GKE: The new home for your batch platform
Ali Zaidi
Solutions Architect, Google Cloud
Maciek Różacki
Group Product Manager
Today’s post is the first in a series that will provide the reasons for why administrators and architects should build batch processing platforms on Google Kubernetes Engine (GKE).
Kubernetes has emerged as a leading container orchestration platform for deploying and managing containerized applications, speeding up the pace of innovation. This platform is not just limited to running microservices, but also provides a powerful framework for orchestrating batch workloads such as data processing jobs, training machine learning models, running scientific simulations, and other compute-intensive tasks. GKE is a managed Kubernetes solution that abstracts underlying infrastructure and accelerates time-to-value for users in a cost effective way.
A batch platform processes batch workloads, defined as Kubernetes Jobs, in the order they are received. The batch platform might incorporate a queue to apply your business case logic.
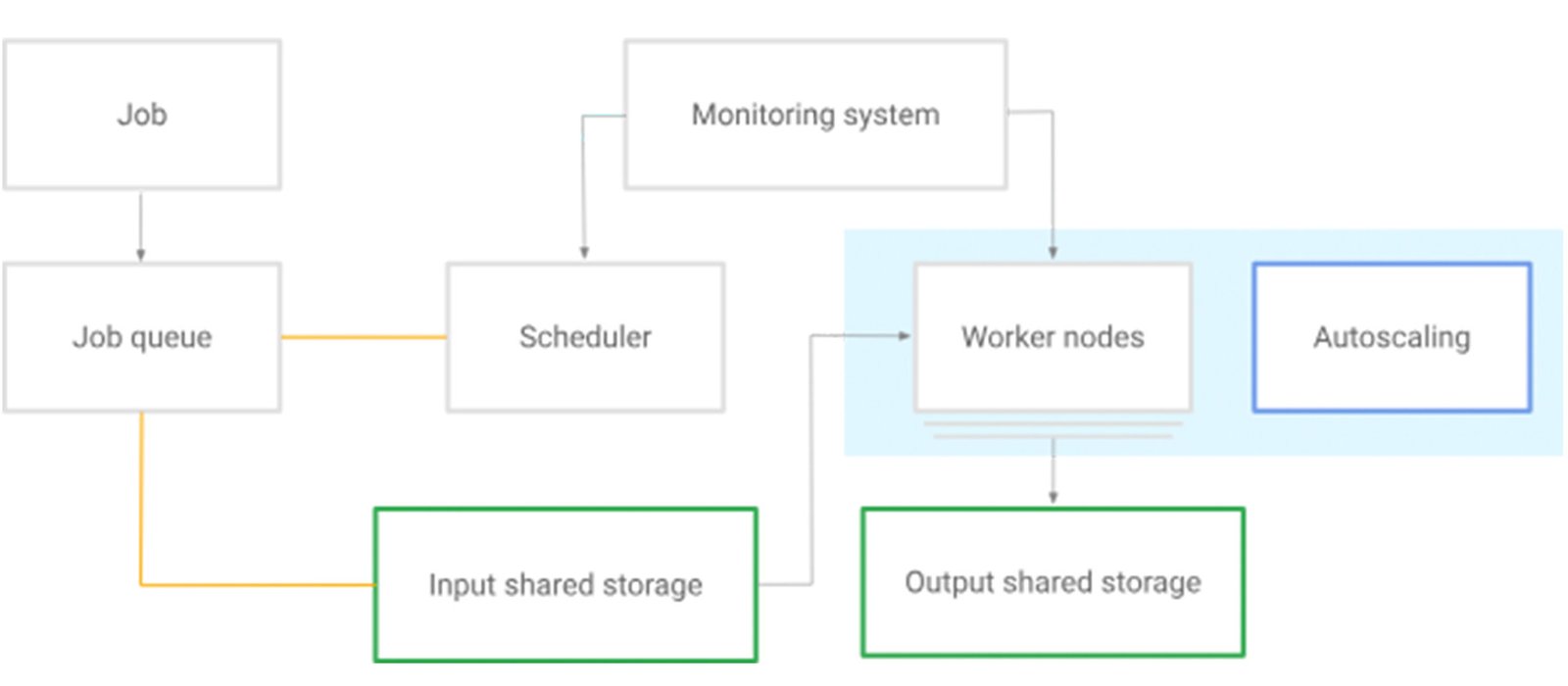
There are two key Kubernetes resources in a batch platform: Jobs and Pods. You can manage Jobs through the Kubernetes Job API. A Job creates one or more Pods and continues to retry execution of the Pods until a specified number of them successfully terminate. As Pods successfully complete, the Job tracks the successful completions. When a specified number of successful completions is reached, the Job, or the task, is considered complete.
GKE is a managed Kubernetes solution that simplifies the complexity of infrastructure and workload orchestration. Let’s take a deeper look at GKE capabilities that make it a compelling place to operate batch platforms.
Cluster architecture and available resources
A GKE environment consists of nodes, which are Compute Engine virtual machines (VMs), that are grouped together to form a cluster. GKE in Autopilot mode automatically manages your cluster configuration, including your nodes, scaling, security, and other preconfigured settings so you can focus on your workload. Autopilot clusters are highly-available by default.
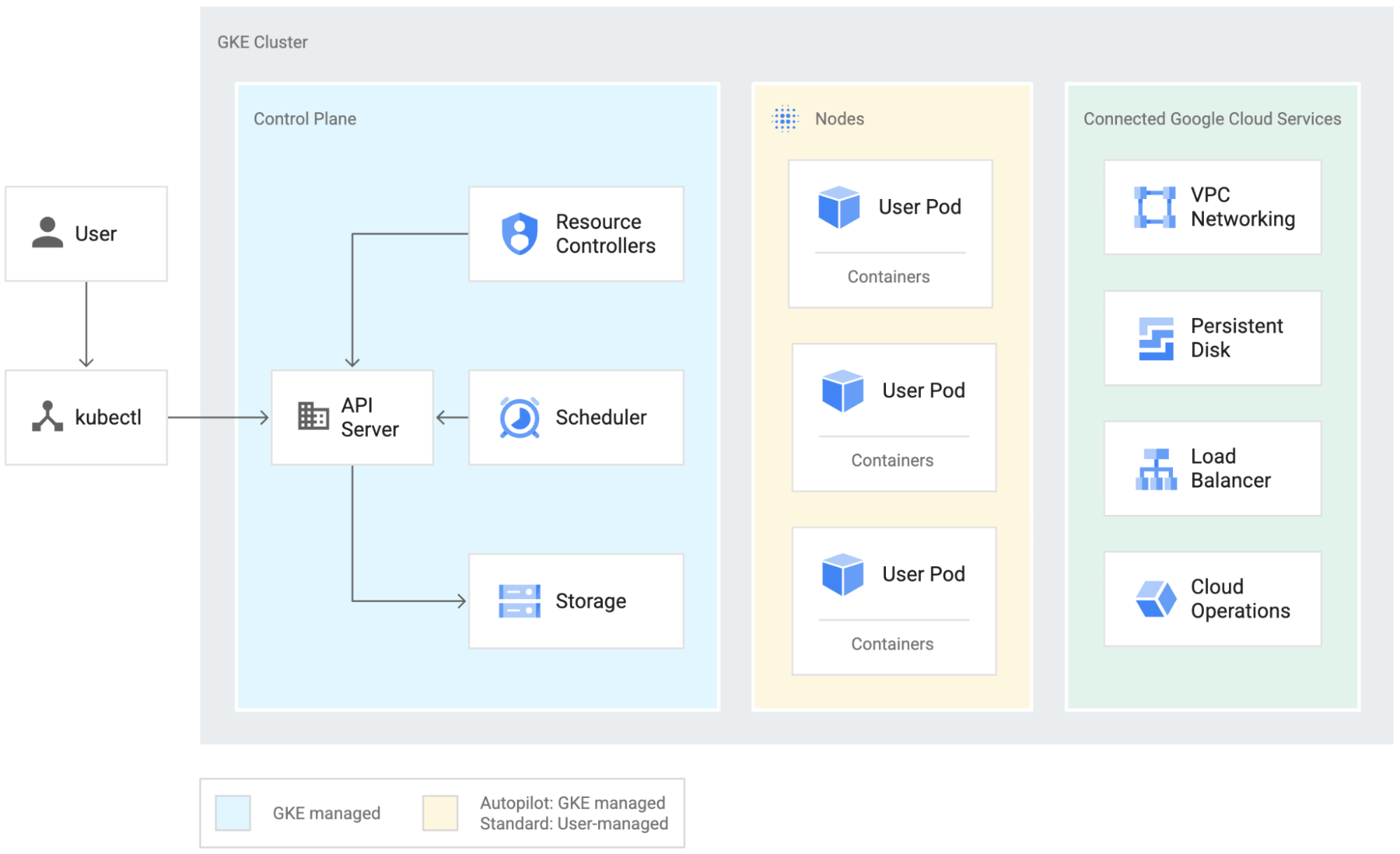
Google Cloud is continuously introducing new workload optimized VM series and shapes; please visit the machine families resource and comparison guide to review the options that are currently available for your workload.
Scalability
GKE is capable of hosting the largest Kubernetes clusters a managed provider currently can. 15,000 nodes per cluster (compared to 5,000 nodes for open-source Kubernetes) is a scale that is key to many batch use cases.
Customers like Bayer Crop Science take advantage of GKE scale to process around 15 billion genotypes per hour, and GKE was used by PGS to build an equivalent of one of the worlds largest supercomputers. GKE can create multiple node pools, each with distinct types/shapes and series of VMs to run workloads of various needs.
Multi-tenancy
GKE cluster multi-tenancy is an alternative to managing many single-tenant clusters and to manage access control. In this model, a multi-tenant cluster is shared by multiple users and/or workloads which are referred to as "tenants". GKE allows tenant isolation on a namespace basis; you can separate each tenant and their Kubernetes resources into their own namespaces. You can then use policies to enforce tenant isolation, restrict API access, set quotas to constrain resource usage, and to restrict what containers are allowed to do.
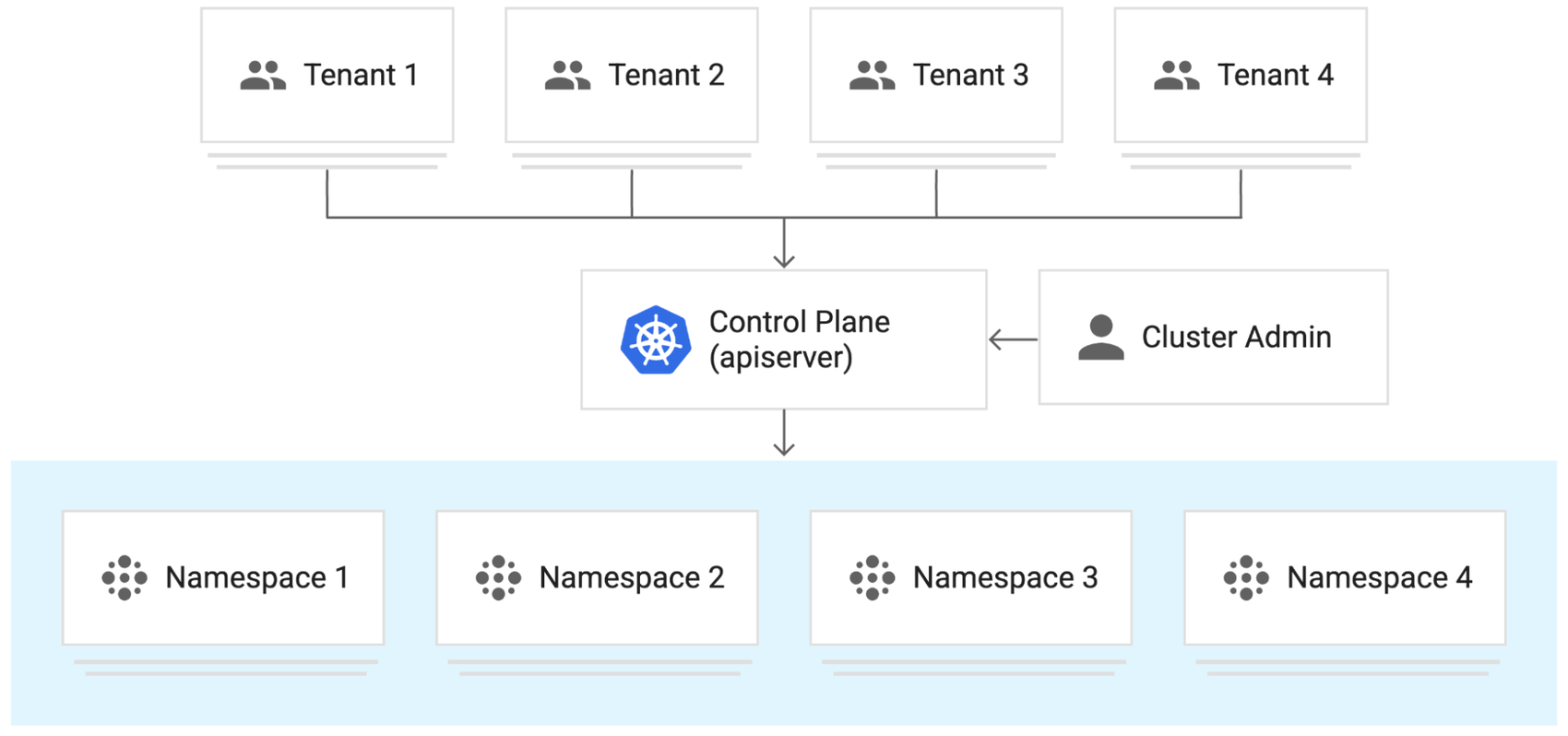
Queueing and ‘fair-sharing’
As an administrator, you can implement policies and configuration to share the underlying cluster resources in a fair way between tenants submitting workloads. You can decide what is fair in this context; you might want to assign resource quota limits per tenant proportional to their minimum workload requirements, to ensure there is room for all tenants’ workloads on the platform. Or you could queue incoming jobs when there are no available resources and process them in the order they were received.
Kueue is a Kubernetes-native job queueing system for batch, high performance computing, machine learning and similar applications in a Kubernetes cluster. To help with fair sharing of cluster resources between its tenants, Kueue manages quotas and how jobs consume them. Kueue decides when a job should wait, when a job should be admitted to start (as in pods can be created) and when a job should be preempted (as in active pods should be deleted). The diagram below shows the flow from a user submitting a Job, to Kueue admitting it with the appropriate nodeAffinity and the other parts of Kubernetes activating to process the workload.
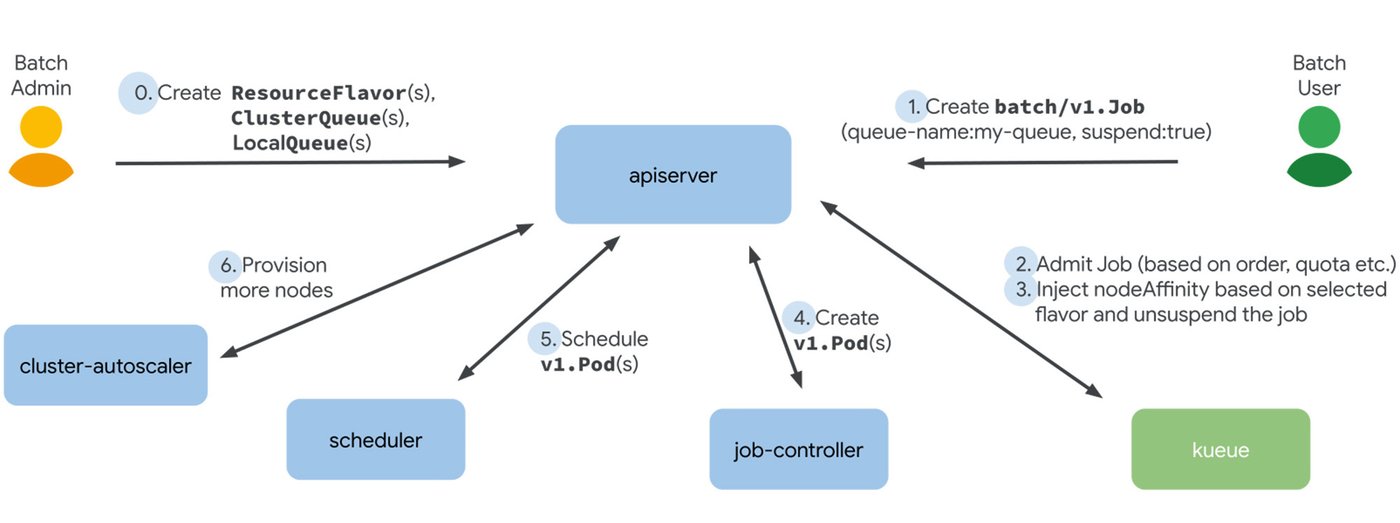
To help administrators configure batch processing behavior Kueue introduces concepts like ClusterQueue (a cluster-scoped object that governs a pool of resources such as CPU, memory, and hardware accelerators). ClusterQueues can be grouped in cohorts; ClusterQueues that belong to the same cohort can borrow unused quota from each other and this borrowing can be controlled using the ClusterQueue’s BorrowingLimit.
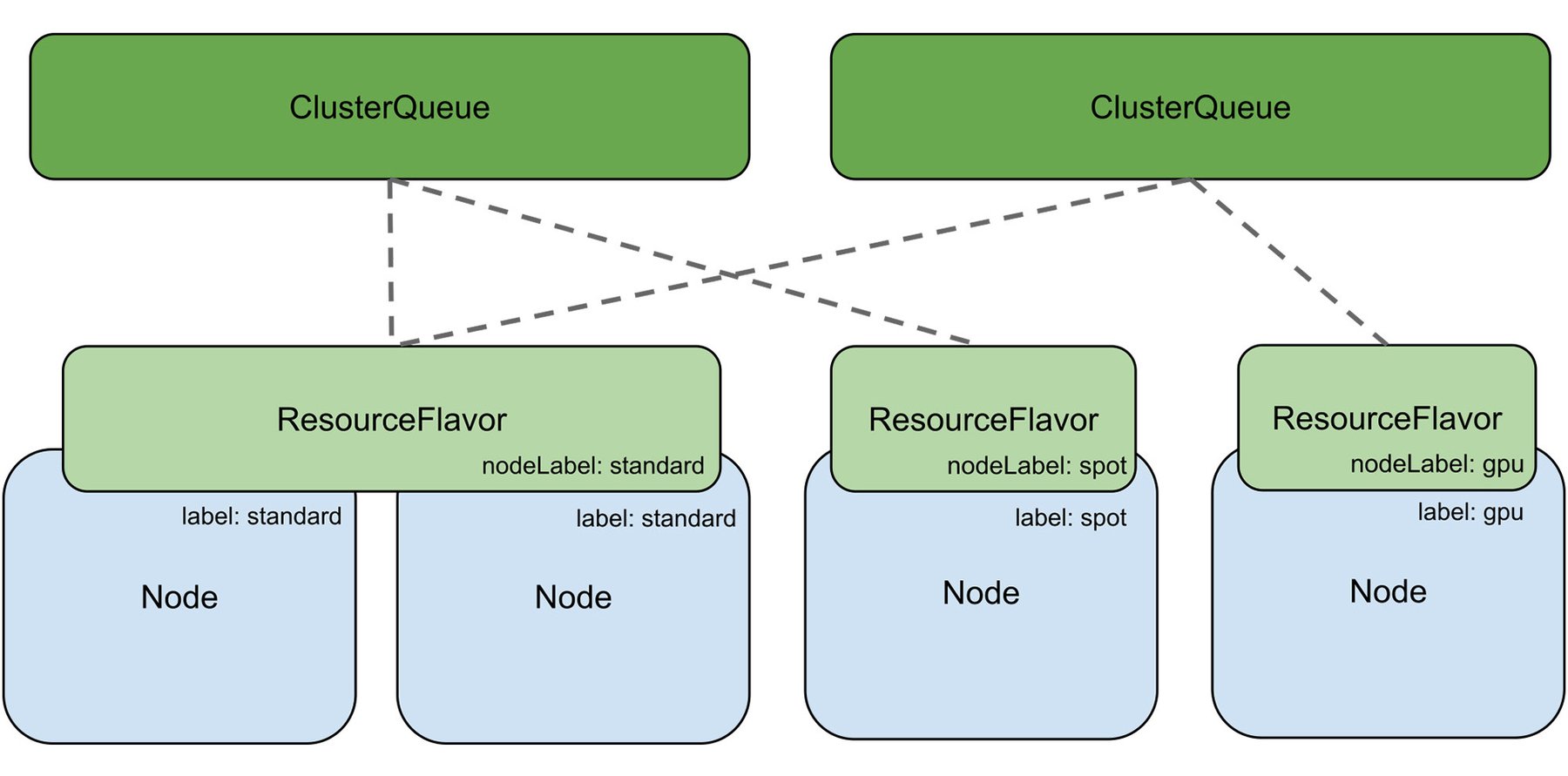
ResourceFlavor is an object in Kueue that represents resource variations and allows you to associate them with cluster nodes through labels and taints. For example, in your cluster you might have nodes with different CPU architectures (e.g. x86, Arm) or different brands and models of accelerators (e.g. Nvidia A100, Nvidia T4, etc). ResourceFlavors can be used to represent these resources and can be referenced in ClusterQueues with quotas to control resource limits. See Kueue concepts for more details.
Want to learn how to implement a Job queueing system, configure workload resource and quota sharing between different namespaces with GKE? See this tutorial.
Reliable workloads optimized for cost
The efficient use of compute and storage platform resources is important. To assist you with reducing costs and right-sizing your compute instances to align with your batch processing needs while not sacrificing performance, your GKE batch workloads can take advantage of Compute Engine Persistent Disks through Persistent volumes, providing durable storage for your workloads. To learn more about ways to optimize your workloads, from storage to networking configurations, see https://cloud.google.com/kubernetes-engine/docs/best-practices/batch-platform-on-gke#storage_performance_and_cost_efficiency
Observability
GKE is integrated with Google Cloud’s operations suite; you can control which logs and which metrics, if any, are sent from your GKE cluster to Cloud Logging and Cloud Monitoring. For batch users, this means being able to access detailed and up to date logs from their workload Pods and the flexibility to write their own workload specific metrics using monitoring systems like Prometheus. GKE also supports Managed Service for Prometheus for zero-hassle metrics collections backed by Google’s planet-scale Monarch time-series database. We recommend that you use managed collection; using it eliminates the complexity of setting up and maintaining Prometheus servers. To learn more, see batch platform monitoring.
Conclusion
GKE provides a scalable, resilient, secure and cost-effective platform for running containerized batch workloads with both a hands-off Autopilot experience and highly customizable Standard mode that can be specified to fit the needs of your organization. Having deep integration with Google Cloud services, access to all Compute Engine VM families, CPU and accelerator architectures and the Kubernetes-native Job queueing capabilities of Kueue, GKE is ready to be the new home for your batch workloads. It gives you the ability to operate large computational platforms, simplifying multitenancy, scale, and performance with cost optimization.
For more detailed information about how to design and implement the batch platform, see the Best practices for running batch workloads on GKE | Google Kubernetes Engine (GKE)
Want to learn how to implement a Job queueing system, configure workload resource and quota sharing between different namespaces with GKE? See this tutorial.