Real-time data visualization and machine learning for London traffic analysis
Justin Kestelyn
Product Marketing Lead
This POC, based on Google Cloud Platform, illustrates how even incremental use of machine learning can yield differentiating applications
Employees of Datatonic, a Europe-based data analytics consultancy, recently participated in a week-long hackathon (“Data in Motion Hack Week”) organized by Traffic for London (TfL), that city’s official transport authority. As you might expect, the goals of the hackathon included stimulating developer creativity to overcome, through innovative use of public-cloud infrastructure and open data, high-priority TfL challenges such as limited overall transport capacity, endemic road congestion and air-quality degradation. (Whether you’re a resident of London, the San Francisco Bay Area, Rome, Sao Paulo, or Beijing, you can probably relate to these challenges.)
Most of the other teams chose to focus on data mashups or visualizations to give London residents information for making better route decisions during their commutes. The Datatonic hackers, in contrast, looked to machine learning (ML). By augmenting real-time data visualization with an ML model, they found they could predict areas of congestion during the morning and evening commutes, which currently stand at 30 million daily journeys, and more than 1 million net-new journeys expected by 2018. Their solution uses Google Cloud Platform (GCP) for storage and data processing and provides insights based on 3 months of data from 14,000 traffic sensors across London, amounting to well over 100 billion rows. (From this dataset, 8 days of data from 300 sensors were used for model-training purposes.)
Here’s a demo of Datatonic’s live traffic visualization app:
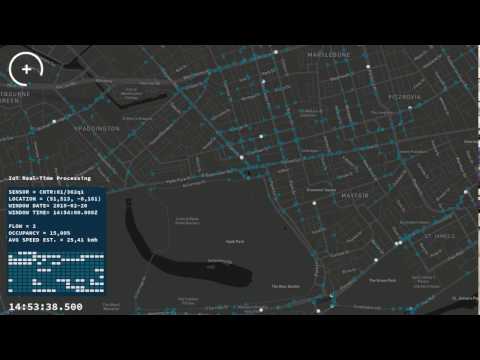
Of equal interest to this IoT-oriented use case is the fact that Datatonic’s solution spans the data analytics continuum: from data ingest and storage (Google Cloud Storage for batch or Google Cloud Pub/Sub for real-time), to data processing (Google Cloud Dataflow), to data exploration (Tableau on Google BigQuery), to machine learning/prediction (built using TensorFlow). In that sense, Datatonic’s app exemplifies the modern, cloud-based data analytics pipeline. Such pipelines accommodate varying data velocities and processing styles and ensure application portability via a single API (Apache Beam [incubating]), and enable backward-looking exploration in addition to prediction via custom or pre-built/trained models.
Furthermore, modern pipelines have the added benefit of operational (not just machine) abstractions that allow data engineers to focus on programming instead of infrastructure. More specifically, instead of those users having the unwanted responsibility of spinning up, right-sizing, and managing virtualized servers and networks, they can rely on the same automation techniques that Google developed to manage its vast internal infrastructure.
From storage and processing, to exploration, to prediction
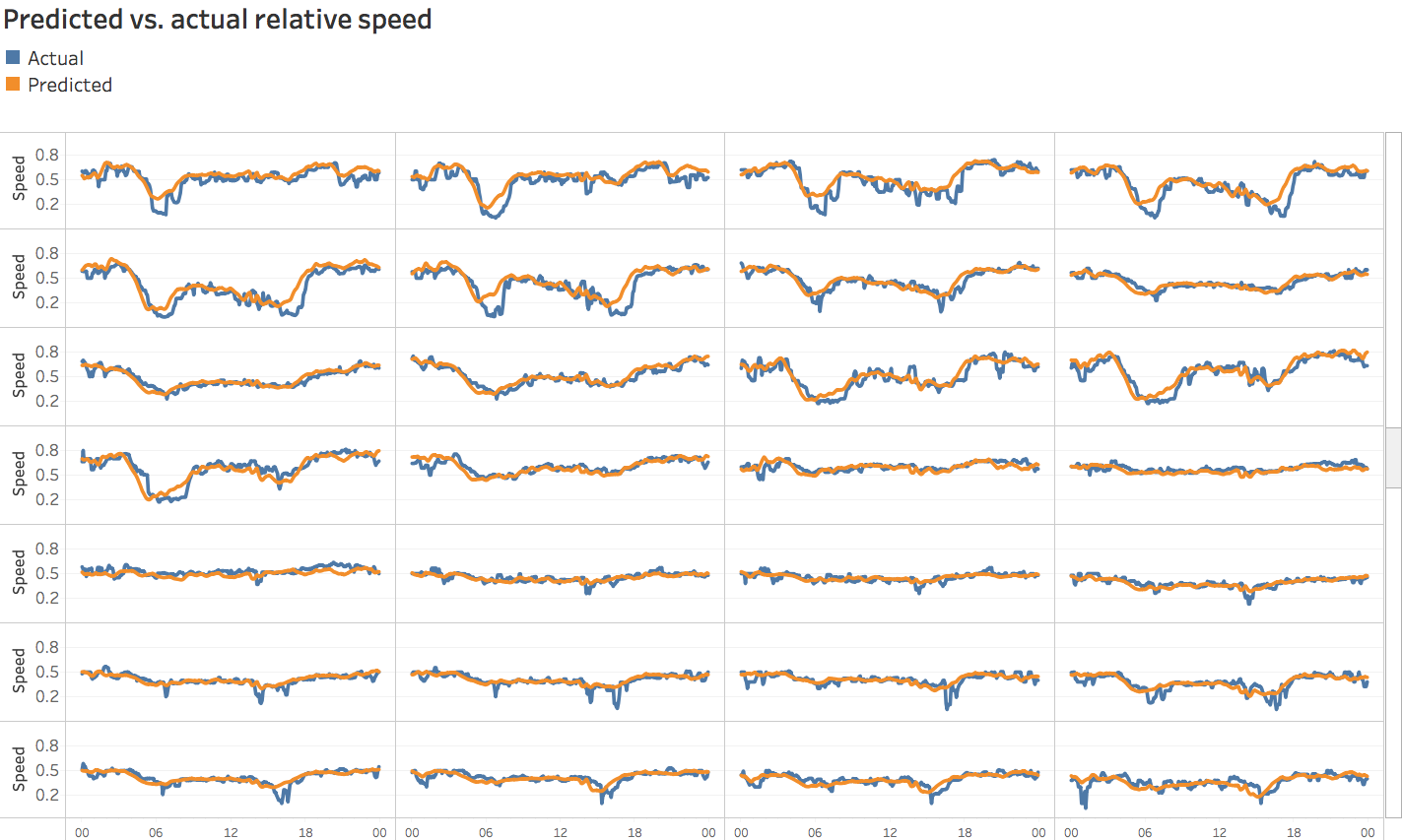
We applaud the Datatonic team for its innovative use of open data, and for its foresight in applying machine-learning concepts to show how even incremental use of ML can provide differentiating functionality. To illustrate the model’s potential, here are actual vs. predicted results provided by Datatonic for a small subset of sensors (training with more data would likely improve prediction accuracy):
We encourage you to experiment with building such a pipeline yourself; the GCP team has provided everything you need to get a similar POC off the ground relatively quickly:
- Bring your own data or select sample data from an interesting public dataset in Google Cloud Storage.
- Build a data processing pipeline on Google Cloud Dataflow using Java or Python.
- Load and explore the data using Google BigQuery.
- As the final step in the journey, add predictive capability to your app via Google Cloud Machine Learning (beta; build/train your own model or use pre-trained models via Cloud ML APIs).
For details about the Datatonic team’s methodology, architecture and results, see these blog posts:



