A closer look at the HANA ecosystem on Google Cloud Platform
Babu Prasad Elumalai
Technical Lead, SAP on GCP
Since we announced our partnership with SAP in early 2017, we’ve rapidly expanded our support for SAP HANA, SAP’s in-memory, column-oriented, relational database management system. From the beginning, we knew we’d need to build tools that integrate SAP HANA with Google Cloud Platform (GCP) that make it faster and easier for developers and administrators to take advantage of the platform.
In this blog post, we’ll walk you through the evolution of SAP HANA on GCP and take a deeper look at the ecosystem we’ve built to support our customers.
The evolution of SAP HANA on GCP
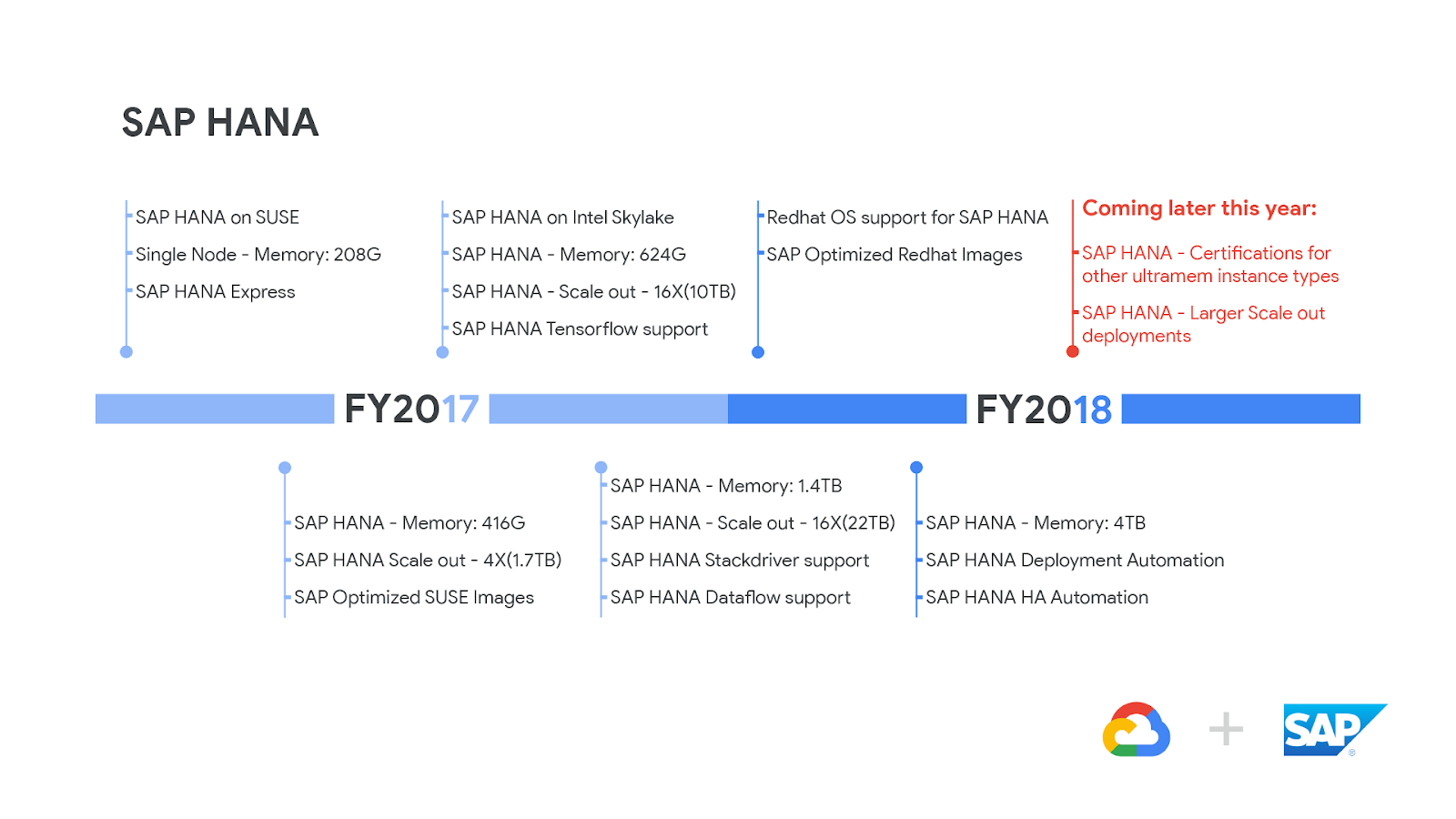
For many enterprise customers running SAP HANA databases, instances with large amounts of memory are essential. That’s why we’ve been working to make virtual machines with larger memory configurations available for SAP HANA workloads.
Our initial work with SAP on the certification process for SAP HANA began in early 2017. In that 15 month period, we’ve rapidly evolved from instances with 208GB memory to 4TB memory. This has allowed us to support larger single-node SAP HANA installations of up to 4TB.
Smart Data Access — Google BigQuery
Google BigQuery, our serverless data warehouse, enables low cost, high performance analytics at petabyte scale. We’ve worked with SAP to natively integrate SAP HANA with BigQuery through smart data access which allows you to extend SAP HANA’s capabilities and query data stored within BigQuery by means of virtual tables. This support has been available since SAP HANA 2.0 SPS 03, and you can try it out by following this step-by-step codelabs tutorial.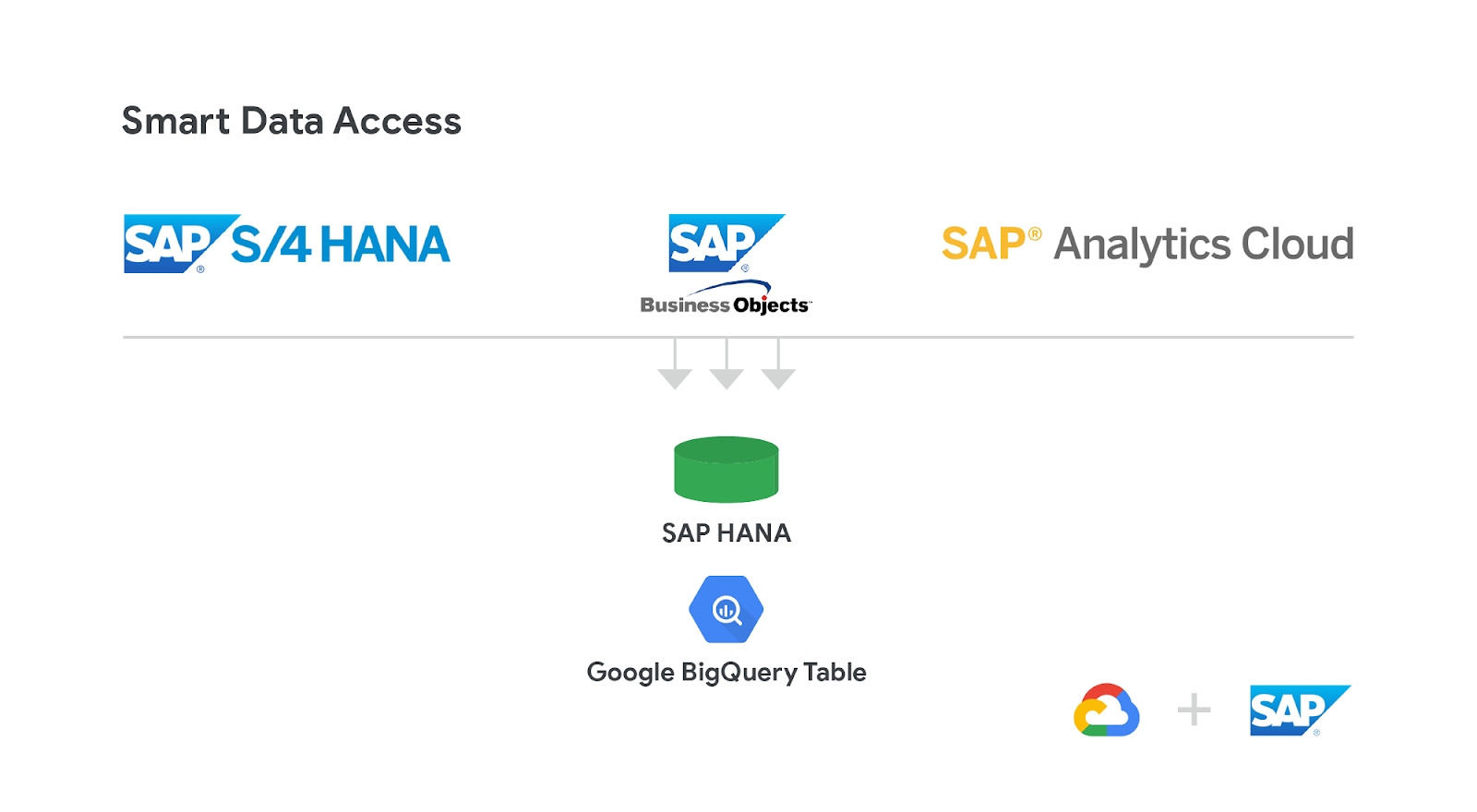
Fully automated deployment of SAP HANA
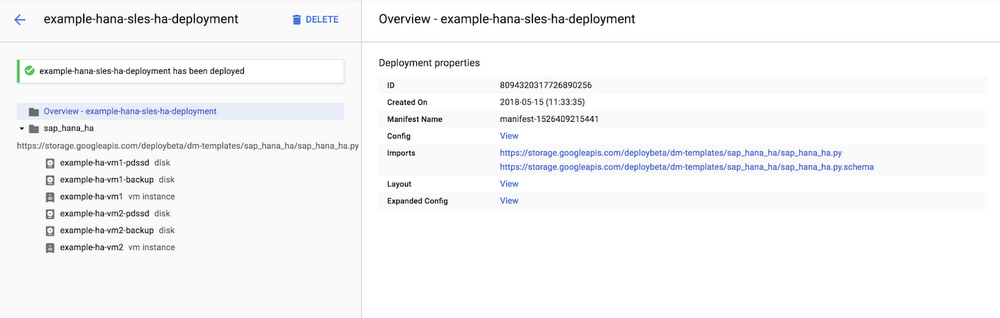
In many cases, the manual deployment process can be time consuming, error prone and cumbersome. It’s very important to reduce or eliminate the margin of error and make the deployment conform to SAP’s best practices and standards.To address this, we’ve launched deployment templates that fully automate the deployment of single node and scale-out SAP HANA configurations on GCP. In addition, we’ve also launched a new deployment automation template that creates a high availability SAP HANA configuration with automatic failover.
With these templates, you have access to fully configured, ready-to-go SAP HANA environments in a matter of minutes. You can also see the resources you created, and a complete catalog of all your deployments, in one location through the GCP console. We’ve also made the deployment process fully visible by providing deployment logs through Google Stackdriver.
Monitoring SAP HANA with Stackdriver
Visibility into what’s happening inside your SAP HANA database can help you identify factors impacting your database, and prepare accordingly. For example, a time series view of how resource utilization or latency within the SAP HANA database changes over time can help administrators plan in advance, and in many cases successfully troubleshoot issues.Stackdriver provides monitoring, logging, and diagnostics to better understand the health, performance, and availability of cloud-powered applications. Stackdriver’s integration with SAP HANA helps administrators monitor their SAP HANA databases, notifying and alerting them so they can proactively fix issues.
More information on this integration is available in our documentation.
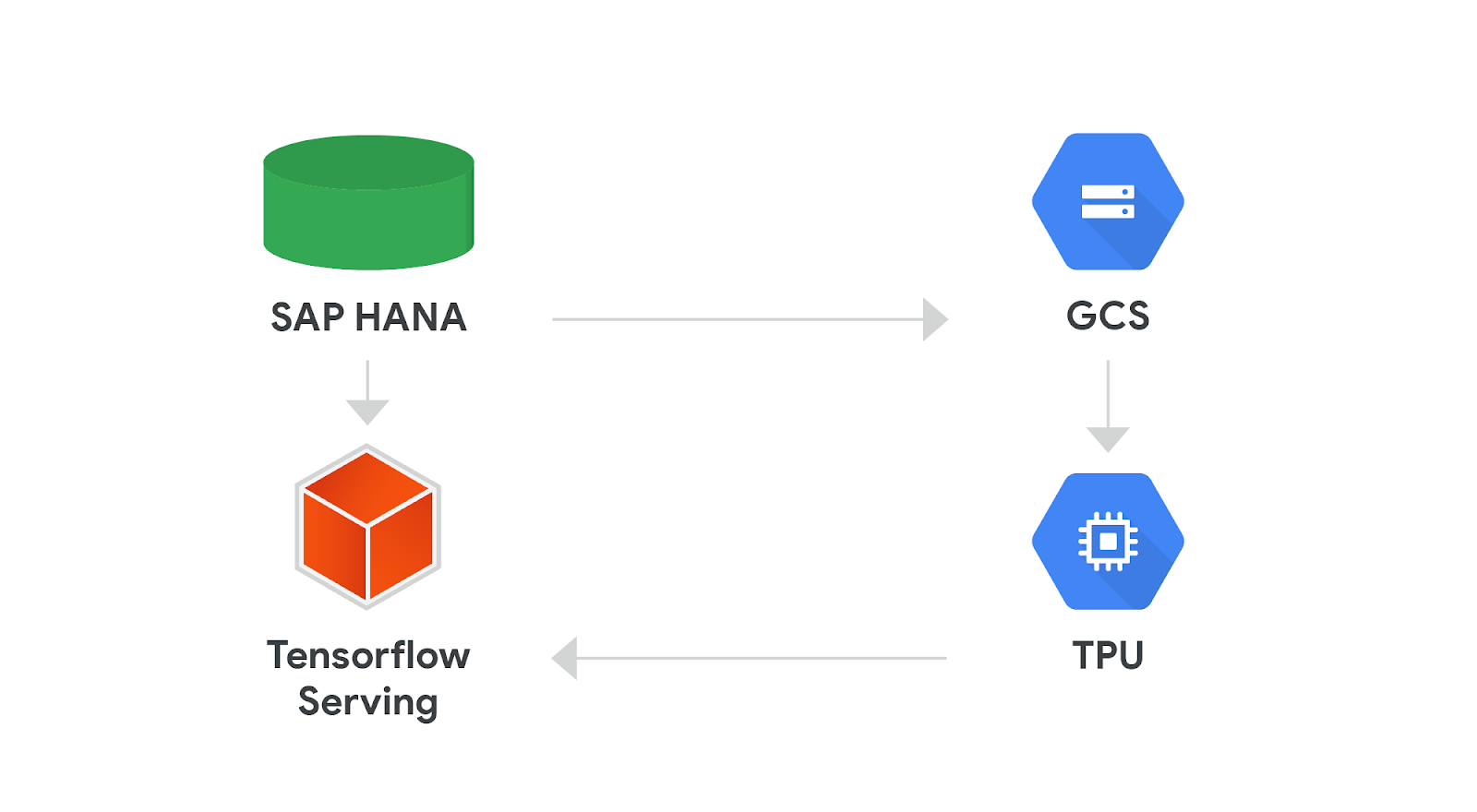
TensorFlow support in SAP HANA
SAP has offered support for TensorFlow Serving beginning with SAP HANA 2.0. This lets you directly build inference into SAP HANA through custom machine learning models hosted in TensorFlow serving applications running on Google Compute Engine.You can easily build a continuous training pipeline by exporting data in your SAP HANA database to Google Cloud Storage and then using Cloud TPUs to train deep learning models. These models can then be hosted with TensorFlow Serving to be used for inference within SAP HANA.