Experimenting with BigQuery data compression
David Cueva Tello
Cloud Solutions Architect
Rubén Fernández
Customer Engineer, Data Analytics
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try nowWith the introduction of BigQuery’s physical storage billing model, BigQuery users now have more control over their storage costs, unlocking potential savings, especially for large deployments. But as we showed in a previous blog post, opting for this model can yield different size reductions for different data sets. You might be wondering why the range of estimated byte reduction is so broad? One of the keys is compression ratios. In this blog post, we run some experiments to illustrate different factors that influence this compression ratio variance.
Under the hood, BigQuery stores data in Capacitor, a columnar-oriented format similar to Apache Parquet. This format provides storage efficiency by encoding similar values within a column. The underlying persistence layer is provided by Colossus, Google’s distributed file system that automatically encrypts, replicates and distributes data across different Google Cloud zones for increased availability and durability.
Building heavily on the research presented in "Integrating Compression and Execution in Column-Oriented Database Systems," Capacitor employs variations of techniques such as run-length encoding (RLE), dictionary encoding, bit-vector encoding, etc., to reduce the total size of the data stored while still optimizing for read and write performance. The compression efficiency of these techniques varies based on your type of data, your data values and how they’re distributed in a table, which explains the different compression ratios you will find across your BigQuery tables.
We ran some experiments with different real-world datasets to observe the impact of different factors in BigQuery’s table compression ratio. All the datasets we used for the experiments are publicly available, so you can easily reproduce the results. We also provide code snippets for each experiment so you can use them with your own datasets.
Keep in mind that when it comes to cost reduction, optimizing your query performance generally yields better cost savings than optimizing your storage compression. For example, clustering your data based on your query patterns to reduce the number of bytes scanned or slots consumed is probably a better cost optimization than clustering to get the best compression ratio.
What’s the compression ratio of a BigQuery table?
The compression ratio of a BigQuery table is its total compressed size divided by its total uncompressed size. We obtain these two values from the TABLE_STORAGE view in BigQuery’s INFORMATION_SCHEMA. By using total_physical_bytes, the ratio considers active (< 90d), long-term (> 90d), and time travel (deleted or changed data) bytes. To follow along, make sure your user has the required role to query this table.
In each experiment we choose one table from the dataset as the benchmark, we apply some transformations to get a modified table, and then observe if its compression ratio increases.
To make it easier to compare, we also calculate a percentage difference between the benchmark and modified compressed ratios as:
percentage_difference = (modified_table_compression_ratio / benchmark_table_compression_ratio) - 1
For example, a 10% difference means that the compressed modified table is 10% smaller than the compressed benchmark table. A negative difference means that the compressed modified table actually increased in size.
Record reordering experiments
The first experiment tests the impact of record reordering in the final compression ratio. Intuitively, reordering records should place similar values together in each column, therefore allowing Capacitor to make longer RLE spans. We evaluate two methods: manually pre-sorting rows, and using clustering.
Let's start with pre-sorting rows. Capacitor itself reorders rows to improve compression rates, but finding the optimal sorting strategy automatically is a very computationally-intensive task, so Capacitor uses best-effort heuristics. In contrast, you as a subject matter expert for your dataset may know which columns are prone to repetition, and may be able to sort them before ingesting them into BigQuery in a more efficient way.
However loading data into BigQuery runs in a distributed fashion behind the scenes, therefore the data may be shuffled across the workers performing the load, which could render any pre-sorting of data much less effective.
We evaluated how pre-sorting the records before ingesting into BigQuery affected the final compression numbers.
We used the New York City Taxi Trips, which includes trip records from all taxi trips completed in New York City, USA in the years since 2009. We built the benchmark table 'taxi' with the following query:
The resulting table had 192,092,698 rows with the following schema:
location_id INTEGER NULLABLE pickup_datetime DATETIME NULLABLE zone STRING NULLABLE
We measured the default compression ratio of the 'taxi' table in BigQuery (marked as “benchmark”) and compared it with the ratios of new copies of the same table, where the data has been sorted by each column or by all columns at once. This script is an example:
The results are as follows:

The benchmark (default) compression ratio is 6.69 to 1. Pre-sorting data in this table has almost no impact when sorting by location ID or zone, but sorting on pickup date time improves the compression ratio by about 74%. This shows that the gains of improving encoding are greater for the columns with “longer” data types — timestamps are larger than integers or short strings, and so improving the encoding on the timestamp fields will “free up” more space than doing so over the smaller data types as explained in this blog.
The compression gain when pre-sorting all columns was the highest with a 185.20% increase in the ratio, producing a 19 to 1 compressed table versus the original 6.69 to 1.
We invite you to run similar experiments on your data to determine if pre-sorting has a positive effect for your specific case. However, please keep in mind that Capacitor performs its own record reordering which in many cases could be sufficient, and could make pre-ordering unnecessary.
As a second part of this experiment, we compared the compression ratios of the original tables versus the ratios on new tables that were clustered by different columns. This is a sample script:
The results are as follows:

We see again the highest compression gains when clustering by a timestamp field vs. the integers or short strings.
In this section we experimented with pre-sorting and clustering tables. Although the highest compression ratio in this particular scenario was achieved via pre-sorting on all fields, we strongly recommend using clustering as a superior cost optimization method over pre-sorting, because gains using the latter might get diluted by Capacitor's own record reordering and by data shuffling across BigQuery load workers, but most importantly, because of clustering’s ability to reduce the amount of data scanned when querying. Clustering is a native way of defining a column sort order, which in most cases yields higher savings through the improvement of query performance and reduced query costs.
Dictionary experiments
In this second group of experiments, we explored the impact of having pre-standardized and clean values to minimize the number of different entries that Capacitor needs to encode in dictionaries and to provide longer encoding runs.
The publicly available dataset for this test is Google Trends. The dataset includes the Top 25 Stories and Top 25 rising queries from Google Search, with a new set of top terms appended every day. The constantly updating nature of this data set means that if you're following along by running the queries, your results may vary.
We used the whole table international_top_terms as a benchmark. We refer to this table simply as 'trend' in the results. This table includes two columns of interest for our dictionary experiments: country_name and term.
The first column for the experiment is country_name, which as its name implies, stores values from a small enumeration of country names. We created a table 'trend_no_enum', where we replaced 10% of the country names with their corresponding country code. This emulates a scenario where most upstream systems correctly use the country name enumeration, but a few "legacy" systems still use the country code when writing data.
We measured the compression ratios of the original table and of the 'trend_no_enum' table that contains the 10% replacement of country codes instead of names, causing the 'country_name' column to have double the number of distinct values.

The overall compression of the table went down by 4.89%. This seemingly small percentage hides the true effect on the single column that was modified because all the other columns in the table, which take up the bulk of the space, were left unchanged. To observe the effect on just the modified column, we extracted it alone into a table and performed the same change:

As expected, after the change the column occupies a larger compressed space than before. Therefore, the more columns use values from well-defined and minimal enums, the better the compression for the whole table.
The second column for this experiment is the 'term' column, which contains free-text input from Google users. The Google Trends dataset has already been cleansed from typos, so we’ll introduce artificial "typos" on 10% of the entries to mimic a non-cleansed dataset:
The number of rows (199,351,041) is unchanged, but the number of distinct values in the `term` column was 15,821 before the change and 31,856 after. Let's compare the compression ratios:

Similar to the 'country_name' enum result, the compression of the table was 6.71% lower after the change. Let's observe the impact of the change when isolating the 'term' column:
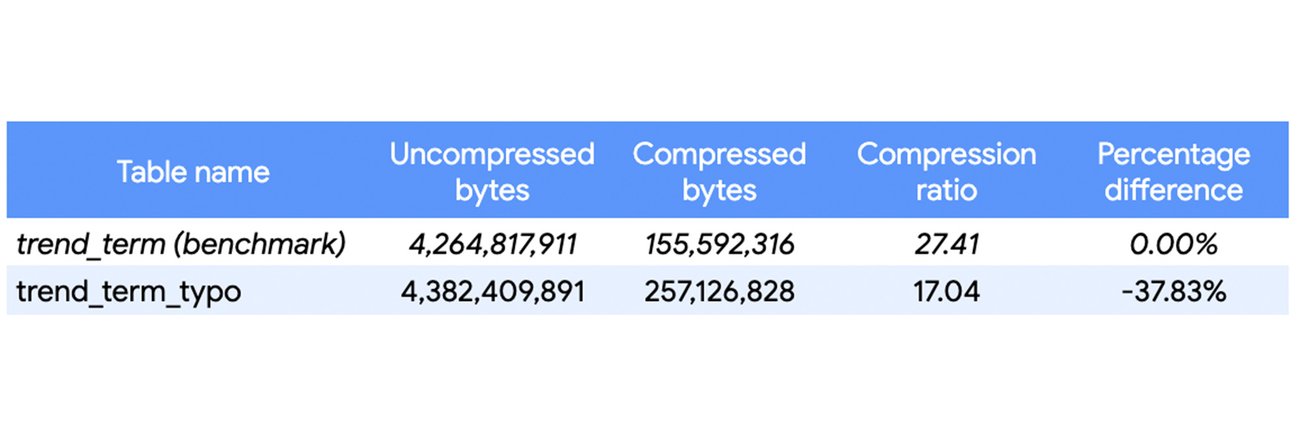
The column by itself shows that the introduced typos cause more than one third decrease in compression, which is in line with the notion of Capacitor compression working best when there are less distinct entries in a column.
String-sorting experiments
In this third group of experiments, we evaluated the impact of sorting substrings inside of long string types to help Capacitor find repeated values closer together so they can be encoded, possibly achieving a more compact representation of the data.
We used the BREATHE BioMedical Literature Dataset, a large-scale biomedical database that contains entries from 10 major repositories of biomedical research. We chose the 'jama' (Journal of the American Medical Association) table for its representative size and because it has a 'keywords' column that is well suited for sorting experiments: this column contains values separated by a semi-colon, such as:
myeloproliferative disease; thrombocythemia, hemorrhagic; polycythemia vera; hyperplasia; thrombosis; myelofibrosis, idiopathic, chronic;
To test the impact of intra-string sorting, we sort the keywords alphabetically for each record, so that similar or duplicate keywords are closer together. First we create a user-defined function (UDF) to sort strings:
Second, we create a table with sorted 'keywords' by calling the sort() function:
We also tested storing the keywords in a BigQuery repeated field instead of a single string. For this, we use two UDFs, similar to sort(), but they return an array of strings:
We create the tables 'jama_repeated' and 'jama_repeated_sorted' with the keywords attribute defined as an ARRAY <STRING>. The values for the attribute are the output of the two previous functions. Here is the creation of the 'jama_repeated_sorted' table:
This table show the comparison between the unmodified 'jama' table as a benchmark and the three recently created tables:

The increase in compression achieved by repeated field instead of string type is about 1.50%, while the difference by sorting the keywords both within a string or within the repeated field is negligible. These numbers use the whole table, where the rest of the columns remain unchanged. Therefore it is worth observing the effect in the keywords column by itself.

It’s easier to observe the difference in compression percentage with the column in isolation. Using a repeated field gives about twice better compression for the column, but simply sorting the values within the string did not yield a significant improvement. The reason may be because the strings themselves are relatively small, or because repetition is not very common.
We run these same tests with a different dataset to corroborate the results. In this case, we used the US Food and Drug Administration adverse event reports dataset, which includes 91,776 records detailing adverse reactions or symptoms experienced by people in the US when consuming different food products. The `reactions` column of the `food_events` table is a comma-separated list of adverse reactions or symptoms experienced by the individual involved. For example:
CHILLS, FEELING HOT, DIZZINESS, FEELING OF BODY TEMPERATURE CHANGE, PRURITUS, HEADACHE, BURNING SENSATION, RASH, VOMITING, FLUSHING.
Similar to the previous experiment, we sorted the keywords alphabetically for each record, so that similar or duplicated keywords are closer together, and also created a table with a repeated field for each reaction instead of using a single comma-separated string.

Similarly to the previous dataset, sorting the column sub-strings has a very small impact on compression. Splitting the value into a BigQuery repeated field has a larger, although modest impact.
Comparing the reactions column in isolation provides clearer results:

The results are consistent with the JAMA dataset. However, in both cases the column values have relatively small sequences of values, so we ran one final test with a dataset with a significantly larger set of values.
For this third iteration, we used the BREATHE BioMedical Literature Dataset again, but focusing on a different table, 'springer', which stores information about 918,845 articles that appeared in the German scientific journal Springer.
The 'abstract' column is a free-text column that provides an opportunity to test how compression would perform when similar words are grouped close together in a larger string. In real life, you will not be sorting words of unstructured text, but rather terms, parameters, keywords, URLs, and other order-independent sequences. However, this exercise acts as a proxy when these sequences are of a considerable size.
We applied a very similar UDF as before, and focused only in the `abstract` column in isolation:

The results show that even with a much larger string, the compression improvement achieved by sorting the substrings of a larger string is relatively low for this table.
Capacitor compared to other formats
In this fourth and final round of experiments, we compared the compression ratios achieved by Capacitor with other popular open-source file formats, namely: Parquet, Avro, CSV, and ORC, using different compression algorithms. We used the same NYC Taxi trips 'taxi' table from the first experiment, and we exported it to Cloud Storage in the mentioned file formats. We then used file sizes to calculate compression ratios and differences.
To export each file format we used the following command:
For FORMAT we used Avro, Parquet, CSV, and ORC, and for COMPRESSION we used SNAPPY, DEFLATE, GZIP, and ZSTD (when available)
BigQuery currently doesn’t natively support exports to ORC. To generate these files, we used pySpark and the Spark BigQuery Connector to read the BigQuery table into a DataFrame and then write it to a Cloud Storage bucket in ORC. Here’s a snippet of the code used:
To get the sizes we used the following command:
Note: the 'taxi' table has a 'DATETIME'` field, which in Avro exports is stored as a string. Please take this into account when comparing across formats.

We can see that for this table, without any sorting or additional modifications, BigQuery and Capacitor offer a compression of 6.69 to 1, which is higher than what the other formats achieve. Please note we’re not claiming here that Capacitor compresses data better than Parquet, Avro, or ORC for any table structure, just that this test is indicative of this particular table and data structures.
We repeated the same test using the improvements demonstrated in the first experiment as a baseline, through sorting by all columns before ingesting:

In this particular scenario, ORC with ZSTD resulted in a slightly higher compression ratio than Capacitor, while all of the other tested formats and compression algorithms produced significantly lower ratios.
Finally, we use clustering, in this case by the 'pickup_datetime' timestamp column:

We can see that pre-sorting or clustering data has a positive impact in the compression ratios across all formats and compression algorithms. For example, Parquet with GZIP compression goes from a 4.55 to 1 ratio in the original table to a 10.68 to 1 when clustering by the timestamp field. Similarly, ORC with ZSTD compression saw their ratio increase from almost 5:1 to over 19:1 when pre-sorting the table by all fields.
Across the board, we see Capacitor’s compression significantly outperform other formats. Among other optimization techniques, BigQuery automatically re-sorts the data after ingestion to improve compressibility. This is one of the key reasons why, in most scenarios, Capacitor and BigQuery provide better compression rates than other formats.
Conclusion
The BigQuery physical storage billing model allows you to have more control over your storage costs. Pre-processing your data before ingestion may help Capacitor, the columnar-oriented format used by BigQuery, get higher compression ratios. These are some guidelines for you to better understand your current compression ratios and to experiment with:
-
Pre-sorting and clustering some columns before ingestion may yield better compression ratios than ingesting unsorted data. We recommend native clustering over pre-sorting because compression gains obtained by manual pre-sorting may get diluted by Capacitor's own reordering and by data shuffling across BigQuery load workers. In addition, clustering is likely to be superior in terms of query performance and reduced query costs.
-
Cleansing your data and standardizing it into well-defined enums whenever possible are techniques that may help Capacitor better encode similar values and thus achieve better compression ratios.
-
Another option that may increase the compression ratio is the use of repeated fields instead of delimiter-separated-strings.
-
All these techniques may have better results when applied to columns with large values.
-
BigQuery natively achieves better compression ratios than other file formats in most scenarios, resulting in more compact data volumes compared to Cloud Storage file exports.
But don’t take our word for it. It’s very important for you to verify that the cost optimization gains obtained by applying these changes are significant enough for your use case, and contrast them against the costs of defining, implementing, running and maintaining any pre-processing or refactoring.
Finally, we want to reiterate that optimizing your query performance will in general yield better cost savings than optimizing your storage compression, and that the internal implementation of Capacitor is in constant evolution, so the current behavior observed in the experiments may change.

