BigQuery under the hood
Tino Tereshko
Product Manager, Google BigQuery
Jordan Tigani
Director of Product Management, BigQuery
In our previous blog post, we discussed how fast BigQuery really is, and how easy it is for BigQuery users to leverage vast resources. Today we’ll dive deeper and discuss what it takes to build something this fast. We’ll also talk about what BigQuery hides under the hood, leveraging technologies like Borg, Colossus, Jupiter and Dremel.
We previously ran a back-of-the-napkin estimate on what it would take to run a typical large query elsewhere in under 30 seconds:
- 330 100 MB/sec hard drives
- 3,300 Cores
- A 330 Gigabit network
- Even if you have the data on 300 disks, the data will need to be perfectly spaced among those disks, you need to be able to read at full speed from all of those disks at once, and each disk will need to be otherwise completely idle. And be sure to account for several factors of replication for redundancy.
- You would need to coordinate that many CPUs to start at the same time and get the same amount of work done. Assuming ~100 32-processor machines, one of the servers will fail every day on average, which will take all 3,300 CPUs offline, so you’ll need extra coordination to handle these failures without slowing down, including deploying additional computing redundancy, preferably across multiple zones.
- To coordinate this much networking throughput so quickly, you’d need to make sure that networking throughput is evenly distributed across each instance, and you’ll likely worry about locality, as well as limits of total bisectional bandwidth.
The answer is very simple — BigQuery has this much hardware (and much much more) available to devote to your queries for seconds at a time. BigQuery is powered by multiple data centers, each with hundreds of thousands of cores, dozens of petabytes in storage capacity, and terabytes in networking bandwidth. The numbers above — 300 disks, 3000 cores, and 300 Gigabits of switching capacity — are small. Google can give you that much horsepower for 30 seconds because it has orders of magnitude more.
BigQuery’s vast size gives users great query performance. Perhaps just as important is the multitenancy benefit — it is nearly impossible to starve BigQuery out of resources, and as our customers’ concurrency demands grow, BigQuery scales seamlessly with those demands. There is no such thing as one bad query taking down the entire service.
Dremel: The Execution Engine
It takes more than just a lot of hardware to make your queries run fast. BigQuery requests are powered by the Dremel query engine (paper on Dremel published in 2010), which orchestrates your query by breaking it up into pieces and re-assembling the results.
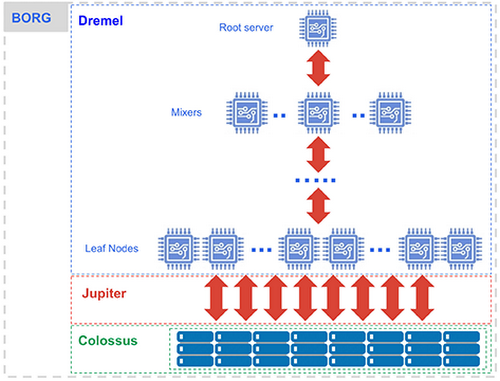
Dremel turns your SQL query into an execution tree. The leaves of the tree it calls ‘slots’, and do the heavy lifting of reading the data from Colossus and doing any computation necessary. In the example from the last post, the slots are reading 100 Billion rows and doing a regular expression check on each one.
The branches of the tree are ‘mixers’, which perform the aggregation. In between is ‘shuffle’, which takes advantage of Google’s Jupiter network to move data extremely rapidly from one place to another. The mixers and slots are all run by Borg, which doles out hardware resources.
Dremel dynamically apportions slots to queries on an as needed basis, maintaining fairness amongst multiple users who are all querying at once. A single user can get thousands of slots to run their queries.
Dremel is widely used at Google — from search to ads, from youtube to gmail — so there’s great emphasis on continuously making Dremel better. BigQuery users get the benefit of continuous improvements in performance, durability, efficiency and scalability, without downtime and upgrades associated with traditional technologies.
Colossus: Distributed Storage
BigQuery relies on Colossus, Google’s latest generation distributed file system. Each Google datacenter has its own Colossus cluster, and each Colossus cluster has enough disks to give every BigQuery user thousands of dedicated disks at a time. Colossus also handles replication, recovery (when disks crash) and distributed management (so there is no single point of failure). Colossus is fast enough to allow BigQuery to provide similar performance to many in-memory databases, but leveraging much cheaper yet highly parallelized, scalable, durable and performant infrastructure.
BigQuery leverages the ColumnIO columnar storage format and compression algorithm to store data in Colossus in the most optimal way for reading large amounts of structured data.Colossus allows BigQuery users to scale to dozens of Petabytes in storage seamlessly, without paying the penalty of attaching much more expensive compute resources — typical with most traditional databases.
Borg: Compute
To give you thousands of CPU cores dedicated to processing your task, BigQuery takes advantage of Borg, Google’s large-scale cluster management system. Borg clusters run on dozens of thousands of machines and hundreds of thousands of cores, so your query which used 3300 CPUs only used a fraction of the capacity reserved for BigQuery, and BigQuery’s capacity is only a fraction of the capacity of a Borg cluster. Borg assigns server resources to jobs; the job in this case is the Dremel cluster.
Machines crash, power supplies fail, network switches die, and a myriad of other problems can occur while running a large production datacenter. Borg routes around it, and the software layer is abstracted. At Google-scale, thousands of servers will fail every single day, and Borg protects us from these failures. Someone unplugs a rack in the datacenter in the middle of running your query, and you’ll never notice the difference.
Jupiter: The Network
Besides obvious needs for resource coordination and compute resources, Big Data workloads are often throttled by networking throughput. Google’s Jupiter network can deliver 1 Petabit/sec of total bisection bandwidth, allowing us to efficiently and quickly distribute large workloads.
Jupiter networking infrastructure might be the single biggest differentiator in Google Cloud Platform. It provides enough bandwidth to allow 100,000 machines to communicate with any other machine at 10 Gbs. The networking bandwidth needed to run our query would use less than 0.1% of the total capacity of the system. This full-duplex bandwidth means that locality within the cluster is not important. If every machine can talk to every other machine at 10 Gbps, racks don’t matter.
Traditional approaches to separation of storage and compute include keeping data in an object store like Google Cloud Storage or AWS S3 and loading that data on-demand to VMs. This approach is often more efficient than co-tenant architectures like HDFS, but is subject to local VM and object storage throughput limits. Jupiter allows us to bypass this process entirely and read terabytes of data in seconds directly from storage, for every SQL query.
BigQuery: The Service
In the end, these low level infrastructure components are combined with several dozen high-level technologies, APIs, and services — like Bigtable, Spanner, and Stubby — to make one transparent and powerful analytics database — BigQuery.
The ultimate value of BigQuery is not in the fact that it gives you incredible computing scale, it’s that you are able to leverage this scale for your everyday SQL queries, without ever so much as thinking about software, virtual machines, networks and disks. BigQuery is truly a Serverless database, and BigQuery’s simplicity allows customers with dozens of Petabytes to have a nearly identical experience as its free tier customers.




