Databases on Google Cloud part 2 - Options at a glance

Abirami Sukumaran
Staff Developer Advocate, Google
A guide to databases on Google Cloud: Part 2 - Options at a glance
Isaac Newton said, “If I have seen farther than others it is because I have stood on the shoulders of giants.” He meant that in order to explain the Law of Gravity, he used the work of major thinkers who came before him in order to make intellectual progress (as-in giving credit). In the 1640’s (yes, the time of the English Civil War and the start of the mini Ice Age), we can say the Age of Reason began and the word “data” was also (re)born in a way. Why? Hard to assert a specific reason, it could be apropos of all those events of that decade, and somewhere amidst all that, the scientists and Churchmen (rather Churchman, Henry Hammond who really coined the term data) started to pen down their credit in books and there was a continued proliferation of data to reason their finding (and most times to reason why their work was better than that of the others). And thus comes to us the word datum from the Latin verb dare (it means “to give”, not the English dare).
Dare to Recap History?
Data is history captured through language (it has become the future as well, but that is for another day). Now we all like history (well, most of us). But it is highly likely the context gets lost in the complexity and style of definition. One way to mitigate that risk is to have a clear set of definitions (language), sustained hold of events (history), a clean process of capture (extract) and a scalable process for translation and aggregation (transform). If we want our data to be successful and rise to the occasion, then we need to keep these ways to mitigate the risk of complexity in mind.
And this is exactly what we discussed in the Part 1 of this blog series, Data Modeling Basics - The various business characteristics, technical aspects, design questions, and considerations for designing your database model.
In this blog…
We will look into the different databases and storage options in Google Cloud, a brief note on each one of them, a few key feature highlights and exceptions if any if you make it to the end of the blog, a fun challenge to make sure we put this little tech nugget to an ACID test (see what I did there?). If you are a cloud enthusiast, a database practitioner, a data geek, or a general wonderer of life with computing, you may find this engaging… A kind note: By the time you are reading this blog, a lot of key features and changes would have been included to some database services in Google Cloud following recent announcements. Please do keep in mind that while this can give you a good starting point to learning the basics of the various Database Service options in Google Cloud, you should reference documentation for recent updates.
Google Cloud Storage Options
We at Google Cloud, have realized how hard it is to go through these laundry list assessment aspects and have made it simpler for you with a Decision Tree. (Of course, It ain't Christmas if not for the tree):
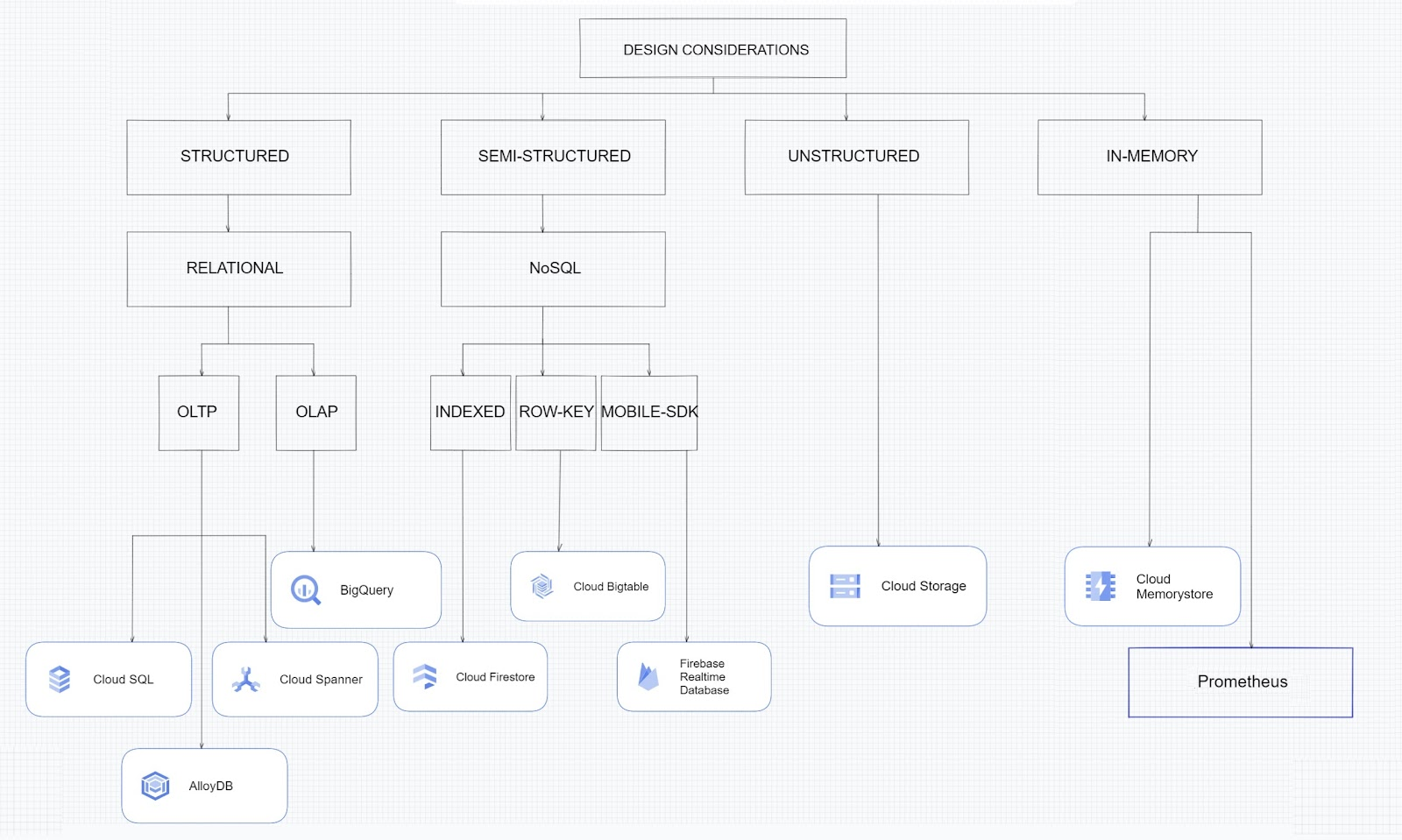
If only the world was always “Structured”
In a structured world, you will know all the attributes on a first-name basis (I mean to say that you will have a well defined fixed set of attributes that can be modeled in a table of rows and columns), and the applications are transactional or analytical in orientation. Transactional Structured Data operate one row at a time generally and they need to adhere to ACID compliance. (Ah. Now you connect the dots, if not already.) ACID properties are Atomicity, Consistency, Isolation, and Durability. Cloud SQL and Cloud Spanner are our Google Cloud choices for Transactional Structured Data use cases.
In essence, this blog covers 1) key features, 2) list a few use cases and 3) security highlights of each database under the different types and structures of data. This blog is intended for developers as a quick and narrow reference to Google Cloud databases. For a detailed overview of these products, their features and use cases, refer to their documentation. Also note that it is a high level summary of the products and services so this blog is not intended to cover every key feature included in the offering, please refer to product docs. However there are upcoming blogs in this series that are intended to cover specific technical deep-dives and experiments for select use-cases for the database and storage options in Google Cloud.
Note: Before we begin Cloud SQL introduction, let's understand Managed Databases. A managed database is one that does not require as much administration and operational support (creating databases, performing backups, updating the database instances and the underlying operating system) as an self-managed database.
Cloud SQL
Fully Managed, cloud-native ANSI-SQL RDBMS (Relational DataBase Management System) that offers MySQL, PostgreSQL, SQL Server engines with 99.95% SLA
Scales workloads within and across regions, writes scale up and reads scale out
Offers rich extension collections, configuration flags, and developer ecosystem, but without the hassle of self management
Up to 64 TB of storage available, with the ability to automatically scale up as your data grows - add up to 96 processor cores and up to 624 GB of RAM and 64 TB of storage and add read replicas to handle increasing read traffic
Many Cloud SQL users today leverage read replicas for building dimensional data models to use the most up to date data without significant data movement and without impacting the read/write workload on the primary instance
Later in this blog, we will also cover databases that are built to address more complex analytical requirements like dynamic schemas on a per-object basis and extended analytical processing on a huge amount of data.
Security
Data stored is encrypted both in transit and at rest
Have built-in support for access control, using network firewalls to manage database access,
Supports private connectivity with Virtual Private Cloud (VPC), and every Cloud SQL instance includes a network firewall, allowing you to control public network access to your database instance
Support for secure external connections with the Cloud SQL Auth proxy or with the SSL/TLS protocol, Audit Logging, Customer-managed encryption keys (CMEK), IAM database authentication, Cloud External Key Manager (EKM), access transparency and justification. Refer this link for detailed understanding of EKM and Key Access Justifications
Cloud SQL supports Access Transparency and Access Approval by expanding visibility and control with admin access logs and approval controls
These capabilities enable customers to satisfy a wide range of government and industry regulatory compliance requirements across the world. For a more comprehensive list of features, please refer to the docs.
Cloud Spanner
Relational, horizontally scalable, global database with strong consistency
Supports schemas, ACID transactions, and SQL queries (ANSI 2011)
Scales horizontally in regions, but can also scale across regions for workloads that have more stringent availability requirements
Handles large amounts of data and for high transactional consistency
Preferred when you require sharding for higher throughput, access and low latency
Typically Cloud Spanner is a recommended storage system for applications that require large scalability, transactional compliance at global scale and ANSI 2011 standard and PostgreSQL Query compliance. As mentioned earlier we have other offerings in the catalog that serve the online analytical processing (OLAP) workloads.
Now with the Granular Instance Compute Capacity called “Processing Units” or PUs, you can run workloads on Spanner at as low as 1/10th the cost of regular instances, equating to approximately $65/month.
Security
Security features in Spanner include data-layer encryption, audit logging, and Identity and Access Management (IAM) integration to just list a few. For a detailed list of features, please refer to the product documentation.
Analytical Structure is when we want the data to tell us an aggregated or enhanced story, for which we use limited columns and multiple rows and hence mostly use a Column-Oriented storage mechanism. Column-oriented storage is if we want to store the data in the tables by columns instead of by rows, and this column-oriented storage is done to efficiently access only a subset of columns for querying. BigQuery is the data warehouse option for analytics needs.
Note: A data warehouse stores large quantities of data for query and analysis instead of transactional processing.
BigQuery
BigQuery is a fully managed Data Warehouse for analytics with built-in data transfer service
Peta-byte scale, low-cost warehouse that supports loading data through the web interface, command line tools, and REST API calls
Incorporates features for machine learning, business intelligence, and geospatial analysis that are provided through BigQuery ML, BI Engine, and GIS
For use cases that cover process analytics and optimization, big data (Petabyte scale) processing and analytics, data warehouse modernization, machine learning-based behavioral analytics, and predictions
Security
BigQuery provides encryption at rest and in transit. Cloud Data Loss Prevention (Cloud DLP) can be used to scan the BigQuery tables and to protect sensitive data and meet compliance requirements. BigQuery supports access control of datasets and tables using Identity and Access Management (IAM). For a full list of features and use cases, refer to documentation.
Next stop, we have the Semi-structured and the Unstructured world of data that we will address in the below sections. For details on what is semi-structured, refer to part 1 of the series.
Cloud Firestore (Cloud Datastore)
Firestore is the next major version of Datastore and a re-branding of the product (Datastore). Taking the best of Datastore and the Firebase Realtime Database, Firestore is a NoSQL document database built for automatic scaling, high performance, and ease of application development.
A fully managed, serverless NoSQL Google Cloud database designed for the development of serverless apps that stores JSON data
Can be used to store, sync, and query data for web, mobile, and IoT applications
Automatically handles sharding and replication making it highly available, durable, and scalable
Provides ACID transactions, SQL-like queries, indexes, and more against your document data
If a client does not have network connectivity, the Firestore API lets your app persist data to a local disk and synchronizes itself with the current server state once connectivity is reestablished
For use cases of app development, live synchronization, offline support, multi-user collaborative applications, leaderboard, etc
Not a relational database so not meant for relational structured data applications and use cases.
Security
Firestore Security Rules support serverless authentication and authorization for the mobile and web client libraries. Identity and Access Management (IAM) manages database access.
For a full list of features refer to documentation.
Cloud Bigtable
Bigtable is a wide-column, fully managed, high-performance NoSQL database service designed for terabyte- to petabyte-scale workloads
Bigtable is battle tested on Google internal Bigtable database infrastructure that powers Google Search, Google Analytics, Google Maps, and Gmail
Provides consistent, low-latency, and high-throughput storage for large-scale NoSQL data
Typically used for large amounts of single key data and is preferable for low-latency, high throughput workloads and for real-time app serving workloads and large-scale analytical workloads
Bigtable is not a relational database. It does not support SQL queries, joins, or multi-row transactions
Security
All the data at rest in Cloud Bigtable is encrypted using Google's default encryption, by default.
Instead of Google managing the encryption keys that protect your data, your Bigtable instance can also be protected using a key that you manage (customer-managed encryption keys (CMEK)) in Cloud Key Management Service (Cloud KMS).
For a full list of security and other features, refer to the documentation.
Cloud Storage
Google Cloud Storage is an object storage system that is durable and highly available, persists unstructured data like images, videos, data files, videos, backup, and other data
It is unstructured and so the files in the cloud storage are atomic that you read the entire file but you cannot access specific blocks in the files
Cloud Storage is available in multiple classes, depending on the availability and performance required for apps and services
- Standard - Offers the highest levels of availability and is appropriate for storing data that requires low-latency access
- Nearline - Low-cost, highly durable, fast-access storage service for storing data that you access less than once per month
- Coldline - Very-low-cost, highly durable, fast-access storage service for storing data that you intend to access less than once per quarter
- Archive - Lowest-cost, highly durable, fast-access storage service for storing data that you intend to access less than once per year
Security
Files in Cloud Storage are organized by project into individual buckets. These buckets can support either custom access control lists (ACLs) or centralized identity and access management (IAM) controls.
For a full list of security and other features, refer to documentation.
Firebase Realtime Database
Firebase is a realtime, NoSQL, Google Cloud database that is a part of the Firebase platform that allows you to store and sync data in real-time and includes caching capabilities for offline use
Data is stored as JSON and synchronized in real-time to every connected client and remains available when app goes offline
Typically used for mobile and web app development, development of apps that work across devices
Not used in relational dataset use cases. The Realtime Database is a NoSQL database and as such has different optimizations and functionality compared to a relational database
Security
The Realtime Database provides a flexible, expression-based rules language, called Firebase Realtime Database Security Rules, to define how your data should be structured and when data can be read from or written to. When integrated with Firebase Authentication, developers can define who has access to what data, and how they can access it.
For a full list of security and other features, refer to documentation.
That’s a rather packed read. But I hope you find this useful to understand comprehensively the basics of data, storage options and databases in Google Cloud Platform. To list a few in rapid-fire summary (not all options are covered):
If you need full SQL support for an online transaction processing (OLTP) system, consider Cloud Spanner or Cloud SQL
If you need interactive querying in an online analytical processing (OLAP) system, consider BigQuery
If you need to store highly structured objects in a document database, with support for ACID transactions and SQL-like queries, consider Firestore
For in-memory data storage with low latency, consider Memorystore
To sync data between users in real-time, consider the Firebase Realtime Database
Next Steps, before I go…
For more information about other database options, see the overview of database services and Google Cloud storage options. There are 2 products that I haven’t mentioned in this blog so far, use the links to get an overview, more on those in another series:
Managed Service for Prometheus: In-Memory, Time Series Database Service - Google Cloud's fully managed storage and query service for Prometheus metrics. This service is built on top of Monarch, the same globally scalable data store as Cloud Monitoring. Since this is the same back end that powers Google Cloud’s monitoring service, you can query, visualize, and analyze metrics from both services together in Cloud Monitoring
The newest in the league, AlloyDB (A fully managed PostgreSQL-compatible database service for the most demanding enterprise database workloads) in this episode. But let’s save that for another part.
In the blog part 1 of the series, I ended with an action item - “How would you model a NoSQL solution for an application that needs to query the lineage between individual entities that are represented in pairs?”.
Well, my answer is Firestore. As part of this episode, why don’t you take some time to go over the options and key aspects that attribute to this.




