Google Cloud Platform adds new tools for easy data preparation and integration
Fausto Ibarra
Director of Product Management, Google Marketing Platform
When it comes to getting value from data — whatever its volume, velocity or variety — we’ve come a long way from the days of traditional data warehouses. The accelerating interest in, and adoption of, Google BigQuery suggests that building a culture of “citizen data science” is within reach for more organizations.
That said, there’s still work to be done. When I speak with customers and partners, it’s clear that barriers to adoption of data analytics remain: including the time and cost of building and maintaining infrastructure, of giving business users easy and more secure access to the right data sets for analysis, and especially, of data preparation — with some customers estimating up to 80% of total workload process time being devoted to it.
Today, as part of Google Cloud NEXT ‘17, we're excited to announce more offerings that directly address the challenges on that list. These new products and services will help organizations of all sizes focus even more tightly on solving business problems with data, rather than spending time and resources on building, integrating and managing underlying infrastructure.
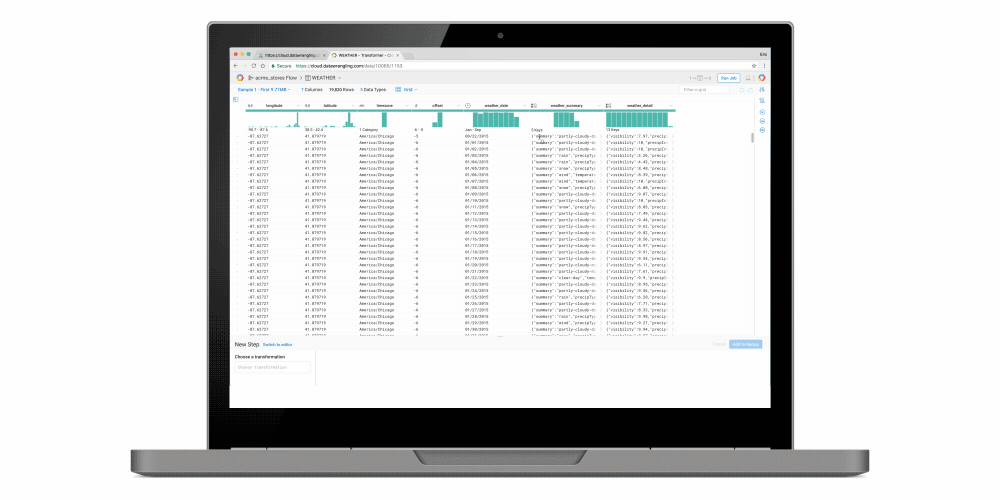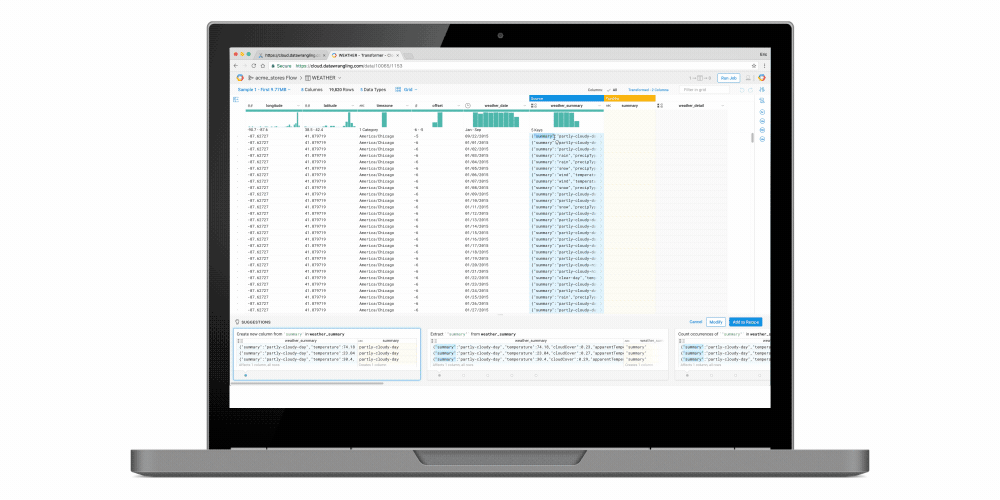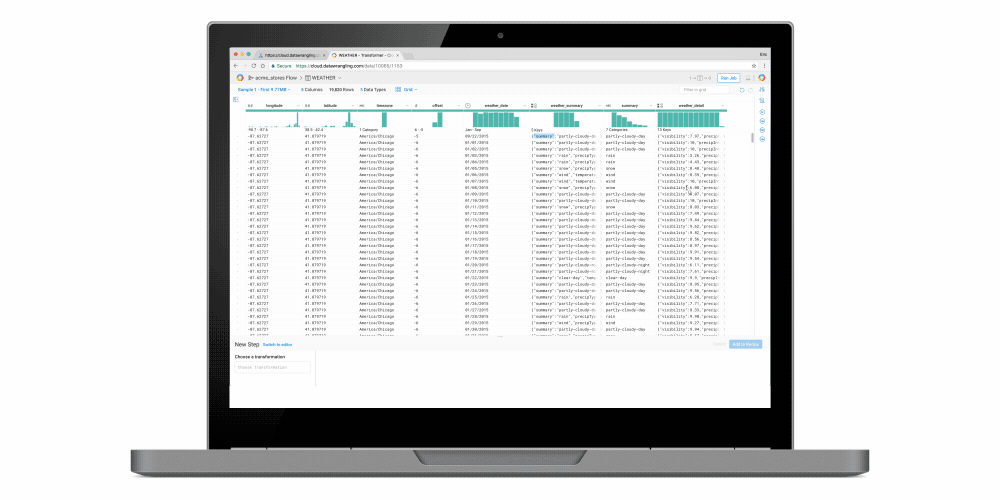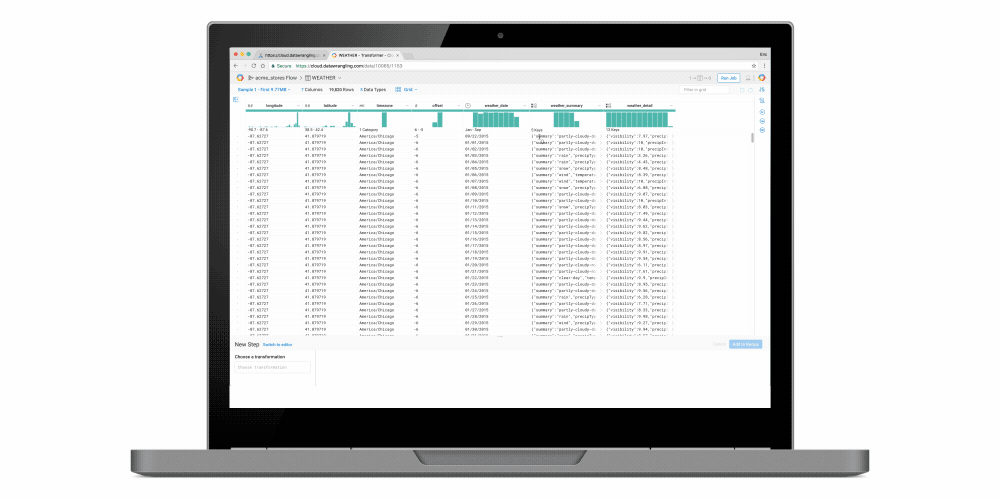
Easy data preparation with Google Cloud Dataprep
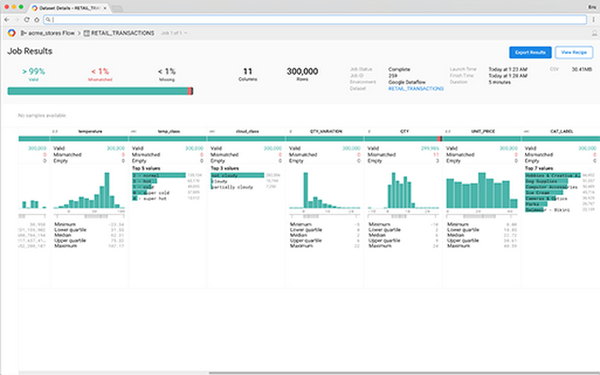
Google Cloud Dataprep (Private Beta) is a new managed data service, built in collaboration with Trifacta, that enables analysts and data scientists to visually explore and prepare data for analysis in seconds via the following features:- Anomaly detection: Cloud Dataprep automatically detects schema, type, distributions and missing/mismatched values. It utilizes machine learning to suggest corrective data transformations.
- Drag-and-drop development: An intuitive user experience eliminates the need for coding so that users can focus on analysis.
- Out-of-box integration with GCP: Users can more securely read raw data from Google Cloud Storage or BigQuery, or upload from their local machine and write back cleaned data into BigQuery for further analysis.
- Fully managed infrastructure: Like our other managed services, IT resource provisioning and management are handled for you automatically and elastically.
BigQuery enhancements: Data Transfer Service and federated query for Cloud Bigtable
BigQuery has established itself with customers like Hearst and The New York Times as a new kind of cloud-native enterprise data warehouse that allows users without deep experience in analytics to uncover amazing insights. Now, we're introducing two features that make it easier to access data from across the cloud and get insights from it faster:- The new BigQuery Data Transfer Service makes it easy for users to quickly get value from all their Google-managed advertising datasets. With just a few clicks, marketing analysts can schedule data imports from Google Adwords, DoubleClick Campaign Manager, DoubleClick for Publishers and YouTube Content and Channel Owner reports. By unifying digital-advertising data with existing reporting data (e.g., point-of-sale, inventory, customer-service request, and so on), customers can move much closer to a true 360-degree view of their marketing efforts. When these services are paired with Google Data Studio or with solutions from our visualization partners (including Tableau, Looker and Zoomdata), the time to insight is even shorter.
Zenith is leveraging Google Cloud to ingest impression, click and conversion data from Google, DoubleClick and the Aviva websites. After adding additional offline signals from the client and other data sources, this holistic picture of customer behaviour is reattributed using machine learning and fed back into DoubleClick Bid Manager and DS for more efficient media buying against those most likely to take a quotation. This closed loop system has resulted in 15% improvement in media efficiency for Aviva.
Ian Liddicoat, Global Head of Data, Technology and Analytics at Zenith
- We're extending BigQuery's reach to query data inside Cloud Bigtable, the NoSQL database service designed for massive analytic or operational workloads that require low latency and high throughput (particularly common in Financial Services and IoT use cases). BigQuery users can already query data in Google Cloud Storage, Google Drive and Google Sheets; the ability to query data in Cloud Bigtable is the next step toward a seamless cloud platform in which data of all kinds can be analyzed conveniently via BigQuery, without the need to copy it across systems.
Commercial data comes to BigQuery via Commercial datasets
Businesses often look for datasets (public or commercial) outside their organizational boundaries. Commercial datasets offered include financial market data from Xignite, residential real-estate valuations (historical and projected) from HouseCanary, predictions when a house will go on sale from Remine, historical weather data from AccuWeather and news archives from Dow Jones, all immediately ready for use in BigQuery (with more to come as new partners join the program).
After subscribing to these datasets with each respective data provider, you'll be ready to query this data in BigQuery immediately. As a customer, you can now focus on getting value from that data and spend less time worrying about how to load, store or version-control it.
Google Cloud is making Dow Jones’ world-class content and data easier to access than ever before. This will enable analysts and developers to use modern data analytics and machine-learning tools to integrate business-critical information into their workflows."
Clancy Childs, Chief Product & Technology Officer, Dow Jones
Next, I’ll describe some announcements pertaining to other parts of GCP’s data analytics stack.
Python for Google Cloud Dataflow in GA
Cloud Dataflow’s “serverless” approach removes significant complexity and operational overhead from data processing— in batch as well as stream-processing scenarios. Until recently, these benefits have been available solely to Java developers. Today, we're proud to announce general availability of the Python SDK for Cloud Dataflow for batch processing scenarios. The SDK comes directly from Apache Beam, and its implementation on Cloud Dataflow has proven popular for a variety of use cases where Python is commonly used, from ETL, to orchestrating large-scale image processing, to data preparation for machine learning.Stackdriver Monitoring for Cloud Dataflow (Beta)
Google Stackdriver provides monitoring and diagnostics for applications on GCP and AWS. Integrating Cloud Dataflow with Stackdriver Monitoring has been one of the most frequently requested features by customers, and today we're happy to announce a public beta that lets you access and analyze Cloud Dataflow job metrics and create alerts for specific Cloud Dataflow job conditions. For example, you can quickly build a dashboard showing streaming system lag, define an alert when lag increases above a predefined threshold and receive email and SMS notifications when the alert is raised.Google Cloud Datalab in GA
Cloud Datalab is now generally available! This interactive data science workflow tool makes it easy to do iterative model and data analysis in a Jupyter notebook-based environment using standard SQL, Python and shell commands. Developers and data scientists can use Cloud Datalab to explore, analyze and visualize data in BigQuery, Cloud Storage or stored locally. For machine learning development, they can take a full-lifecycle approach, building a model prototype on a smaller dataset stored locally, then training in the cloud using the full dataset stored in Cloud Storage. In this GA release, there's new support for TensorFlow and Scikit-learn, as well as batch and stream processing using Cloud Dataflow or Apache Spark via Cloud Dataproc.Google Cloud Dataproc updates
Cloud Dataproc, our fully-managed service for running Apache Spark, Flink and Hadoop pipelines, is designed to make stream processing easier, to accelerate pipeline development and make administration of clusters more flexible for customers. As additional support for those goals, we're announcing:- New support for automatically restarting failed jobs, thereby adding durability to long-running and/or streaming-related jobs (Beta)
- You can now create single-node clusters for lightweight data science, education and sandbox development (Beta)
- You can now attach GPUs to Cloud Dataproc clusters for jobs that involve compute-intensive workloads such as genomics (Beta)
- Cloud labels are now in GA, giving you more flexibility to manage your Cloud Dataproc resources
- Regional endpoints are now available, providing better isolation and performance for Cloud Dataproc resources based on your needs
- Cloud Storage operations are faster due to SSL optimizations where we've switched the Java SSL provider with one based on BoringSSL
Next steps
With these announcements, customers can now mix-and-match the products below to adopt and get value from data analytics more quickly across a broad range of scenarios:- Cloud Dataprep for easy data preparation (new)
- BigQuery Transfer Services and Commercial Datasets for data integration (new)
- Cloud Dataflow and Cloud Pub/Sub for fast, easy data ingestion and processing
- BigQuery for fast interactive SQL analytics
- Cloud Dataproc for running Spark pipelines
- Cloud Datalab for data science workflow
- Cloud Machine Learning for large-scale machine learning
- Partner solutions from a rich and growing ecosystem



