Running external libraries with Cloud Dataflow for grid-computing workloads
Reza Rokni
Dataflow Product Manager
A common pattern in banking, media and life sciences is the running of “embarrassingly parallel” workloads. In these environments, a large number of compute nodes form a cluster, with nodes independently carrying out processing tasks. In this post, I’ll explain how Google Cloud Dataflow, used in conjunction with other Google Cloud Platform (GCP) services, can unlock these workloads for Google Cloud customers. As these workloads will often make use of C++ libraries, which is not a native SDK for Cloud Dataflow, running them as external libraries will be the main focus of this post.
Why Cloud Dataflow?
Cloud Dataflow is a fully-managed GCP service for transforming and enriching data in streaming (real time) and batch (historical) modes with equal reliability and expressiveness. The Cloud Dataflow 2.0 SDK for Java is based on Apache Beam (more about Beam below).Across all applications of grid computing, there's a common thread: Distribution of data to functions that run across many cores, often requiring very high concurrency reads followed by a large fan-out of data to be absorbed by downstream systems.
Helpfully for these workloads, Cloud Dataflow’s core competency is the distribution of batch and stream workloads across resources and managing auto-scaling and dynamic work rebalancing across these resources (with performance, scalability, availability and security needs handled automatically). For Cloud Dataflow users, the short latency between data ingestion and the time that users can query the dataset (achieved with minimal development) has been proven to be very attractive. Cloud Dataflow is also integrated with other GCP managed services that can absorb massive-scale parallelized data I/O such as Cloud Bigtable (wide-column store for caching and serving), Cloud Pub/Sub (global event stream ingestion service), Cloud Storage (unified object store) and BigQuery (petabyte-scale data warehouse service). Used together, these services provide a compelling solution for embarrassingly parallel workloads.
Calling the external library
Apache Beam is an open source, unified model for defining batch and streaming processing pipelines. Pipelines programmed with Beam run on a choice of processing engines, including Cloud Dataflow, Apache Spark and Apache Flink.To run a library written in a language (such as C++) that does not have a native SDK in Apache Beam, you need to make an out-of-process call from the DoFn that's used to process the incoming element. In the work Google has done with customers, we've used the Java SDK, which allows for two options, each with its own pros and cons, described below. The variable and method names (e.g. PCollection, DoFn) mentioned below are all standard parts of the Beam/Dataflow Java SDK. For data input and output, we rely on Beam/Dataflow SDK primitives.
Setup
When using a native Apache Beam language (Java or Python), the SDK will automatically move all required code to the workers. In the case of making a call to an external library, you need to do this step manually for that library. The approach is to:- Store the code (along with versioning information) in Cloud Storage, this removes any concerns about throughput if running 10,000s of cores in the flow.
- In the
@beginBundlemethod, create a synchronized block to check if the file is available on the local resource. If not, use the Cloud Storage client library to pull the file across.
Getting the data needed for the processing
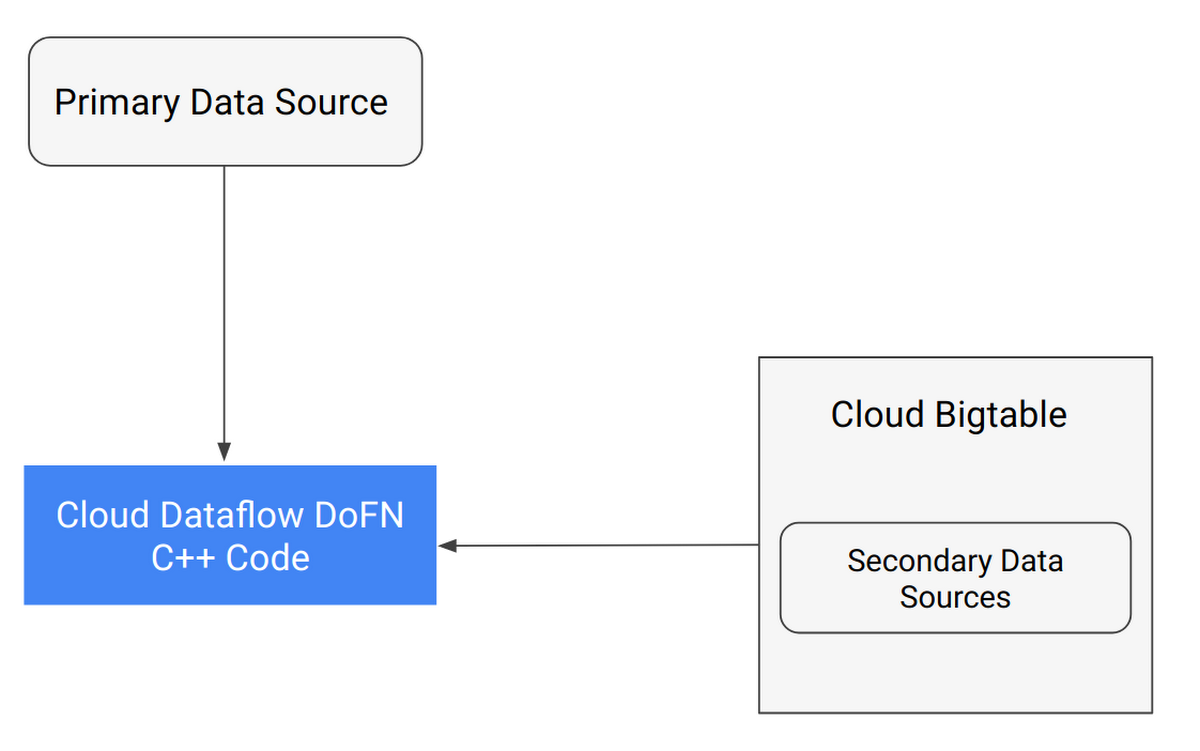
The data access method depends on the use case; there are several strategies that can be used individually or in combination. In Figure 1, the primary data source becomes thePCollection that drives the work distribution with each element being pushed out to the DoFn; the SideInput is a one-time read of the other data sources that then become available for the DoFn. This pattern works well for smaller secondary data sources (under 1GB). For larger data sets (1GB to 100s of TB), the pattern in Figure 2 is recommended.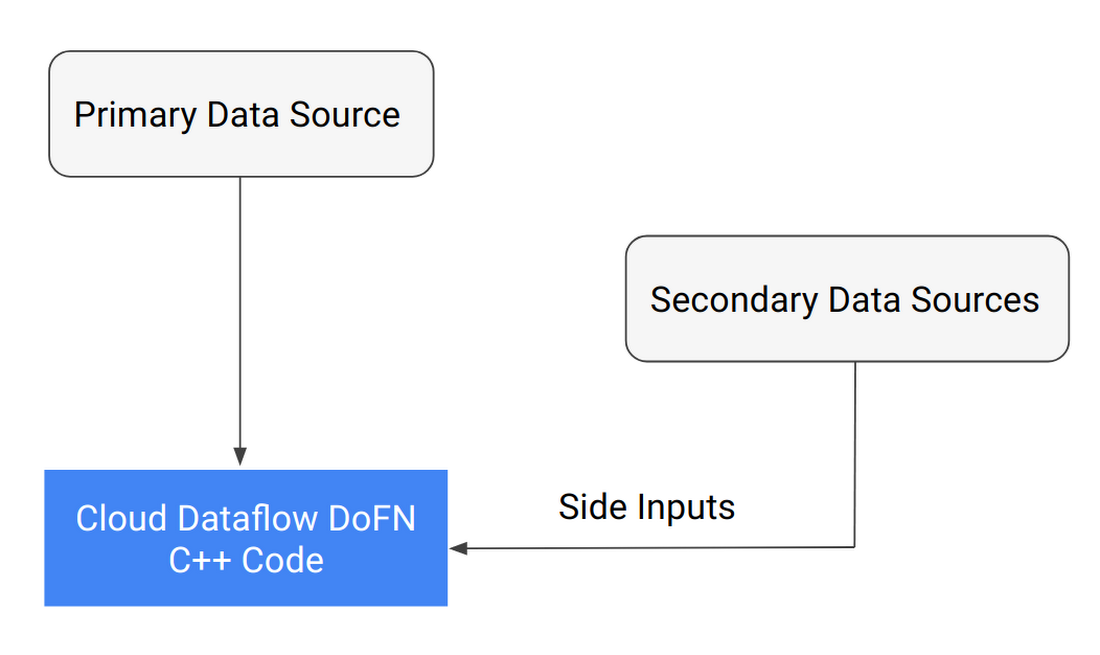
If the use case does not have the concept of a primary data source, then create a PCollection containing integers where the count() of the values is == the number of times the process should be executed.
Running the external library
Using JNIJNI is a reasonable abstraction that provides a nice way to deal with passing data into and out of the external library. Being efficient in terms of performance, this approach is ideal if the C++ library is well established and very stable. The key challenge here is that if the C++ library is unstable, it can throw segfaults.
Catching these errors becomes problematic as any failure can take the JVM along with it. If that’s the case, the java process described below is a more robust and recommended approach.
Java process call
Although this method is slightly less efficient than JNI, in practice it has proven to have attractive advantages for robustness. Even the small efficiency difference becomes irrelevant when the processing to be done requires many seconds, minutes (or even hours) for every element.
In this mode, you redirect stdout and stderr pipes to files to avoid any out-of-memory considerations, ensuring a robust system. We highly recommend against the use of stdout to pass the result of the computation back to the DoFn because the other libraries that your C++ code calls may send messages to stdout as well, thereby polluting it with logging info. Instead, it's a much better practice to make a small change to the user C++ code to accept a parameter that indicates where to create a .ret file that stores the value. Ideally this file will be stored in a protobuf format that allows the C++ code to pass an object back to the Java code. The DoFn can then read the result directly from the .ret file and pass it onto its output() call.
The future
With any new technology, what's most exciting is not the faster/cheaper discussion (which is always nice of course!) but how it can improve the way things are done. With a Cloud Dataflow external library, rather than building monolithic C++ functions, it's possible to tightly integrate the flow of data to and from this code directly into the data pipeline. For example, take a computation that's the result of 10 functions chained together in the library. As I/O is much easier to deal with, storing intermediate results allows for much easier debugging of subtle computational issues.Another advantage is that the pipeline DAG can now include multi-branched pipelines, allowing a single run to include multiple computations that can be brought back together using native primitives in Apache Beam such as SideInputs, SideOutputs, GroupByKey and joins.
And of course the main advantage is the ability to benefit from Dataflow’s operational ease of use and efficiency by running processing pipelines that don’t require any infrastructure provisioning, maintenance or configuration. Just submit your jobs when you need them, and pay exactly for what you consume.



