Structuring unstructured text with the Google Cloud Natural Language API
Jerjou Cheng
Developer Programs Engineer
Imagine you need to analyze a large corpus of free-form text, a collection of news articles or user feedback to glean insights. Perhaps you’d like to discern the prominent figures in the news for a given time period, or how people feel about your products based on their written feedback. Normally you might search for specific names if you knew who to search for, or perhaps send out a survey asking your users to rate your product from 1 to 5 so you can have a number with a known meaning you can average. But instead, all you have is a mass of unstructured text representing folks griping or gushing about any one of a number of products, or about any number of newsworthy people you might not even know about.
This is a use case where the Google Cloud Natural Language API shines. Using the Natural Language API, you can take a blob of text that was previously unstructured and add structure to it — you can detect entities present in the text (people, consumer goods, etc.), the sentiment expressed and other things. Once that’s done, you can engage your existing toolset, or services like Google BigQuery, to analyze the imputed structure and derive insights.
Let’s look at an example. For this demo, we’ve created an App Engine web app that uses the Wikipedia API to dynamically pull the text of a Wikipedia article and analyze it for sentiment, as well as entities mentioned. The app then uses the metadata from the API to call out entities important to the article, and links all the mentions of an entity together. If you hover over a detected entity, it highlights other occurrences of it in the text. For example, take a look at the processed article on the Android Operating System:
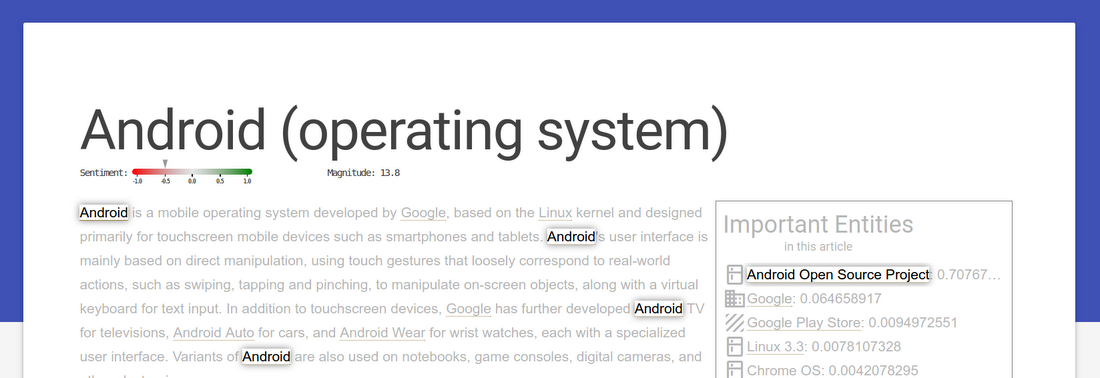
Clicking on an entity takes the analysis a bit further, and pulls up a graph of “related” entities of the same type. “Relatedness” in this case is calculated across the entire Wikipedia corpus, and measures the number of articles where both entities appear. For entities that are consumer goods, this often provides insight into comparable products — to wit, clicking on “Android” displays the following graph:

Let’s take a look at how we calculate this metric.
The magic happens through a preprocessing step. For this demo we process Wikipedia articles, but in principle the same processing can be performed on timestamped news articles, customer feedback or any other corpus of text you’d like to analyze.
To retain as much flexibility as possible for analyzing this data, we’ll run every article through entity detection and sentiment analysis, and save the structure we obtain directly. Google Cloud Platform makes this a straightforward process, using a combination of Cloud Dataflow and BigQuery. We first do a bit of preprocessing of Wikipedia’s XML dump, parsing the XML and markdown and filtering out Wikipedia meta pages:
Cloud Dataflow automatically runs this pipeline in parallel, which takes about an hour to filter the 53 GB of raw XML into ~5 million text-only articles. We now pass these articles through the Natural Language API, and output all the entities, coupled with the article’s sentiment and other metadata, into BigQuery:
We’ve now created structured data from unstructured text!
Fun with BigQuery
Because the text blobs now have defined structure, we can use tools like BigQuery to run queries against our heretofore opaque blob of text, gaining insight that was previously unavailable to us — especially across datasets too big for humans to process manually.Let’s see a little bit of what we can do with all this data. This simple query gives us the five most-mentioned entities in Wikipedia, by number of articles:
| Row | entity_name | num_articles |
| 1 | United States | 653420 |
| 2 | English | 591128 |
| 3 | American | 562490 |
| 4 | British | 336654 |
| 5 | London | 325461 |
Okay, it makes sense that the English-language Wikipedia would mention entities associated with the language quite a bit. But perhaps we’re more concerned with, say, consumer goods than we are with nation-states — we can pose the following query:
| Row | entity_name | num_articles |
| 1 | Windows | 14610 |
| 2 | iTunes | 13281 |
| 3 | Android | 6020 |
| 4 | Microsoft Windows | 5754 |
| 5 | PlayStation 2 | 5301 |
This gives us an idea about the products that Wikipedia denizens write about. However, the sheer number of articles that mention a product doesn’t give a sense for how the product is perceived. Fortunately, our preprocessing pipeline also extracted the sentiment from the articles. Let’s use that to find what products are most favorably portrayed in our corpus:
| Row | entity_name | sentiment |
| 1 | NASCAR | 1.8 |
| 2 | SRX | 1.5 |
| 3 | Sugar | 1.2 |
| 4 | Formula One | 1.1 |
| 5 | iPod Touch | 1.1 |
Note: The above query also includes a filter on the salience of the entity, which is a measure (from 0 to 1) of how important the entity is to the article it appears in. That is, if an entity is just mentioned in passing, the overall sentiment of the article isn’t really reflective of the entity.
We can, of course, also perform the related-entities query demonstrated in the demo app, to find entities that a given consumer good is associated with:
| Row | entity_name | num_articles |
| 1 | iOS | 2733 |
| 2 | iPhone | 2035 |
| 3 | Windows | 1543 |
| 4 | iPad | 1223 |
| 5 | Windows Phone | 841 |
The beauty of the Natural Language API is that it’s not restricted to the use cases we’ve mentioned, but generically provides a structure for entity, sentiment and syntax onto which you can then unleash your normal toolset. Try it out for your use case, and see what you can do!
- Natural Language API - for detecting entities, sentiment, syntax
- BigQuery - for ad-hoc data analysis on arbitrarily big data
- Cloud Dataflow - for easy distributed data processing
- Google Cloud Storage - for file storage & scratch space
- App Engine - for web app serving



