Easy access to stream analytics with SQL, real-time AI, and more
Evren Eryurek PhD
Director Product Management, Google Cloud
During times of challenge and uncertainty, businesses across the world must think creatively and do more with less in order to maintain reliable and effective systems for customers in need. In terms of data analytics, it’s important to find ways for bootstrapped engineering and ops teams working in unique circumstances to maintain necessary levels of productivity. Balancing the development of modern, high-value streaming pipelines with maintaining and optimizing cost-saving batch workflows is an important goal for a lot of teams. At Google Cloud, we’re launching new capabilities to help developers and ops teams easily access stream analytics.
Highlights across these launches include:
Streaming pipelines developed directly within the BigQuery web UI with general availability of Dataflow SQL
Dataflow integrations with AI Platform allow for simple development of advanced analytics use cases
Enhanced monitoring capabilities with observability dashboards
Built on the autoscaling infrastructure of Pub/Sub, Dataflow, and BigQuery, Google Cloud’s streaming platform provisions the resources that engineering and operations teams need to ingest, process, and analyze fluctuating volumes of real-time data to get real-time business insights. We are honored that The Forrester Wave™: Streaming Analytics, Q3 2019 report named Google Cloud a Leader in the space. These launches build on and strengthen the capabilities that drove that recognition.
What’s new in stream analytics
The development process for streaming and batch data pipelines is now even easier with these key launches across both Dataflow and Pub/Sub. You can get from idea to pipeline and management to iteration to fulfill customer needs efficiently.
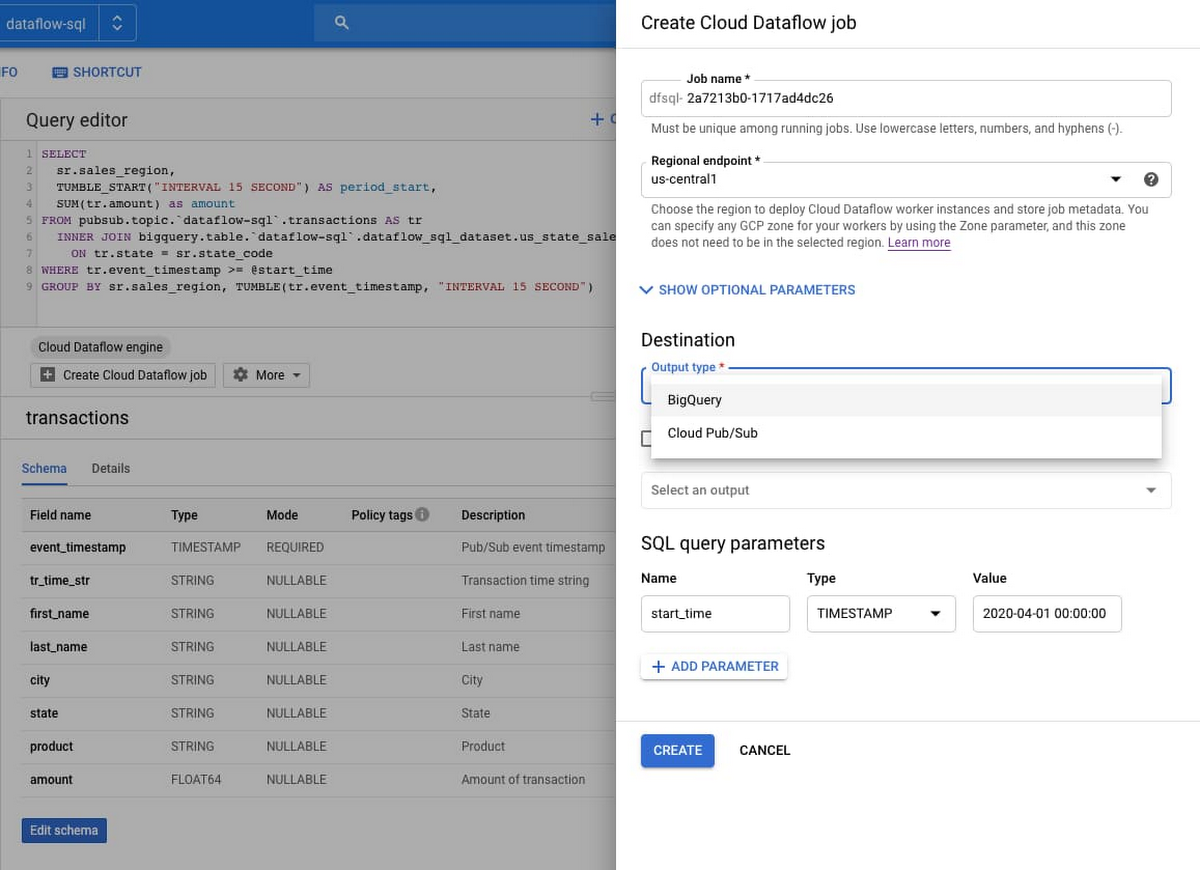
General availability of Dataflow SQL
Dataflow SQL lets data analysts and data engineers use their SQL skills to develop streaming Dataflow pipelines right from the BigQuery web UI. Your Dataflow SQL pipelines have full access to autoscaling, time-based windowing, a streaming engine, and parallel data processing. You can join streaming data from Pub/Sub with files in Cloud Storage or tables in BigQuery, write results into BigQuery or Pub/Sub, and build real-time dashboards using Google Sheets or other BI tools. There’s also a recently added command line interface to script your production jobs with full support of query parameters, and you can rely on the Data Catalog integration and a built-in schema editor for schema management.
Iterative pipeline development in Jupyter notebooks
With notebooks, developers can now iteratively build pipelines from the ground up with AI Platform Notebooks and deploy with the Dataflow runner. Author Apache Beam pipelines step by step by inspecting pipeline graphs in a read-eval-print-loop (REPL) workflow. Available through Google’s AI Platform, Notebooks allows you to write pipelines in an intuitive environment with the latest data science and machine learning frameworks so you can develop better customer experiences easily.
Share pipelines and scale with flex templates
Dataflow templates allow you to easily share your pipelines with team members and across your organization or take advantage of many Google-provided templates to implement simple but useful data processing tasks. With flex templates, you can create a template out of any Dataflow pipeline.
General availability of Pub/Sub dead letter topics
Operating reliable streaming pipelines and event-driven systems has gotten simpler with general availability of dead letter topics for Pub/Sub. A common problem in these systems is “dead letters,” or messages that cannot be processed by the subscriber application. A dead letter topic allows such messages to be put aside for offline examination and debugging so the rest of the messages can be processed without delays.
Optimize stream data processing with change data capture (CDC)
One way to optimize stream data processing is to focus on working only with data that has changed instead of all available data. This is where change data capture (CDC) comes in handy. The Dataflow team has developed a sample solution that lets you ingest a stream of changed data coming from any kind of MySQL database on versions 5.6 and above (self-managed, on-prem, etc.), and sync it to a dataset in BigQuery using Dataflow.
Integration with Cloud AI Platform
You can now take advantage of an easy integration to AI Platform APIs and access to libraries for implementation of advanced analytics use cases. AI Platform and Dataflow capabilities include video clip classification, image classification, natural text analysis, data loss prevention, and a number of other streaming prediction use cases.
Ease and speed shouldn’t come just to those building and launching data pipelines, but those managing and maintaining them as well. We’ve also enhanced the monitoring experience for Dataflow, aimed to further empower operations teams.
Reduce operations complexity with observability dashboards
Observability dashboards and Dataflow inline monitoring let you directly access job metrics to help with troubleshooting batch and streaming pipelines. You can access monitoring charts at both step- and worker-level visibility, and set alerts for conditions such as stale data and high system latency. Here’s a look at one example:
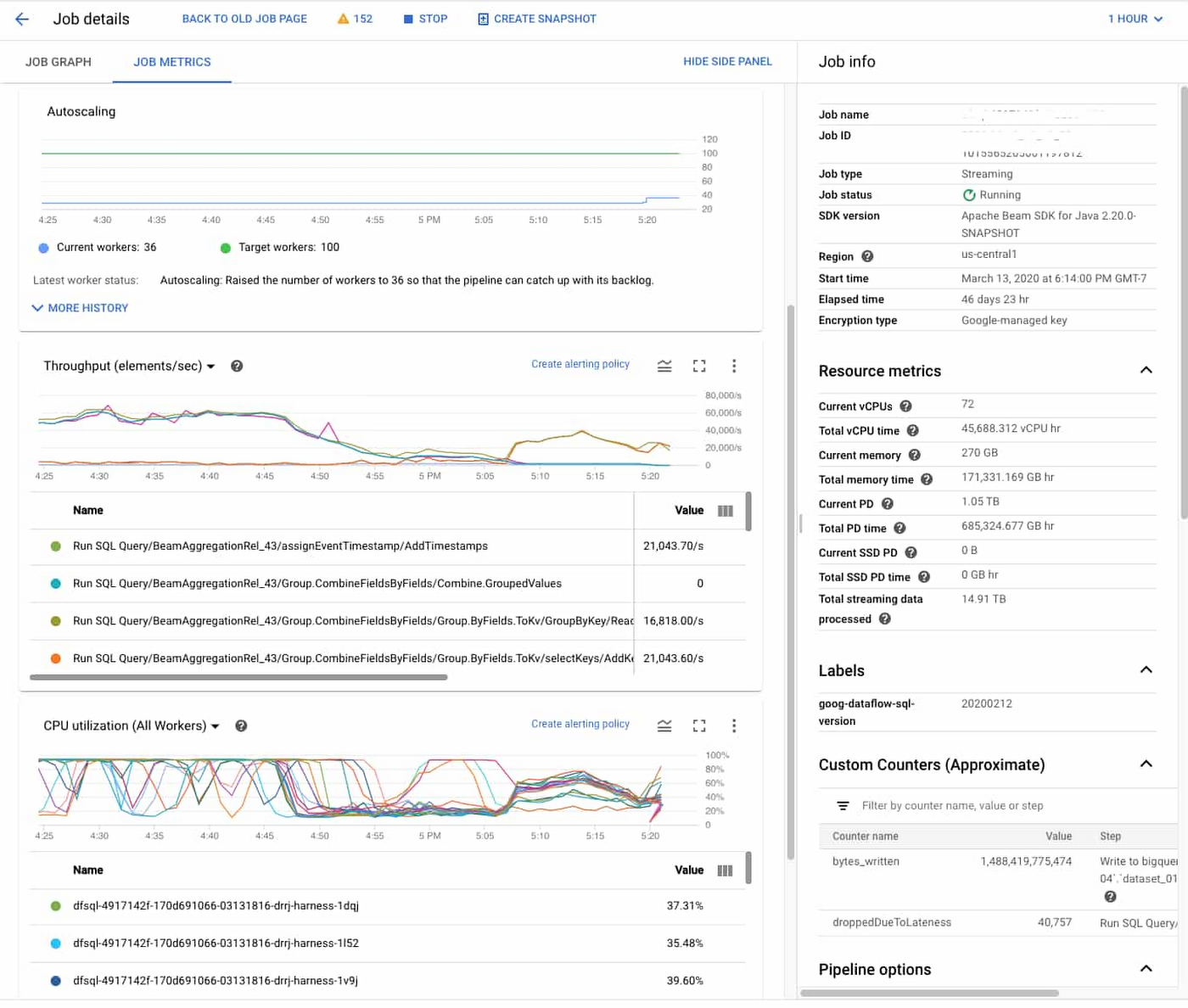
Getting started with stream analytics is now easier than ever. The first step to begin testing and experimenting is to move some data onto the platform. Take a look at the Pub/Sub Quickstart docs to get moving with real-time ingestion and messaging with Google Cloud.

