geospatial analysis, data sharing, log analytics, and business intelligence. MongoDB is a document-based database that handles the real-time operational application with thousands of concurrent sessions with millisecond response times. Often, curated subsets of data from MongoDB are replicated to BigQuery for aggregation and complex analytics and to further enrich the operational data and end-customer experience. As you can see, MongoDB Atlas and Google Cloud BigQuery are complementary technologies.
Introduction to Google Cloud Dataflow
Dataflow is a truly unified stream and batch data processing system that's serverless, fast, and cost-effective. Dataflow allows teams to focus on programming instead of managing server clusters as Dataflow's serverless approach removes operational overhead from data engineering workloads. Dataflow is very efficient at implementing streaming transformations, which makes it a great fit for moving data from one platform to another with any changes in the data model required. As part of Data Movement with Dataflow, you can also implement additional use cases such as identifying fraudulent transactions, real-time recommendations, etc.
Announcing new Dataflow Templates for MongoDB Atlas and BigQuery
Customers have been using Dataflow widely to move and transform data from Atlas to BigQuery and vice versa. For this, they have been writing custom code using Apache Beam libraries and deploying it on the Dataflow runtime.
To make moving and transforming data between Atlas and BigQuery easier, the MongoDB and Google teams worked together to build templates for the same and make them available as part of the Dataflow page in the Google Cloud console. Dataflow templates allow you to package a Dataflow pipeline for deployment. Templates have several advantages over directly deploying a pipeline to Dataflow. The Dataflow templates and the Dataflow page make it easier to define the source, target, transformations, and other logic to apply to the data. You can key in all the connection parameters through the Dataflow page, and with a click, the Dataflow job is triggered to move the data.
To start with, we have built three templates. Two of these templates are batch templates to read and write from MongoDB to BigQuery and vice versa. And the third is to read the change stream data pushed on Pub/Sub and write to BigQuery. Below are the templates for interacting with MongoDB and Google Cloud native services currently available:
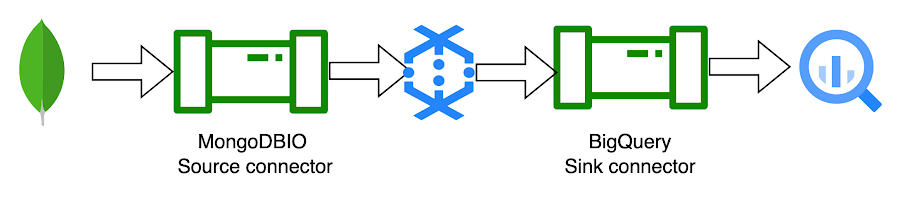
1. MongoDB to BigQuery template:
The MongoDB to BigQuery template is a batch pipeline that reads documents from MongoDB and writes them to BigQuery
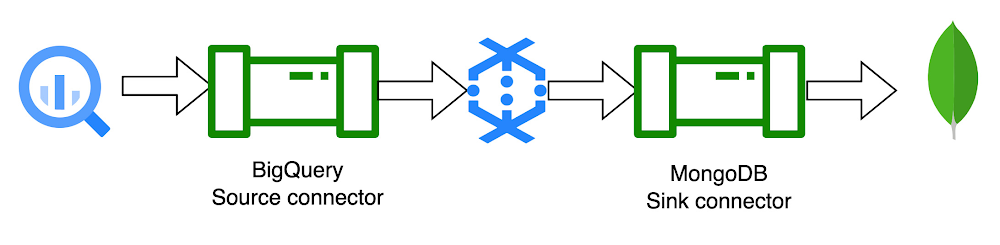
2. BigQuery to MongoDB template:
The BigQuery to MongoDB template can be used to read the tables from BigQuery and write to MongoDB.
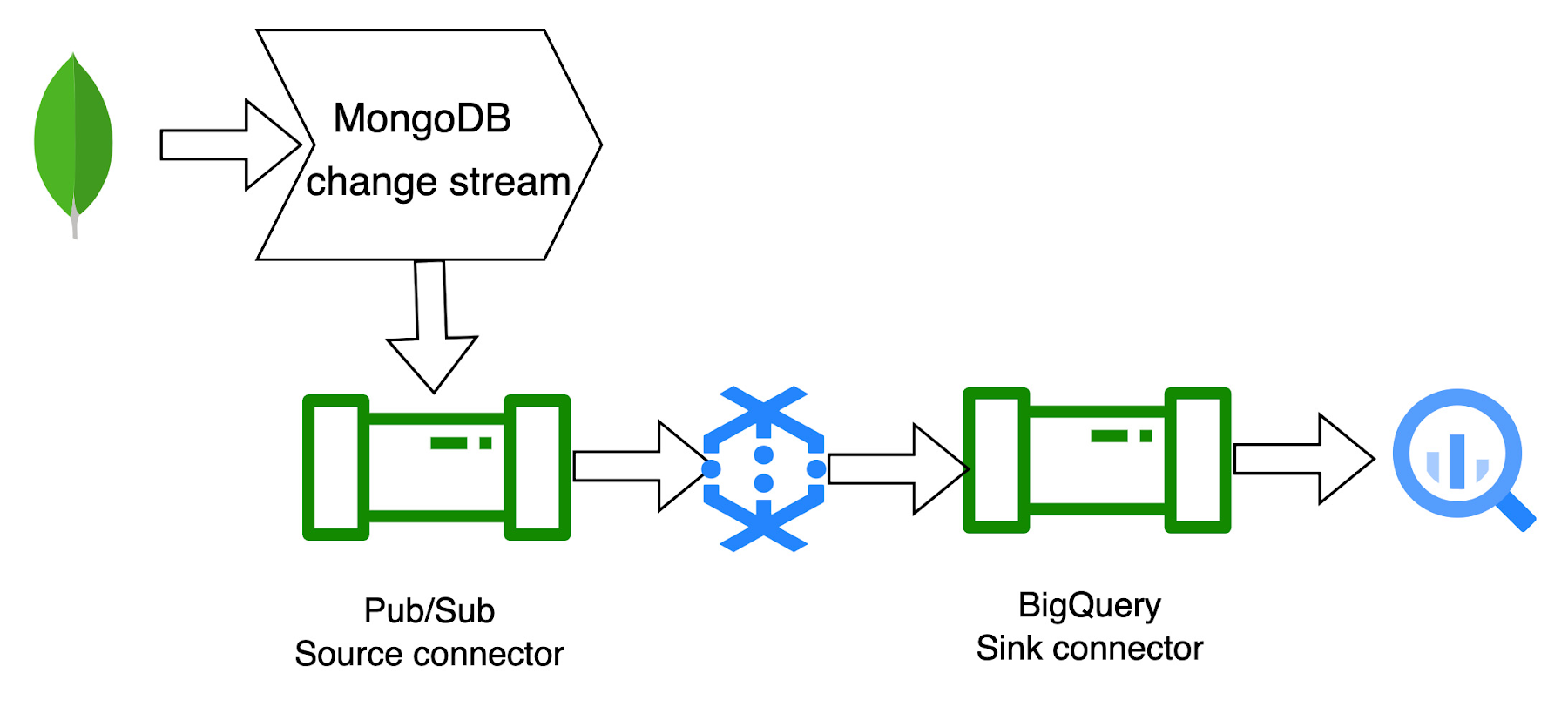
3. MongoDB to BigQuery CDC template:
The MongoDB to BigQuery CDC (Change Data Capture) template is a streaming pipeline that works together with MongoDB change streams. The pipeline reads the JSON records pushed to Pub/Sub via a MongoDB change stream and writes them to BigQuery
The Dataflow page in the Google Cloud console can help accelerate job creation. This eliminates the requirement to set up a java environment and other additional dependencies. Users can instantly create a job by passing parameters including URI, database name, collection name, and BigQuery table name through the UI.
Below you can see these new MongoDB templates currently available in the Dataflow page:
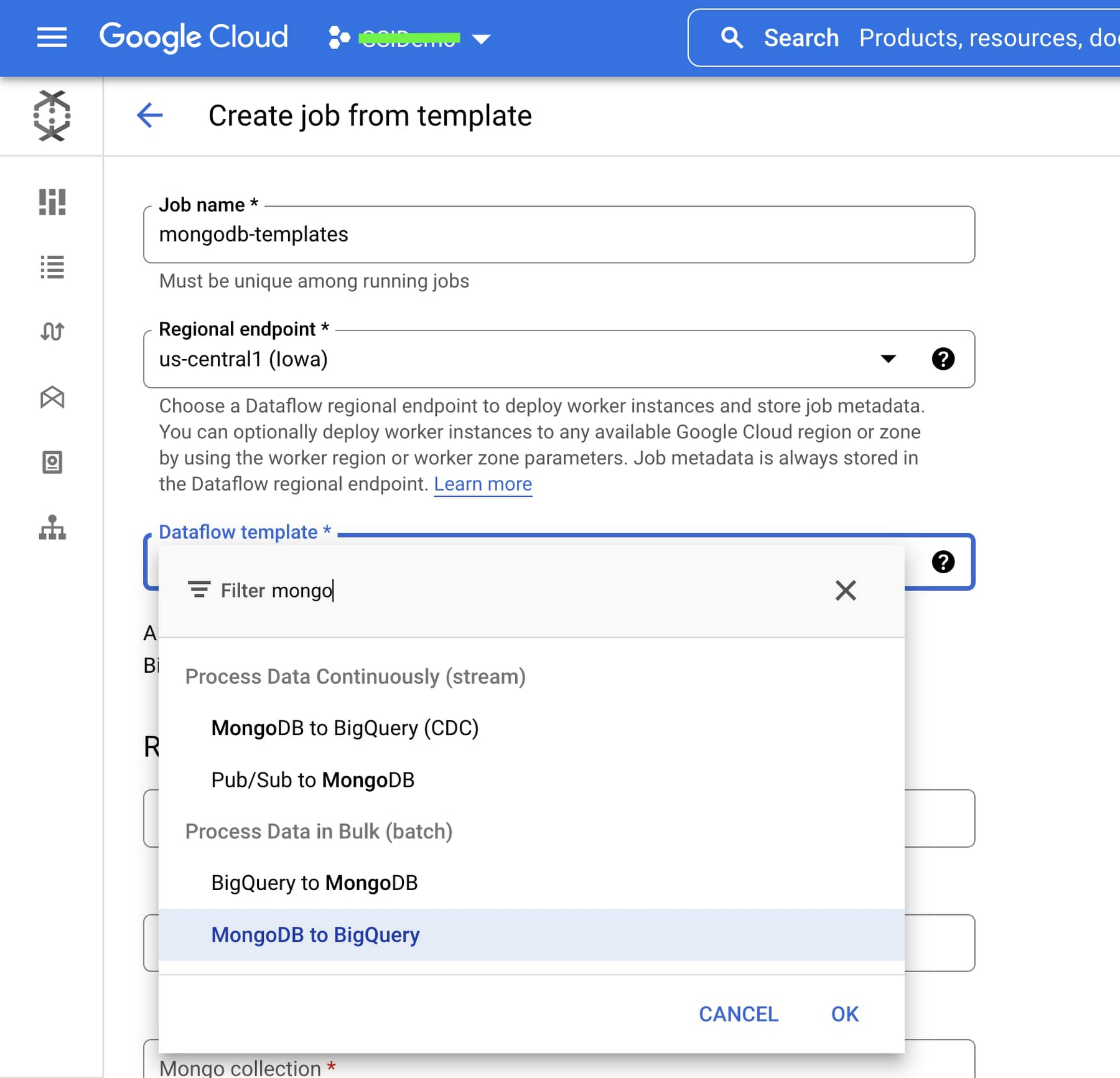
Below is the parameter configuration screen for the MongoDB to BigQuery (Batch) template. The required parameters vary based on the template you select.
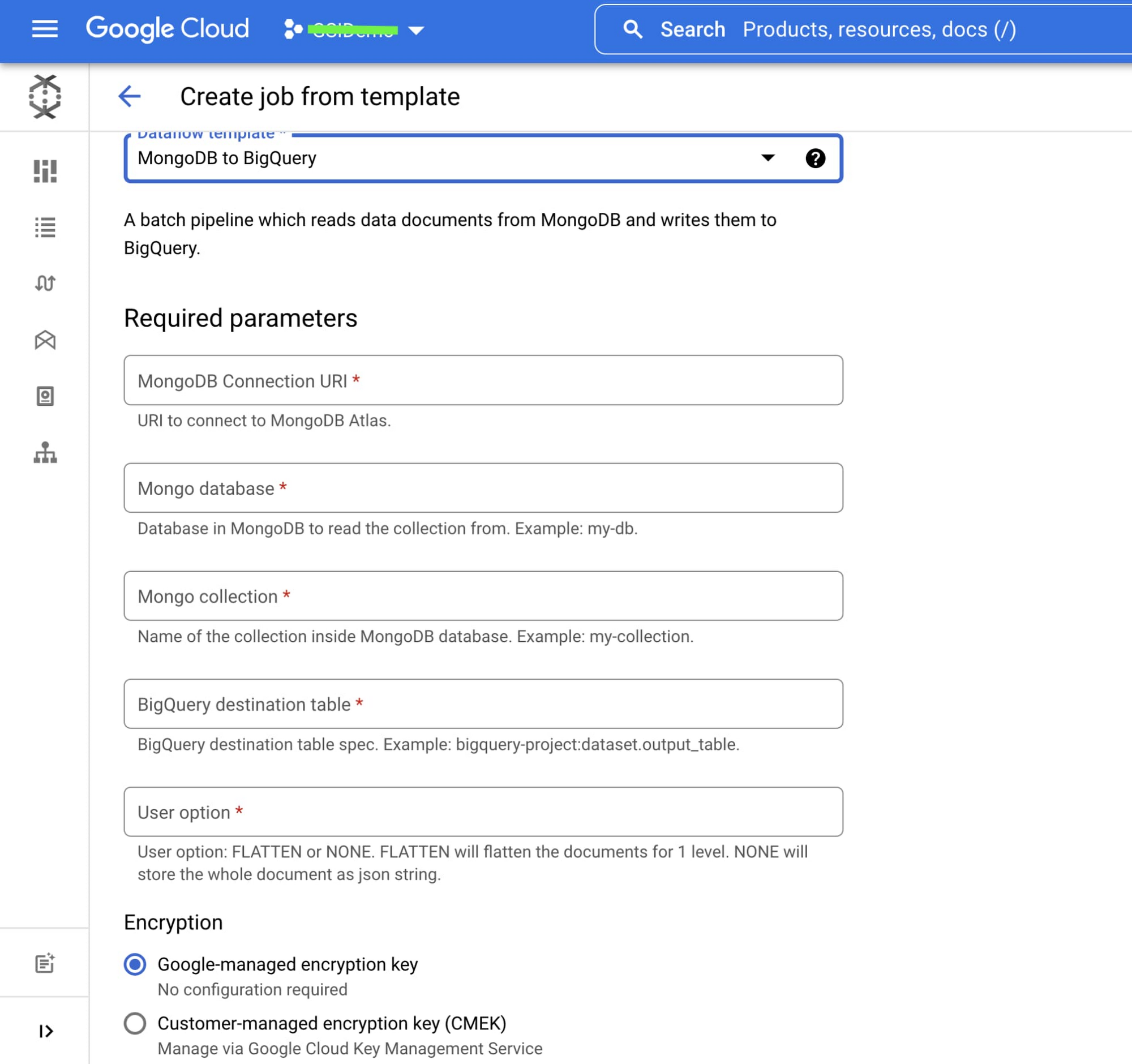
Getting started
Refer to the Google provided Dataflow templates documentation page for more information on these templates. If you have any questions, feel free to contact us or engage with the Google Cloud Community Forum.
Reference
Acknowledgement: We thank the many Google Cloud and MongoDB team members who contributed to this collaboration, and review, led by Paresh Saraf from MongoDB and Maruti C from Google Cloud.


