Anatomy of a BigQuery Query
Tino Tereshko
Product Manager, Google BigQuery
Jordan Tigani
Director of Product Management, BigQuery
Google BigQuery is a lightning-fast analytics database. Customers find BigQuery performance liberating, allowing them to experiment with enormous datasets without compromise. But how fast is BigQuery really? And what does it take to achieve BigQuery speeds? Let’s check out the publically-available bigquery-samples:wikipedia_benchmark, specifically the Wiki100B table. This table contains 100 billion rows and is about 7 Terabytes in size.
Let’s run a typical SQL query:
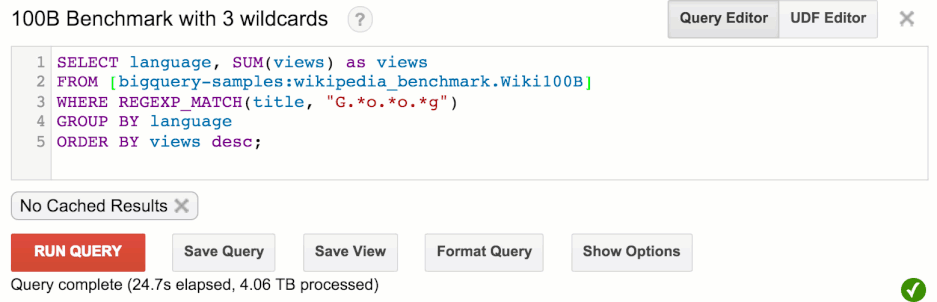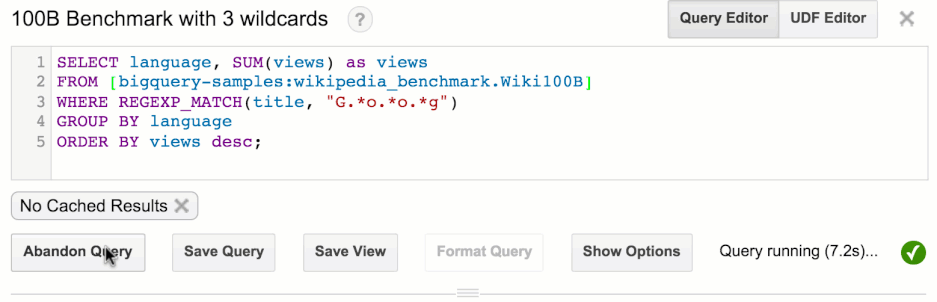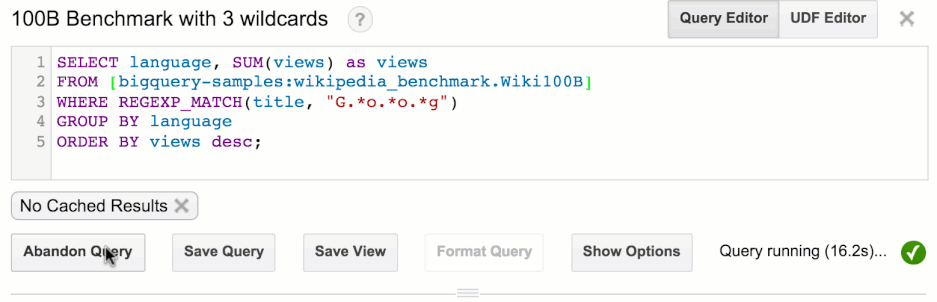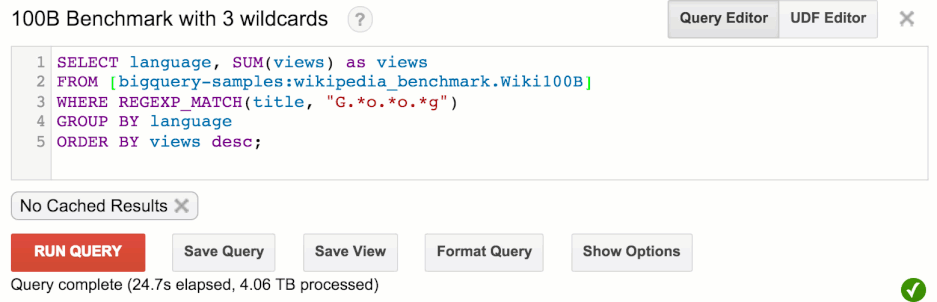
You can see that this query runs in under 30 seconds, but let’s round up to 30. It’s quite impressive, since to churn through this much data, BigQuery has had to:
- Read about 1TB of data, then uncompress it to 4TB (assuming ~4:1 compression)
- Execute 100 billion regular expressions with 3 wildcards each
- Distribute 1.25TB of data across the network (1TB compressed for initial read, and 0.25TB for the aggregation)
Let’s assume for a second that all distributed analytics engines take the same amount of resources to process a query and that queries are perfectly parallelizable. All else being equal, if one were to build a distributed cluster capable of executing this query this fast, one must deploy at the very least:
- About 330 100MB/sec dedicated hard-drives to read 1TB of data
- A 330 Gigabit network to shuffle the 1.25 TB of data
- 3,300 cores to uncompress 1TB of data and process 100 billion regular expressions at 1 μsec per
That’s a lot of resources! So it’s quite impressive that BigQuery lets you use all this stuff for just the few seconds required for your job to complete.
But what’s even more impressive is that we do not know this is happening — we simply press “Run Query” and BigQuery takes care of the rest automagically. BigQuery entirely hides the complexity of large-scale analytics technologies.
To reiterate, we simply created a Google Cloud project, enabled billing, and ran this SQL query in BigQuery. We didn’t have to deploy any software, any virtual machines, or any clusters. We didn’t have to define any indexes, keys, sort keys, or any similar database administration tasks.
This ability to easily leverage massive computational resources democratizes Big Data in the very same manner Gmail democratized email, introducing a Gigabyte of simple to consume storage and powerful search to the world instead of constantly micro-managing your 50MB inbox.
In this blog post we estimated how much CPU, networking, and disk is required to achieve BigQuery’s level of performance. We made a whole lot of assumptions, and arrived at what is most likely a purely theoretical low bar of required resources. In the next blog we will discuss the level of complexity associated with such scale in greater detail. Stay tuned!




